cp13_Parallelizing NN Training w TF_printoptions(precision)_squeeze_shuffle_batch_repeat_image处理_map
In this chapter, we will move on from the mathematical foundations of machine learning and deep learning to focus on TensorFlow. TensorFlow is one of the most popular deep learning libraries currently available, and it lets us implement neural networks (NNs) much more efficiently than any of our previous NumPy implementations. In this chapter, we will start using TensorFlow and see how it brings significant benefits to training performance.
This chapter will begin the next stage of our journey into machine learning and deep learning, and we will explore the following topics:
- • How TensorFlow improves training performance
- • Working with TensorFlow's Dataset API (tf.data) to build input pipelines and efficient model training
- • Working with TensorFlow to write optimized machine learning code
- • Using TensorFlow high-level APIs to build a multilayer NN
- • Choosing activation functions for artificial NNs
- • Introducing Keras (tf.keras), a high-level wrapper around TensorFlow that can be used to implement common deep learning architectures conveniently
TensorFlow and training performance
TensorFlow can speed up our machine learning tasks significantly. To understand how it can do this, let's begin by discussing some of the performance challenges we typically run into when we run expensive calculations on our hardware. Then, we will take a high-level look at what TensorFlow is and what our learning approach will be in this chapter.
Performance challenges
The performance of computer processors has, of course, been continuously improving in recent years, and that allows us to train more powerful and complex learning systems, which means that we can improve the predictive performance of our machine learning models. Even the cheapest desktop computer hardware that's available right now comes with processing units that have multiple cores.
In the previous chapters, we saw that many functions in scikit-learn allow us to spread those computations over multiple processing units. However, by default, Python is limited to execution on one core due to the global interpreter lock (GIL). So, although we, indeed, take advantage of Python's multiprocessing library to distribute our computations over multiple cores, we still have to consider that the most advanced desktop hardware rarely comes with more than eight or 16 such cores.
You will recall from cp12_implement a Manual Artificial Neuron Network_gzip_mnist_struct_savez_compressed_fetch_openml_back propagation_weights update_L2https://blog.csdn.net/Linli522362242/article/details/111940633, that we implemented a very simple multilayer perceptron (MLP) with only one hidden layer consisting of 100 units.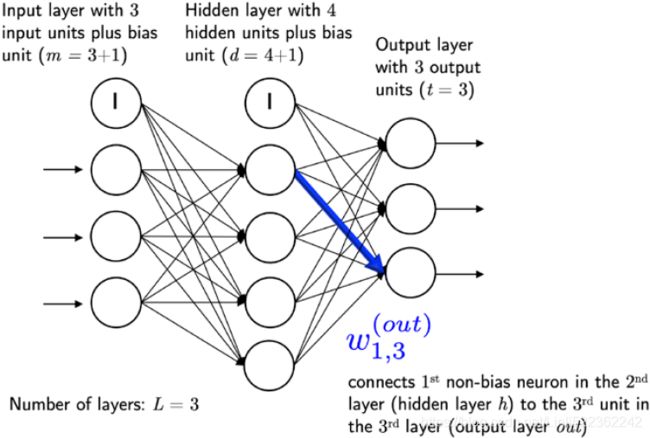 We had to optimize approximately 80,000 weight parameters ([784*100 neurons for weight coefficients + 100 neurons for bias] + [100 * 10 output classes] + 10 = 79,510, since 784 input units (n_features), 100 hidden units (n_hidden), and 10 output units (n_output)) to learn a model for a very simple image classification task. The images in MNIST are rather small (28 × 28 ), and we can only imagine the explosion in the number of parameters if we wanted to add additional hidden layers or work with images that have higher pixel densities. Such a task would quickly become unfeasible for a single processing unit. The question then becomes, how can we tackle such problems more effectively?
We had to optimize approximately 80,000 weight parameters ([784*100 neurons for weight coefficients + 100 neurons for bias] + [100 * 10 output classes] + 10 = 79,510, since 784 input units (n_features), 100 hidden units (n_hidden), and 10 output units (n_output)) to learn a model for a very simple image classification task. The images in MNIST are rather small (28 × 28 ), and we can only imagine the explosion in the number of parameters if we wanted to add additional hidden layers or work with images that have higher pixel densities. Such a task would quickly become unfeasible for a single processing unit. The question then becomes, how can we tackle such problems more effectively?
The obvious solution to this problem is to use graphics processing units (GPUs), which are real work horses. You can think of a graphics card as a small computer cluster inside your machine. Another advantage is that modern GPUs are relatively cheap compared to the state-of-the-art central processing units (CPUs), as you can see in the following overview: The sources for the information in the table are the following websites (Date: October 2019):
The sources for the information in the table are the following websites (Date: October 2019):
- • https://ark.intel.com/content/www/us/en/ark/products/189123/intel-core-i9-9960x-x-series-processor-22m-cache-up-to-4-50-ghz.html
- • https://www.nvidia.com/en-us/geforce/graphics-cards/rtx-2080-ti/
At 65 percent of the price of a modern CPU, we can get a GPU that has 272 times more cores and is capable of around 10 times more floating-point calculations per second. So, what is holding us back from utilizing GPUs for our machine learning tasks? The challenge is that writing code to target GPUs is not as simple as executing Python code in our interpreter. There are special packages, such as CUDA and OpenCL, that allow us to target the GPU. However, writing code in CUDA or OpenCL is probably not the most convenient environment for implementing and running machine learning algorithms. The good news is that this is what TensorFlow was developed for!
What is TensorFlow?
TensorFlow is a scalable and multiplatform programming interface for implementing and running machine learning algorithms, including convenience wrappers for deep learning. TensorFlow was developed by the researchers and engineers from the Google Brain team. While the main development is led by a team of researchers and software engineers at Google, its development also involves many contributions from the open source community. TensorFlow was initially built for internal use at Google, but it was subsequently released in November 2015 under a permissive open source license. Many machine learning researchers and practitioners from academia and industry have adapted TensorFlow to develop deep learning solutions.
To improve the performance of training machine learning models, TensorFlow allows execution on both CPUs and GPUs. However, its greatest performance capabilities can be discovered when using GPUs. TensorFlow supports CUDAenabled GPUs officially. Support for OpenCL-enabled devices is still experimental. However, OpenCL will likely be officially supported in the near future. TensorFlow currently supports frontend interfaces for a number of programming languages.
Luckily for us as Python users, TensorFlow's Python API is currently the most complete API, thereby it attracts many machine learning and deep learning practitioners. Furthermore, TensorFlow has an official API in C++. In addition, new tools based on TensorFlow have been released, TensorFlow.js and TensorFlow Lite, that focus on running and deploying machine learning models in a web browser and on mobile and Internet of Things (IoT) devices. The APIs in other languages, such as Java, Haskell, Node.js, and Go, are not stable yet, but the open source community and TensorFlow developers are constantly improving them.
TensorFlow is built around a computation graph composed of a set of nodes. Each node represents an operation that may have zero or more input or output. A tensor is created as a symbolic handle to refer to the input and output of these operations.
Mathematically, tensors can be understood as a generalization of scalars, vectors, matrices, and so on. More concretely, a scalar can be defined as a rank-0 tensor, a vector can be defined as a rank-1 tensor, a matrix can be defined as a rank-2 tensor, and matrices stacked in a third dimension can be defined as rank-3 tensors. But note that in TensorFlow, the values are stored in NumPy arrays, and the tensors provide references to these arrays.
To make the concept of a tensor clearer, consider the following figure, which represents tensors of ranks 0 and 1 in the first row, and tensors of ranks 2 and 3 in the second row:
In the original TensorFlow release, TensorFlow computations relied on constructing a static, directed graph to represent the data flow. As the use of static computation graphs proved to be a major friction point for many users, the TensorFlow library recently received a major overhaul全面改革 with its 2.0 version, which makes building and training NN models a lot simpler. While TensorFlow 2.0 still supports static computation graphs, it now uses dynamic computation graphs, which allows for more flexibility.
How we will learn TensorFlow
First, we are going to cover TensorFlow's programming model, in particular, creating and manipulating tensors. Then, we will see how to load data and utilize TensorFlow Dataset objects, which will allow us to iterate through a dataset efficiently. In addition, we will discuss the existing, ready-to-use datasets in the tensorflow_datasets submodule and learn how to use them.
After learning about these basics, the tf.keras API will be introduced and we will move forward to building machine learning models, learn how to compile and train the models, and learn how to save the trained models on disk for future evaluation.
First steps with TensorFlow
In this section, we will take our first steps in using the low-level TensorFlow API. After installing TensorFlow, we will cover how to create tensors in TensorFlow and different ways of manipulating them, such as changing their shape, data type, and so on.
Installing TensorFlow
Depending on how your system is set up, you can typically just use Python's pip installer and install TensorFlow from PyPI by executing the following from your terminal:
pip install tensorflow https://blog.csdn.net/Linli522362242/article/details/108037567
This will install the latest stable version, which is 2.0.0 at the time of writing. In order to ensure that the code presented in this chapter can be executed as expected, it is
recommended that you use TensorFlow 2.0.0, which can be installed by specifying the version explicitly:
pip install tensorflow==[desired-version]
In case you want to use GPUs (recommended), you need a compatible NVIDIA graphics card, along with the CUDA Toolkit and the NVIDIA cuDNN library to be installed. If your machine satisfies these requirements, you can install TensorFlow with GPU support, as follows:
pip install tensorflow-gpu
For more information about the installation and setup process, please see the official recommendations at https://www.tensorflow.org/install/gpu.
Note that TensorFlow is still under active development; therefore, every couple of months, newer versions are released with significant changes. At the time of writing
this chapter, the latest TensorFlow version is 2.0. You can verify your TensorFlow version from your terminal, as follows:
python -c 'import tensorflow as tf; print(tf.__version__)'
import tensorflow as tf
print(tf.__version__)![]()
Troubleshooting your installation of TensorFlow
If you experience problems with the installation procedure, read more about system- and platform-specific recommendations that are provided at https://www.tensorflow.org/install/.
Note that all the code in this chapter can be run on your CPU; using a GPU is entirely optional but recommended if you want to fully enjoy the benefits of TensorFlow. For example, while training some NN models on CPU could take a week, the same models could be trained in just a few hours on a modern GPU. If you have a graphics card, refer to the installation page to set it up appropriately. In addition, you may find this TensorFlow-GPU setup guide helpful, which explains how to install the NVIDIA graphics card drivers, CUDA, and cuDNN on Ubuntu (not required but recommended requirements for running TensorFlow on a GPU): https://sebastianraschka.com/pdf/books/dlb/appendix_h_cloud-computing.pdf.
Furthermore, as you will see in Chapter 17, Generative Adversarial Networks for Synthesizing New Data, you can also train your models using a GPU for free via Google Colab.
Creating tensors in TensorFlow
Now, let's consider a few different ways of creating tensors, and then see some of their properties and how to manipulate them. Firstly, we can simply create a tensor from a list or a NumPy array using the tf.convert_to_tensor function as follows:
import tensorflow as tf
import numpy as npnp.set_printoptions(precision=3)
a = np.array([1,2,3], dtype=np.int32)
b = [4,5,6]
t_a = tf.convert_to_tensor(a)
t_b = tf.convert_to_tensor(b)
print(t_a)
print(t_b)![]()
This resulted in tensors t_a and t_b, with their properties, shape=(3,) and dtype=int32, adopted from their source. Similar to NumPy arrays, we can further
see these properties:
t_ones = tf.ones((2,3))
t_ones.shape![]()
To get access to the values that a tensor refers to, we can simply call the .numpy() method on a tensor:
t_ones.numpy
Finally, creating a tensor of constant values can be done as follows:
const_tensor = tf.constant( [1.2, 5, np.pi], dtype=tf.float32 )
print( const_tensor )![]()
Manipulating the data type and shape of a tensor
Learning ways to manipulate tensors is necessary to make them compatible for input to a model or an operation. In this section, you will learn how to manipulate tensor data types and shapes via several TensorFlow functions that cast, reshape, transpose, and squeeze.
The tf.cast() function can be used to change the data type of a tensor to a desired type:
t_a_new = tf.cast(t_a, tf.int64)
print( t_a_new.dtype )![]()
As you will see in upcoming chapters, certain operations require that the input tensors have a certain number of dimensions (that is, rank) associated with a certain number of elements (shape). Thus, we might need to change the shape of a tensor, add a new dimension, or squeeze an unnecessary dimension. TensorFlow provides useful functions (or operations) to achieve this, such as tf.transpose(), tf.reshape(), and tf.squeeze(). Let's take a look at some examples:
- Transposing a tensor:
t = tf.random.uniform( shape=(3,5) ) t_tr = tf.transpose(t) print( t.shape, ' --> ', t_tr.shape )
-
Reshaping a tensor (for example, from a 1D vector to a 2D array):
t = tf.zeros((30,)) t_reshape = tf.reshape(t, shape=(5,6)) print(t_reshape.shape)
- Removing the unnecessary dimensions (dimensions that have size 1, which are not needed):
t = tf.zeros((1,2,1,4,1)) t_sqz = tf.squeeze(t, axis=(2,4)) print(t.shape, ' --> ', t_sqz.shape)
Applying mathematical operations to tensors
Applying mathematical operations, in particular linear algebra operations, is necessary for building most machine learning models. In this subsection, we will cover some widely used linear algebra operations, such as element-wise product, matrix multiplication, and computing the norm of a tensor.
First, let's instantiate two random tensors, one with uniform distribution in the range [–1, 1) and the other with a standard normal distribution:
tf.random.set_seed(1)
t1 = tf.random.uniform( shape=(5,2),
minval=-1.0,
maxval= 1.0)
t2 = tf.random.normal( shape=(5,2),
mean=0.0,
stddev=1.0)Notice that t1 and t2 have the same shape. Now, to compute the element-wise product of t1 and t2, we can use the following:
t3 = tf.multiply( t1, t2 ).numpy()
print(t3)
To compute the mean, sum, and standard deviation along a certain axis (or axes), we can use tf.math.reduce_mean(), tf.math.reduce_sum(), and tf.math.reduce_std(). For example, the mean of each column in t1 can be computed as follows:
t4 = tf.math.reduce_mean( t1, axis=0 )
print(t4)![]()
The matrix-matrix product between t1 and t2 (that is,  , where the superscript T is for transpose) can be computed by using the tf.linalg.matmul() function as follows:
, where the superscript T is for transpose) can be computed by using the tf.linalg.matmul() function as follows:
t5 = tf.linalg.matmul( t1, t2, transpose_b=True )
print(t5.numpy())
On the other hand, computing is performed by transposing t1, resulting in an array of size 2 × 2 :
t6 = tf.linalg.matmul( t1, t2, transpose_a=True )
print(t6.numpy())![]()
Finally, the tf.norm() function is useful for computing the  norm of a tensor. For example, we can calculate the
norm of a tensor. For example, we can calculate the ![]() norm of t1 as follows:
norm of t1 as follows:
norm_t1 = tf.norm(t1, ord=2, axis=1).numpy()
print( norm_t1 )![]()
To verify that this code snippet computes the ![]() norm of t1 correctly, you can compare the results with the following NumPy function: np.sqrt(np.sum(np. square(t1), axis=1)).
norm of t1 correctly, you can compare the results with the following NumPy function: np.sqrt(np.sum(np. square(t1), axis=1)).
np.sqrt( np.sum( np.square(t1),
axis=1
) )![]()
Split, stack, and concatenate tensors
In this subsection, we will cover TensorFlow operations for splitting a tensor into multiple tensors, or the reverse: stacking and concatenating multiple tensors into a single one.
Assume that we have a single tensor and we want to split it into two or more tensors. For this, TensorFlow provides a convenient tf.split() function, which divides an input tensor into a list of equally-sized tensors. We can determine the desired number of splits as an integer using the argument num_or_size_splits to split a tensor along a desired dimension specified by the axis argument. In this case, the total size of the input tensor along the specified dimension must be divisible by the desired number of splits. Alternatively, we can provide the desired sizes in a list.
Let's have a look at an example of both these options:
- • Providing the number of splits (must be divisible):
tf.random.set_seed(1) t = tf.random.uniform((6,)) print(t.numpy()) t_splits = tf.split(t,3) [item.numpy() for item in t_splits]
- • Providing the sizes of different splits:
tf.random.set_seed(1) t = tf.random.uniform((5,)) print(t.numpy()) t_splits = tf.split(t, num_or_size_splits=[3,2]) [item.numpy() for item in t_splits]
Sometimes, we are working with multiple tensors and need to concatenate or stack them to create a single tensor. In this case, TensorFlow functions such as tf.stack() and tf.concat() come in handy. For example, let's create a 1D tensor, A, containing 1s with size 3 and a 1D tensor, B, containing 0s with size 2 and concatenate them into a 1D tensor, C, of size 5:
A = tf.ones((3,))
B = tf.zeros((2,))
C = tf.concat([A,B], axis=0)
print(C.numpy())![]()
If we create 1D tensors A and B, both with size 3, then we can stack them together to form a 2D tensor, S:
A = tf.ones((3,))
B = tf.zeros((3,))
S = tf.stack([A,B], axis=1)
print(S.numpy())
The TensorFlow API has many operations that you can use for building a model, processing your data, and more. However, covering every function is outside the scope of this book, where we will focus on the most essential ones. For the full list of operations and functions, you can refer to the documentation page of TensorFlow at https://www.tensorflow.org/versions/r2.0/api_docs/python/tf.
Building input pipelines using tf.data –the TensorFlow Dataset API
When we are training a deep NN model, we usually train the model incrementally using an iterative optimization algorithm such as stochastic gradient descent, as we have seen in previous chapters.
As mentioned at the beginning of this chapter, the Keras API is a wrapper around TensorFlow for building NN models. The Keras API provides a method, .fit(), for training the models. In cases where the training dataset is rather small and can be loaded as a tensor into the memory, TensorFlow models (that are built with the Keras API) can directly use this tensor via their .fit() method for training. In typical use cases, however, when the dataset is too large to fit into the computer memory, we will need to load the data from the main storage device (for example, the hard drive or solid-state drive) in chunks, that is, batch by batch (note the use of the term "batch" instead of "mini-batch" in this chapter to stay close to the TensorFlow terminology). In addition, we may need to construct a data-processing pipeline to apply certain transformations and preprocessing steps to our data, such as mean centering, scaling, or adding noise to augment the training procedure and to prevent overfitting.
Applying preprocessing functions manually every time can be quite cumbersome. Luckily, TensorFlow provides a special class for constructing efficient and convenient preprocessing pipelines. In this section, we will see an overview of different methods for constructing a TensorFlow Dataset, including dataset transformations and common preprocessing steps.
Creating a TensorFlow Dataset from existing tensors
If the data already exists in the form of a tensor object, a Python list, or a NumPy array, we can easily create a dataset using the tf.data.Dataset.from_tensor_slices() function. This function returns an object of class Dataset, which we can use to iterate through the individual elements in the input dataset. As a simple example, consider the following code, which creates a dataset from a list of values:
a = [1.2, 3.4, 7.5, 4.1, 5.0, 1.0]
ds = tf.data.Dataset.from_tensor_slices(a)
print(ds)![]()
We can easily iterate through a dataset entry by entry as follows:
for item in ds:
print(item)
If we want to create batches from this dataset, with a desired batch size of 3, we can do this as follows:
batch(batch_size, drop_remainder=False) method of tensorflow.python.data.ops.dataset_ops.TensorSliceDataset instanceds_batch = ds.batch(3) #batch_size =3
for i, elem in enumerate( ds_batch, 1):
print('batch {}:'.format(i), elem.numpy())![]()
This will create two batches from this dataset, where the first three elements go into batch #1, and the remaining elements go into batch #2. The .batch() method has an optional argument, drop_remainder, which is useful for cases when the number of elements in the tensor is not divisible by the desired batch size. The default for drop_remainder is False. We will see more examples illustrating the behavior of this method later in the subsection Shuffle, batch, and repeat.
ds_batch = ds.batch(4) #batch_size =4
for i, elem in enumerate( ds_batch, 1):
print('batch {}:'.format(i), elem.numpy())![]()
Combining two tensors into a joint dataset
Often, we may have the data in two (or possibly more) tensors. For example, we could have a tensor for features and a tensor for labels. In such cases, we need to build a dataset that combines these tensors together, which will allow us to retrieve the elements of these tensors in tuples.
Assume that we have two tensors, t_x and t_y. Tensor t_x holds our feature values, each of size 3, and t_y stores the class labels. For this example, we first create these two tensors as follows:
tf.random.set_seed(1)
t_x = tf.random.uniform([4,3], dtype=tf.float32)
t_y = tf.range(4)
t_x
t_y![]()
Now, we want to create a joint dataset from these two tensors. Note that there is a required one-to-one correspondence[ˌkɒrəˈspɒndəns]关联, 通信 between the elements of these two tensors:
ds_x = tf.data.Dataset.from_tensor_slices( t_x )
ds_y = tf.data.Dataset.from_tensor_slices( t_y )
ds_x![]() Hide the first dimension
Hide the first dimension
ds_y![]()
ds_joint = tf.data.Dataset.zip((ds_x, ds_y))
for example in ds_joint:
print(' x:', example[0].numpy(),
' y:', example[1].numpy())
Here, we first created two separate datasets, namely ds_x and ds_y. We then used the zip function to form a joint dataset. Alternatively, we can create the joint dataset using tf.data.Dataset.from_tensor_slices() as follows:
ds_joint = tf.data.Dataset.from_tensor_slices( (t_x,t_y) )
for example in ds_joint:
print( ' x:', example[0].numpy(),
' y:', example[1].numpy() )
which results in the same output.
Note that a common source of error could be that the element-wise correspondence between the original features (x) and labels (y) might be lost (for example, if the two datasets are shuffled separately). However, once they are merged into one dataset, it is safe to apply these operations.
Next, we will see how to apply transformations to each individual element of a dataset. For this, we will use the previous ds_joint dataset and apply featurescaling to scale the values to the range [-1, 1), as currently the values of t_x are in the range [0, 1) based on a random uniform distribution:
# x : floats, the default range is [0, 1)=[minval, maxval)
ds_trans = ds_joint.map( lambda x, y: (x*2-1.0, y))
for example in ds_trans:
print( ' x:', example[0].numpy(),
' y:', example[1].numpy() )
Applying this sort of transformation can be used for a user-defined function. For example, if we have a dataset created from the list of image filenames on disk, we can define a function to load the images from these filenames and apply that function by calling the .map() method. You will see an example of applying multiple transformations to a dataset later in this chapter.
Shuffle, batch, and repeat
As was mentioned in cp2_TrainingSimpleMachineLearningAlgorithmsForClassification_meshgrid_ravel_contourf_OvA_GradientDesent https://blog.csdn.net/Linli522362242/article/details/96429442, to train an NN model using stochastic gradient descent optimization, it is important to feed training data as randomly shuffled batches. You have already seen how to create batches by calling the .batch() method of a dataset object. Now, in addition to creating batches, you will see how to shuffle and reiterate over the datasets. We will continue working with the previous ds_joint dataset.
First, let's create a shuffled version from the ds_joint dataset:
tf.random.set_seed(1)
#buffer_size : determines how many elements in the dataset are grouped together before shuffling
ds = ds_joint.shuffle( buffer_size=len(t_x) )
for example in ds:
print(' x:', example[0].numpy(),
' y:', example[1].numpy() )
where the rows are shuffled without losing the one-to-one correspondence between the entries in x and y. The .shuffle() method requires an argument called buffer_size, which determines how many elements in the dataset are grouped together before shuffling. The elements in the buffer are randomly retrieved and their place in the buffer is given to the next elements in the original (unshuffled) dataset. Therefore, if we choose a small buffer_size, we may not shuffle the dataset perfectly.
If the dataset is small, choosing a relatively small buffer_size may negatively affect the predictive performance of the NN as the dataset may not be completely randomized. In practice, however, it usually does not have a noticeable effect when working with relatively large datasets, which is common in deep learning. Alternatively, to ensure complete randomization during each epoch, we can simply choose a buffer size that is equal to the number of the training examples, as in the preceding code (buffer_size=len(t_x)).
You will recall that dividing a dataset into batches for model training is done by calling the .batch() method. Now, let's create such batches from the ds_joint dataset and take a look at what a batch looks like:
ds = ds_joint.batch( batch_size=3,
drop_remainder=False )
# iter: The iter() function is used to generate iterators.
# next: next() returns the next item in the iterator.
# The next() function should be used together with the iter() function that generates iterators
batch_x, batch_y = next( iter(ds) )
print('Batch-x: \n', batch_x.numpy() )
print('Batch_y: ', batch_y.numpy() )
In addition, when training a model for multiple epochs, we need to shuffle and iterate over the dataset by the desired number of epochs. So, let's repeat the batched dataset twice:
ds = ds_joint.batch(3).repeat(count=2)
ds![]()
ds = ds_joint.batch(3).repeat(count=2) #4/3~~2*2=4
for i, (batch_x, batch_y) in enumerate(ds):
print(i, batch_x, batch_y.numpy())
ds = ds_joint.batch(3).repeat(count=2)
for i, (batch_x, batch_y) in enumerate(ds):
print(i, batch_x.shape, batch_y.numpy())
This results in two copies of each batch. If we change the order of these two operations, that is, first batch and then repeat, the results will be different:
ds = ds_joint.repeat(count=2).batch(3)
for i, (batch_x, batch_y) in enumerate(ds): # 4*2/3~~3
print(i, batch_x.shape, batch_y.numpy())
Notice the difference between the batches. When we first batch and then repeat, we get four batches. On the other hand, when repeat is performed first, three batches are created.
Finally, to get a better understanding of how these three operations (batch, shuffle, and repeat) behave, let's experiment with them in different orders. First, we will combine the operations in the following order: (1) shuffle, (2) batch, and (3) repeat (Suggested):
## Order 1: shuffle -> batch_2 -> repeat_3
tf.random.set_seed(1)
ds = ds_joint.shuffle(4).batch(2).repeat(3)
for i, (batch_x, batch_y) in enumerate(ds): # 4/2*3=6 and 4 is the number of elements in ds
print(i, batch_x.shape, batch_y.numpy())
Now, let's try a different order: (2) batch, (1) shuffle, and (3) repeat:
## Order 2: batch -> shuffle -> repeat
tf.random.set_seed(1)
ds = ds_joint.batch(2).shuffle(4).repeat(3)
for i, (batch_x, batch_y) in enumerate(ds):
print(i, batch_x.shape, batch_y.numpy())
While the first code example (shuffle, batch, repeat) appears to have shuffled the dataset as expected, we can see that in the second case (batch, shuffle, repeat), the elements within a batch were not shuffled at all. We can observe this lack of shuffling by taking a closer look at the tensor containing the target values, y. All batches contain either the pair of values [y=0, y=1] or the remaining pair of values [y=2, y=3]; we do not observe the other possible permutations: [y=2, y=0], [y=1,y=3], and so forth. Note that in order to ensure these results are not coincidental[kəʊˌɪnsɪˈdentl]巧合的, you may want to repeat this with a higher number than 3. For example, try it with .repeat(20).
Now, can you predict what will happen if we use the shuffle operation after repeat, for example, (2) batch, (3) repeat, (1) shuffle? Give it a try.
tf.random.set_seed(1)
ds = ds_joint.batch(2).repeat(3).shuffle(4)
for i, (batch_x, batch_y) in enumerate(ds):
print(i, batch_x.shape, batch_y.numpy())
One common source of error is to call .batch() twice in a row on a given dataset. By doing this, retrieving items from the resulting dataset will create a batch of batches of examples. Basically, each time you call .batch() on a dataset, it will increase the rank of the retrieved tensors by one.
(1) shuffle, (2) batch, and (3) repeat (Suggested):
Creating a dataset from files on your local storage disk
In this section, we will build a dataset from image files stored on disk. There is an image folder associated with the online content of this chapter. After downloading the folder, you should be able to see six images of cats and dogs in JPEG format.
This small dataset will show how building a dataset from stored files generally works. To accomplish this, we are going to use two additional modules in TensorFlow: tf.io to read the image file contents, and tf.image to decode the raw contents and image resizing.
##############################################################
tf.io and tf.image modules
The tf.io and tf.image modules provide a lot of additional and useful functions, which are beyond the scope of the book. You are encouraged to browse through the official documentation to learn more about these functions:
https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/io for tf.io
https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/image for tf.image
##############################################################
Before we start, let's take a look at the content of these files. We will use the pathlib library to generate a list of image files:
pathlib.Path.glob(pattern)
Glob the given relative pattern in the directory represented by this path, yielding all matching files (of any kind):
########################################################
os.path.basename(path)
Return the base name of pathname path. This is the second element of the pair returned by passing path to the function split(). Note that the result of this function is different from the Unix basename program; where basename for '/foo/bar/' returns 'bar', the basename() function returns an empty string ('').
########################################################
tf.io.read_file(
filename, name=None
) Reads and outputs the entire contents of the input filename.
########################################################
tf.io.decode_image(
contents, channels=None, dtype=tf.dtypes.uint8, name=None,
expand_animations=True
) Detects whether an image is a BMP, GIF, JPEG, or PNG, and performs the appropriate operation to convert the input bytes string into a Tensor of type dtype.
########################################################
import pathlib
# pathlib.Path.cwd() #==> WindowsPath('C:/Users/LlQ/0Python Machine Learning')
imgdir_path = pathlib.Path('cat_dog_images') # WindowsPath('cat_dog_images') in current directory
file_list = sorted([ str(path) for path in imgdir_path.glob('*.jpg') ])#glob(pattern)
print(file_list)![]()
Next, we will visualize these image examples using Matplotlib:
import matplotlib.pyplot as plt
import os
fig = plt.figure( figsize=(10,5) )
for i,file in enumerate( file_list ):
img_raw = tf.io.read_file( file )
img = tf.image.decode_image( img_raw )
print('Image shape: ', img.shape)
ax = fig.add_subplot(2,3,i+1)
ax.set_xticks([])
ax.set_yticks([])
ax.imshow(img)
# os.path.basename( 'cat_dog_images\\cat-01.jpg') return cat_01.jpg
ax.set_title( os.path.basename(file), size=15 )
plt.tight_layout()
plt.show()The following figure shows the example images:

Just from this visualization and the printed image shapes, we can already see that the images have different aspect ratios. If you print the aspect ratios (or data array shapes) of these images, you will see that some images are 900 pixels high and 1200 pixels wide (900 × 1200 ), some are 800 × 1200 , and one is 900 × 742 . Later, we will preprocess these images to a consistent size. Another point to consider is that the labels for these images are provided within their filenames. So, we extract these labels from the list of filenames, assigning label 1 to dogs and label 0 to cats:
labels = [1 if 'dog' in os.path.basename(file) else 0
for file in file_list ]
print(labels)![]()
Now, we have two lists: a list of filenames (or paths of each image) and a list of their labels. In the previous section, you already learned two ways( ds_x=tf.data.Dataset.from_tensor_slices(t_x)+tf.data.Dataset.from_tensor_slices(t_y) ==> tf.data.Dataset.zip((ds_x, ds_y)) , OR tf.data.Dataset.from_tensor_slices(t_x,t_y) ) of creating a joint dataset from two tensors. Here, we will use the second approach as follows:
ds_files_labels = tf.data.Dataset.from_tensor_slices(
(file_list, labels)
)
for item in ds_files_labels:
print( item[0].numpy(), item[1].numpy() )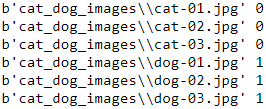
We have called this dataset ds_files_labels, since it has filenames and labels. Next, we need to apply transformations to this dataset: load the image content from its file path, decode the raw content, and resize it to a desired size, for example, 80 × 120 . Previously, we saw how to apply a lambda function using the .map() method. However, since we need to apply multiple preprocessing steps this time, we are going to write a helper function instead and use it when calling the .map() method:
for item in ds_files_labels:
print(item)
The load_and_preprocess() function wraps all four steps into a single function, including the loading of the raw content, decoding it, and resizing the images. The function then returns a dataset that we can iterate over and apply other operations that we learned about in the previous sections.
def load_and_preprocess(path, label):
image = tf.io.read_file(path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize( image, [img_height, img_width] )
image /= 255.0
return image, label
img_width, img_height = 120, 80
# map(function, iterable, ...)
ds_images_labels = ds_files_labels.map( load_and_preprocess )#############
fig = plt.figure( figsize=(10,5) )
for i, example in enumerate( ds_images_labels ):
print( example[0].shape, example[1].numpy() )
ax = fig.add_subplot(2,3,i+1)
ax.set_xticks([])
ax.set_yticks([])
ax.imshow(example[0])
ax.set_title( '{}'.format( example[1].numpy() ),
size=15 )
plt.tight_layout()
plt.show()This results in the following visualization of the retrieved example images, along with their labels:

ds_images_labels![]()
Fetching available datasets from the tensorflow_datasets library
The tensorflow_datasets library provides a nice collection of freely available datasets for training or evaluating deep learning models. The datasets are nicely formatted and come with informative descriptions, including the format of features and labels and their type and dimensionality, as well as the citation of the original paper that introduced the dataset in BibTeX format. Another advantage is that these datasets are all prepared and ready to use as tf.data.Dataset objects, so all the functions we covered in the previous sections can be used directly. So, let's see how to use these datasets in action.
First, we need to install the tensorflow_datasets library via pip from the command line:
pip install tensorflow-datasets : https://blog.csdn.net/Linli522362242/article/details/108037567
Now, let's import this module and take a look at the list of available datasets:
import tensorflow_datasets as tfds
print( len( tfds.list_builders()
) )
print( tfds.list_builders()[:5] )![]()
The preceding code indicates that there are currently 195 datasets available (195 datasets at the time of writing this chapter, but this number will likely increase)—we printed the first five datasets to the command line. There are two ways of fetching a dataset, which we will cover in the following paragraphs by fetching two different datasets: CelebA (celeb_a) and the MNIST digit dataset.
The first approach consists of three steps:
- 1. Calling the dataset builder function
- 2. Executing the download_and_prepare() method
- 3. Calling the as_dataset() method
Let's work with the first step for the CelebA dataset and print the associated description that is provided within the library:
celeba_bldr = tfds.builder('celeb_a')
print( celeba_bldr.info.features )FeaturesDict({
'attributes': FeaturesDict({
'5_o_Clock_Shadow': tf.bool,
'Arched_Eyebrows': tf.bool,
'Attractive': tf.bool,
'Bags_Under_Eyes': tf.bool,
'Bald': tf.bool,
'Bangs': tf.bool,
'Big_Lips': tf.bool,
'Big_Nose': tf.bool,
'Black_Hair': tf.bool,
'Blond_Hair': tf.bool,
'Blurry': tf.bool,
'Brown_Hair': tf.bool,
'Bushy_Eyebrows': tf.bool,
'Chubby': tf.bool,
'Double_Chin': tf.bool,
'Eyeglasses': tf.bool,
'Goatee': tf.bool,
'Gray_Hair': tf.bool,
'Heavy_Makeup': tf.bool,
'High_Cheekbones': tf.bool,
'Male': tf.bool,
'Mouth_Slightly_Open': tf.bool,
'Mustache': tf.bool,
'Narrow_Eyes': tf.bool,
'No_Beard': tf.bool,
'Oval_Face': tf.bool,
'Pale_Skin': tf.bool,
'Pointy_Nose': tf.bool,
'Receding_Hairline': tf.bool,
'Rosy_Cheeks': tf.bool,
'Sideburns': tf.bool,
'Smiling': tf.bool,
'Straight_Hair': tf.bool,
'Wavy_Hair': tf.bool,
'Wearing_Earrings': tf.bool,
'Wearing_Hat': tf.bool,
'Wearing_Lipstick': tf.bool,
'Wearing_Necklace': tf.bool,
'Wearing_Necktie': tf.bool,
'Young': tf.bool,
}),
'image': Image(shape=(218, 178, 3), dtype=tf.uint8),
'landmarks': FeaturesDict({
'lefteye_x': tf.int64,
'lefteye_y': tf.int64,
'leftmouth_x': tf.int64,
'leftmouth_y': tf.int64,
'nose_x': tf.int64,
'nose_y': tf.int64,
'righteye_x': tf.int64,
'righteye_y': tf.int64,
'rightmouth_x': tf.int64,
'rightmouth_y': tf.int64,
}),
})print( celeba_bldr.info.features.keys() )
print( '\n', 30*'=', '\n')
print( celeba_bldr.info.features['image'] )
print( '\n', 30*'=', '\n')
print( celeba_bldr.info.features['attributes'].keys() )
print( '\n', 30*'=', '\n')
print( celeba_bldr.info.citation )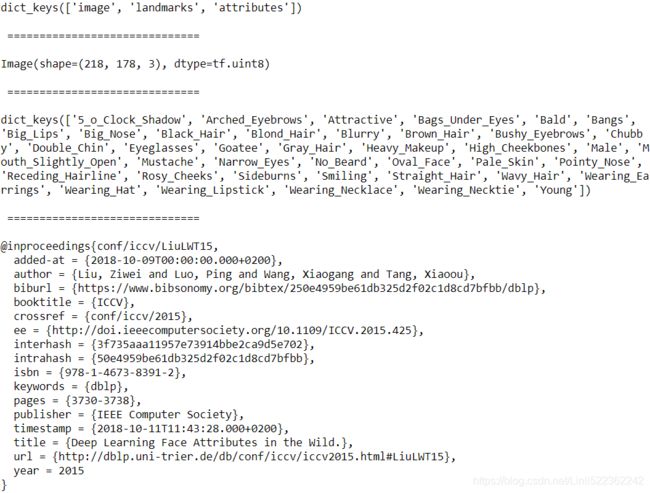
This provides some useful information to understand the structure of this dataset. The features are stored as a dictionary with three keys: 'image', 'landmarks', and 'attributes'.
The 'image' entry refers to the face image of a celebrity名人; 'landmarks' refers to the dictionary of extracted facial points, such as the position of the eyes, nose, and so on; and 'attributes' is a dictionary of 40 facial attributes for the person in the image, like facial expression, makeup, hair properties, and so on.
Next, we will call the download_and_prepare() method. This will download the data and store it on disk in a designated folder for all TensorFlow Datasets. If you have already done this once, it will simply check whether the data is already downloaded so that it does not re-download it if it already exists in the designated location:
# Download the data, prepare it, and write it to disk
celeba_bldr.download_and_prepare()
... ...
NonMatchingChecksumError: Artifact https://drive.google.com/uc?export=download&id=0B7EVK8r0v71pZjFTYXZWM3FlRnM, downloaded to C:\Users\LlQ\tensorflow_datasets\downloads\ucexport_download_id_0B7EVK8r0v71pZjFTYXZWM3FlDDaXUAQO8EGH_a7VqGNLRtW52mva1LzDrb-V723OQN8.tmp.f73027367c6e4cf793230277faf5b708\uc, has wrong checksum. This might indicate:
* The website may be down (e.g. returned a 503 status code). Please check the url.
* For Google Drive URLs, try again later as Drive sometimes rejects downloads when too many people access the same URL. See https://github.com/tensorflow/datasets/issues/1482
* The original datasets files may have been updated. In this case the TFDS dataset builder should be updated to use the new files and checksums. Sorry about that. Please open an issue or send us a PR with a fix.
* If you're adding a new dataset, don't forget to register the checksums as explained in: https://www.tensorflow.org/datasets/add_dataset#2_run_download_and_prepare_locally
!python -m tensorflow_datasets.scripts.download_and_prepare --datasets=celeb_a
Dl Size...: 0 MiB [00:00, ? MiB/s]I0112 19:51:43.926949 9600 download_manager.py:466] URL https://drive.google.com/uc?export=download&id=0B7EVK8r0v71pZjFTYXZWM3FlRnM already downloaded: reusing C:\Users\LlQ\tensorflow_datasets\downloads\ucexport_download_id_0B7EVK8r0v71pZjFTYXZWM3FlDDaXUAQO8EGH_a7VqGNLRtW52mva1LzDrb-V723OQN8. I0112 19:51:43.929949 9600 download_manager.py:466] URL https://drive.google.com/uc?export=download&id=0B7EVK8r0v71pd0FJY3Blby1HUTQ already downloaded: reusing C:\Users\LlQ\tensorflow_datasets\downloads\ucexport_download_id_0B7EVK8r0v71pd0FJY3Blby1HbdQ1eXJPJLYv0yq8hL1lCD5T2aOraaQwvj25ndmE7pg. I0112 19:51:43.932950 9600 download_manager.py:466] URL https://drive.google.com/uc?export=download&id=0B7EVK8r0v71pblRyaVFSWGxPY0U already downloaded: reusing C:\Users\LlQ\tensorflow_datasets\downloads\ucexport_download_id_0B7EVK8r0v71pblRyaVFSWGxPqmNvhNr_SZRozDtonT6daGXcRrWZZWDT9tfYjYVI_EU. I0112 19:51:43.935950 9600 download_manager.py:466] URL https://drive.google.com/uc?export=download&id=0B7EVK8r0v71pY0NSMzRuSXJEVkk already downloaded: reusing C:\Users\LlQ\tensorflow_datasets\downloads\ucexport_download_id_0B7EVK8r0v71pY0NSMzRuSXJE4OYZnheYf8_38ZWubhmIueQWaU9Xe0gIjD4rZYK-6iw.

Solutions:
Large-scale CelebFaces Attributes (CelebA) Dataset : http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
2020-07-10 Two related datasets, CelebAMask-HQ https://github.com/switchablenorms/CelebAMask-HQ and CelebA-Spoof https://github.com/Davidzhangyuanhan/CelebA-Spoof, have been released.
2016-07-29 If Dropbox is not accessible, please download the dataset using Google Drive https://drive.google.com/drive/folders/0B7EVK8r0v71pWEZsZE9oNnFzTm8 or Baidu Drive (password: rp0s) https://pan.baidu.com/share/init?surl=CRxxhoQ97A5qbsKO7iaAJg.
https://drive.google.com/uc?export=download&id=0B7EVK8r0v71pZjFTYXZWM3FlRnM
OR go to C:\Anaconda3\envs\tensorflow\Lib\site-packages\tensorflow_datasets\image\celeba.py
IMG_ALIGNED_DATA = ("https://drive.google.com/uc?export=download&id=0B7EVK8r0v71pZjFTYXZWM3FlRnM")
# OR IMG_ALIGNED_DATA = ("https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/celeba.zip")
EVAL_LIST = ("https://drive.google.com/uc?export=download&id=0B7EVK8r0v71pY0NSMzRuSXJEVkk")
# Landmark coordinates: left_eye, right_eye etc.
LANDMARKS_DATA = ("https://drive.google.com/uc?export=download&id=0B7EVK8r0v71pd0FJY3Blby1HUTQ")
# Attributes in the image (Eyeglasses, Mustache etc).
ATTR_DATA = ("https://drive.google.com/uc?export=download&id=0B7EVK8r0v71pblRyaVFSWGxPY0U")
# coding=utf-8
# Copyright 2021 The TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""CelebA dataset.
Large-scale CelebFaces Attributes (CelebA) Dataset
Deep Learning Face Attributes in the Wild
Ziwei Liu and Ping Luo and Xiaogang Wang and Xiaoou Tang
"""
import os
import tensorflow.compat.v2 as tf
import tensorflow_datasets.public_api as tfds
IMG_ALIGNED_DATA = ("https://drive.google.com/uc?export=download&"
"id=0B7EVK8r0v71pZjFTYXZWM3FlRnM")
EVAL_LIST = ("https://drive.google.com/uc?export=download&"
"id=0B7EVK8r0v71pY0NSMzRuSXJEVkk")
# Landmark coordinates: left_eye, right_eye etc.
LANDMARKS_DATA = ("https://drive.google.com/uc?export=download&"
"id=0B7EVK8r0v71pd0FJY3Blby1HUTQ")
# Attributes in the image (Eyeglasses, Mustache etc).
ATTR_DATA = ("https://drive.google.com/uc?export=download&"
"id=0B7EVK8r0v71pblRyaVFSWGxPY0U")
LANDMARK_HEADINGS = ("lefteye_x lefteye_y righteye_x righteye_y "
"nose_x nose_y leftmouth_x leftmouth_y rightmouth_x "
"rightmouth_y").split()
ATTR_HEADINGS = (
"5_o_Clock_Shadow Arched_Eyebrows Attractive Bags_Under_Eyes Bald Bangs "
"Big_Lips Big_Nose Black_Hair Blond_Hair Blurry Brown_Hair "
"Bushy_Eyebrows Chubby Double_Chin Eyeglasses Goatee Gray_Hair "
"Heavy_Makeup High_Cheekbones Male Mouth_Slightly_Open Mustache "
"Narrow_Eyes No_Beard Oval_Face Pale_Skin Pointy_Nose Receding_Hairline "
"Rosy_Cheeks Sideburns Smiling Straight_Hair Wavy_Hair Wearing_Earrings "
"Wearing_Hat Wearing_Lipstick Wearing_Necklace Wearing_Necktie Young"
).split()
_CITATION = """\
@inproceedings{conf/iccv/LiuLWT15,
added-at = {2018-10-09T00:00:00.000+0200},
author = {Liu, Ziwei and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou},
biburl = {https://www.bibsonomy.org/bibtex/250e4959be61db325d2f02c1d8cd7bfbb/dblp},
booktitle = {ICCV},
crossref = {conf/iccv/2015},
ee = {http://doi.ieeecomputersociety.org/10.1109/ICCV.2015.425},
interhash = {3f735aaa11957e73914bbe2ca9d5e702},
intrahash = {50e4959be61db325d2f02c1d8cd7bfbb},
isbn = {978-1-4673-8391-2},
keywords = {dblp},
pages = {3730-3738},
publisher = {IEEE Computer Society},
timestamp = {2018-10-11T11:43:28.000+0200},
title = {Deep Learning Face Attributes in the Wild.},
url = {http://dblp.uni-trier.de/db/conf/iccv/iccv2015.html#LiuLWT15},
year = 2015
}
"""
_DESCRIPTION = """\
CelebFaces Attributes Dataset (CelebA) is a large-scale face attributes dataset\
with more than 200K celebrity images, each with 40 attribute annotations. The \
images in this dataset cover large pose variations and background clutter. \
CelebA has large diversities, large quantities, and rich annotations, including\
- 10,177 number of identities,
- 202,599 number of face images, and
- 5 landmark locations, 40 binary attributes annotations per image.
The dataset can be employed as the training and test sets for the following \
computer vision tasks: face attribute recognition, face detection, and landmark\
(or facial part) localization.
Note: CelebA dataset may contain potential bias. The fairness indicators
[example](https://www.tensorflow.org/responsible_ai/fairness_indicators/tutorials/Fairness_Indicators_TFCO_CelebA_Case_Study)
goes into detail about several considerations to keep in mind while using the
CelebA dataset.
"""
class CelebA(tfds.core.GeneratorBasedBuilder):
"""CelebA dataset. Aligned and cropped. With metadata."""
VERSION = tfds.core.Version("2.0.1")
SUPPORTED_VERSIONS = [
tfds.core.Version("2.0.0"),
]
RELEASE_NOTES = {
"2.0.1": "New split API (https://tensorflow.org/datasets/splits)",
}
def _info(self):
return tfds.core.DatasetInfo(
builder=self,
description=_DESCRIPTION,
features=tfds.features.FeaturesDict({
"image":
tfds.features.Image(
shape=(218, 178, 3), encoding_format="jpeg"),
"landmarks": {name: tf.int64 for name in LANDMARK_HEADINGS},
# Attributes could be some special MultiLabel FeatureConnector
"attributes": {
name: tf.bool for name in ATTR_HEADINGS
},
}),
homepage="http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html",
citation=_CITATION,
)
def _split_generators(self, dl_manager):
downloaded_dirs = dl_manager.download({
"img_align_celeba": IMG_ALIGNED_DATA,
"list_eval_partition": EVAL_LIST,
"list_attr_celeba": ATTR_DATA,
"landmarks_celeba": LANDMARKS_DATA,
})
# Load all images in memory (~1 GiB)
# Use split to convert: `img_align_celeba/000005.jpg` -> `000005.jpg`
all_images = {
os.path.split(k)[-1]: img for k, img in
dl_manager.iter_archive(downloaded_dirs["img_align_celeba"])
}
return [
tfds.core.SplitGenerator(
name=tfds.Split.TRAIN,
gen_kwargs={
"file_id": 0,
"downloaded_dirs": downloaded_dirs,
"downloaded_images": all_images,
}),
tfds.core.SplitGenerator(
name=tfds.Split.VALIDATION,
gen_kwargs={
"file_id": 1,
"downloaded_dirs": downloaded_dirs,
"downloaded_images": all_images,
}),
tfds.core.SplitGenerator(
name=tfds.Split.TEST,
gen_kwargs={
"file_id": 2,
"downloaded_dirs": downloaded_dirs,
"downloaded_images": all_images,
})
]
def _process_celeba_config_file(self, file_path):
"""Unpack the celeba config file.
The file starts with the number of lines, and a header.
Afterwards, there is a configuration for each file: one per line.
Args:
file_path: Path to the file with the configuration.
Returns:
keys: names of the attributes
values: map from the file name to the list of attribute values for
this file.
"""
with tf.io.gfile.GFile(file_path) as f:
data_raw = f.read()
lines = data_raw.split("\n")
keys = lines[1].strip().split()
values = {}
# Go over each line (skip the last one, as it is empty).
for line in lines[2:-1]:
row_values = line.strip().split()
# Each row start with the 'file_name' and then space-separated values.
values[row_values[0]] = [int(v) for v in row_values[1:]]
return keys, values
def _generate_examples(self, file_id, downloaded_dirs, downloaded_images):
"""Yields examples."""
img_list_path = downloaded_dirs["list_eval_partition"]
landmarks_path = downloaded_dirs["landmarks_celeba"]
attr_path = downloaded_dirs["list_attr_celeba"]
with tf.io.gfile.GFile(img_list_path) as f:
files = [
line.split()[0]
for line in f.readlines()
if int(line.split()[1]) == file_id
]
attributes = self._process_celeba_config_file(attr_path)
landmarks = self._process_celeba_config_file(landmarks_path)
for file_name in sorted(files):
record = {
"image": downloaded_images[file_name],
"landmarks": {
k: v for k, v in zip(landmarks[0], landmarks[1][file_name])
},
"attributes": {
# atributes value are either 1 or -1, so convert to bool
k: v > 0 for k, v in zip(attributes[0], attributes[1][file_name])
},
}
yield file_name, recordLet's use Google Drive
https://drive.google.com/drive/folders/0B7EVK8r0v71pWEZsZE9oNnFzTm8
Details
CelebFaces Attributes Dataset (CelebA) is a large-scale face attributes dataset with more than 200K celebrity images, each with 40 attribute annotations. The images in this dataset cover large pose variations and background clutter. CelebA has large diversities, large quantities, and rich annotations, including
-
10,177 number of identities
 ,
,
-
202,599 number of face images, and
 OR (
OR ( )
)
-
5 landmark locations(I use list_landmarks_align_celeba.txt), 40 binary attributes(list_attr_celeba.txt) annotations per image.
-
 and celeba 2.0.1 dataset_info.json
and celeba 2.0.1 dataset_info.json{ "citation": "@inproceedings{conf/iccv/LiuLWT15,\n added-at = {2018-10-09T00:00:00.000+0200},\n author = {Liu, Ziwei and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou},\n biburl = {https://www.bibsonomy.org/bibtex/250e4959be61db325d2f02c1d8cd7bfbb/dblp},\n booktitle = {ICCV},\n crossref = {conf/iccv/2015},\n ee = {http://doi.ieeecomputersociety.org/10.1109/ICCV.2015.425},\n interhash = {3f735aaa11957e73914bbe2ca9d5e702},\n intrahash = {50e4959be61db325d2f02c1d8cd7bfbb},\n isbn = {978-1-4673-8391-2},\n keywords = {dblp},\n pages = {3730-3738},\n publisher = {IEEE Computer Society},\n timestamp = {2018-10-11T11:43:28.000+0200},\n title = {Deep Learning Face Attributes in the Wild.},\n url = {http://dblp.uni-trier.de/db/conf/iccv/iccv2015.html#LiuLWT15},\n year = 2015\n}", "description": "CelebFaces Attributes Dataset (CelebA) is a large-scale face attributes dataset with more than 200K celebrity images, each with 40 attribute annotations. The images in this dataset cover large pose variations and background clutter. CelebA has large diversities, large quantities, and rich annotations, including\n - 10,177 number of identities,\n - 202,599 number of face images, and\n - 5 landmark locations, 40 binary attributes annotations per image.\n\nThe dataset can be employed as the training and test sets for the following computer vision tasks: face attribute recognition, face detection, and landmark (or facial part) localization.", "downloadSize": "1485204305", "location": { "urls": [ "http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html" ] }, "name": "celeb_a", "schema": { "feature": [ { "name": "attributes" }, { "name": "image", "shape": { "dim": [ { "size": "218" }, { "size": "178" }, { "size": "3" } ] }, "type": "INT" }, { "name": "landmarks" } ] }, "splits": [ { "name": "test", "numBytes": "171454591", "numShards": "1", "shardLengths": [ "9981", "9981" ], "statistics": { "features": [ { "name": "image", "numStats": { "commonStats": { "numNonMissing": "19962" }, "max": 255.0 } } ], "numExamples": "19962" } }, { "name": "train", "numBytes": "1398155767", "numShards": "1", "shardLengths": [ "10173", "10173", "10173", "10173", "10174", "10173", "10173", "10173", "10173", "10173", "10173", "10174", "10173", "10173", "10173", "10173" ], "statistics": { "features": [ { "name": "image", "numStats": { "commonStats": { "numNonMissing": "162770" }, "max": 255.0 } } ], "numExamples": "162770" } }, { "name": "validation", "numBytes": "171488615", "numShards": "1", "shardLengths": [ "9934", "9933" ], "statistics": { "features": [ { "name": "image", "numStats": { "commonStats": { "numNonMissing": "19867" }, "max": 255.0 } } ], "numExamples": "19867" } } ], "version": "2.0.1" }import os import tensorflow as tf import numpy as np import matplotlib.pyplot as plt list_eval_partition = r'C:\Users\LlQ\tensorflow_datasets\celeb_a\2.0.1\Eval\list_eval_partition.txt' list_landmarks_align_celeba = r'C:\Users\LlQ\tensorflow_datasets\celeb_a\2.0.1\Anno\list_landmarks_align_celeba.txt' list_attr_celeba = r'C:\Users\LlQ\tensorflow_datasets\celeb_a\2.0.1\Anno\list_attr_celeba.txt' def generate_examples(file_id, list_eval_partition_file): with tf.io.gfile.GFile(list_eval_partition_file) as f: files = [ line.split()[0] for line in f.readlines() if int(line.split()[1]) == file_id ] #['000001.jpg',...] return files train_jpg_list = generate_examples(0, list_eval_partition) valid_jpg_list = generate_examples(1, list_eval_partition) test_jpg_list = generate_examples(2, list_eval_partition) # train_jpg_list[:5] # # ['000001.jpg', '000002.jpg', '000003.jpg', '000004.jpg', '000005.jpg'] # valid_jpg_list[:5] # # ['162771.jpg', '162772.jpg', '162773.jpg', '162774.jpg', '162775.jpg'] # test_jpg_list[:5] # # ['182638.jpg', '182639.jpg', '182640.jpg', '182641.jpg', '182642.jpg'] train_jpg_list[:5]
import pathlib import os # pathlib.Path.cwd() #==> WindowsPath('C:/Users/LlQ/0Python Machine Learning') os.chdir(r'C:\Users\LlQ\tensorflow_datasets\celeb_a\2.0.1') # print(os.getcwd()) #C:\Users\LlQ\tensorflow_datasets\celeb_a\2.0.1 celebA_imgdir = pathlib.Path(r'img_align_celeba')############################################# You should not use the following code #############################################
import pathlib import os # pathlib.Path.cwd() #==> WindowsPath('C:/Users/LlQ/0Python Machine Learning') os.chdir(r'C:\Users\LlQ\tensorflow_datasets\celeb_a\2.0.1') # print(os.getcwd()) #C:\Users\LlQ\tensorflow_datasets\celeb_a\2.0.1 celebA_imgdir = pathlib.Path(r'img_align_celeba') # celebA_imgdir : WindowsPath('C:/Users/LlQ/tensorflow_datasets/celeb_a/2.0.1/img_align_celeba') celebA_jpg_list = sorted([ str(path) for path in celebA_imgdir.glob('*.jpg') ])#glob(pattern) # ['img_align_celeba\\000001.jpg'] # train_jpg_list[:3] # ['000001.jpg', '000002.jpg', '000003.jpg'] # test_jpg_list = [str(celebA_imgdir) + "\\" + _ for _ in test_jpg_list] # train_jpg_list = [str(celebA_imgdir) + "\\" + _ for _ in train_jpg_list] # valid_jpg_list = [str(celebA_imgdir) + "\\" + _ for _ in valid_jpg_list] # train_jpg_list[:3] # # ['img_align_celeba\\000001.jpg', # # 'img_align_celeba\\000002.jpg', # # 'img_align_celeba\\000003.jpg'] # test_jpg_list[:3] # # ['img_align_celeba\\182638.jpg', # # 'img_align_celeba\\182639.jpg', # # 'img_align_celeba\\182640.jpg'] ###################################### OR time consuming # train_jpg_list = [_ for _ in celebA_jpg_list if os.path.split(_)[-1] in train_jpg_list] # test_jpg_list = [_ for _ in celebA_jpg_list if os.path.split(_)[-1] in test_jpg_list] # valid_jpg_list = [_ for _ in celebA_jpg_list if os.path.split(_)[-1] in valid_jpg_list] ###################################### OR train_jpgs = [] test_jpgs = [] valid_jpgs = [] for _ in celebA_jpg_list: f=os.path.split(_)[-1] if f in train_jpg_list: train_jpgs.append( _ ) elif f in test_jpg_list: test_jpgs.append( _ ) else: valid_jpgs.append( _ ) train_jpg_list = train_jpgs test_jpg_list = test_jpgs valid_jpg_list = valid_jpgs train_jpg_list[:3] # test_jpg_list[:3]
import matplotlib.pyplot as plt import os fig = plt.figure( figsize=(10,5) ) for i,file in enumerate( train_jpg_list[:3] ): img_raw = tf.io.read_file( file ) # step1 img = tf.image.decode_image( img_raw ) # step2 print('Image shape: ', img.shape) ax = fig.add_subplot(2,3,i+1) ax.set_xticks([]) ax.set_yticks([]) ax.imshow(img) # step3 # os.path.basename( 'cat_dog_images\\cat-01.jpg') return cat_01.jpg ax.set_title( os.path.basename(file), size=15 ) plt.tight_layout() plt.show()
-
#############################################
#train_jpg_list[:5] : ['000001.jpg', '000002.jpg', '000003.jpg', '000004.jpg', '000005.jpg'] tf.io.read_file( os.path.join( 'img_align_celeba\\', train_jpg_list[0]) ) # train_jpg_list[0] is a file path
After tf.image.decode_image( )tf.image.decode_image( tf.io.read_file( os.path.join( 'img_align_celeba\\', train_jpg_list[0] ), ), # train_jpg_list[0] is a file path channels=3 ) # tf.io.read_file( os.path.join( 'img_align_celeba\\', # train_jpg_list[0] ), # ) # train_jpg_list[0] is a file path

since the image is jpeg formattrain_jpg_tsd = tf.data.Dataset.from_tensor_slices( train_jpg_list ) test_jpg_tsd = tf.data.Dataset.from_tensor_slices( test_jpg_list ) valid_jpg_tsd = tf.data.Dataset.from_tensor_slices( valid_jpg_list ) ## for item in train_jpg_tsd: #if train_jpg_tsd = tf.data.Dataset.from_tensor_slices( train_jpg_list[3] ) # print( item.numpy() # output: # b'img_align_celeba\\000001.jpg' # b'img_align_celeba\\000002.jpg' # b'img_align_celeba\\000003.jpg' # img_width, img_height = 120, 80 def load_and_preprocess(path): image = tf.io.read_file(path) # step1 # tf.io.encode_jpeg(image) # encode an image using the JPEG format and put this binary data in a BytesList. # since the image is jpeg format #image = tf.image.decode_jpeg(image, channels=3) # step2 #image = tf.image.convert_image_dtype( image, dtype=tf.float32) # step3 # image = tf.image.resize( image, [img_height, img_width] ) # image /= 255.0 # step4 return image # map(function, iterable, ...) train_images = train_jpg_tsd.map( load_and_preprocess ) test_images = test_jpg_tsd.map( load_and_preprocess ) valid_images = valid_jpg_tsd.map( load_and_preprocess ) fig = plt.figure( figsize=(10,5) ) for i, example in enumerate( test_images ): example=tf.image.decode_jpeg(example, channels=3) print( example.shape ) ax = fig.add_subplot(2,3,i+1) ax.set_xticks([]) ax.set_yticks([]) ax.imshow(example) if i+1>2: break plt.tight_layout() plt.show() 
############################################################################################################## -
Create tfrecord files for 'test', 'train', 'validation'
For nested features, the FeaturesDict will internally flatten the keys for the features and the conversion to tf.train.Example. Indeed, the tf.train.Example proto do not support nested feature, while tf.data.Dataset does. But internal transformation should be invisible to the user. https://www.tensorflow.org/datasets/api_docs/python/tfds/features/FeaturesDict
https://www.tensorflow.org/datasets/catalog/celeb_a
list_landmarks_align_celeba![]()
def process_celeba_config_file(file_path):
"""Unpack the celeba config file.
The file starts with the number of lines, and a header.
Afterwards, there is a configuration for each file: one per line.
Args:
file_path: Path to the file with the configuration.
Returns:
keys: names of the attributes
values: map from the file name to the list of attribute values for
this file.
"""
with tf.io.gfile.GFile(file_path) as f:
data_raw = f.read()
lines = data_raw.split("\n")
# lines[0] : 202599 # we don't need
keys = lines[1].strip().split()# split by space
values = {}
# Go over each line (skip the last one, as it is empty).
for line in lines[2:-1]:
row_values = line.strip().split()
# Each row start with the 'file_name' and then space-separated values.
values[row_values[0]] = [int(v) for v in row_values[1:]]
return keys, values
attributes = process_celeba_config_file(list_attr_celeba)
landmarks = process_celeba_config_file(list_landmarks_align_celeba)
print( landmarks[0] )![]()
print( landmarks[1]['000001.jpg'] )![]()
print( landmarks[1]['000001.jpg'][0] )![]()
print( attributes[0] ) #keys
# value_attributes # { '000001.jpg' : [-1,...],
# # '000002.jpg' : [-1,...]
# # }
print( attributes[1]['000001.jpg'] )


# https://www.tensorflow.org/tutorials/load_data/tfrecord
### Convenience function for writing Feature in TFRecords
def bytes_feature(value): # for image
"""Returns a bytes_list from a string / byte."""
return tf.train.Feature( bytes_list=tf.train.BytesList( value=[value] ) )
def int64_feature(value): # for attributes and landmarks
"""Returns an int64_list from a bool / enum / int / uint."""
if value <0:##################
value=0###################
return tf.train.Feature( int64_list=tf.train.Int64List( value=[value] ) )
Feature = tf.train.Feature
Features = tf.train.Features
Example = tf.train.Example
def create_example( attributes, image, landmarks ):
#image_data = tf.io.serialize_tensor(image)
# encode an image using the JPEG format and put this binary data in a BytesList.
# image_data = tf.io.encode_jpeg( image[..., np.newaxis] ) # OR image[:,:, np.newaxis].shape ==> (28, 28, 1)
return Example(
features = Features(
feature = {
'attributes/5_o_Clock_Shadow': int64_feature( attributes[0] ),
'attributes/Arched_Eyebrows': int64_feature( attributes[1] ),
'attributes/Attractive': int64_feature( attributes[2] ),
'attributes/Bags_Under_Eyes': int64_feature( attributes[3] ),
'attributes/Bald': int64_feature( attributes[4] ),
'attributes/Bangs': int64_feature( attributes[5] ),
'attributes/Big_Lips': int64_feature( attributes[6] ),
'attributes/Big_Nose': int64_feature( attributes[7] ),
'attributes/Black_Hair': int64_feature( attributes[8] ),
'attributes/Blond_Hair': int64_feature( attributes[9] ),
'attributes/Blurry': int64_feature( attributes[10] ),
'attributes/Brown_Hair': int64_feature( attributes[11] ),
'attributes/Bushy_Eyebrows': int64_feature( attributes[12] ),
'attributes/Chubby': int64_feature( attributes[13] ),
'attributes/Double_Chin': int64_feature( attributes[14] ),
'attributes/Eyeglasses': int64_feature( attributes[15] ),
'attributes/Goatee': int64_feature( attributes[16] ),
'attributes/Gray_Hair': int64_feature( attributes[17] ),
'attributes/Heavy_Makeup': int64_feature( attributes[18] ),
'attributes/High_Cheekbones': int64_feature( attributes[19] ),
'attributes/Male': int64_feature( attributes[20] ),
'attributes/Mouth_Slightly_Open': int64_feature( attributes[21] ),
'attributes/Mustache': int64_feature( attributes[22] ),
'attributes/Narrow_Eyes': int64_feature( attributes[23] ),
'attributes/No_Beard': int64_feature( attributes[24] ),
'attributes/Oval_Face': int64_feature( attributes[25] ),
'attributes/Pale_Skin': int64_feature( attributes[26] ),
'attributes/Pointy_Nose': int64_feature( attributes[27] ),
'attributes/Receding_Hairline': int64_feature( attributes[28] ),
'attributes/Rosy_Cheeks': int64_feature( attributes[29] ),
'attributes/Sideburns': int64_feature( attributes[30] ),
'attributes/Smiling': int64_feature( attributes[31] ),
'attributes/Straight_Hair': int64_feature( attributes[32] ),
'attributes/Wavy_Hair': int64_feature( attributes[33] ),
'attributes/Wearing_Earrings': int64_feature( attributes[34] ),
'attributes/Wearing_Hat': int64_feature( attributes[35] ),
'attributes/Wearing_Lipstick': int64_feature( attributes[36] ),
'attributes/Wearing_Necklace': int64_feature( attributes[37] ),
'attributes/Wearing_Necktie': int64_feature( attributes[38] ),
'attributes/Young': int64_feature( attributes[39] ),
'image': bytes_feature( image.numpy() ),
'landmarks/lefteye_x': int64_feature( landmarks[0] ),
'landmarks/lefteye_y': int64_feature( landmarks[1] ),
'landmarks/righteye_x': int64_feature( landmarks[2] ),
'landmarks/righteye_y': int64_feature( landmarks[3] ),
'landmarks/nose_x': int64_feature( landmarks[4] ),
'landmarks/nose_y': int64_feature( landmarks[5] ),
'landmarks/leftmouth_x': int64_feature( landmarks[6] ),
'landmarks/leftmouth_y': int64_feature( landmarks[7] ),
'landmarks/rightmouth_x': int64_feature( landmarks[8] ),
'landmarks/rightmouth_y': int64_feature( landmarks[9] )
}
)
)
# tf.io.read_file( os.path.join( 'img_align_celeba\\',
# train_jpg_list[0]) ) # train_jpg_list[0] is a file path
for image in train_jpg_list[:3]:
print( create_example( attributes[1][image],
tf.io.read_file( os.path.join( 'img_align_celeba\\',
image )
),
landmarks[1][image]
) )
from contextlib import ExitStack
def write_tfrecords(name, dataset, n_shards=10):
paths=[ "{}.tfrecord-{:05d}-of-{:05d}".format(name, index, n_shards)
for index in range(n_shards) ]
with ExitStack() as stack:
writers = [stack.enter_context(tf.io.TFRecordWriter(path))
for path in paths]
for index, image in enumerate(dataset):
shard = index % n_shards
example = create_example( attributes[1][image],
tf.io.read_file( os.path.join( 'img_align_celeba\\',
image )
),
landmarks[1][image]
)
writers[shard].write(example.SerializeToString())
return paths
train_filepaths = write_tfrecords("celeb_a-train", train_jpg_list, 16)
valid_filepaths = write_tfrecords("celeb_a-valid", valid_jpg_list, 2)
test_filepaths = write_tfrecords("celeb_a-test", test_jpg_list, 2)
13_Loading and Preprocessing Data from multiple CSV with TensorFlow_custom training loop_TFRecord : https://blog.csdn.net/Linli522362242/article/details/108108665 9. Load the Fashion MNIST dataset (introduced in 10_Introduction to Artificial Neural Networks w Keras_3_FashionMNIST_pydot_sparse_shift(0.)_plt_imgs https://blog.csdn.net/Linli522362242/article/details/106562190); split it into a training set, a validation set, and a test set;
https://www.programcreek.com/python/example/90550/tensorflow.decode_raw
The dataset can be employed as the training and test sets for the following computer vision tasks: face attribute recognition, face detection, landmark (or facial part) localization, and face editing & synthesis.
# Download the data, prepare it, and write it to disk
celeba_bldr.download_and_prepare()
# Load data from disk as tf.data.Datasets
datasets = celeba_bldr.as_dataset(shuffle_files=False)
datasets.keys()![]()
import tensorflow as tf
ds_train = datasets['train']
assert isinstance(ds_train, tf.data.Dataset)
example = next(iter(ds_train))
print(type(example))
print(example.keys())
example['landmarks']
example['attributes']
ds_train = ds_train.map(lambda item:
(item['image'], tf.cast(item['attributes']['Male'], tf.int32)))
ds_train = ds_train.batch(18)
images, labels = next(iter(ds_train))
print(images.shape, labels)![]()
fig = plt.figure(figsize=(12, 8))
for i,(image,label) in enumerate(zip(images, labels)):
ax = fig.add_subplot(3, 6, i+1)
ax.set_xticks([]); ax.set_yticks([])
ax.imshow(image)
ax.set_title('{}'.format(label), size=15)
plt.show()
Alternative ways for loading a dataset
https://blog.csdn.net/Linli522362242/article/details/113311720