Hadoop之MRjob入门
Hadoop之MRjob入门
- 一、mrjob的安装
- Hadoop 的各 Python 框架对比
- 使用 mrjob 实现词组统计
-
- **启动 Hadoop 集群**
- **启动 hadoop 集群:**
- 代码实践
- mrjob 多种运行方式
- 实战模拟一
- 实战模拟二
- 实战模拟挑战
- 实验总结
1.1 实验内容
本实验将通过 python 中 mrjob 模块来调用 hadoop 处理数据。
mrjob 是用来写能在 hadoop 运行的 python 程序的最简便方法,通过本次实验,你可以初步入门 mrjob,轻松编写 mr 来使用 hadoop。
1.2 实验知识点
Python MRJob 模块的安装
Hadoop Python 各模块介绍
使用 MRJob 实现文本统计
Python MRJob 的运行方式
重写 MRJob 函数实现复杂数据处理
1.3 效果展示
该展示数据含义是通过 mrjob 将每个用户(cuid)看过哪些电影(vid)进行统计并输出。
"45f218b28d1949" ["09", "05", "12", "06", "02"]
"5E79247F1098C8" ["14"]
"622291a28c344a" ["12", "06", "15", "10", "01"]
1.4 实验环境
Hadoop-2.7.3
python3.5
mrjob v0.5.10
一、mrjob的安装
mrjob 可以通过 pip 直接安装,也可以通过下载源码通过 setup.py 安装,可参考 mrjob 安装说明。
本实验中,使用 shiyanlou 账户通过 sudo 权限进行安装。
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
使用 pip 安装 mrjob 的指令如下:
$ sudo python3 -m pip install mrjob
验证是否安装成功。首先输入下面的命令打开 python 交互式解释器:
$ python3
导入 mrjob 包,如果没有错误则说明安装正确。
import mrjob
Hadoop 的各 Python 框架对比
Hadoop Streaming
提供了使用其他可执行程序来作为 Hadoop 的 mapper 或者 reduce 的方式,必须使用规定的语义从标准输入读取数据,然后将结果输出到标准输出。直接使用 Streaming 的一个缺点是当 reduce 的输入是按 key 分组的时候,仍然是一行行迭代的,必须由用户来辨识 key 与 key 之间的界限。
mrjob
开源的 Python 框架,封装 Hadoop 的数据流,并积极开发 Yelp 的。由于 Yelp 的运作完全在亚马逊网络服务,mrjob 的整合与 EMR 是令人难以置信的光滑和容易(使用 boto 包)。
dumbo
同样使用 Hadoop 流包装的框架。dumbo 出现的较早,但由于缺少文档,造成开发困难。这也是不如 mrjob 的一点。dumbo 通过 typedbytes 执行序列化,能允许更简洁的数据传输,也可以更自然的通过指定 JavaInputFormat 读取 SequenceFiles 或者其他格式的文件
hadoopy
是一个兼容 dumbo 的 Streaming 封装,也使用 typedbytes 序列化数据,并直接把 typedbytes 数据写到 HDFS。它有一个很棒的调试机制, 在这种机制下它可以直接把消息写到标准输出而不会干扰 Streaming 过程。它和 dumbo 很相似,但文档要好得多。
pydoop
与其他框架相比,pydoop 封装了 Hadoop 的管道(Pipes),这是 Hadoop 的 C++ API。 正因为此,该项目声称他们能够提供更加丰富的 Hadoop 和 HDFS 接口,以及一样好的性能。需要注意的是所有的输入输出都必须是字符串。
其他
happy、Disco、octopy、Mortar、Luigi 等。
使用 mrjob 实现词组统计
使用 mrjob 进行编程,需要将用到的模块 import 进来,在实现处理逻辑的时候,只需继承(subclass)MRjob 类,并覆盖(override)mapper, combiner, reducer 等方法即可。
在编写多步任务(Multi step job)时,需要覆盖 steps 方法,并在 step 中返回一个由 mapper, combiner, reducer 等组成的 list。
启动 Hadoop 集群
$ su -l hadoop
# 密码:hadoop
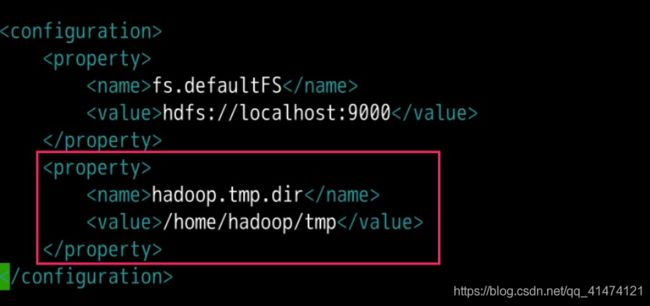
在 /opt/hadoop-2.7.3/etc/hadoop/core-site.xml 文件中添加如下代码用于配置 Hadoop 临时目录:
hadoop.tmp.dir</name>
/home/hadoop/tmp</value>
</property>
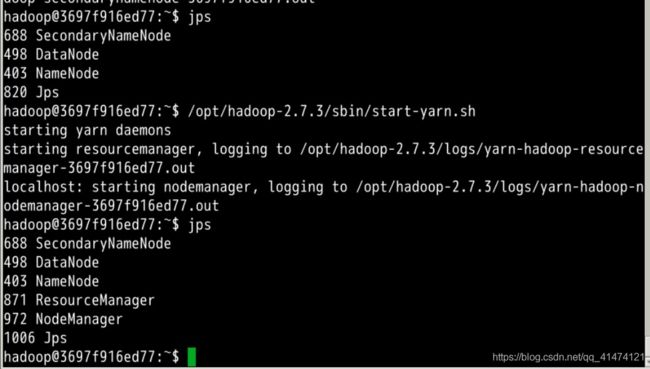
启动 hadoop 集群:
# 格式化 namenode
$ hdfs namenode -format
$ /opt/hadoop-2.7.3/sbin/start-dfs.sh
$ /opt/hadoop-2.7.3/sbin/start-yarn.sh
执行完成后,输入下面的命令查看进程是否启动成功:
$ jps
创建所需文件
在/home/hadoop目录下,新建pyhadoop文件夹,所有数据及代码放在该目录下。
$ cd /home/hadoop
$ mkdir pyhadoop && cd pyhadoop
在pyhadoop下新建data目录,存放小说《教父》数据。我们第一个实例是统计《教父》各个单词出现的次数。
$ mkdir data && cd data
小说《教父》下载目录https://labfile.oss.aliyuncs.com/courses/1167/Godfather.txt,通过wget下载。
$ wget https://labfile.oss.aliyuncs.com/courses/1167/Godfather.txt
代码实践
进入到 /home/hadoop/pyhadoop 目录下,新建 mymrjob.py,我们将在这个文件中实现文本中词组统计。
$ cd /home/hadoop/pyhadoop
$ touch mymrjob.py
编辑 mymrjob.py 文件,导入所需要的模块:
import os
import sys
from mrjob.job import MRJob
from mrjob.step import MRStep
from mrjob.protocol import RawValueProtocol,JSONProtocol,ReprProtocol
import traceback
我们将设计一个 WordCount 类,继承(subclass)MRjob 类:
class WordCount(MRJob):
这个类里面我们需要重写mapper、reducer函数,如果是多步处理,还需要重写step。
#覆盖mapper函数
def mapper(self, _, line):
#将每行输入拆分为单词list`在这里插入代码片`
linearry = line.split()
for word in linearry:
#对每一个单词,进行输出
yield word, 1
mapper() 函数接收传入的数据,这里是Godfather.txt里面的每行句子。通过split()函数将句子拆解成单词,然后再通过yield将处理结果输出或传入下面流程。如果此时直接运行脚本的话,会将所有的 word 以"word, 1"的形式输出出来,不过这对于我们来说没有任何意义,我们继续写reducer()函数。
#覆盖reducer函数
def reducer(self, key, value):
#对mapper输出的值进行sum求和操作
yield key,sum(value)
reducer() 函数的参数是 key、value,是 mapper 中传入的值,我们将 value 根据 key 值进行 sum 求和的操作,就实现了Godfather.txt中词组统计的目的。
完成了WordCount中 mapper、reducer 的重写,别忘了实现 main 函数。
if __name__ == '__main__':
WordCount.run()
最后,运行你写的 mymrjob 脚本实现词组统计。
$ python3 mymrjob.py -r hadoop data/Godfather.txt>1.txt
运行时的参数是python3 + 脚本 + “-r 运行方式” + 数据源 > 输出。数据源可以是本地数据,也可以是 hdfs 上数据,输出可以指定目录。数据源如果是本地,mrjob 会自动上传 hdfs 集群,创建临时文件,待程序运行完成,会自动删除。
打开1.txt文件,我们可以看到 hadoop 统计后的数据。如下:
······
"you'll" 36
"you're" 104
"you've" 21
"you," 66
"you,\"" 23
"you." 65
"you.\"" 34
"you:" 1
"you?" 10
"you?\"" 33
······
接下来,我们介绍一下 mrjob 的各种运行方式。
mrjob 多种运行方式
1、local 本地测试,直接在本地运行代码,检测代码是否有 bug;
2、inline 内嵌模式,在本地模拟 hadoop 集群上运行,特点是调试方便,启动单一进程模拟任务执行状态及结果,Mrjob 默认以内嵌方式运行(需要着重注意的是 inline 与 hadoop 最终 reducer 的全局排序与局部排序的区别);
3、hadoop 集群模式,在 hadoop 集群上运行;
4、emr Amazon EMR 模式,参照 aws;
5、dataproc Google Cloud Platform 模式,参照谷歌云平台 Google Cloud Platform。
实战模拟一
我们模拟一份用户观影的日志,日志是经过处理的 json 格式,下载地址是https://labfile.oss.aliyuncs.com/courses/1167/video.log。在 pyhadoop 下新建 log 目录,将 video.log 放入该目录下。
# 进入文件夹
$ cd /home/hadoop/pyhadoop
# 创建文件夹并下载文件
$ mkdir log && cd log
$ wget https://labfile.oss.aliyuncs.com/courses/1167/video.log
需要编写的代码文件用下面的命令创建:
# 回到上一级目录创建代码文件
$ cd /home/hadoop/pyhadoop
$ touch pyhd_1.py
我们需要实现的目标是通过这份日志来统计每部电影的热度,即每部电影有多少人观看过。
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1534551357, "data": "01"}
{
"user_id": "45f218b28d19492a94c2fb1853351b91", "action": 0, "timestamp": 1535673718, "data": "04"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1535750303, "data": "10"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1534970155, "data": "03"}
{
"user_id": "45f218b28d19492a94c2fb1853351b91", "action": 1, "timestamp": 1534902204, "data": "12"}
{
"user_id": "c6a63477030b4c048797b128f9a94306", "action": 1, "timestamp": 1535811065, "data": "02"}
{
"user_id": "45f218b28d19492a94c2fb1853351b91", "action": 1, "timestamp": 1535627866, "data": "02"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 1, "timestamp": 1535077655, "data": "07"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1534477688, "data": "04"}
{
"user_id": "622291a28c344a059428cb9112ff5933", "action": 1, "timestamp": 1535869832, "data": "01"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1535692131, "data": "12"}
{
"user_id": "c6a63477030b4c048797b128f9a94306", "action": 0, "timestamp": 1534436264, "data": "10"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1535413188, "data": "09"}
{
"user_id": "622291a28c344a059428cb9112ff5933", "action": 0, "timestamp": 1535768055, "data": "10"}
{
"user_id": "45f218b28d19492a94c2fb1853351b91", "action": 0, "timestamp": 1535187021, "data": "05"}
{
"user_id": "45f218b28d19492a94c2fb1853351b91", "action": 0, "timestamp": 1535757675, "data": "04"}
{
"user_id": "45f218b28d19492a94c2fb1853351b91", "action": 0, "timestamp": 1534546048, "data": "06"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 1, "timestamp": 1535732403, "data": "14"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1535235322, "data": "07"}
{
"user_id": "c6a63477030b4c048797b128f9a94306", "action": 0, "timestamp": 1534710059, "data": "13"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 1, "timestamp": 1535001990, "data": "15"}
{
"user_id": "622291a28c344a059428cb9112ff5933", "action": 1, "timestamp": 1535275346, "data": "10"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1535111069, "data": "07"}
{
"user_id": "45f218b28d19492a94c2fb1853351b91", "action": 1, "timestamp": 1535246953, "data": "06"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 1, "timestamp": 1535553547, "data": "04"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1535870611, "data": "14"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 1, "timestamp": 1535233150, "data": "06"}
{
"user_id": "c6a63477030b4c048797b128f9a94306", "action": 0, "timestamp": 1535447569, "data": "05"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1534718331, "data": "04"}
{
"user_id": "622291a28c344a059428cb9112ff5933", "action": 1, "timestamp": 1534862112, "data": "15"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 1, "timestamp": 1534111573, "data": "07"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1534798913, "data": "10"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1534553499, "data": "03"}
{
"user_id": "622291a28c344a059428cb9112ff5933", "action": 0, "timestamp": 1534887670, "data": "12"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 1, "timestamp": 1534812695, "data": "04"}
{
"user_id": "c6a63477030b4c048797b128f9a94306", "action": 0, "timestamp": 1534760524, "data": "12"}
{
"user_id": "622291a28c344a059428cb9112ff5933", "action": 1, "timestamp": 1534408381, "data": "12"}
{
"user_id": "5E79247F1098C82E436B5980AF98D67D", "action": 0, "timestamp": 1535158819, "data": "04"}
日志参数的含义如下:
1、user_id:用户 id,观影用户的唯一标识;
2、action:用户行为,0表示用户浏览电影信息,并未进行观看,1表示用户观看了电影;
3、timestamp:时间戳,表示用户行为的发生时间;
4、data:电影 id,被操作的电影 id。
实现思路
首先我们通过 mapper 将输入的每条日志转为电影id:1格式的key:value值。然后在通过 reducer 针对每个 key(电影)进行 sum 的求和操作。最后就能统计出每部电影的观看用户数量。
代码实现
mapper 的代码如下:
def mymapper(self, _, line):
#真实日志数据会有bad case,通过try排除bad case
try:
#将输入字符串转为json
jsline = json.loads(line)
cuid = jsline["user_id"]
action = jsline["action"]
video = jsline["data"]
#只有action=1即用户观看电影时,才会统计
if action == 1:
yield video,1
except Exception:
pass
reducer 的代码如下:
def myreducer(self, key, value):
#求知操作,统计每部电影观看人数
yield key,sum(value)
pyhd_1.py 的完整代码如下:
# -*- coding:utf-8 -*-
#!/usr/bin/python3
import os
import sys
from mrjob.job import MRJob
from mrjob.step import MRStep
from mrjob.protocol import RawValueProtocol, JSONProtocol,ReprProtocol
import traceback
import json
#统计每个电影有多少人观看过
class GetVideos(MRJob):
def steps(self):
return[
MRStep(mapper = self.mymapper,
reducer = self.myreducer)
]
def mymapper(self, _, line):
try:
jsline = json.loads(line)
cuid = jsline["user_id"]
action = jsline["action"]
video = jsline["data"]
if action == 1:
yield video,1
except Exception:
pass
def myreducer(self, key, value):
yield key,sum(value)
if __name__ == '__main__':
GetVideos.run()
新建 output 文件夹用于存放输出:
$ mkdir /home/hadoop/pyhadoop/output
运行代码:
$ python3 pyhd_1.py -r hadoop log/video.log > output/1.txt
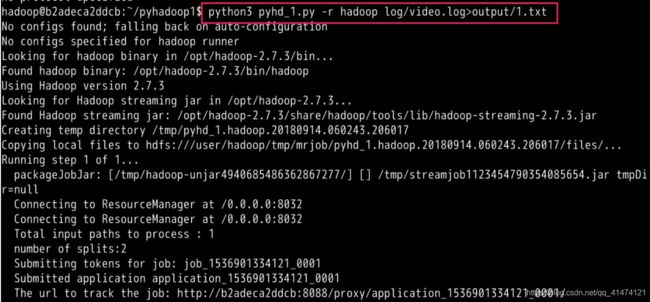
结果输出在 output/1.txt 文件中:
"01" 1
"02" 2
"03" 1
"04" 2
"05" 1
"06" 3
"07" 2
"09" 1
"10" 1
"11" 1
"12" 3
"14" 3
"15" 2
为了方便大家理解,我将序号对应的电影名称列出来,如下:
01 一出好戏
02 大三儿
03 精灵旅社3:疯狂假期
04 巨齿鲨
05 欧洲攻略
06 快把我哥带走
07 新乌龙院之笑闹江湖
08 西虹市首富
09 小偷家族
10 爱情公寓
11 美食大冒险之英雄烩
12 狄仁杰之四大天王
13 神秘世界历险记4
14 最后的棒棒
15 风雨咒
实战模拟二
上述实验统计了每部电影的被观看次数,那么如何统计每部电影的观看用户列表呢?
实现思路
mrjob 允许开发者通过重写覆盖父函数来实现更为复杂的数据处理。除了多步任务需要覆盖的 steps 方法,mrjob 还可覆盖重写以下函数:
mapper_init()
combiner_init()
reducer_init()
mapper_final()
combiner_final()
reducer_final()
为了实现本实战模拟的任务,我们需要覆盖mapper_init()。首先我们要进行一轮mapper-reducer将输入的 json 日志行转变为key-value格式的video-cuid值,这个过程会通过reducer将key进行排序;然后我们通过覆盖第二轮mapper-reducer中的mapper_init()实现将相同key值的value进行聚合。
需要注意的是,为了不让第一轮 MR 将同一cuid的其他vid值reducer掉,同时还能实现排序效果,我们将key值定义为cuid,timestamp,理论上同一时间点,一个用户只能操作一部电影,这样就保证了value值的完整性。
代码实现
def steps(self):
return[
MRStep(mapper = self.mymapper_1,
reducer = self.myreducer_1),
MRStep(mapper_init = self.mymapper_init_2,
mapper = self.mymapper_2)
]
重写mapper_init()实现列表统计逻辑:
def mymapper_init_2(self):
self.video = ""
self.uidlist = []
def mymapper_2(self, key, value):
cuid = value
vid = key[0]
if self.video != "" and self.video != vid:
#print(self.video, self.uidlist, value)
yield self.video,self.uidlist
self.video = ""
self.uidlist = []
if self.video == vid:
if cuid not in self.uidlist:
self.uidlist.append(cuid)
else:
self.video = vid
self.uidlist.append(cuid)
在 /home/hadoop/pyhadoop 目录下新建 pyhd_2.py 文件,完整代码如下所示:
# -*- coding:utf-8 -*-
#!/usr/bin/python3
import os
import sys
from mrjob.job import MRJob
from mrjob.step import MRStep
from mrjob.protocol import RawValueProtocol, JSONProtocol,ReprProtocol
import traceback
import json
#统计每个电影有哪些用户观看
class GetVideos(MRJob):
def steps(self):
return[
MRStep(mapper = self.mymapper_1,
reducer = self.myreducer_1),
MRStep(mapper_init = self.mymapper_init_2,
mapper = self.mymapper_2)
]
def mymapper_1(self, _, line):
try:
jsline = json.loads(line)
cuid = jsline["user_id"]
timestmp = jsline["timestamp"]
action = jsline["action"]
video = jsline["data"]
if action == 1:
yield (video,timestmp),cuid
except Exception:
pass
def myreducer_1(self,key,value):
yield key,max(value)
def mymapper_init_2(self):
self.video = ""
self.uidlist = []
def mymapper_2(self, key, value):
cuid = value
vid = key[0]
if self.video != "" and self.video != vid:
#print(self.video, self.uidlist, value)
yield self.video,self.uidlist
self.video = ""
self.uidlist = []
if self.video == vid:
if cuid not in self.uidlist:
self.uidlist.append(cuid)
else:
self.video = vid
self.uidlist.append(cuid)
if __name__ == '__main__':
GetVideos.run()
运行代码:
$ python3 pyhd_2.py -r hadoop log/video.log>output/2.txt
最后查看 output/2.txt 文件,结果如下:
"01" ["622291a28c344a059428cb9112ff5933"]
"02" ["45f218b28d19492a94c2fb1853351b91", "c6a63477030b4c048797b128f9a94306"]
"03" ["c6a63477030b4c048797b128f9a94306"]
"04" ["5E79247F1098C82E436B5980AF98D67D"]
"05" ["45f218b28d19492a94c2fb1853351b91"]
"06" ["622291a28c344a059428cb9112ff5933", "5E79247F1098C82E436B5980AF98D67D", "45f218b28d19492a94c2fb1853351b91"]
"09" ["45f218b28d19492a94c2fb1853351b91"]
"10" ["622291a28c344a059428cb9112ff5933"]
"11" ["c6a63477030b4c048797b128f9a94306"]
"12" ["5E79247F1098C82E436B5980AF98D67D", "622291a28c344a059428cb9112ff5933", "45f218b28d19492a94c2fb1853351b91"]
"14" ["c6a63477030b4c048797b128f9a94306", "5E79247F1098C82E436B5980AF98D67D"]
另外实验楼用户liullgg提出上述统计不够准确,修正后的参考代码如下所示:
# -*- coding:utf-8 -*-
#!/usr/bin/python3
import os
import sys
from mrjob.job import MRJob
from mrjob.step import MRStep
import json
# 统计每个电影有哪些用户观看
class GetVideos(MRJob):
def steps(self):
return[ MRStep(mapper = self.mymapper_1, reducer = self.myreducer_1), ]
def mymapper_1(self, _, line):
try:
jsline = json.loads(line)
cuid = jsline["user_id"]
timestmp = jsline["timestamp"]
action = jsline["action"]
video = jsline["data"]
if action == 1:
yield video,cuid
except Exception:
pass
def myreducer_1(self,key,value):
list = sorted(value)
list_new = sorted(set(list), key=list.index)
# print(list_num_new)
yield key,list_new
if __name__ == '__main__':
GetVideos.run()
运行结果如下所示,提供给大家参考:

实战模拟挑战
参照[2.6实战模拟]统计每部电影的观看用户列表,实现通过 mrjob 统计每个用户的观影列表。
结果如下:
"45f218b28d19492a94c2fb1853351b91" ["09", "05", "12", "06", "02"]
"5E79247F1098C82E436B5980AF98D67D" ["14"]
"622291a28c344a059428cb9112ff5933" ["12", "06", "15", "10", "01"]
实现思路
参照2.6实验,我们首先需要通过一轮 MR 将日志处理为cuid-vid格式的值,而且是根据cuid排过序的。然后我们通过第二轮 MR 覆盖mapper_init()函数,将vid根据cuid进行聚合。最终输出目标结果。
代码实现
重写 steps 进行多步操作。
def steps(self):
return[
MRStep(mapper = self.mymapper_1,
reducer = self.myreducer_1),
MRStep(mapper_init = self.mymapper_init_2,
mapper = self.mymapper_2)
]
进行第一轮的 MR,将日志转为key-value格式的(cuid,timestamp)-vid。
def mymapper_1(self, _, line):
try:
jsline = json.loads(line)
cuid = jsline["user_id"]
timestmp = jsline["timestamp"]
action = jsline["action"]
video = jsline["data"]
if action == 1:
yield (cuid,timestmp),video
except Exception:
pass
def myreducer_1(self,key,value):
yield key,max(value)
进行第二轮的 MR,该过程只需要 mapper。通过覆盖mapper_init()实现vid的聚合。
def mymapper_init_2(self):
self.cuid = ""
self.videolist = []
def mymapper_2(self, key, value):
cuid = key[0]
vid = value
if self.cuid != "" and self.cuid != cuid:
#print(self.video, self.uidlist, value)
yield self.cuid,self.videolist
self.cuid = ""
self.videolist = []
if self.cuid == cuid:
if vid not in self.videolist:
self.videolist.append(vid)
else:
self.cuid = cuid
self.videolist.append(vid)
在 /home/hadoop/pyhadoop 目录下新建 pyhd_3.py 文件,完整代码如下所示:
# -*- coding:utf-8 -*-
#!/usr/bin/python3
import os
import sys
from mrjob.job import MRJob
from mrjob.step import MRStep
from mrjob.protocol import RawValueProtocol, JSONProtocol,ReprProtocol
import traceback
import json
#统计每个用户看过多少电影
class GetVideos(MRJob):
def steps(self):
return[
MRStep(mapper = self.mymapper_1,
reducer = self.myreducer_1),
MRStep(mapper_init = self.mymapper_init_2,
mapper = self.mymapper_2)
]
def mymapper_1(self, _, line):
try:
jsline = json.loads(line)
cuid = jsline["user_id"]
timestmp = jsline["timestamp"]
action = jsline["action"]
video = jsline["data"]
if action == 1:
yield (cuid,timestmp),video
except Exception:
pass
def myreducer_1(self,key,value):
yield key,max(value)
def mymapper_init_2(self):
self.cuid = ""
self.videolist = []
def mymapper_2(self, key, value):
cuid = key[0]
vid = value
if self.cuid != "" and self.cuid != cuid:
#print(self.video, self.uidlist, value)
yield self.cuid,self.videolist
self.cuid = ""
self.videolist = []
if self.cuid == cuid:
if vid not in self.videolist:
self.videolist.append(vid)
else:
self.cuid = cuid
self.videolist.append(vid)
if __name__ == '__main__':
GetVideos.run()
运行代码:
$ python3 pyhd_3.py -r hadoop log/video.log>output/3.txt
实验总结
本次实验通过简单却又赋有代表性的例子跟大家分享了 mrjob 的使用经验,希望大家能反复琢磨这几个简单例子,完全理解以后,我相信会对大家使用 mrjob 进行大数据处理有很大帮助。
本次实验缺少对 hadoop 集群的介绍,大家可以参照实验楼其他课程关联学习。
完整代码
代码及数据下载地址:
wget https://labfile.oss.aliyuncs.com/courses/1167/pyhadoop.zip