Centos 7 安装Hadoop 3.0.0-alpha1
简介:
本文主要介绍如何安装和配置单节点Hadoop,运用Hadoop MapReduce和Hadoop分布式文件系统(HDFS)执行一些简单的操作。算是一个入门级的文档吧。hadoop 安装三种模式
1. 单机
2. 伪分布式
3. 分布式
前提
支持的平台
GNU / Linux的支持作为开发和应用的平台。Hadoop已经证明在GNU / Linux集群中可以支持2000个节点。
Windows 平台不做介绍。
依赖的软件
1. JDK
2. ssh
操作系统: CentOS-7-x86_64
用户 : root
安装JDK
JDK:
下载最新的JDK8
将安装包解压到/usr/java/latest目录下面,设置环境变量
vi ~/.bash_profile
export JAVA_HOME=/usr/java/latest/jdk1.8.0_101
export PATH=$JAVA_HOME/bin:$PATH
配置ssh免密码登录
$ yum install ssh
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
安装hadoop-3.0.0-alpha1
下载最新的hadoop-3.0.0-alpha1
将安装包解压到 /root/hadoop目录下
tar -xzvf hadoop-3.0.0-alpha1.tar.gz
设置环境变量
export HADOOP_HOME=/root/hadoop/hadoop-3.0.0-alpha1
PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$HADOOP_HOME/bin
使环境变量生效. ~/.bash_profile
Standalone Operation
默认情况下,Hadoop常常配置为伪分布式模式,作为一个单独的java程序来调试。下面的示例是将打开conf目录使用作为输入,然后查找并显示每一个匹配正则表达式的文件。
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0-alpha1.jar grep input output 'dfs[a-z.]+'
$ cat output/*
Pseudo-Distributed Operation 伪分布式操作
Hadoop可以运行在一个伪分布模式,每个Hadoop守护进程运行在一个单独的java程序的一个节点。
etc/hadoop/core-site.xml:
fs.defaultFS
hdfs://localhost:9000
etc/hadoop/hdfs-site.xml:
dfs.replication
1
YARN on a Single Node 单节点Yarn
etc/hadoop/mapred-site.xml:
mapreduce.framework.name
yarn
mapreduce.admin.user.env
HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME
etc/hadoop/yarn-site.xml:
yarn.nodemanager.aux-services
mapreduce_shuffle
启动停止Hadoop
1. Format the filesystem:
$ bin/hdfs namenode -format
2. Start NameNode daemon and DataNode daemon:
$ sbin/start-dfs.sh
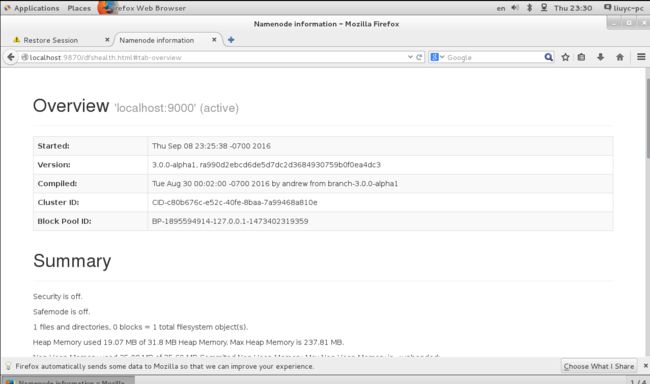
3. Browse the web interface for the NameNode; by default it is available at:
NameNode - http://localhost:9870/
4. Start ResourceManager daemon and NodeManager daemon:
$ sbin/start-yarn.sh
5. Browse the web interface for the ResourceManager; by default it is available at:
ResourceManager - http://localhost:8088/
停止hadoop
$ sbin/stop-dfs.sh
$ sbin/stop-yarn.sh
查看进程命令
jps
参考文档:
Apache Hadoop 官方文档