YOLOV4与YOLOV3的区别
YOLOV4与YOLOV3的区别
20年的11月份的时候,正式开始接触v4。时间过去了小半年了,最近突然忘记了v4里面的所谓那些tricks,所以特地做一篇blog(怕过段时间又忘记了~)。
首先,先大概的说下二者之间的差别:
1.特征提取网络的不同
2.激活函数的不同
3.loss的不同
4.数据处理的不同
5.学习率的不同
参考:
https://blog.csdn.net/weixin_44791964/article/details/106533581
https://blog.csdn.net/weixin_44791964/article/details/105310627
一、特征提取网络的不同
先贴上二者的特征提取网络的图
yolov3
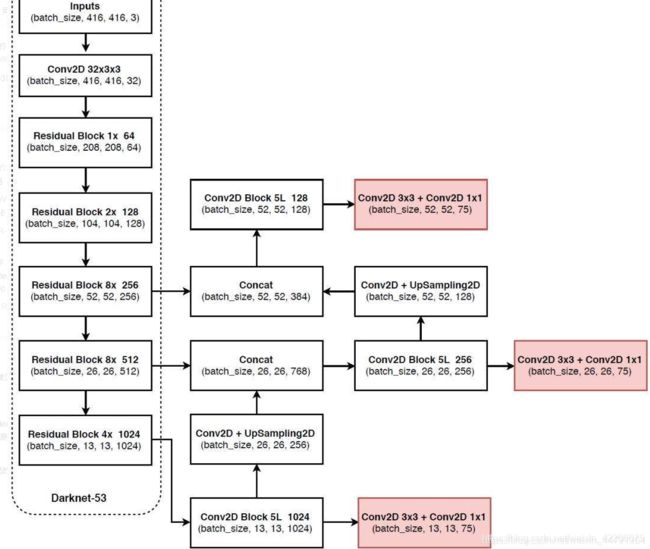
yolov4
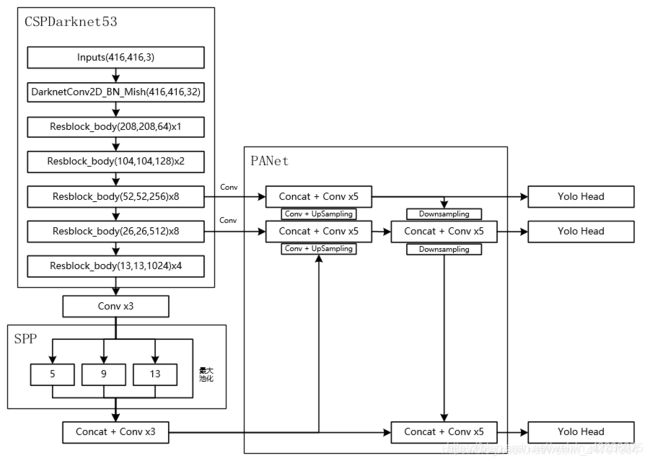
主要有三个不同的地方:
1.backbone由Darknet53变成CSP Darknet53。
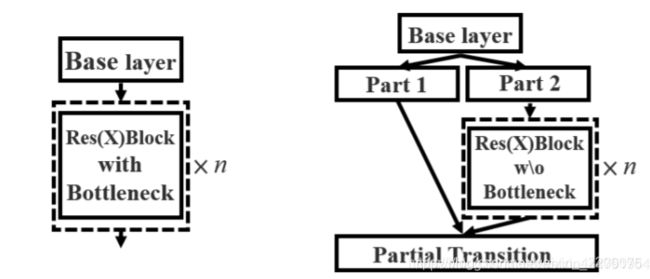
这是CSP网络结构,可以看到,base layer后面会分出来两个分支,一个分支是一个大残差边,另外一个分支会接resnet残差结构,最后会将二者经过融合。而yolov3中只有csp中简单的残差,并没有最后的融合操作。
值得说下的是,yolov3和4经过backbone之后得到的都是三个分支:(52,52,256),(26,26,512),(13,13,1024)。当然了,前提是喂进网络的图片大小都是(416,416,3)的。
2.v4中在backbone后面进行了一个spp操作。(目的:增加感受野?)
# 使用了SPP结构,即不同尺度的最大池化后堆叠。
maxpool1 = MaxPooling2D(pool_size=(13, 13), strides=(1, 1), padding='same')(P5)
maxpool2 = MaxPooling2D(pool_size=(9, 9), strides=(1, 1), padding='same')(P5)
maxpool3 = MaxPooling2D(pool_size=(5, 5), strides=(1, 1), padding='same')(P5)
P5 = Concatenate()([maxpool1, maxpool2, maxpool3, P5])
我感觉这个操作是一个伪spp吧(我印象中spp net中的spp不是这样的操作吧)。这里只是利用不同的池化核进行池化,其中还有一个点是需要注意的,就是tf中padding选择的是same,同时步长为1,那么默认输出的feature map的长宽与输入的一致,所以这里输入的是backbone中最后一层(13,13,1024)先经过三次卷积得到(13,13,512),那么经过三次不同池化核池化得到的还是(13,13,512),最后将本身在内的四个经过最后一维concat,那么P5的维度就是(13,13,2048)。
3.v4中经过了spp之后会经过一个PANet网络结构
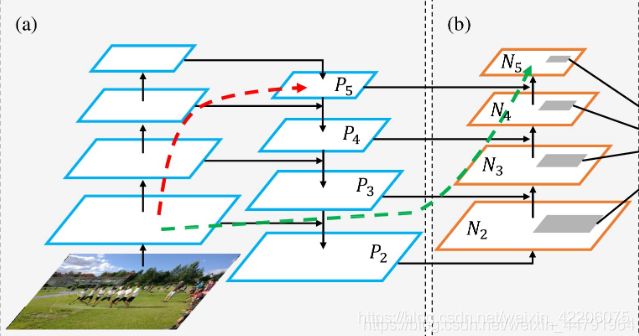
在yolov3中,由darknet53得到的(13,13,1024)的feature map经过两次上采样,途中与(26,26,512)和(52,52,256)进行concat。
在yolov4中,不仅有特征金字塔结构,还有下采样的操作。由spp之后先经过三次conv,然后喂进PANet,先经过两次上采样,然后再经过两次下采样,途中进行特征融合,得到预测的三个head。
二、激活函数的不同
yolov3使用的leaky relu激活函数
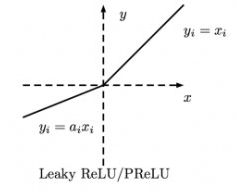
yolov4使用的mish激活函数
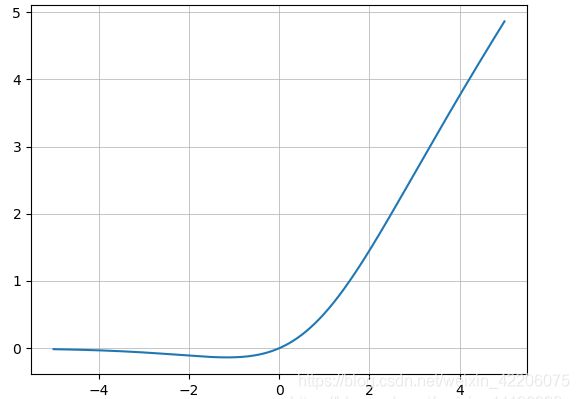
计算公式:Mish = x*tanh(ln(1+e^x))
优点:
1.从图中可以看出他在负值的时候并不是完全截断,而是允许比较小的负梯度流入,从而保证信息流动。
2.并且激活函数无边界这个特点,让他避免了饱和这一问题,比如sigmoid,tanh激活函数通常存在梯度饱和问题,在两边极限情况下,梯度趋近于1,而Mish激活函数则巧妙的避开了这一点。
3.另外Mish函数也保证了每一点的平滑,从而使得梯度下降效果比Relu要好。
https://blog.csdn.net/weixin_44106928/article/details/103042287
三、loss的不同
先来看下yolov3中对于正样本的预测框的位置loss计算代码
# pos_samples 只有在正样本的地方取值为1.,其它地方取值全为0.
pos_objectness = label_objectness > 0
pos_samples = fluid.layers.cast(pos_objectness, 'float32')
pos_samples.stop_gradient=True
#从output中取出所有跟位置相关的预测值
tx = reshaped_output[:, :, 0, :, :]
ty = reshaped_output[:, :, 1, :, :]
tw = reshaped_output[:, :, 2, :, :]
th = reshaped_output[:, :, 3, :, :]
# 从label_location中取出各个位置坐标的标签
dx_label = label_location[:, :, 0, :, :]
dy_label = label_location[:, :, 1, :, :]
tw_label = label_location[:, :, 2, :, :]
th_label = label_location[:, :, 3, :, :]
# 构建损失函数
loss_location_x = fluid.layers.sigmoid_cross_entropy_with_logits(tx, dx_label)
loss_location_y = fluid.layers.sigmoid_cross_entropy_with_logits(ty, dy_label)
loss_location_w = fluid.layers.abs(tw - tw_label)
loss_location_h = fluid.layers.abs(th - th_label)
# 计算总的位置损失函数
loss_location = loss_location_x + loss_location_y + loss_location_h + loss_location_w
# 乘以scales
loss_location = loss_location * scales
# 只计算正样本的位置损失函数
loss_location = loss_location * pos_samples
分别找到模型输出的预测框的tx,ty,tw,th,然后与基于真实框得到的label的tx,ty,tw,th进行交叉熵损失函数的构建,最后进行相加。
但是,在v4中是使用(1-CIOU)直接作为正样本的位置损失函数。
#-----------------------------------------------------------#
# 真实框越大,比重越小,小框的比重更大。
#-----------------------------------------------------------#
box_loss_scale = 2 - y_true[l][...,2:3]*y_true[l][...,3:4]
#-----------------------------------------------------------#
# 计算Ciou loss
#-----------------------------------------------------------#
raw_true_box = y_true[l][...,0:4]
ciou = box_ciou(pred_box, raw_true_box)
ciou_loss = object_mask * box_loss_scale * (1 - ciou)
再来看看CIOU是什么东西?
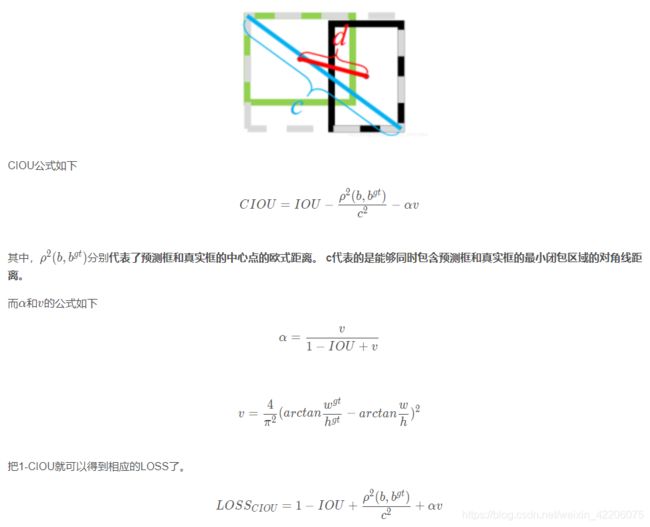
(原谅我懒了~我就直接截大佬的图了,ciou的讲解一般都差不多)
相比于IOU的优点:
1.IOU没有考虑到两个框之间的位置信息,如果两个框没有重叠,它的IOU=0,没法进行反向传播。
2.还有一点,就是为什么之前的所有目标检测的网络中没有用iou直接作为损失函数,这个在我的上一篇blog中也提到了。就是因为对于大小不同的框,iou值相同,但是其重叠程度却不同(说白了,就是对尺度不敏感)。在ciou中,由于有v这个概念,所以就使这种情况不可能再出现(个人理解,不对还请指正)。
四、数据处理的不同
yolov4中数据增强采用了mosaic数据增强(我一般喜欢叫它为马赛克数据增强)。
他的步骤也是比较简单的:
1.选取四张图片。然后将四张图片分别放置一张画布的四个角。
2.然后进行超参数的拼接。
3.每张图的gt框也随之进行处理,若一张图片中的某个gt框由于拼接过程中删除,我们还要对其进行边缘优化操作。
五、学习率的不同
在yolov3中,学习率一般都是使用衰减学习率,就是每学习多少epoch,学习率减少固定的值。
在yolov4中,学习率的变化使用了一种比较新的方法:学习率余弦退火衰减。
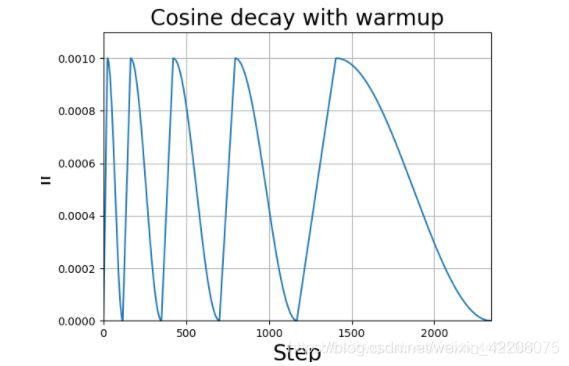
由图中可以看得出来,学习率会先上升再下降,这是退火优化法的思想。
在tf中,有实现的代码:
lr_schedule = tf.keras.experimental.CosineDecayRestarts(
initial_learning_rate = learning_rate_base,
first_decay_steps = 5*epoch_size,
t_mul = 1.0,
alpha = 1e-2
)
总结
总的来说,v4是v3的一种增强版,因为其核心思想是没有什么改进的,只不过里面加了很多小的tricks,为了就是让训练变得更快,map更高。