Tensorflow内存溢出问题
本文总结了Tensorflow内存溢出的各种原因,以及在此排查过程中使用的方法。
本文在实现Tensorflow模型的保存(save)和重新调用(restore)过程中,程序总是发生内存溢出而中止的问题,所以对其进行故障排查。
排查工具及步骤
1. Tensorboard
Tensorboard是Tensorflow提供的向用户展示模型结构以及运行结果等的可视化工具。当Tensorflow相关程序发生内存溢出,并且确认程序所使用的数据量并不大时,首先想到使用Tensorboard对模型结构进行可视化,在此之前,需要对模型中的各个变量(variable, placeholder)、节点(nodes)、以及节点域进行命名,从而方便可视化后对模型各个部分的辨别和故障排查。例如:
import tensorflow as tf
with tf.name_scope('Input'):
batchX_placeholder = tf.placeholder(tf.float32, [input_size, look_back], name='Input_Placeholder')
batchY_placeholder = tf.placeholder(tf.float32, [output_size, look_back], name='Output_Placeholder')
这段代码对应在Tensorboard中如下图所示:
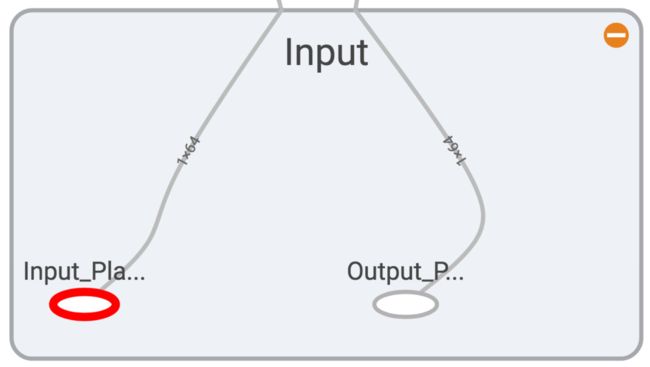
input nodes.png
类似地,搭建出整个模型的结构图之后,通过如下代码将图保存在文件当中,之后就可以通过tensorboard --logdir=filedir --host=127.0.0.1运行Tensorboard,并使用浏览器打开。
train_writer = tf.summary.FileWriter('graph', sess.graph) # save the graph
完成以上步骤后,进行核对,发现graph的结构会随着程序运行逐渐变大,原因在于在生成新的结构时,没有将之前的结构删去,于是,通过如下代码,每次生成新的图时,将之前的结构重置(删去):
tf.reset_default_graph() # reset the previous graph and nodes
结果:Graph不再随着新的模型声明而积累旧的结构,内存溢出问题得到缓解,但并没有完全解决。
2. 内存监视
在查找了程序书写结构上的问题之后,没有什么头绪,于是尝试监视内存查看程序运行问题。
import psutil
def memory_monitor():
# https://github.com/giampaolo/psutil
# 1. virtual_memory():
# total: total physical memory.
# available: the memory that can be given instantly to processes without the system going into swap.
# This is calculated by summing different memory values depending on the platform and it
# is supposed to be used to monitor actual memory usage in a cross platform fashion.
# 2. swap_memory():
# total: total swap memory in bytes
# used: used swap memory in bytes
print psutil.virtual_memory()
print psutil.swap_memory()
将该函数插入到想要查看当前内存使用情况的位置,但是没有任何发现。
3. 给Tensorflow结构分配给不同的GPU
因为之前Tensorflow的结构是使用CPU进行运行,猜想如果将Tensorflow运算分配给不同的GPU,是否可以解决内存溢出的问题。
分配GPU和CPU的原则是,并行结构和运算分配给不同的GPU,主线运算分配给CPU。
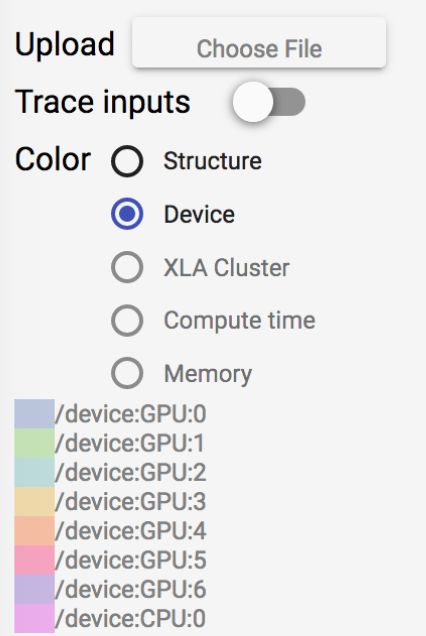
tensorboard-gpu.png
如图所示,可以通过打开Tensorboard中的Device开关,可以在Graph中不同结构标识不同的device。
同样的,内存溢出的问题并没有得到解决。
4. 查看不同变量类型的增长情况以及调用结构
为了进一步查找导致内存溢出的增长源,采用python的gc模块对程序运行过程中的不同变量类型的增长情况以及调用结构进行分析。代码如下:
import objgraph
objgraph.show_growth() # show the growth of the objects
objgraph.show_refs(variableName, filename='graph.png') # show the reference structure of the variable
通过将show_growth()放置在程序单次循环的末尾,以及查看每次循环所带来的变量类型的增长情况进行分析,发现在Tensorflow模型的训练以及预测过程中,Tensor类型的变量数在不断增加,这就是导致内存溢出的关键。
其间,使用了gc.collect()对垃圾进行手动回收,但是没有解决问题。
虽然程序已经包含了之前的tf.reset_default_graph,但是变量数却在增加,这点非常奇怪。为了进一步排除问题的可能性,重新声明一个新的测试类,只包含了模型的声明,测试类的结构和调用方式仿照存在内存溢出问题的类,如下所示:
class testClass(object):
def __init__(self):
pass
def test1(self, CF):
print '------------------------'
objgraph.show_growth()
tf.reset_default_graph()
'''Establish the model'''
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
sess.close()
objgraph.show_growth()
def test2(self, CF):
print '------------------------'
objgraph.show_growth()
tf.reset_default_graph()
'''Establish the model'''
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
sess.close()
objgraph.show_growth()
经过测试发现,sess虽然是局部变量,但是如果不对sess进行close操作,那么之前所有的graph, nodes, variables等等Tensor将会全部被保留下来,(尽管已经完成了reset_default_graph),找到了根源之后,添加close操作,再通过show_growth可以观察到,在重复调用test1和test2时,内存不会产生之前无用的消耗和溢出。
至此,完成了对tensorflow内存溢出问题的排查和调试。
总结:
出现内存溢出问题,可能的原因有很多种,对于机器学习程序,从数据和模型两方面进行入手,首先确认数据的处理、调用等是否存在内存溢出的问题,这部分可以通过objgraph模块内的相关函数对其进行调试和排查;其次需要对Tensorflow的模型进行核查,是否存在旧的节点和图未删去、Session使用后未关闭等问题。
作者:惊鸿指尖
链接:https://www.jianshu.com/p/bbc508f3c5f1
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。