计算机视觉 CS231n Course Introduction
CS231n是非常经典的计算机视觉课程,为了方便新手学习,尤其是英文不好的同学,特意将该课程亲自翻译成中文,希望能对大家学习CV有一定的帮助。
CS231n每一年都有课程,最早的是2015年(http://cs231n.stanford.edu/2015),其中包括视频的分别为2016年(http://cs231n.stanford.edu/2016)和2017年(http://cs231n.stanford.edu/2017)。教学大纲为子域名syllabus,如http://cs231n.stanford.edu/2016/syllabus。两者最大的变化是,使用的深度学习框架是不同的。前者使用的是Tensorflow,而后者使用的是Pytorch。另外一个变化是,2016年的授课老师包括Andrej Karpathy(特斯拉AI高级总监,具体信息可参考https://cs.stanford.edu/people/karpathy/)。所以综上所述,最终选择了2016年版本的CS231n。

本门课主要的学习内容是神经网络,尤其是CNN(卷积神经网络)。
1. 计算机视觉的简要历史

2016年,思科统计得出,在网络空间中超过85%的数据均是多媒体数据(图片、视频等)。这是由于作为数据载体的互联网和数据采集器的爆炸式增长。具体的数据采集器(手机、摄像头等)如上图所示。
随着CV数据量的急剧增加,对应的数据处理能力也是不可或缺的。以Youtube为例,每一分钟所有的视频创作者就会上传总时长为150小时的视频。如此大的数据量,完全通过人工标注是不现实的。

CV是一门交叉学科。我们可以利用CV的方法,去解决各行各业的问题。而我们从事于认知科学、神经科学之间以及NLP和语音之间的交集。

基础较差的同学可以先学习CS131,学习地址为(http://vision.stanford.edu/teaching/cs131_fall2021/syllabus.html 和 https://github.com/StanfordVL/cs131_release)。
CS231a vs CS231n,CS231a中学习的工具和话题的覆盖面更广(如3D机器人的视觉识别),所以它是一门更通用的课程。而CS231n更专注于神经网络和视觉识别。
CS331和CS431是更深入的CV课程。

之所以介绍计算机视觉的简要历史,是因为如果没有对问题域是深入理解的话,就很难创造出解决问题的新模型,也就是说问题域和模型域并不是相互独立的,而是相互依托、相互推动的。例如,CNN的网络架构来自于解决视觉问题的实际需求,而视觉的实际问题帮助深度学习算法进化更新。


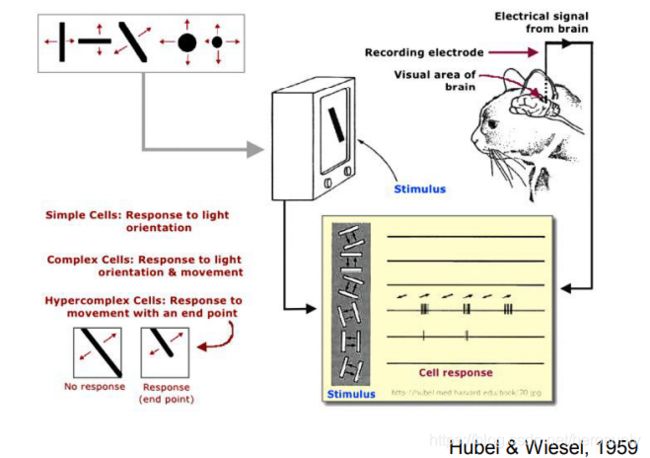
生物大脑如何处理视觉呢?哈佛博士后通过生物实验来进行探索,他对一只意识清晰、但被麻醉的猫进行实验,把一根针插入它脑部的基础视觉皮层。给猫播放各种图片(老鼠、鱼、花等),但是神经元都没有产生激活。但是在切换图片的时候,猫的神经元产生了激活,说明切换幻灯片的动作刺激了猫的神经元。实验证明,不管图片是正方形还是矩形的,移动的边缘都驱动了神经元的激活。基础视觉区的神经元是按一列一列的组织起来,每一列神经元只“喜欢”某一种特定简单的形状,例如条纹,边界。最终说明视觉的最初处理对象,不是整个形状,而是定向的边缘。该发现对神经生理学和神经科学都有非常深远的影响。
之后,对人脑的神经网络进行可视化,会发现出现了简单的边缘状结构,即使发现是在50年代后期和60年代初,这项工作赢得了1981年的诺贝尔医学奖。
有趣的是视觉皮层和眼睛之间的距离是比较远的,另外视觉涉及到大脑中大约50%的区域,所以视觉是大脑中最复杂的感知系统(耗费了很长的时间去演变进化)。

1963年Larry Roberts发表的 Block world是最早的计算机视觉的博士论文之一。他的观点是说,如上图所示两个相同的blocks,即使方向和光照发生了变化,人们也会认为是相同的blocks。而他的假设是说,结构是由边缘定义的,只要它们不被改变,则人们就会认为是不变的。

在1966年,MIT开启了一个著名的暑期项目即The Summer Vision Project,该项目企图用一个夏天的时间来解决大部分视觉系统的问题,该目标的确是野心勃勃。如今50多年已经过去了,计算机视觉领域也从一个单调的暑期项目发展成了在全世界拥有数以千记研究者的领域,虽然我们目前为止,还是没有彻底解决,但是计算机视觉仍是人工智能中最重要发展最快的领域之一(CV顶会包括CVPR、ICCV、ECCV等)。

David Marr也是MIT的视觉科学家,他曾经写了一本很有影响力的书叫做《VISION》。之前Hubel和Wiesel的研究表明,视觉系统初始对简单结构进行处理。而David Marr更进一步,提出了如何认识一个三维物体。上述的两个研究成果促使了视觉深度学习的开始。
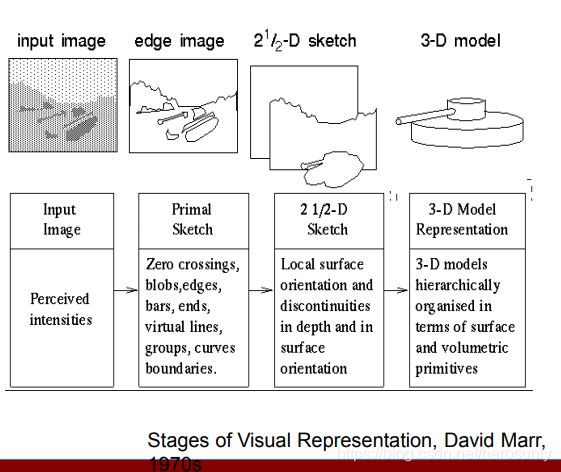
认识三维物体的过程如下所示:
- 基元图:由于图像的密度变化可能与物体边界这类具体的物理性质相对应,因此它主要描述图像的密度变化及其局部几何关系。(Zero crossings, blobs, edges, bars, ends, virtual lines, groups, curves, boundaries)
- 2.5维图:以观察者为中心,描述可见表面的方位、轮廓、深度及其他性质。(Local surface orientation and dis continuities in depth and in suface orientation)
- 3-D模型表示:以物体为中心,是用来处理和识别物体的三维形状表象。(3-D models hierarchically organized in terms of surface and volumetric primitives)
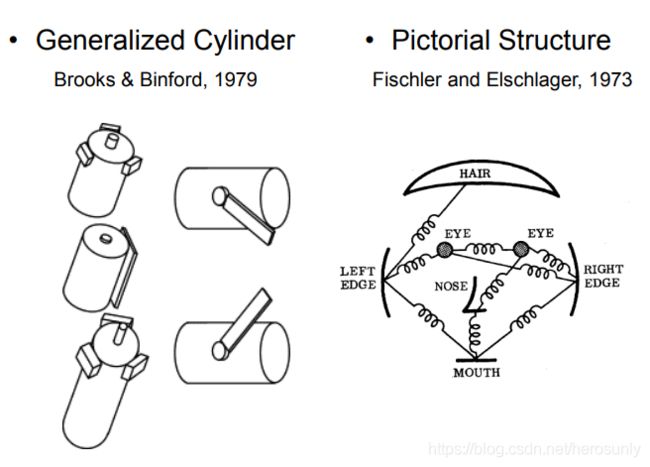
Rodney Brooks提出了第一个所谓的广义圆柱模型。他的观点是说,世界是由简单的形状(如圆柱)构成的,任何现实的物体都是由不同角度下简单形状的组合。
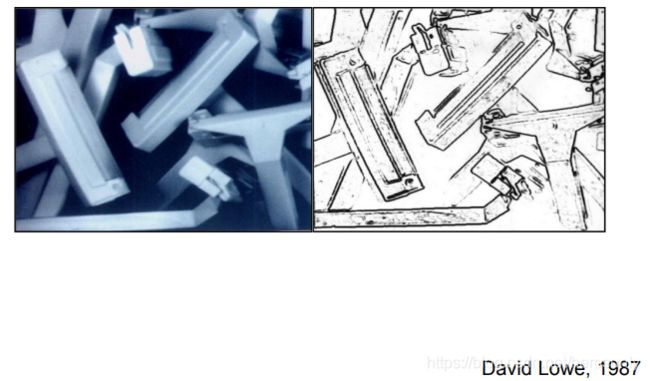
20世纪80年代,David Lowe使用边缘和简单形状的组合来识别物体(如剃须刀)。

感知分组(perceptual group是视觉中最重要的问题之一。

人脸识别技术在2006年被使用在富士相机上,人脸识别算法是比较早成功应用于产品中的算法。
随着时间的推移,计算机视觉从构建3D形状的物体到物体识别。
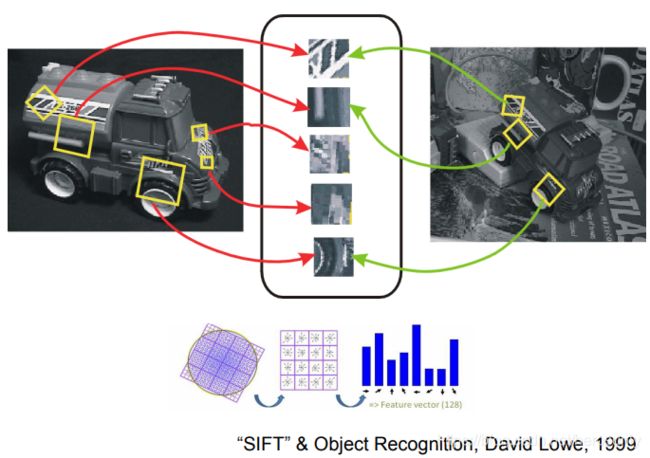
人们逐渐发现通过描述整个物体来进行识别是非常困难的,而通过重要的特征进行识别是可行的。David Lowe提出了基于:SIFT算子特征的图像识别算法。在2000~2010年的时间里,CV领域聚焦于提取特征对物体进行识别。

空间金字塔匹配也是通过提取特征+SVM分类的方法进行场景识别。

&esmp;在深度学习之前的最后一个模型是deformable part model(是一种基于组件的检测算法),该算法借鉴使用了之前的HOG算法。

PASCAL Visual Object Challenge,该数据集包括总共10000张图片,图片分为20个类别:火车、飞机、人等等

由于现实生活远不止20个类别,所以李飞飞开创了ImageNet项目,该项目专注于构建图像分类的数据集。ImageNet 不仅是计算机视觉发展的重要推动者,也是这一波深度学习热潮的关键驱动力之一。
ImageNet包括了1500 万由人工标注的图片,该图片库包括了超过 2.2 万个类别。其中,至少有 100 万张里面提供了边框(bounding box)。

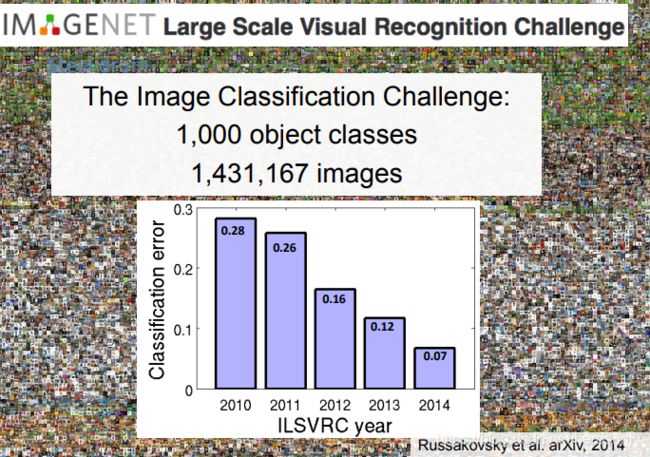
需要注意的是,y轴表示的是错误率。20120年的冠军使用了CNN网络,所以错误率急剧下降。最初的CNN网络是深度学习的开始。
2. 课程概述
CS231n聚焦于图像识别中最重要的问题之一:图像分类。图像识别包括了很多子领域,例如图像分类、3D建模、感知分组、图像分割。

图像分类的应用场景非常广泛。
以下是图像分类以外的其他视觉任务:

CNN成为了目标识别的重要工具。
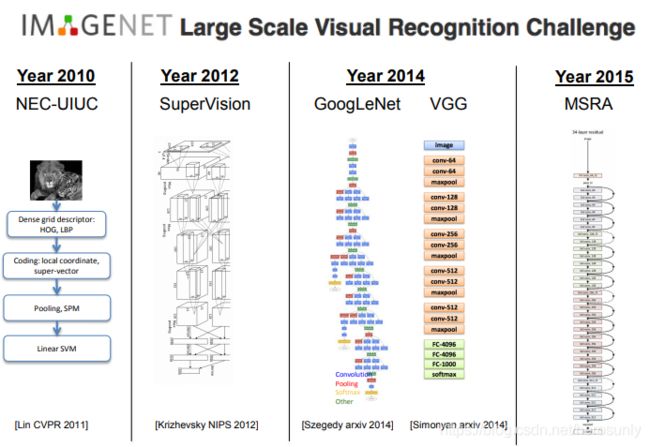
在各种图像识别的方法中,卷积神经网络(CNN)是目前最为成功的一类方法,自从2012年Alex krizhevsky和其导师Geoff Hinton提出的7层卷积神经网络获得Imagenet冠军之后,每届的冠军都是CNN网络架构,如2014年的GoogleNet和VGG,2015年的Resnet(该网络结构具有152层)。

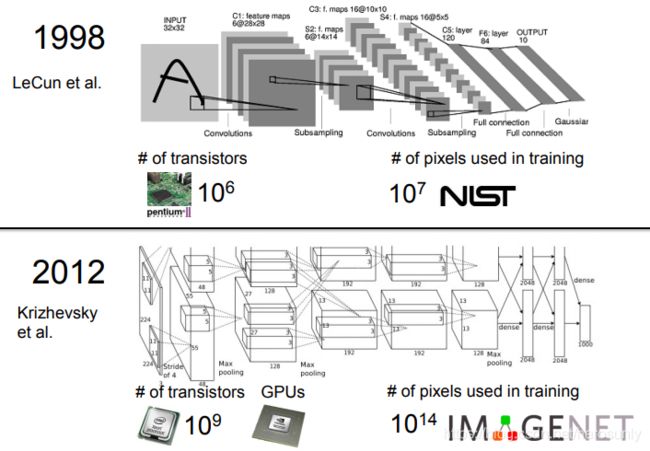
卷积神经网络并不是在一夜之间发明的,它是在研究神经网络过程中,多人智慧结晶的一个成果,其中最早作出贡献的是日本学者Kunihiko Fukushima,他建立了一个其称为Neocognitron的模型结构,Yann LeCun在90年代发表的用于手写数字识别的神经网络,其实与2012年Alex提出的模型是十分相似的。由于算力的大幅度增长,模型结构也变得越来越复杂,与此同时,模型的识别能力也逐渐增加。

图片的语义理解也是重要的研究方向。例如上图所示,理解图中的人物之间的关系,他们在做什么。

人们观察图片500ms就可以写出一篇短文用来描述其中的物体和发生的事件。所以我们也希望机器学习也能达到同样的效果。

