2020天池大数据-智慧海洋建设方案赛分享
初赛(2020年1月2日—2020年2月21日),复赛(2020年2月25日—2020年3月22日),baseline准确度0.7843,太低~,这个题目围绕“智慧海洋建设,赋能海上安全治理能力现代化”。要求选手通过分析渔船北斗设备位置数据,判断出是拖网作业、围网作业还是流刺网作业。其实总结就是“轨迹(序列数据)+多分类”的任务,比较常规,主要还是特征提取和处理上面,复杂的在于位置信息处理;
一、赛题理解
以下是拖网、围网、刺网的示意图。
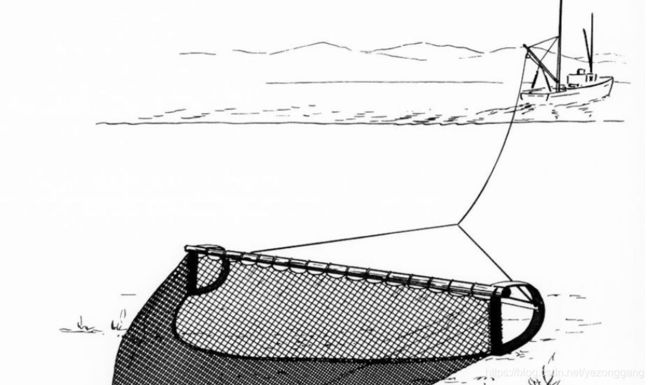
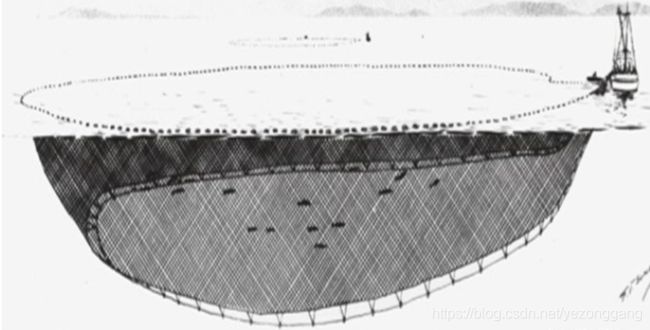

渔船的状态包括:Anchored-off:船舶休息的点;Turning:船舶转弯的点;Straight-sailing:船舶航行的点

二、数据预处理和特征工程
1)、使用PCA算法变换x和y(旋转变换),分别统计每个ship中变换后的x和y的最大值(x_max,y_max)、最小值(x_min,y_min)、平均值(x_mean,y_mean)、
和众数(x_mode,y_mode)、以及x_mode与y_mode相乘的交互特征(刻画渔船频繁出现的位置特征);同理,对x,y的旋转特征(x_pca,y_pca)进行了同样的提取特征的操作。
2)、添加对渔船频繁点刻画的特征。根据经纬度的精度,分别对将原纬度和PCA变换后的纬度乘10的3次幂,分别再加上原经度,得到sign和sign_pca用于后面的特征。分别计算sign和sign_pca的众数sign_mode与sign_pca_mode(刻画频繁出现的位置);
3)、根据EDA发现刺网渔船作业的分散性较围网与拖网低,即刺网渔船会在局部集中的海域活动,为刻画这种行为,用每个ship的sign的nunique(即渔船经过的不同位置的数量)除以len(sign)(记录的总数量),以该特征描述渔船运动的分散性,得到sign_nunique;根据sign_nunique特征的分布,再继续对sign_nunique进行分箱处理,小于0.2 置0、大于0.2小于0.63置1、其余的置3;
4)、分别计算每个ship中速度大于0小于等于2、大于2小于等于6、大于6小于等于10的比例和平均值,三种区间代表三种运动状态,以每个区间中的平均速度代表该船在该运动状态下的速度描述(根据速度的分布图选择的对速度的分箱方式)。
5)、为了描述频繁点处的其他信息,统计了sign_mode的count特征(作为频繁点处的先验信息),以及不同的运动状态的速度的均值(即统计相同的频繁点处的3种运动状态速度的平均值)。
6)、计算每个ship中角度的平均值。
7)、利用原数据'time'特征,提取其‘分钟’特征,计算其最大值。
8)、时间差的平均值。
9)、时间差的分位数。
10)、时间差的中位数。
11)、以速度大于4的连续运动片段作为工作状态,计算每个ship中的工作状态片段并计算每个片段的位移作为作业间隔,统计每个ship中的作业间隔的中位数特征
12)、数据处理:skew较大的特征sign_pca_mode使用log函数将其正态化;与速度相关的特征保留其两位有效数字。
13)、设计了拐角特征,并统计每艘船的三种拐角形式的数量,均值作为特征。
14)、总体模型特征为42个
三、模型训练调优/代码
import pandas as pd
import numpy as np
from lightgbm.sklearn import LGBMClassifier
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import f1_score
from gensim.models import Word2Vec
from scipy import sparse
from tqdm import tqdm
import os
import gc
import time
import warnings
warnings.filterwarnings('ignore')
label_dict1 = {'拖网': 0, '围网': 1, '刺网': 2}
label_dict2 = {0: '拖网', 1: '围网', 2: '刺网'}
name_dict = {'渔船ID': 'id', '速度': 'v', '方向': 'dir', 'type': 'label', 'lat': 'x', 'lon': 'y'}
def get_data(file_path, model):
paths = os.listdir(file_path)
tmp = open(f'{model}.csv', 'w', encoding='utf-8')
for t in tqdm(range(len(paths))):
p = paths[t]
with open(f'{file_path}/{p}', encoding='utf-8') as f:
if t!=0:
next(f)
tmp.write(f.read())
tmp.close()
ttt = time.time()
get_data('/tcdata/hy_round2_train_20200225', 'train')
get_data('/tcdata/hy_round2_testA_20200225', 'testA')
get_data('/tcdata/hy_round2_testB_20200312', 'testB')
get_data('/tcdata/hy_round1_train_20200102', 'train_chusai')
train = pd.read_csv('train.csv')
train['flag'] = 0
train['trn'] = 1
test = pd.read_csv('testB.csv')
test['flag'] = 0
test['trn'] = 0
testA = pd.read_csv('testA.csv')
testA['flag'] = 1
testA['trn'] = 0
train_chusai = pd.read_csv('train_chusai.csv')
train_chusai['flag'] = 1
train_chusai['trn'] = 1
print(time.time() - ttt)
train.rename(columns = name_dict, inplace = True)
test.rename(columns = name_dict, inplace = True)
testA.rename(columns = name_dict, inplace = True)
train_chusai.rename(columns = name_dict, inplace = True)
df = pd.concat([train, testA, test], axis=0, ignore_index=True)
df['x'] = df['x'] * 100000 - 5630000
df['y'] = df['y'] * 110000 + 2530000
df = pd.concat([train_chusai, df], axis=0, ignore_index=True)
df['time'] = pd.to_datetime(df['time'].apply(lambda x :'2019-'+ x[:2] + '-' + x[2:4] + ' ' + x[5:]))
df = df.sort_values(['id', 'time']).reset_index(drop=True)
df['label'] = df['label'].map(label_dict1)
df.loc[df['trn'] == 0, 'label'] = -1
print(time.time() - ttt)
df['v_bin'] = pd.qcut(df['v'], 200, duplicates='drop')
df['v_bin'] = df['v_bin'].map(dict(zip(df['v_bin'].unique(), range(df['v_bin'].nunique()))))
for f in ['x', 'y']:
df[f + '_bin1'] = pd.qcut(df[f], 1000, duplicates='drop')
df[f + '_bin1'] = df[f + '_bin1'].map(dict(zip(df[f + '_bin1'].unique(), range(df[f + '_bin1'].nunique()))))
df[f + '_bin2'] = df[f] // 10000
df[f + '_bin1_count'] = df[f + '_bin1'].map(df[f + '_bin1'].value_counts())
df[f + '_bin2_count'] = df[f + '_bin2'].map(df[f + '_bin2'].value_counts())
df[f + '_bin1_id_nunique'] = df.groupby(f + '_bin1')['id'].transform('nunique')
df[f + '_bin2_id_nunique'] = df.groupby(f + '_bin2')['id'].transform('nunique')
for i in [1, 2]:
df['x_y_bin{}'.format(i)] = df['x_bin{}'.format(i)].astype('str') + '_' + df['y_bin{}'.format(i)].astype('str')
df['x_y_bin{}'.format(i)] = df['x_y_bin{}'.format(i)].map(
dict(zip(df['x_y_bin{}'.format(i)].unique(), range(df['x_y_bin{}'.format(i)].nunique())))
)
df['x_bin{}_y_bin{}_count'.format(i, i)] = df['x_y_bin{}'.format(i)].map(df['x_y_bin{}'.format(i)].value_counts())
for stat in ['max', 'min']:
df['x_y_{}'.format(stat)] = df['y'] - df.groupby('x_bin1')['y'].transform(stat)
df['y_x_{}'.format(stat)] = df['x'] - df.groupby('y_bin1')['x'].transform(stat)
print(time.time() - ttt)
g = df.groupby('id')
for f in ['x', 'y']:
df[f + '_prev_diff'] = df[f] - g[f].shift(1)
df[f + '_next_diff'] = df[f] - g[f].shift(-1)
df[f + '_prev_next_diff'] = g[f].shift(1) - g[f].shift(-1)
df['dist_move_prev'] = np.sqrt(np.square(df['x_prev_diff']) + np.square(df['y_prev_diff']))
df['dist_move_next'] = np.sqrt(np.square(df['x_next_diff']) + np.square(df['y_next_diff']))
df['dist_move_prev_next'] = np.sqrt(np.square(df['x_prev_next_diff']) + np.square(df['y_prev_next_diff']))
df['dist_move_prev_bin'] = pd.qcut(df['dist_move_prev'], 50, duplicates='drop')
df['dist_move_prev_bin'] = df['dist_move_prev_bin'].map(
dict(zip(df['dist_move_prev_bin'].unique(), range(df['dist_move_prev_bin'].nunique())))
)
print(time.time() - ttt)
def get_loc_list(x):
prev = ''
res = []
for loc in x:
loc = str(loc)
if loc != prev:
res.append(loc)
prev = loc
return res
size = 10
sentence = df.groupby('id')['x_y_bin1'].agg(get_loc_list).tolist()
model = Word2Vec(sentence, size=size, window=20, min_count=1, sg=1, workers=12, iter=10)
emb = []
for w in df['x_y_bin1'].unique():
vec = [w]
try:
vec.extend(model[str(w)])
except:
vec.extend(np.ones(size) * -size)
emb.append(vec)
emb_df = pd.DataFrame(emb)
emb_cols = ['x_y_bin1']
for i in range(size):
emb_cols.append('x_y_bin1_emb_{}'.format(i))
emb_df.columns = emb_cols
print(time.time() - ttt)
def start(x):
try:
return x[0]
except:
return None
def end(x):
try:
return x[-1]
except:
return None
def mode(x):
try:
return pd.Series(x).value_counts().index[0]
except:
return None
df = df[df['flag'] == 0].reset_index(drop=True)
for f in ['dist_move_prev_bin', 'v_bin']:
df[f + '_sen'] = df['id'].map(df.groupby('id')[f].agg(lambda x: ','.join(x.astype(str))))
g = df.groupby('id').agg({
'id': ['count'], 'x_bin1': [mode], 'y_bin1': [mode], 'x_bin2': [mode], 'y_bin2': [mode], 'x_y_bin1': [mode],
'x': ['mean', 'max', 'min', 'std', np.ptp, start, end],
'y': ['mean', 'max', 'min', 'std', np.ptp, start, end],
'v': ['mean', 'max', 'min', 'std', np.ptp], 'dir': ['mean'],
'x_bin1_count': ['mean'], 'y_bin1_count': ['mean', 'max', 'min'],
'x_bin2_count': ['mean', 'max', 'min'], 'y_bin2_count': ['mean', 'max', 'min'],
'x_bin1_y_bin1_count': ['mean', 'max', 'min'],
'dist_move_prev': ['mean', 'max', 'std', 'min', 'sum'],
'x_y_min': ['mean', 'min'], 'y_x_min': ['mean', 'min'],
'x_y_max': ['mean', 'min'], 'y_x_max': ['mean', 'min'],
}).reset_index()
g.columns = ['_'.join(col).strip() for col in g.columns]
g.rename(columns={'id_': 'id'}, inplace=True)
cols = [f for f in g.keys() if f != 'id']
print(time.time() - ttt)
df = df.drop_duplicates('id')[['id', 'label', 'dist_move_prev_bin_sen', 'v_bin_sen']].sort_values('id').reset_index(drop=True)
df = df.sort_values('label').reset_index(drop=True)
sub = df[df['label'] == -1].reset_index(drop=True)[['id']]
test_num = sub.shape[0]
labels = df[df['label'] != -1]['label'].values
df = df.merge(g, on='id', how='left')
df[cols] = df[cols].astype('float32')
df['dist_total'] = np.sqrt(np.square(df['x_end'] - df['y_start']) + np.square(df['y_end'] - df['y_start']))
df['dist_rate'] = df['dist_total'] / (df['dist_move_prev_sum'] + 1e-8)
df = df.merge(emb_df, left_on='x_y_bin1_mode', right_on='x_y_bin1', how='left')
df_values = sparse.csr_matrix(df[cols + emb_cols[1:] + ['dist_total', 'dist_rate']].values)
for f in ['dist_move_prev_bin_sen', 'v_bin_sen']:
cv = CountVectorizer(min_df=10).fit_transform(df[f].values)
df_values = sparse.hstack((df_values, cv), 'csr')
test_values, train_values = df_values[:test_num], df_values[test_num:]
del df, df_values
gc.collect()
print(time.time() - ttt)
def f1(y_true, y_pred):
y_pred = np.transpose(np.reshape(y_pred, [3, -1]))
return 'f1', f1_score(y_true, np.argmax(y_pred, axis=1), average='macro'), True
print(train_values.shape, test_values.shape)
test_pred = np.zeros((test_values.shape[0], 3))
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=2020)
clf = LGBMClassifier(
learning_rate=0.05,
n_estimators=20000,
num_leaves=63,
subsample_freq=1,
subsample=0.9,
colsample_bytree=0.4,
min_child_samples=10,
random_state=2020,
class_weight='balanced',
metric='None'
)
for i, (trn_idx, val_idx) in enumerate(skf.split(train_values, labels)):
trn_x, trn_y = train_values[trn_idx], labels[trn_idx]
val_x, val_y = train_values[val_idx], labels[val_idx]
clf.fit(
trn_x, trn_y,
eval_set=[(val_x, val_y)],
eval_metric=f1,
early_stopping_rounds=100,
verbose=100
)
test_pred += clf.predict_proba(test_values) / skf.n_splits
sub['id'] = sub['id'].astype('int32')
sub['label'] = np.argmax(test_pred, axis=1)
sub['label'] = sub['label'].map(label_dict2)
sub = sub.sort_values('id').reset_index(drop=True)
sub.to_csv('result.csv', index=False, header=False)