我用python分析王冰冰B站视频,和冰冰一起逛北京!!
去年做的大作业,实现用tkinter库制作简单的GUI界面并且显示爬取成功的弹幕,并且制作词云、分析出现次数最多的十条弹幕,弹幕类型,弹幕颜色,提取封面图片等。
文章目录
-
-
-
- 完整代码
- 具体实现
-
-
完整代码
#大作业 b站弹幕分析系统
from imageio import imread #加载图片
import requests #发出请求
import csv #文件格式
import re #正则表达式筛选
import jieba #中文分词
import json
import urllib3
from urllib import request
from PIL import Image,ImageTk #呈现png,jpg图片
import wordcloud #绘制词云
import tkinter as tk
from tkinter import Button
from tkinter import messagebox
import matplotlib.pyplot as plt #绘图
import matplotlib as mpl
from bs4 import BeautifulSoup as BS #解析
mpl.rcParams['font.sans-serif'] = ['STKaiti'] #正常显示中文
main=tk.Tk() #建立主窗体
main.title('B站弹幕爬取界面')
main.geometry('1000x600')
label=tk.Label(main,text='请输入bv号')
label.grid(row=0,column=0)
entry=tk.Entry(main)
entry.grid(row=0,column=1)
Button(main,text='分析',command=lambda:menu0()).grid(row=0,column=2)
def menu0():
bv=entry.get() #获得输入内容
try:
if bv!='': #利用bv号获得cid,顺便获取duration和pic
url='http://api.bilibili.com/x/web-interface/view?bvid='+bv
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
urllib3.disable_warnings() #从urllib3中消除警告
response = requests.get(url,headers=headers)
content = json.loads(response.text)
# 获取到的是str字符串 需要解析成json数据
# print(response.content.decode('utf-8'))
statue_code = content.get('code')
#print(statue_code)
if statue_code == 0:
data=content['data']['pic']
name='fengmian.jpg'
request.urlretrieve(data,filename=name)
cid=content['data']['cid']
duration=content['data']['duration']
else:
print('该bv号不存在')
#利用cid获取并分析弹幕文件
url1='http://api.bilibili.com/x/v1/dm/list.so?oid='+str(cid)
response1 = requests.get(url1,headers=headers)
danmu_html = response1.content.decode('utf-8')
soup = BS(danmu_html, 'lxml') #解析
all_d = soup.select('d')
time,leixing,color=[],[],[]
for d in all_d:
biao=d['p'].split(',')
#把d标签中P的各个属性分离开
yanse=hex(int(biao[3]))[2:]
while len(yanse)<6: #处理颜色
yanse='0'+yanse
yanse1='#'+yanse
#print(yanse1)
color.append(yanse1)
time.append(int(eval(biao[0]))) #处理时间
leixing.append(int(biao[1])) #处理类型
res = re.compile('(.*?)' ) #处理弹幕文件
danmu = re.findall(res,danmu_html)
for i in danmu: #将弹幕按行写入csv文件
with open('b站弹幕.csv','a',newline='',encoding='utf-8-sig') as file:
writer = csv.writer(file)
danmu = []
danmu.append(i)
writer.writerow(danmu)
f = open('b站弹幕.csv',encoding='utf-8')
txt = f.read()
f.close() #打开文件,在文本框插入所有弹幕
text=tk.Text(main,height=30)
text.grid(row=1,column=1)
text.insert('insert',txt)
scrollbar = tk.Scrollbar() #关联文本框和滚动条
scrollbar.grid(row=1, column=1, sticky=tk.N+tk.S)
text['yscrollcommand'] = scrollbar.set
scrollbar['command'] = text.yview
def menu1():
count=[]
for i in range(duration):
count.append(time.count(i)) #统计每秒弹幕条数
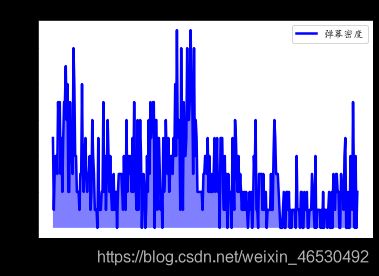
plt.plot(range(duration),count,'b-',linewidth=2.5,label='弹幕密度')
plt.xlabel('时间')
plt.ylabel('弹幕条数')
plt.legend()
plt.title('高能进度条') #绘制折线图
plt.savefig('gaoneng.png',dpi=100)
#填充
plt.fill_between(x=range(duration),y1=0,y2=count,facecolor='blue', alpha=0.5)
plt.show()
top0=tk.Toplevel()
top0.title('高能进度条')
top0.geometry('600x400')
global img_png1 #显示图片
img = Image.open('gaoneng.png')
img_png1 = ImageTk.PhotoImage(img)
label =tk.Label(top0, image = img_png1)
label.pack()
def menu2():
txt_list = jieba.lcut(txt) #精确分词
string = ' '.join((txt_list)) #连接成字符串
#这里需要一张本地图片,设置成mask参数
mk = imread('C:/Users/lenovo/Pictures/google.png')
#这里需要一份停用词表
f1=open('F:/stopwords.txt',encoding='utf-8')
txtt=f1.read()
f1.close()
w = wordcloud.WordCloud(max_font_size=10,
background_color='white',
font_path='C:/Windows/SIMLI.TTF',
mask=mk,
scale=2,
stopwords={
txtt},
collocations=False,
contour_width=5)
#contour_color='red'
w.generate(string) #生成词云
w.to_file('axwordcloud.png')
global img_png2
top=tk.Toplevel()
top.title('词云图')
top.geometry('800x600')
img = Image.open('axwordcloud.png')
img_png2 = ImageTk.PhotoImage(img)
label =tk.Label(top, image = img_png2)
label.pack()
def menu3():
global img_png3
dic,txt1={
},[]
f = open('b站弹幕.csv',encoding='utf-8')
txt= f.readlines() #这个方法是形成一个长列表
f.close()
for line in txt:
danm='' #删除一些无关信息
stop=',./,。?、‘“;;!! ·~`^&*()@#$%[]{}'
line=line[:-1] #去掉换行符\n
for item in line:
if item not in stop:
danm+=item
txt1.append(danm)
for i in range(len(txt1)):
num=0
for j in txt1:
if j==txt1[i]:
num+=1
dic[txt1[i]]=num #统计弹幕出现次数
#字典排序
dic1=sorted(dic.items(),key=lambda x:x[1],reverse=True)
x,y=[],[]
for i in range(10):
x.append(dic1[i][0])
y.append(dic1[i][1])
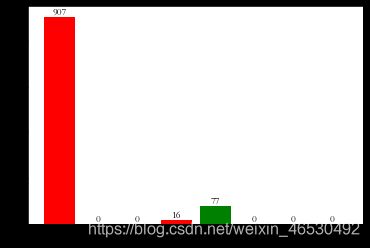
#绘制水平柱状图
bar=plt.barh(range(10),y,height=0.5,color='rgb')
for rect in bar: #显示数字
w = rect.get_width()
plt.text(w, rect.get_y()+rect.get_height()/2, '%d' %
int(w), ha='left', va='center')
plt.yticks(range(10),labels=x) #导入标签
plt.xlabel('弹幕数量')
plt.ylabel('弹幕排名')
plt.savefig('danmutop10.png',dpi=100)
plt.show()
top1=tk.Toplevel()
top1.title('弹幕数量top10柱状图')
top1.geometry('700x500')
img = Image.open('danmutop10.png')
img_png3 = ImageTk.PhotoImage(img)
label =tk.Label(top1, image = img_png3)
label.pack()
def menu4():
global img_png4
x=['滚动弹幕','滚动弹幕','滚动弹幕','底端弹幕','顶端弹幕','逆向弹幕','精准定位','高级弹幕']
y=[0 for i in range(8)]
for i in leixing:
y[i-1]+=1 #弹幕类型
plt.bar(range(1,9),y,color='rgb',tick_label=x)
for i in range(1,9):
plt.text(i,y[i-1],'%d'%y[i-1],ha='center',va='bottom')
plt.savefig('leixing.png',dpi=100)
plt.show()
top3=tk.Toplevel()
top3.title('弹幕类型')
top3.geometry('700x500')
img = Image.open('leixing.png')
img_png4 = ImageTk.PhotoImage(img)
label =tk.Label(top3, image = img_png4)
label.pack()
def menu5():
dic={
}
global img_png5
for i in color:
if i not in dic.keys():
dic[i]=1 #字典的键代表弹幕颜色,值代表出现次数
dic[i]+=1
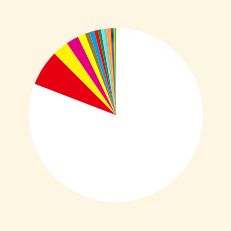
dic1 = dict(sorted(dic.items(), key=lambda x: x[1],reverse=True))
size=dic1.values()
color1=dic1.keys()
plt.style.use('Solarize_Light2') #设置背景颜色
plt.pie(size,colors=color1, #autopct='%1.1f%%',
startangle=90,counterclock=False)
plt.savefig('color.png')
plt.show()
top4=tk.Toplevel()
top4.title('弹幕颜色')
top4.geometry('600x400')
img = Image.open('color.png')
img_png5 = ImageTk.PhotoImage(img)
label =tk.Label(top4, image = img_png5)
label.pack()
def menu6():
global img_png6
top2=tk.Toplevel()
top2.title('封面图片') #封面图片
top2.geometry('1000x800')
img = Image.open('fengmian.jpg')
img_png6 = ImageTk.PhotoImage(img)
label =tk.Label(top2, image = img_png6)
label.pack()
Button(main,text='高能进度条',command=menu1).grid(row=1,column=2)
Button(main,text='生成词云图',command=menu2).grid(row=2,column=0)
Button(main,text='弹幕数量top10柱状图',command=menu3).grid(row=2,column=2)
Button(main,text='弹幕类型统计图',command=menu4).grid(row=2,column=3)
Button(main,text='弹幕颜色统计图',command=menu5).grid(row=3,column=2)
Button(main,text='弹幕封面图片',command=menu6).grid(row=3,column=3)
else:
messagebox.showinfo(message='请输入bv号')
except:
messagebox.showerror(title='爬取失败',message='bv号错误或网络异常')
main.mainloop()
具体实现
1.寻找视频的bv号:BV15K411u7t1
2.运行程序,开始分析

3.点击各个按钮,就可以实现各种功能
词云图:


封面图片:
仿B站高能进度条
前十弹幕

弹幕类型
弹幕颜色比例
完整工程地址:https://download.csdn.net/download/weixin_46530492/12789116