rknn3399pro 2小时入门指南(四)h5模型训练、tflite模型生成
目录
- 1.往期参照
- 2.简述
- 3. 模型训练
-
-
- (1)环境建立
- (2)数据说明
- (3)config代码详解
- (4)运行代码
- (5) 模型生成
- (6)libstdc++.so.6: version `GLIBCXX3.4.22' not found解决
-
1.往期参照
rknn3399pro 2小时入门指南(一)基础概念和基本开发流程
rknn3399pro 2小时入门指南(二)RKNN刷机攻略详解
rknn3399pro 2小时入门指南(三)在PC上搭建RKNN模拟环境、 模型转换代码、RK3399 pro使用
2.简述
(1)Rockchip提供RKNN-Toolkit开发套件进行模型转换、推理运行和性能评估。
模型转换:支持 Caffe、Tensorflow、TensorFlow Lite、ONNX、Darknet 模型,支持RKNN 模型导入导出,后续能够在硬件平台上加载使用。
相关的API有:load_caffe/load_tensorflow(相关pb文件)/load_tflite/load_onnx/load_darknet
(2)本人是基于keras+tensorflow(backend)进行开发的,所以主要是使用keras模型进行相关代码开发和转化。
AI嵌入式设备,常用的目标检测有yolo, tiny-yolo; 分类模型mobilenetv1, vgg, resnet50; 分割模型有mobilenet_segnet 等
注意:AI嵌入式芯片还是有一段路要走。(因为相关NPU芯片运算限制,并不是所有的模型都能完全转化成相关使用模型,所以优选已经成熟的k210/rknn官网提供的模型进行训练、转化。)
(3)从以下开始,以mobilenet-v1为例,详细讲解一下如何端到端训练、运行rknn3399模型。建议按照往期参照阅读。
3. 模型训练
主要使用到的是k210模型转化代码(aXeleRate),详解一下如何训练model、生成tflite。
建议使用CSDN资源下载:h5模型转为.kmodel/.tflite/.pb文件
(1)环境建立
s1:新建anaconda虚拟环境(k210_xxx:名称自取), 并进入
conda create -n k210_xxx python==3.6
conda activate k210_xxx
s2: 安装需要的环境: 如果有GPU的话,先安装tensorflow-gpu==1.15.0, 再 pip安装requirement.txt; 没有的话,就直接pip 安装requirement.txt
# 如果有GPU的话,新建tensorflow-gpu==1.15.0; 没有的话,就直接pip 安装requirement.txt
conda install tensorflow-gpu==1.15.0
pip install -r requirement.txt
requirement.txt内容
tensorflow>=1.15.0,<2.0.0
keras==2.3.1
imgaug>=0.2.9
opencv-python>=4.1.2.30
Pillow
requests
tqdm
sklearn
matplotlib
s3 验证一下:
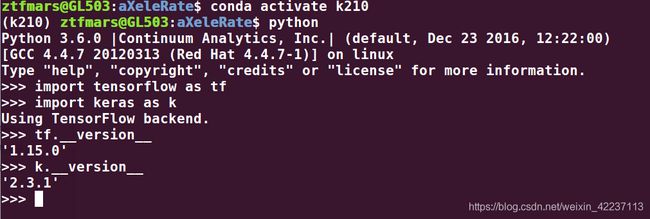
(2)数据说明
准备好数据,放置在aXeleRate文件夹内。
建议分好train/validation文件夹,分类名称即是所在的文件夹名称。数据比例建议按照7:3比例
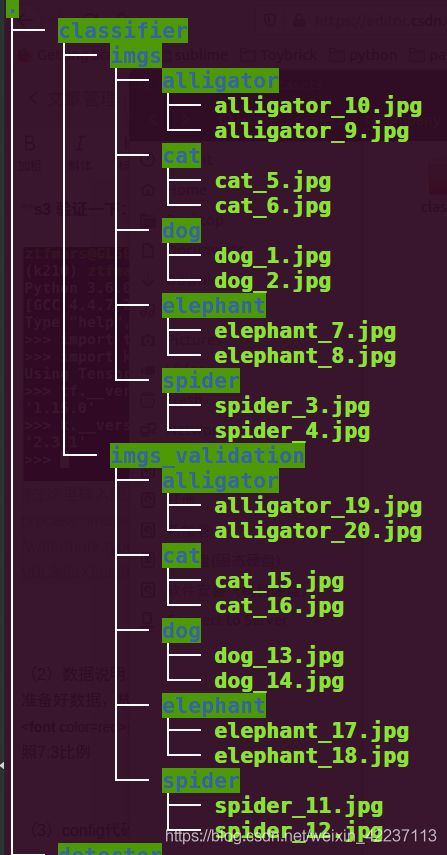
例如上图, 我此时想要训练的分类:alligaror/cat/dog/elephant/spider。
train dir: ./sample_datasets/classifier/imgs
validation dir: ./sample_datasets/classifier/imgs_validation
(3)config代码详解
新建一个xxx.py文件,复制如下代码,按照需求改写、要求训练生成的模型。
例如,需要训练一个分类模型,
需要关注项目:
"architecture":供选择的模型结构,主要有
"backend":默认是imagenet, 也可以是你自己训练的、对应的h5文件 "input_size": 输入图片尺寸, 此处是224 x 224 "actual_epoch": epoch 数目,一般选择300次,训练的时候有earlystop机制,accuracy不变化就自动停止了。 "train_image_folder"、"valid_image_folder": train/valid图片位置 "type": 可以选择生成.tflite---> "tflite"; 可以选择生成.kmodel(k210模型)---> "k210"MobileNet1_0
MobileNet7_5
MobileNet5_0
MobileNet2_5
SqueezeNet
VGG16
ResNet50
import argparse
from axelerate import setup_training, setup_inference
from keras import backend as K
argparser = argparse.ArgumentParser(description='Test axelerate on sample datasets')
argparser.add_argument(
'-t',
'--type',
default="all",
help='type of network to test:classifier,detector,segnet or all')
args = argparser.parse_args()
def configs(network_type):
classifier = {
"model" : {
"type": "Classifier",
"architecture": "MobileNet1_0",
"input_size": 224,
"fully-connected": [],
"labels": [],
"dropout" : 0.5
},
"weights" : {
"full": "",
"backend": "imagenet",
"save_bottleneck": False
},
"train" : {
"actual_epoch": 5,
"train_image_folder": "sample_datasets/classifier/imgs",
"train_times": 1,
"valid_image_folder": "sample_datasets/classifier/imgs_validation",
"valid_times": 1,
"valid_metric": "val_accuracy",
"batch_size": 4,
"learning_rate": 1e-4,
"saved_folder": "classifier",
"first_trainable_layer": "",
"augumentation":True
},
"converter" : {
"type": ["tflite","k210"]
}
}
detector = {
"model":{
"type": "Detector",
"architecture": "MobileNet7_5",
"input_size": [320, 240],
"anchors": [0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828],
"labels": ["aeroplane","person","diningtable","bottle","bird","bus","boat","cow","sheep","train"],
"coord_scale" : 1.0,
"class_scale" : 1.0,
"object_scale" : 5.0,
"no_object_scale" : 1.0
},
"weights" : {
"full": "",
"backend": None
},
"train" : {
"actual_epoch": 5,
"train_image_folder": "sample_datasets/detector/imgs",
"train_annot_folder": "sample_datasets/detector/anns",
"train_times": 1,
"valid_image_folder": "sample_datasets/detector/imgs_validation",
"valid_annot_folder": "sample_datasets/detector/anns_validation",
"valid_times": 1,
"valid_metric": "mAP",
"batch_size": 2,
"learning_rate": 1e-4,
"saved_folder": "detector",
"first_trainable_layer": "",
"augumentation": True,
"is_only_detect" : False
},
"converter" : {
"type": ['k210']
}
}
segnet = {
"model" : {
"type": "SegNet",
"architecture": "MobileNet5_0",
"input_size": 224,
"n_classes" : 20
},
"weights" : {
"full": "",
"backend": "imagenet"
},
"train" : {
"actual_epoch": 5,
"train_image_folder": "sample_datasets/segmentation/imgs",
"train_annot_folder": "sample_datasets/segmentation/anns",
"train_times": 4,
"valid_image_folder": "sample_datasets/segmentation/imgs_validation",
"valid_annot_folder": "sample_datasets/segmentation/anns_validation",
"valid_times": 4,
"valid_metric": "val_loss",
"batch_size": 8,
"learning_rate": 1e-4,
"saved_folder": "segment",
"first_trainable_layer": "",
"ignore_zero_class": False,
"augumentation": True
},
"converter" : {
"type": ['k210']
}
}
dict = {
'all':[classifier,detector,segnet],'classifier':[classifier],'detector':[detector],'segnet':[segnet]}
return dict[network_type]
for item in configs(args.type):
model_path = setup_training(config_dict=item)
K.clear_session()
# setup_inference(item,model_path)
(4)运行代码
直接运行相关代码
python xxx.py --type=classifier
(5) 模型生成
会自动生成一个project文件夹,下面则是生成、转化成的tflite文件、kmodel文件, 还有训练的accuracy变化图。
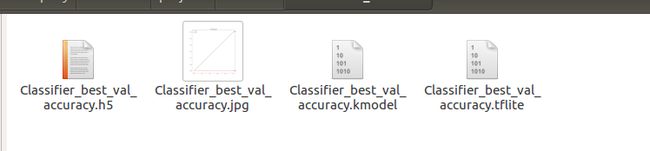
(6)libstdc++.so.6: version `GLIBCXX3.4.22’ not found解决
使用tensorflow model server时,出现错误,libstdc++.so.6: version `GLIBCXX3.4.22’ not found
这是因为当前版本的libstdc++.so.6缺少GLIBCXX_3.4.22.查看当前版本的GLIBCXX命令为,
strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep GLIBCXX
解决方法:
安装libstec++,
sudo apt-get install libstdc++6
如果还未解决,则可以终端运行如下命令:
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade
这是在运行命令,
strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep GLIBCXX
就可以看到存在 > 3.4.2的版本了
