论文阅读:Why Can’t I Dance in the Mall Learning to Mitigate Scene Bias in Action Recognition
目录
Background
How To Do
网络的整体框架
Result
Question(Things To Do)
论文下载地址:https://arxiv.org/abs/1912.05534
code:https://github.com/vt-vl-lab/SDN
project website:http://chengao.vision/SDN/
Background

作者意识到进行 Action Recognition 的 CNN 光识别场景,不需要关注人的动作就可以对其分类,但是这样容易导致 scene bias,从而导致鲁棒性不强。所以他们提出一种类似 GAN 的 debiasing 的动作识别方法,让模型更加关注动作本身,而不是动作所在的场景。
How To Do
作者对 Loss 进行了改进,除了有平常对动作进行分类的 Cross Entropy Loss 部分,还设计了两个 Loss:
- a scene-adversarial loss
- a human mask confusion loss
We use a scene-adversarial loss to obtain scene-invariant feature representation. We use a human mask confusion loss to encourage a network to be unable to predict correct actions when there is no visual evidence.
意思就是作者希望通过 scene-adversarial loss 来学习到一种“场景不变性”(不依赖于场景)的特征;希望通过 human mask confusion loss,让网络无法根据带有 human mask 的视频判断动作的类别,从而迫使网络更集中关注动作本身。
首先,作者给出了如何计算一个 Dataset 的 scene representation bias:
![]()
is a scene representation;
M(D,
is a random chance action classification accuracy on the dataset D
作者还给了一个计算例子:比如用一个在 Places365(一个场景分类数据集) 上 pretrain 好的 ResNet-50 模型,再在其 2048 个维度的特征后接一个线性分类器,对 UCF101(一个动作分类数据集)里的视频进行动作分类的训练,最后正确率可达 59.7%;而对该数据集进行随机分类的正确率约为 1%(1/101)。那么,这个 UCF101 数据集的 scene representation bias 就是 log(59.7/1.0) = 4.09. 一个 completely unbiased 的数据集,其 scene representation bias 应该为 log(1.0/1.0) = 0.
网络的整体框架
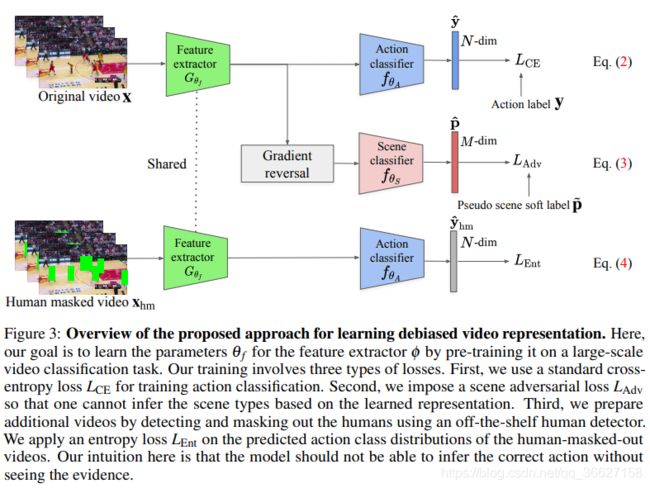
本篇文章的训练目标是得到一个尽可能只关注动作本身的 feature extractor G 的参数 ![]() 。
。
首先是标准的动作分类交叉损失熵函数:
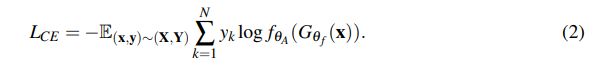
其中,N 是动作类别总数。
接着是 scene adversarial loss(![]() ),用来 penalizes the model if it could infer the scene types based on the learned representation
),用来 penalizes the model if it could infer the scene types based on the learned representation
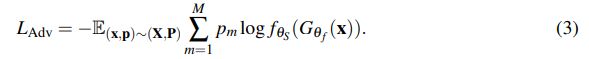
其中,M 是场景类别总数。这一项 Loss 越大,说明越无法确定场景的类型; Loss 越小,说明越确定是哪一种场景。所以我们希望这一项 Loss 越大越好。
最后是 human mask confusion loss(![]() ),用来 penalizes the model if it could predict the actions when the humans in the video are masked-out,也就是说当输入一个 human-masked-out video 时,我们要最大化预测动作分类的信息熵分布。
),用来 penalizes the model if it could predict the actions when the humans in the video are masked-out,也就是说当输入一个 human-masked-out video 时,我们要最大化预测动作分类的信息熵分布。
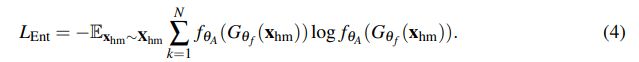
这一项 Loss 越大,说明越无法确定 human-masked-out video 的动作类别,也正是我们希望的结果:更关注动作本身。
那么总的优化过程如下:
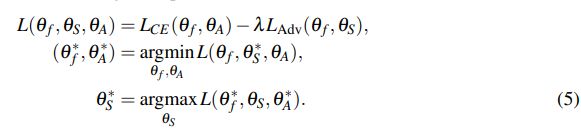
第一条公式的意思是:我们希望 (动作分类的损失)越小越好,![]() (场景分类的损失)越大越好,所以
(场景分类的损失)越大越好,所以 ![]() 前有一个 −λ ,所以总体的 L 越小越好。
前有一个 −λ ,所以总体的 L 越小越好。
第二条公式的意思是:固定场景分类器 ![]() 的参数时,希望得到能使总体的 L 越小越好的特征提取器
的参数时,希望得到能使总体的 L 越小越好的特征提取器 ![]() 和动作分类器
和动作分类器 ![]() 参数
参数
第三条公式的意思是(我这里还有点不太明白,同实验室的大神解释):有点像 GAN 中的 Discriminator,主要目的是让模型得到一个分不清场景的特征提取器 ![]()
文章中提到使用 GRL(gradient reversal layer)来进行这种对抗性的训练,这里待深入了解。
当输入是一个 human-masked-out video 时,优化过程如下:
![]()
每个 iteration 中,(5)、(6)交替优化,在代码中体现如下:
# # ------------------------------------------------
# # Train using Action CE loss and Place ADV loss
# # ------------------------------------------------
if opt.model == 'vgg':
inputs_unmasked = inputs_unmasked.squeeze()
inputs_unmasked = Variable(inputs_unmasked)
targets_unmasked = Variable(targets_unmasked)
if opt.is_mask_entropy:
if opt.is_place_adv:
if opt.is_mask_adv:
outputs_unmasked, outputs_places_unmasked, outputs_rev_unmasked = model (inputs_unmasked)
else:
outputs_unmasked, outputs_places_unmasked = model(inputs_unmasked)
else:
if opt.is_mask_adv:
outputs_unmasked, outputs_rev_unmasked = model(inputs_unmasked)
else:
outputs_unmasked = model(inputs_unmasked)
elif opt.is_mask_cross_entropy:
if opt.is_place_adv:
outputs_unmasked, outputs_places_unmasked, outputs_rev_unmasked = model (inputs_unmasked)
else:
outputs_unmasked, outputs_rev_unmasked = model(inputs_unmasked)
loss_act = criterions['action_cross_entropy'](outputs_unmasked, targets_unmasked)
if opt.is_place_adv:
loss_place = criterions['places_cross_entropy'](outputs_places_unmasked, places_unmasked)
if opt.is_place_entropy and epoch>=opt.warm_up_epochs:
loss_place_entropy = criterions['places_entropy'](outputs_places_unmasked)
loss = loss_act + loss_place + opt.weight_entropy_loss*loss_place_entropy
else:
loss = loss_act + loss_place # 为什么是 + loss_place
else:
if opt.is_place_entropy and epoch>=opt.warm_up_epochs:
loss_place_entropy = criterions['places_entropy'](outputs_places_unmasked)
loss = loss_act + opt.weight_entropy_loss*loss_place_entropy
else:
loss = loss_act
if torch_version < 0.4:
acc = calculate_accuracy(outputs_unmasked, targets_unmasked)
losses.update(loss.data[0], inputs_unmasked.size(0))
else:
act_acc = calculate_accuracy_pt_0_4(outputs_unmasked, targets_unmasked)
if opt.is_place_adv:
if opt.is_place_soft:
_, places_hard_target = torch.max(places_unmasked, 1)
place_acc = calculate_accuracy_pt_0_4(outputs_places_unmasked, places_hard_target)
else:
place_acc = calculate_accuracy_pt_0_4(outputs_places_unmasked, places_unmasked)
place_losses.update(loss_place.item(), inputs_unmasked.size(0))
else:
place_losses.update(0, inputs_unmasked.size(0))
losses.update(loss.item(), inputs_unmasked.size(0))
act_losses.update(loss_act.item(), inputs_unmasked.size(0))
if opt.is_place_entropy and epoch>=opt.warm_up_epochs:
place_entropy_losses.update(loss_place_entropy.item(), inputs_unmasked.size(0))
act_accuracies.update(act_acc, inputs_unmasked.size(0))
if opt.is_place_adv:
place_accuracies.update(place_acc, inputs_unmasked.size(0))
else:
place_accuracies.update(0, inputs_unmasked.size(0))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# -------------------------------------------------
# Train using Mask Action Entropy loss (maximize)
# -------------------------------------------------
print('num of actual masking_inds = {}/{}'.format(torch.sum(maskings), maskings.shape[0]))
if opt.model == 'vgg':
inputs_masked = inputs_masked.squeeze()
inputs_masked = Variable(inputs_masked)
targets_masked = Variable(targets_masked)
if opt.is_mask_entropy:
if opt.is_place_adv:
if opt.is_mask_adv:
outputs_masked, outputs_places_masked, outputs_rev_masked = model(inputs_masked)
else:
outputs_masked, outputs_places_masked = model(inputs_masked)
else:
if opt.is_mask_adv:
outputs_masked, outputs_rev_masked = model(inputs_masked)
else:
outputs_masked = model(inputs_masked)
elif opt.is_mask_cross_entropy:
if opt.is_place_adv:
outputs_masked, outputs_places_masked, outputs_rev_masked = model(inputs_masked)
else:
outputs_masked, outputs_rev_masked = model(inputs_masked)
if opt.is_mask_entropy:
if opt.is_mask_adv:
loss_action_entropy = criterions['mask_criterion'](outputs_rev_masked)
else:
loss_action_entropy = criterions['mask_criterion'](outputs_masked)
msk_loss = loss_action_entropy
elif opt.is_mask_cross_entropy:
loss_action_cross_entropy = criterions['mask_criterion'](outputs_rev_masked, targets_masked)
msk_loss = loss_action_cross_entropy
if torch_version < 0.4:
if opt.is_mask_adv:
acc = calculate_accuracy(outputs_rev_masked, targets_masked)
else:
acc = calculate_accuracy(outputs_masked, targets_masked)
else:
if opt.is_mask_adv:
msk_act_acc = calculate_accuracy_pt_0_4(outputs_rev_masked, targets_masked)
else:
msk_act_acc = calculate_accuracy_pt_0_4(outputs_masked, targets_masked)
msk_act_losses.update(msk_loss.item(), inputs_masked.size(0))
msk_act_accuracies.update(msk_act_acc, inputs_masked.size(0))
optimizer.zero_grad()
msk_loss.backward()
optimizer.step()
Result

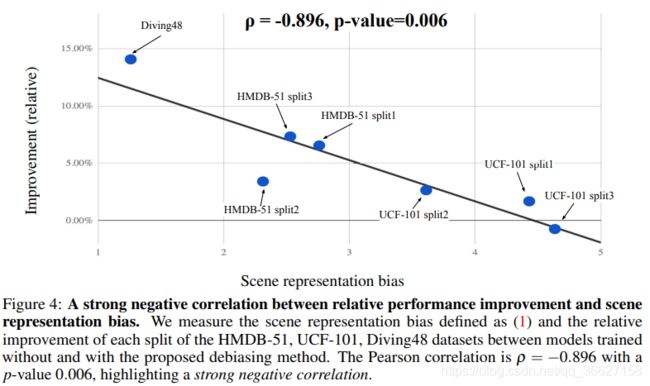
这一幅图最开始有点没看懂,不明白为什么 scene representation bias 越大,反而 debias 后相对提升的效果越小呢?
后来看到后面才知道:
The Pearson correlation is ρ = −0.896 with a p-value 0.006, highlighting a strong negative correlation between the relative performance improvement and the scene representation bias.
Our results show that if a model is pre-trained with debiasing, the model generalizes better to the datasets with less scene bias, as the model pays attention to the actual action.
In contrast, if a model is pre-trained on a dataset with a significant scene bias e.g., Kinetics without any debiasing, the model would be biased towards certain scene context. Such a model may still work well on target dataset with strong scene biases (e.g., UCF-101), but does not generalize well to other less biased target datasets (e.g., Diving48 and HMDB-51).
意思就是说:
模型本身在有着非常大 significant scene bias 的数据集(如 Kinetics)上 pretrain,导致模型会偏向特定的某些场景。这个时候再放到同样有着较大 significant scene bias 的数据集(如 UCF-101)上 fine-tune 的话,也可以得到不错的结果(因为学习到了 scene bias);而放到有着较小 significant scene bias 的数据集(如 Diving48)上 fine-tune 的话,效果会很差,因为可能没有类似的场景。
所以,这个时候如果改成在 debiased 数据集上 pretrain 好的话,再在有着较小 significant scene bias 的数据集(如 Diving48)上 fine-tune,性能会有很大提升,因为已经 debiased 了,没有见过类似的场景也没有关系,relative performance improvement between models trained without and with the proposed debiasing method 就会比较大;而在有着较大 significant scene bias 的数据集(如 UCF-101)上 fine-tune 的话,性能提升会相对小一些,因为本身在没有 debiased 的数据集上性能就已经很高了,所以模型即使 debiased 了,提升得也不过多,relative performance improvement between models trained without and with the proposed debiasing method 就会比较小。
所以总体来说,是更 generalized 的。
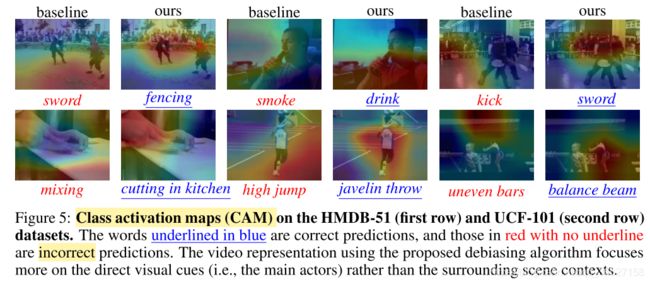
CAM 可视化后的结果
Question(Things To Do)
1、优化函数中的 argmax 在代码中如何体现?
2、总的 Loss 公式中的 −λ 没有体现出来,尤其是负号?
3、深入了解 GRL(gradient reversal layer)
4、CAM