python爬虫实战教程
Python爬虫学习
前言
本博客为本人原创禁止转载
本次python爬虫系列主要以代码的方式入门基础爬虫系列,对部分知识理论解释不多,读者会用即可,特点注意本博客是以实战为基础一定要看代码,讲解主要分。以下7个模块进行。
1、requests库
2、xpath使用
3、BeautifulSoup
4、Re正则模块
5、代理IP
6、分页爬取
7、实战妹子图
requests库
requests库的简单入门
发起get请求
如何发起get请求?
# 导入requests包
import requests
# 定义请求的url(本次爬取百度)
url = 'https://www.baidu.com'
# 发起get请求
res = requests.get(url=url)
# 获取响应结果
print(res) # 对象 200表示成功
print(res.content) # b'...' 二进制文本流
print(res.content.decode('utf-8')) # 把二进制文本流按utf-8转换为普通字符集
print(res.text) # 获取相应内容
print(res.status_code) # 请求状态码 200代表成功
print(res.url) # 请求url
print(res.request.headers) # 请求头信息
print(res.headers) # 响应头信息
当然我们通过上述res.request.headers获取请求头可以发现,我们的请求头为’python-requests/2.23.0’值等于赤裸裸的告诉浏览器,我就是爬虫我要来爬你,很大概率会被服务器拒绝访问,此时就需要引入请求头。
requests请求头
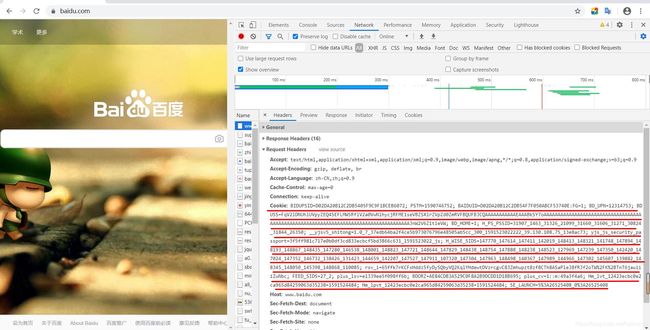
什么是请求头我们在谷歌输入www.baidu.com后打开开发者工具回车后可以看到如下信息

我红线画出的是requests请求的请求头,要使服务器察觉不到是爬虫访问了它最简单的就是设置请求头,下面实现一个带请求头的代码。
import requests
# 定义请求的url
url = 'https://baidu.com/'
# 定义请求头信息
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36'
}
# 发起get请求
res = requests.get(url=url, headers=headers)
# 获取响应状态码
code = res.status_code
# 响应成功后把响应内容写入文件
if code == 200:
print(res.requests.headers)
此时请求头信息就定义为了我们设置的这时服务器就无法判断着到底是爬虫还是正常请求了。
当然如果我们想通过爬虫获取网页源代码只需要在代码下面加上这个语句
with open('./test1.html', 'w', encoding='utf-8') as fp:
fp.write(res.text)
值得注意的是,由于pycharm默认utf-8编码格式,如果不加上encoding='utf-8’是会报错的。
post请求
前面我们学习了get请求,顾名思义get请求拉请求,向服务器拉取我们需要的内容,入网页,但某些时候我们是需要向服务器发送东西的,例如我们进行翻译时时需要向服务器发送内容的,这时便需要post请求。
下面跟我进行百度翻译过程分析,当输入需要翻译的内容后打开开发者工具可以看到个sug的消息,里面包含了我们请求翻译的内容以及返回的内容


可以看出浏览器向www.baidu.com/sug发送post请求后可得到一个json的返回数据,数据里面有我们需要的数据。
下面我们就来通过post请求实现一个翻译的功能
import requests
# 定义请求的url
url = 'https://fanyi.baidu.com/sug'
# 定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36'
}
# post发送数据
data = {
'kw':'你好'}
# 发送请求
res = requests.post(url=url, headers=headers, data=data)
# 接受返回数据
code = res.status_code
if code == 200:
print('请求成功')
data = res.json()
if data['errno'] == 0:
print('响应成功')
print(data['data'][0]['k'])
v = data['data'][0]['v']
print(v.split(';')[-2])
当然上面的data是事先设置好的,感兴趣的小伙伴可以自己去实现一个能自己输入信息进行翻译的代码,给个提示使用个input就可以,对有python基础的小伙伴应该很容易实现.
cookie和session
使用浏览器我们经常会发现意见事情浏览器貌似会记住我们的信息,但我们都了解http请求是一个无状态请求协议,什么是无状态请求协议简单来说就是它不会记住用户的状态和任何信息。而网站记录的信息是怎么回事,其实这就是cookie信息,同时我们也可以使用cookie信息访问网站
而cookie是在服务器本地的如果我们不想使用只要在浏览器清除cookie信息就不可以使用了,而seesion与cookie不同,session是在服务器断进行数据记录的,并给每一个用户生成session ID,并在浏览器设置cookie。
下面来看一个带cookie的请求头
# 定义请求头信息
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36',
'cookie':'cookie的信息各位从浏览器复制即可'
}
Xpath使用
xpath基本入门
xpath可以怎么用xpath可以用来解析html字符串,下面用一个小案例啊进行演示
from lxml import etree # 这就是使用xpath所必须的导包操作
text = '''
海螺肉爬虫教程
'''
# 使用etree解析html字符串
html = etree.HTML(text)
# 提取数据
r = html.xpath('/html/body/ul/li/a/text()') # ['Java工程师', 'python工程师', 'AI工程师']
# print(r)
r = html.xpath('/html/body/ul/li[1]/a/text()') # ['Java工程师']
print(r)
当然小伙伴们可能会好奇这是怎么解析的,下面就进行说明。
'''
/ 当前元素的直接子节点
// 当前元素的子节点或孙子节点
text() 获取文本
@attr 获取属性对应的值
'''
而对第一个代码进行分析
/html后获取的为整个html文档的值,/html/body后获取的内容就缩小为标签内的内容了,/html/body/ul后或取的内容就缩小到了
xpath实战
下面我们使用xpath进行一下实战带小伙伴们更好的学习xpath,我们将要实战xpath获取文章的信息,爬取内容如下。
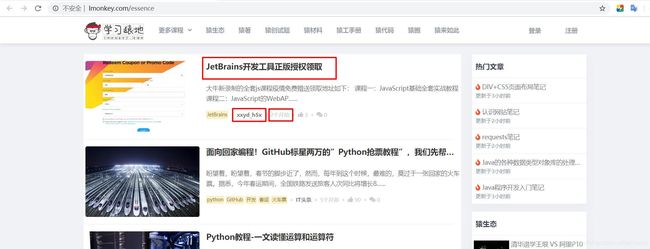
爬取学习猿地猿著文章的标题,作者,以及文章url。首先对网页源码进行分析。
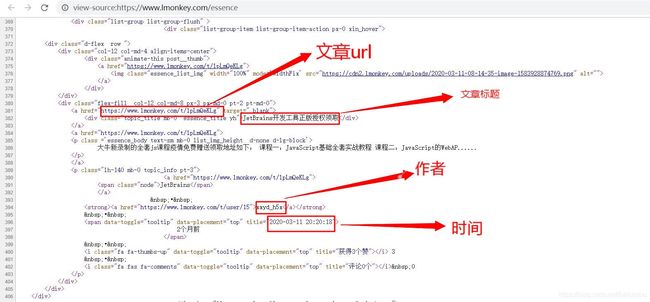
下面给出爬虫代码并进行分析
import requests
import json
from lxml import etree
# 请求地址
url = 'https://www.lmonkey.com/essence'
# 请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36'
}
# 发送get请求
res = requests.get(url=url, headers=headers)
# 请求成功
if res.status_code==200:
# 请求内容写入文件
with open('./yuanzhu.html', 'w', encoding='utf-8') as fp:
fp.write(res.text)
# 解析数据
html = etree.parse('./yuanzhu.html', etree.HTMLParser())
# 提取数据 作者 文章标题 文章地址url
author = html.xpath('//div[@class="list-group-item list-group-item-action px-0 xin_hover"]//strong/a/text()')
titles = html.xpath('//div[@class="topic_title mb-0 essence_title yh"]/text()')
titleurl = html.xpath('//div[@class="flex-fill col-12 col-md-8 px-3 px-md-0 pt-2 pt-md-0"]/a[1]/@href')
data = []
for i in range(0,len(author)):
res = {
'作者:':author[i], '标题:':titles[i], '文章链接:':titleurl[i]}
data.append(res)
print(data)
# 写入数据
with open('./yz.json', 'w') as fp:
json.dump(data, fp)
BeautifulSoup
bs4基本操作
from bs4 import BeautifulSoup
html_doc = '''
海螺肉爬虫
内容如下
Java工程师
Java在当前比较火值得学习
python工程师
python写爬虫很棒
AI工程师
ai改变世界
'''
# 创建一个BeautifulSoup对象,建议手动指定解析器
soup = BeautifulSoup(html_doc, 'lxml')
# 通过tag标签对象获取文档数据
r = soup.title
r = soup.title.text # 获取文本
print(r)
p = soup.p # 获取p标签的内容
print(p)
# 通过搜索获取页面中的元素 find, find_all
r = soup.find('a') # 找到第一个a标签的内容
print(r)
r = soup.find_all('a') # 找到所有a标签的内容
print(r)
# css选择器
# 通过标签选择元素
r = soup.select('title') # 获取title标签内容
# print(r)
# 通过class类获取元素
r = soup.select('.title') # 获取class为title的标签的内容
# print(r)
# 通过ID名获取元素
# 通过空格 层级关系获取元素
r = soup.select('html body p') # 获取html下body内容下所有p标签的内容
# print(r)
# 通过逗号 并列关系获取元素
r = soup.select('title, a') # 获取title标签和a标签下的内容
print(r)
Re正则模块
Re基本内容
'''
正则表达式,就是使用字符,转义字符和特殊字符组成一个规则
使用这个规则对文本的内容完成一个搜索或匹配或替换的功能
正则表达式的组成
普通字符:大小写字母,数字,符号
转义字符:\w \W \d \D \s \S...
特殊符号:. * ? + ^ $ [] {} ()
匹配模式:I U...
'''
import re
# 定义字符串
vars = 'ilove520python'
# 定义正则
reg = '\d\d\d'
# 调用正则表达式
res = re.findall(reg,vars)
print(res) # 520
# 一个简单的正则匹配了520三个数字
Re模块相关函数
import re
'''
re.match()函数
特点:从头开始匹配,要么第一个就符合要求,要么不符合
匹配成功返回match对象,否则返回None,
返回结果可用group()获取
可用span()获取匹配区间
re.search()函数
特点:从字符串开头到结尾开始搜索式匹配
匹配成功返回search对象,否则返回None,
返回结果可用group()获取
可用span()获取匹配区间
re.findall()
特点:按照正则表达式规则在字符串中匹配元素,结果返回一个列表,如果没有返回空列表
re.finditer()
特点:按照正则表达式规则在字符串中匹配所有复合规则的元素,返回一个迭代器
re.sub()
特点:安按照正则表达式的规则,在字符串中找到需要被替换的字符串
参数:
pattern:正则表达式规则,匹配组要被替换的字符串
repl:替换的字符串
string:被替换原始字符串
compile()
定义:可以直接将正则表达式定义为正则对象,使用正则对象直接操作
'''
# 定义字符串
vars = 'iloveyou521tosimida511'
# 定义正则表达式
reg = 'love' # 代表一个数字
# 调用match正则方法
res = re.match(reg, vars)
# print(res)
# print(res.group())
# print(res.span())
# search
res = re.search(reg, vars)
# print(res)
# print(res.group())
# print(res.span())
# re.findall()
reg = '\d\d\d' # 也可以 reg = '\d{3}'
# res = re.findall(reg, vars)
# print(res)
# re.finditer()
res = re.finditer(reg, vars)
# print(res)
# print(list(res))
# sub
# res = re.sub(reg, 'AAA', vars)
# print(res)
# compile
reg = re.compile('\d{3}')
res = reg.findall((vars))
print(res)
Re模块正则表达式定义
import re
'''
正则表达式规则定义
'''
# 普通字符
# vars = 'iloveyou'
#
# reg = 'love'
# res = re.search(reg, vars).group()
# print(res)
# 转义字符 \w \W \d \D \s \S...
# \w 代表单个字母 数字 下划线
# \W代表单个的W非 字母、数字、下划线
# \d 代表单个数字
# \D代表单个的非数字
# \s代表单个空格符或制表符
# \S代表单个的非空格符或制表符
# varstr = '@_ilove you520'
#
# reg = '\S\w\w\w\w' # 可组合使用
# res = re.search(reg, varstr).group()
# print(res)
# 特殊字符 . * + ? {} [] () ^ $
varstr = 'hello Wor。ld iloveyou5211'
reg = '.' # 代表任意字符 除了换行符之外
reg = '.*' # * 代表匹配次数 任意次数 若开始不符合直接返回
reg = '.+' # + 代表匹配次数 至少要求匹配一次 若开始不匹配 往后跳继续匹配
reg = '.+?' # ? 拒绝贪婪,匹配要求只要达成则返回
reg = '\w{4}' # {} 代表匹配次数 {4} 一个数字时,代表必须匹配的次数 {2,5}两个数字时,代表匹配的区间次数
reg = '[a-z]' # []代表范围
reg = '[A-Z, a-z]'
reg = '\w+(\d{4})' # ()代表子组 括号中的表达式首先作为正则的一部分,另外会把小括号中的内容单独提取一份
reg = '(.*?)'
res = re.search(reg, varstr)
print(res.group())
varstr = '17610105211'
# 定义一个匹配手机号的正则表达式规则
reg = '^1\d{10}$'
# 定义一个正则表达式验证一个邮箱是否正确
varstr = '[email protected]'
reg = '[a-zA-Z0-9-_]+@[a-zA-Z0-9]+.com$'
res = re.search(reg, varstr)
# print(res.group())
# print(res.groups())
# 正则模式
varstr = 'iloveYou'
reg = '[a-z]+'
res = re.search(reg, varstr)
# print(res.group())
代理IP
某些时候我们使用爬虫爬取大量数据的时候由于快速的请求,导致服务器压力过大而这时服务器最好的解决措施就是封IP,让你的IP不能继续访问, 而这时解决方式有两个,一个就是你爬慢一点,让服务器觉得你还是人在请求,还有一个就是使用代理IP,代理IP当然现在有很多代理IP网站,但如果你不出钱几乎用不了(曾经试过十多个才能找到一个可能的

当然我画出只是告诉你他是一个免费的IP,并不是说可用…
而代理IP该如何使用下面进行了解
proxies = {
'http':'123.207.57.145:1080',
'https':'123.207.57.145:1080'
}
# 发起get请求
res = requests.get(url=url, headers=headers, proxies=proxies)
# 如上就使用了代理IP技术
分页爬取
前面的爬虫都只能爬一页可是作为爬虫只爬一页是不是太屈辱了…所以还是得学会分页爬虫才行,分页爬虫怎么进行简单来说就是不断循环请求而已,最后我会用分页爬取技术爬取快代理20页ip
分页原理分析
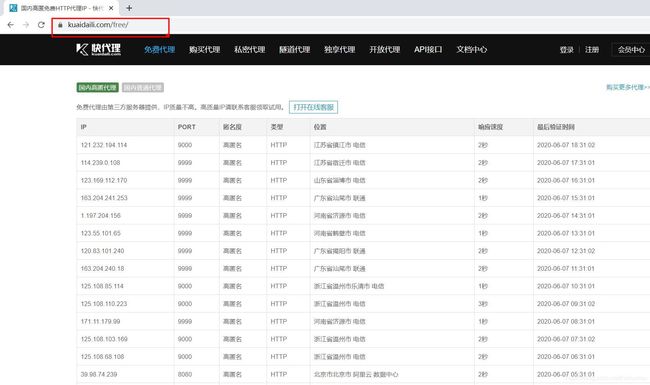

可以看到两个页面的差别在于url地址的不同,所以我们只需要在循环请求中不断改变url地址即可
而该如何循环实现改变url地址呢
for i in range(1,21):
print(f'当前正在爬取第{i}页')
# 定义请求url
time.sleep(2)
url = 'https://www.kuaidaili.com/free/inha/'+str(i)+'/'
这样就可以不断改变url地址,实现循环请求
而前面我们获取的数据都没有进行存取,但是当我们获取大量数据后将其存入数据库就是必须的了,如何实现这个操作其实页很简单,使用一个pymqsql包就可以,我使用的是python3.×,如果小伙伴使用python 2.×所需包有所不同.
# 将数据写入数据库
try:
conn = pymysql.connect(host="127.0.0.1", user='root', port=3306, passwd='root', db='db1', charset='utf8')
cursor = conn.cursor()
insert_inf = ("insert into dlip(ip, port, ym, kind, time)" "values (%s, %s, %s, %s, %s)")
for i in range(len(ip)):
ata_inf = (ip[i], port[i], ym[i], kind[i], time1[i])
cursor.execute(insert_inf, data_inf)
conn.commit() # 提交事务
conn.close()
except :
s = sys.exc_info()
print("Error '%s' happened on line %d" % (s[1], s[2].tb_lineno)) # 打印错误信息
print('connect mysql error.')
上述就是将数据写入数据库的操作,值得注意的是cursor不可以重复使用,还有try后一定要打印错误日志要不然bug可能会逼疯你…
分页实战快代理
前面讲了分页操作及数据库存取操作,我下面给出整个流程完整代码
import requests
from fake_useragent import UserAgent # 这个包以前未讲 ,主要用来获取虚拟请求头的
import re
import pymysql
import sys
import time
un = UserAgent()
for i in range(1,11):
print(f'当前正在爬取第{i}页')
# 定义请求url
time.sleep(2)
url = 'https://www.kuaidaili.com/free/inha/'+str(i)+'/'
# 定义请求头
headers = {
'User-Agent':un.random
}
# 发起get请求
res = requests.get(url=url, headers=headers)
if res.status_code == 200:
# print('请求成功')
# 获取ip地址
reg = '(.*) '
ip = re.findall(reg,res.text)
# 获取端口号
reg = '(.*) '
port = re.findall(reg, res.text)
# 隐秘度
reg = '(.*) '
ym = re.findall(reg, res.text)
# 类型
reg = '(.*) '
kind = re.findall(reg, res.text)
# 最后验证时间
reg = '(.*) '
time1 = re.findall(reg, res.text)
# 将数据写入数据库
try:
conn = pymysql.connect(host="127.0.0.1", user='root', port=3306, passwd='root', db='db1', charset='utf8')
cursor = conn.cursor()
insert_inf = ("insert into dlip(ip, port, ym, kind, time)" "values (%s, %s, %s, %s, %s)")
for i in range(len(ip)):
data_inf = (ip[i], port[i], ym[i], kind[i], time1[i])
cursor.execute(insert_inf, data_inf)
conn.commit()
conn.close()
except :
s = sys.exc_info()
print("Error '%s' happened on line %d" % (s[1], s[2].tb_lineno))
print('connect mysql error.')
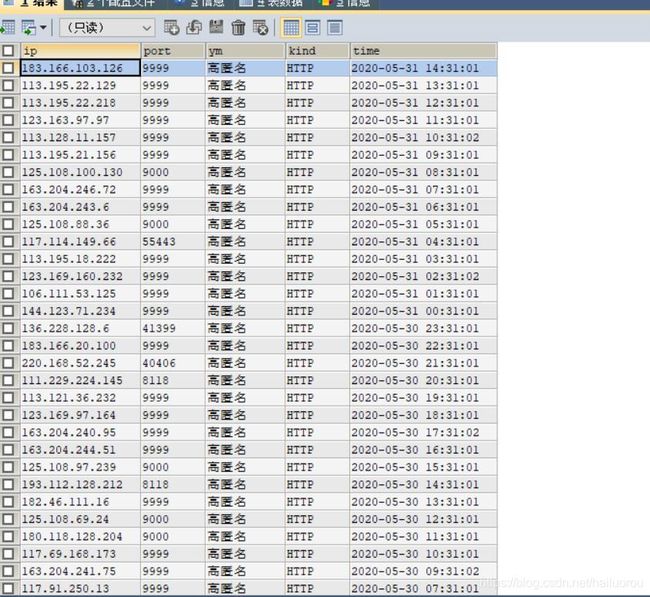
此时获取的ip就全部存入了数据库。
重磅!爬虫爬取妹子图
前面讲述了爬虫爬取数据但没有讲述如何下载图片我们最后进行学习
废话不多直接给出代码,各位小伙伴去分析吧
import requests
import os
def getPage(kw, num):
params = []
for i in range(30, 30*num+30,30):
params.append({
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': '201326592',
'is':'',
'fp': 'result',
'queryWord': kw,
'cl': '2',
'lm': '-1',
'ie': 'utf - 8',
'oe': 'utf - 8',
'adpicid':'',
'st':'',
'z':'',
'ic':'',
'hd':'',
'latest':'',
'copyright':'',
'word': kw,
's':'',
'se':'',
'tab':'',
'width':'',
'height':'',
'face':'',
'istype':'',
'qc':'',
'nc':'',
'fr':'',
'expermode':'',
'force':'',
'cg': 'girl',
'pn': '90',
'rn': '30',
'gsm': '5a',
'1590936486366':'',
})
url = 'https://image.baidu.com/search/acjson'
urls = []
for i in params:
# 向每一个url发起请求
res = requests.get(url=url, params=i).json()['data']
# 获取请求数据
urls.append(res)
return urls
def downloadImg(datalist, dir):
# 检测文件夹是否存在
if not os.path.exists(dir):
os.mkdir(dir)
# 循环下在文件数据
x = 0
for data in datalist:
for i in data:
if i.get('thumbURL') != None:
print(f'下载图片{i.get("thumbURL")}')
# 发请求
imgres = requests.get(i.get("thumbURL"))
with open(dir+f'{x}.jpg', 'wb')as f:
f.write(imgres.content)
x += 1
# 获取用户输入信息
keyword = input('请输入搜索图片的关键字:')
# 调用函数进行数据爬取 ,可指定关键字和下载页数
datalist = getPage(keyword, 2)
# 调用函数,保存数据, 可以指定要保存的图片路劲
# downloadImg(datalist,'F:\\baidu')
# 检测文件夹是否存在
if not os.path.exists('F:\\baidu'):
os.mkdir('F:\\baidu')
# 循环下在文件数据
x = 0
for data in datalist:
for i in data:
if i.get('thumbURL') != None:
print(f'下载图片{i.get("thumbURL")}')
# 发请求
imgres = requests.get(i.get("thumbURL"))
print(requests.get(i.get("thumbURL")))
open(f'F:\\baidu\\{x}.jpg', 'wb').write(imgres.content)
x += 1
至于效果如何请各位小伙伴自行探索。
原创不易若有帮助点赞支持!