《Python数据分析与挖掘实战》第7章——航空公司客户价值分析(kmeans)
本文是基于《Python数据分析与挖掘实战》的实战部分的第七章的数据——《航空公司客户价值分析》做的分析。
旨在补充原文中的细节代码,并给出文中涉及到的内容的完整代码。
1)在数据预处理部分增加了属性规约、数据变换的代码
2)在模型构建的部分增加了一个画出雷达图的函数代码
1 背景与目标分析
此项目旨在根据航空公司提供的数据,对其客户进行分类,并且比较不同类别客户的价值,为能够更好的为客户提供个性化服务做参考。
2 数据探索性分析
2.1 数据质量分析
#对数据进行基本的探索
#返回缺失值个数以及最大最小值
import pandas as pd
datafile = 'air_data.csv'#航空公司原始数据,第一行是属性名
result = 'explore.xlsx'
data = pd.read_csv(datafile, encoding='utf-8')
explore = data.describe( percentiles = [],include = 'all').T
explore['null'] = len(data)-explore['count']
explore1 = explore[['null','max','min']]
explore1.columns = [u'空值数',u'最大值',u'最小值']#重命名列名
explore1.to_excel(result)
探索结果:
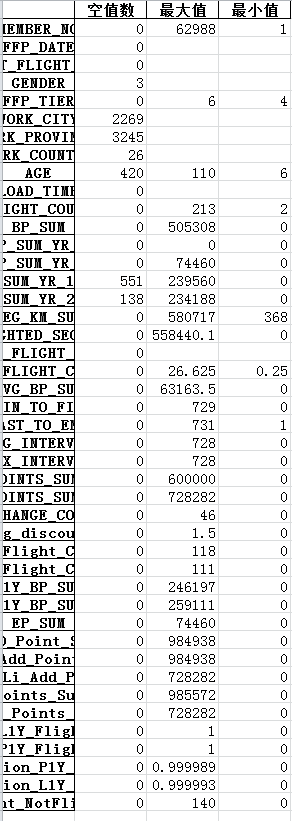
3 数据预处理
3.1 数据清洗
datafile = 'air_data.csv'#航空公司原始数据,第一行是属性名
data = pd.read_csv(datafile, encoding='utf-8')
# 丢弃掉票价为0的记录;丢弃票价为0、平均折扣不为零、总飞行公里大于0的记录
cleanedfile = 'cleaned.xlsx'
data1 = data[data['SUM_YR_1'].notnull()*data['SUM_YR_2'].notnull()] #票价非空值才保留,去掉空值
#只保留票价非零的,或者平均折扣率与总飞行公里数同时为零的记录
index1 = data1['SUM_YR_1'] != 0
index2 = data1['SUM_YR_2'] != 0
index3 = (data1['SEG_KM_SUM'] == 0) & (data1['avg_discount'] == 0)
data1 = data1[index1 | index2 | index3] #或关系
data1.to_excel(cleanedfile)
data2 = data1[['LOAD_TIME','FFP_DATE','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]
data2.to_excel('datadecrese.xlsx')
3.2 数据规约及属性构造
import numpy as np
data = pd.read_excel('datadecrese.xlsx')
data['L1'] = pd.to_datetime(data['LOAD_TIME']) - pd.to_datetime(data['FFP_DATE'])# 以纳秒为单位
# data['L3'] = data['L1'].astype('int64')/10**10/8640/30 # 此方法假定每个月是30天,这方法不准确
data['L3'] = data['L1']/np.timedelta64(1, 'M') # 将间隔时间转成月份为单位,注意,此处必须加一个中间变量 (****)
# 将表中的浮点类型保留至小数点后四为
# f = lambda x:'%.2f' % x
# data[['L3']] = data[['L3']].applymap(f) # or data['L3'] = data['L3'].apply(f)
# data[['L3']] = data[['L3']].astype('float64')# 注意:使用apply或applymap后,数据类型变成Object,若后续有需要需要在此进行类型转换
data["L3"] = data["L3"].round(2) # 等价于上面三句话,数据类型不变
data['LAST_TO_END'] = (data['LAST_TO_END']/30).round(2) # 此方法假定每个月是30天,这方法不够准确
data['avg_discount'] = data['avg_discount'].round(2)
data.drop('L1', axis=1, inplace =True) # 删除中间变量
data.drop(data.columns[:3], axis=1, inplace =True) # 去掉不需要的u'LOAD_TIME', u'FFP_DATE'
data.rename(columns={
'LAST_TO_END':'R','FLIGHT_COUNT':'F','SEG_KM_SUM':'M','avg_discount':'C','L3':'L'},inplace=True)
data.to_excel('sxgz.xlsx',index=False)
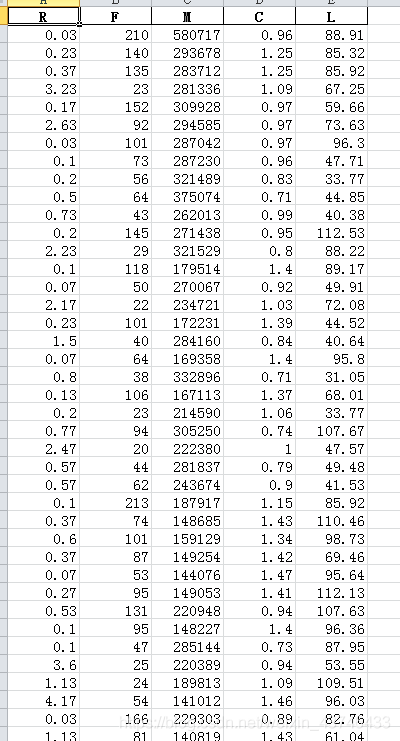
def f(x):
return Series([x.min(),x.max()], index=['min','max'])
d = data.apply(f)
d.to_excel('summary_data.xlsx')

3.3 数据标准化
# 3> 数据标准化
#标准差标准化
d1 = pd.read_excel('sxgz.xlsx')
d1=d1.astype('float64')
d2 = (d1-d1.mean())/d1.std()
d1 =d2.iloc[:,[4,0,1,2,3]]
d1.columns = ['Z'+i for i in d1.columns]#表头重命名
d1.to_excel('sjbzh.xlsx',index=False)
4.模型建立
4.1 k-means
#使用K-means聚类算法分类并分析每类的特征
import pandas as pd
from pandas import DataFrame,Series
from sklearn.cluster import KMeans #导入K均值聚类算法
k = 5 # 聚为5类
d3 = pd.read_excel('sjbzh.xlsx')
#调用k-means算法,进行聚类分析
kmodel = KMeans(n_clusters=k, n_jobs=4)# n_job是并行数,一般等于CPU数较好
kmodel.fit(d3)
labels = kmodel.labels_#查看各样本类别
demo = DataFrame(labels,columns=['numbers'])
demo1= DataFrame(kmodel.cluster_centers_, columns=d3.columns) # 保存聚类中心
demo2= demo['numbers'].value_counts() # 确定各个类的数目
demo2

demo4 = pd.concat([demo2,demo1],axis=1)
demo4.index.name='labels'
demo4.to_excel('kmeansresults.xlsx')
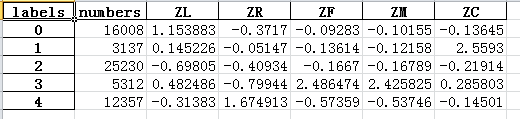
4.2 雷达图
#画雷达图 客户群特征分析图
subset = demo1.copy()
subset = subset.round(3)
subset.to_excel('testradar.xlsx')
data = subset.as_matrix() # 将表格数据转成数组
from radar1 import drawRader # 从已经编写好的画雷达图的函数中导入
title = 'RadarPicture'
rgrids = [0.5, 1, 1.5, 2, 2.5]
itemnames = ['ZL','ZR','ZF','ZM','ZC']
labels = list('abcde')
drawRader(itemnames=itemnames,data=data,title=title,labels=labels, saveas = '2.jpg',rgrids=rgrids)
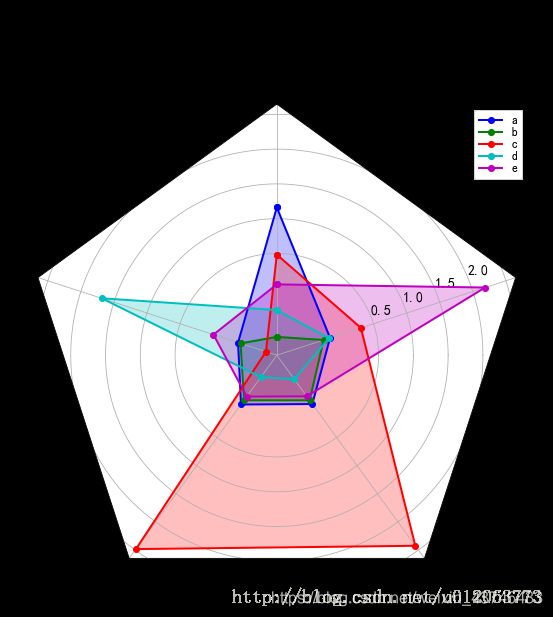
radar1:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.path import Path
from matplotlib.spines import Spine
from matplotlib.projections.polar import PolarAxes
from matplotlib.projections import register_projection
def radar_factory(num_vars, frame='circle'):
"""Create a radar chart with `num_vars` axes.
This function creates a RadarAxes projection and registers it.
Parameters
----------
num_vars : int
Number of variables for radar chart.
frame : {'circle' | 'polygon'}
Shape of frame surrounding axes.
"""
# calculate evenly-spaced axis angles
theta = np.linspace(0, 2*np.pi, num_vars, endpoint=False)
# rotate theta such that the first axis is at the top
theta += np.pi/2
def draw_poly_patch(self):
verts = unit_poly_verts(theta)
return plt.Polygon(verts, closed=True, edgecolor='k')
def draw_circle_patch(self):
# unit circle centered on (0.5, 0.5)
return plt.Circle((0.5, 0.5), 0.5)
patch_dict = {
'polygon': draw_poly_patch, 'circle': draw_circle_patch}
if frame not in patch_dict:
raise ValueError('unknown value for `frame`: %s' % frame)
class RadarAxes(PolarAxes):
name = 'radar'
# use 1 line segment to connect specified points
RESOLUTION = 1
# define draw_frame method
draw_patch = patch_dict[frame]
def fill(self, *args, **kwargs):
"""Override fill so that line is closed by default"""
closed = kwargs.pop('closed', True)
return super(RadarAxes, self).fill(closed=closed, *args, **kwargs)
def plot(self, *args, **kwargs):
"""Override plot so that line is closed by default"""
lines = super(RadarAxes, self).plot(*args, **kwargs)
for line in lines:
self._close_line(line)
def _close_line(self, line):
x, y = line.get_data()
# FIXME: markers at x[0], y[0] get doubled-up
if x[0] != x[-1]:
x = np.concatenate((x, [x[0]]))
y = np.concatenate((y, [y[0]]))
line.set_data(x, y)
def set_varlabels(self, labels):
self.set_thetagrids(np.degrees(theta), labels)
def _gen_axes_patch(self):
return self.draw_patch()
def _gen_axes_spines(self):
if frame == 'circle':
return PolarAxes._gen_axes_spines(self)
# The following is a hack to get the spines (i.e. the axes frame)
# to draw correctly for a polygon frame.
# spine_type must be 'left', 'right', 'top', 'bottom', or `circle`.
spine_type = 'circle'
verts = unit_poly_verts(theta)
# close off polygon by repeating first vertex
verts.append(verts[0])
path = Path(verts)
spine = Spine(self, spine_type, path)
spine.set_transform(self.transAxes)
return {
'polar': spine}
register_projection(RadarAxes)
return theta
def unit_poly_verts(theta):
"""Return vertices of polygon for subplot axes.
This polygon is circumscribed by a unit circle centered at (0.5, 0.5)
"""
x0, y0, r = [0.5] * 3
verts = [(r*np.cos(t) + x0, r*np.sin(t) + y0) for t in theta]
return verts
def example_data():
# The following data is from the Denver Aero
data1 = [
['ZL','ZR','ZF','ZM','ZC'],
('R',
[[0.063,-0.0040000000000000001, -0.22600000000000001,-0.22900000000000001,2.1949999999999998],
[1.161, -0.377, -0.086999999999999994, -0.095000000000000001, -0.159],
[0.48299999999999998,-0.79900000000000004,2.4830000000000001,2.4249999999999998,0.308],
[-0.314,1.6859999999999999,-0.57399999999999995,-0.53700000000000003,-0.17299999999999999],
[-0.69999999999999996, -0.41499999999999998, -0.161, -0.161, -0.253]]
)
]
return data1
if __name__ == '__main__':
N = 5
theta = radar_factory(N, frame='polygon')
data = example_data()
spoke_labels = data.pop(0)
fig, axes = plt.subplots(figsize=(9, 9), nrows=2, ncols=2,
subplot_kw=dict(projection='radar'))
fig.subplots_adjust(wspace=0.25, hspace=0.20, top=0.85, bottom=0.05)
colors = ['b', 'r', 'g', 'm', 'y']
# Plot the four cases from the example data on separate axes
for ax, (title, case_data) in zip(axes.flatten(), data):
ax.set_rgrids([0.5, 1, 1.5,2,2.5])
ax.set_title(title, weight='bold', size='medium', position=(0.5, 1.1),
horizontalalignment='center', verticalalignment='center')
for d, color in zip(case_data, colors):
ax.plot(theta, d, color=color)
ax.fill(theta, d, facecolor=color, alpha=0.25)
ax.set_varlabels(spoke_labels)
# add legend relative to top-left plot
ax = axes[0, 0]
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
labels = (list('abcde'))
legend = ax.legend(labels, loc=(0.9, .95),
labelspacing=0.1, fontsize='small')
fig.text(0.5, 0.965, '5-Factor Solution Profiles Across Four Scenarios',
horizontalalignment='center', color='black', weight='bold',
size='large')
plt.show()
虽然以前刚开始接触数据分析做过一遍这个项目,第二遍浏览下来感觉比第一次轻松许多。
参考大佬的文章:https://blog.csdn.net/u012063773/article/details/79297670