【论文笔记】BlockFLA: Accountable Federated Learning via Hybrid Blockchain Architecture

0. 关键词
混合区块链、超链、以太坊、机器学习、后门攻击、联邦学习、联邦平均
1. 摘要
隐藏训练数据使攻击者有机会向训练好的模型注入后门攻击。很多研究试图通过设计健壮的聚合函数来减轻后门攻击的威胁,作者从一个互补的角度来研究这个问题——目标使通过检测和惩罚攻击来阻止后门攻击。为此,作者开发了一个基于区块链的混合FL框架,该框架使用智能合约来自动检测并通过罚款来惩罚攻击者。文章设计的框架是通用的,任何聚合函数和任何攻击者检测算法都可以插入其中。作者进行了实验来证明框架的通信效率,并提供了实验结果来说明它可以通过作者设计的新的攻击者检测算法来成功地惩罚攻击者。【没有设“防”,只进行“检测&惩罚”。让敌手“知难而退”?】
后门攻击希望在模型的训练过程中通过某种方式在模型中埋藏后门(backdoor),埋藏好的后门通过攻击者预先设定的触发器(trigger)激发。在后门未被激发时,被攻击的模型具有和正常模型类似的表现;而当模型中埋藏的后门被攻击者激活时,模型的输出变为攻击者预先指定的标签(target label)以达到恶意的目的。后门攻击可以发生在训练过程非完全受控的很多场景中,例如使用第三方数据集、使用第三方平台进行训练、直接调用第三方模型,因此对模型的安全性造成了巨大威胁。
本段引用摘自:https://zhuanlan.zhihu.com/p/160964591
2. 主要贡献
- 1)提出了基于区块链的联邦学习(BlockFLA)。这是一个旨在提供问责机制来防止敌对攻击的通用FL框架,任何的聚合函数和任何的攻击检测算法都可以插入其中。
- 2)提供了一种新的攻击检测算法,特别针对像素模式后门攻击设计的,并通过实验证明了其有效性。
- 3)我们展示了在不同设置下对BlockFLA的评估。
- 4)详细分析了BlockFLA提供的安全性和隐私性。
3. 背景知识
联邦学习和区块链的介绍,不再赘余。
后门攻击和模型中毒
针对机器学习的训练时间,攻击大致分为两类:有目标攻击和无目标攻击。
在无目标攻击中,敌对的任务是使模型收敛到次优最小值,或者使模型完全发散,这种攻击也称为收敛攻击。在某种程度上,它们很容易通过观察模型在验证数据上的准确性来检测。以图片分类为例,攻击者只需要让目标模型对样本分类错误即可,但并不指定分类错成哪一类。
在有目标攻击中,对手希望模型只对一组选定的样本进行错误分类,同时对其在主要任务上的性能影响最小。攻击者指定某一类,使得目标模型不仅对样本分类错误并且需要错成指定的类别。从难度上来说,有目标攻击的实现要难于无目标攻击。实施后门攻击的一个突出方式是通过特洛伊木马。
在FL中,训练数据是分散的,聚合服务器只接受模型更新。鉴于此,后门攻击通常是通过构建恶意更新来实现的。也就是说,对手试图创建对一个后门进行编码的更新,这样,当它与其他更新聚合在一起时,聚合模型就会显示后门。这被称为模型中毒攻击。例如,敌手可以控制FL实例中的一些参与代理,并在安装了木马的数据集上训练它们的本地模型来构建恶意更新。
4.系统结构
在文章中,作者提出了一个系统架构,它允许运行任何联邦学习算法,同时支持可审计性。还可以安全检测模型的特洛伊木马,并惩罚违规方。
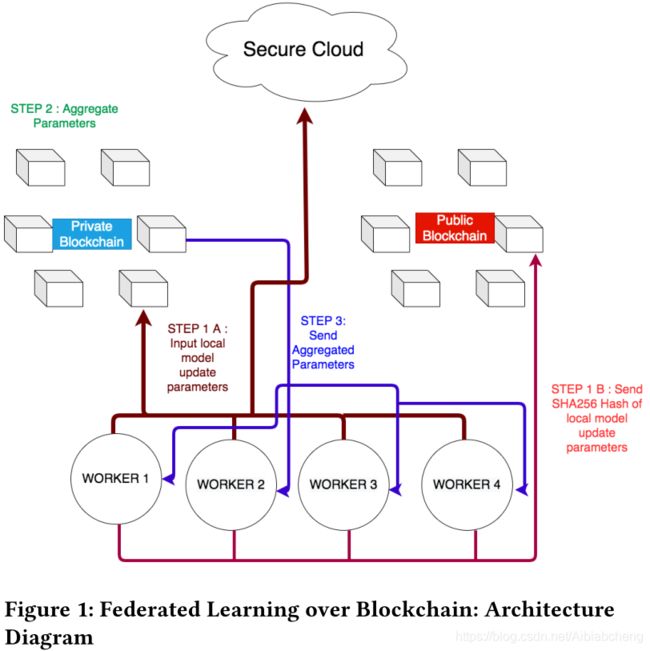
- step 1-A:本地模型将参数上传至私链,同时也记录到安全云中。(详解见原文3.5)
- step 1-B:将相应生成的本地更新的SHA256散列发送到公链,用于验证。(详解见原文3.3)
- step 2:模型参数聚合在私链(服务器)上进行。(并没有去完全中心化,和其他文章的本地更新不同)
- step 3:聚合参数形式的全局更新被发送回下一轮的每个worker。
4.1链上聚合
模型的训练由参与收敛过程的个体工作者在链外进行。
这篇文章中,联邦学习中的服务器由私有链表示,私有链执行聚合并江全局更新返回给worker。在部署在私链的智能合约的帮助下,执行所有工作者-区块链通信(all worker-blockchain communication)。私链与每个worker都在同一个网络中。
由于这是一个私链,每个账户都由一个权威机构发行。在这种情况下,建立私链的结点充当向每个worker提供成员资格的最终权威。证书由服务器证书颁发机构(CA)签发,以便工作节点通过在SSL上维护TLS链接来发送和接收来自服务器的参数。然后,worker等待上传参数到私有区块链,直到它从链码接收到聚合参数形式的响应。在收集聚合参数时,worker会移动到下一个迭代以重新训练其模型并重新发送更新的参数。
链上的服务器将等待每个worker都发送了模型参数。一旦从每个工作节点受到更新,服务器/私链将确认收到的每个参数实例的完整性。检查的内容包括更新的大小、接收到的更新的类型以及发送方是否使用了合适的凭证来发送更新。当服务器聚合参数完成后,worker开始下一次迭代。
任何worker都不能再同一时期内两次上传参数。一旦全部worker都成功上传,就进行聚合。
4.2公共分类账的验证
【这部分讲公链的作用】
对公链的验证是以所有人都可见的智能合约的形式。私链上的每个工作节点在公链上都有一个账户,私链维护的账户和公链上的账户有一个一对一的映射。每个worker必须在公链上拥有一个带有足够加密货币或交易货币的钱包,以便在发送更新时调用智能合约函数。
公链上智能合约的作用有3个:
1)存储发送的参数的SHA256哈希值;
2)验证功能。用于验证参与者或参与者的子集是否有作弊行为;
3)管理/负责押金和罚款。
智能合约为每个工作节点设了一个数组,用于存储发送到私链服务器的每个参数集的加密(即SHA256)哈希。哈希值由链外的每个工作节点在它们自己的本地机器上单独计算,并发送到公共智能合约(如上图step1B)。这里服务的主要目的是让任何工作人员在检测到特洛伊木马的情况下追究任何违规工作节点的责任。由于公共链是透明且不可变的,所以工作节点只能下载SHA256,从私有链上的参数存储中检索重新创建的SHA256,并验证存储在公共链上的SHA256是否与创建的私有链SHA256匹配。
4.3 惩罚结构
worker参与模型训练的主要动机是金钱,这种货币利益是以加密货币的形式实现的。
每个worker必须拥有一个加密钱包,并通过公链提交存款。完成后,当模型收敛时,该奖励返还给worker,此外,每位诚实的worker也会获得一份奖励。(该奖励取决于将模型参数发送发哦服务器进行聚合所花费的平均时间。参数发送的越快,奖励就越多。)如果一个worker结点被其他worker发现发送引入特洛伊木马的更新,押金丢失并重新分配给其他的worker。
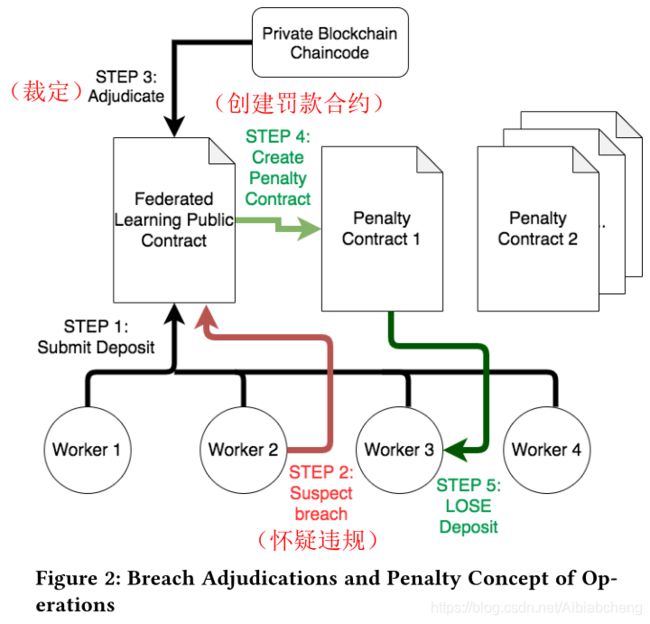
如图所示,如果worker怀疑某个worker违规,公链会创建一个验证合约,并检查被告是否真的违规。如果违规行为被证实,则被告将失去存款;如果没有真正违规,原告就失去保证金。
4.4 安全云上的日志方案
日志发布。
每一轮结束后,每个worker发送日志到安全云。日志存储在基于安全云的文件系统中,其中每个工作人员都有自己唯一的存储位置,并且在每一轮之后,该位置将具有来自除该worker之外的聚合参数的测试分类结果(是否违规/有效的验证结果)。日志包括以下内容:
1)每个worker节点上传的参数;
2)在通过排除该worker上传的参数来聚集参数之后,测试每一轮的分类结果。
【疑问:验证是否有效,是测试将第i个worker的参数剔除后,与剩余N-1个worker参数聚合的结果进行比较,是更好还是更差,以此来验证第 i 个worker是否违规???】
异常警报策略。
每当参与者怀疑某个worker违规时,他会通过调用公链的智能合约,该合约保存了每个worker本地更新的SHA256哈希。根据私链的确认信息,如果私链能够根据本地更新生成与公共智能合约上的哈希相匹配的SHA256哈希,那么嫌疑人上传的参数就是诚实的。现在,对于特洛伊木马检测,私链将提供嫌疑人在安全云上日志位置的一次性的链接。参与者可以下载包含被指控方本地参数更新的日志,并运行特洛伊木马检测算法(下一节介绍)。如果被检测到木马,嫌疑人将收到惩罚。
智能合约上的SHA256散列数组的形式存储。每个worker都有自己的数组。
4.5 一种针对恶意攻击的攻击者检测算法
假设验证者可以访问后门模型、特洛伊木马模式以及对手使用的原始标签和目标标签的信息。验证者还可以访问在执行FL期间发送的模型更新(因为更新被记录在安全云中)。
检测算法背后的关键思想是通过计算经验费歇尔信息矩阵(FIM)来完成参数属性。在高层次上,验证者首先使用对手的特洛伊木马模式创建中毒的验证集。也就是说,他从干净的验证数据集中提取原始类别(base class),将它们添加到特洛伊木马模式中,并将它们重新标记为目标类。然后,他使用记录的更新 回放训练过程。每一轮之后,他使用聚合模型计算中毒验证数据集的后门损失。然后,对于后门损失减少的回合,验证者通过FIM使用中毒验证数据集对聚合模型进行参数归属。这允许验证者按照后门任务的重要性顺序列出模型的参数,因此她可以识别后门任务的前k个最重要的参数(其中k是超参数)。最后,开发人员测量并记录每个代理对这k个参数的更新的L2范数。
向量范数 2-范数:
,欧几里得范数,即向量元素绝对值的平方和再开方。(就是)
矩阵范数 2-范数:
,
为
的最大特征值,即
的最大特征值的开平方。
当后门损失减少时,对于最重要的后门任务参数,我们期望攻击者的贡献大于诚实代理的贡献。然后,通过查看所记录的所有回合的L2范数的平均值,并对敌对代理的数量做出假设,验证者可以尝试区分攻击者。也就是说,对后门任务的top-k重要参数贡献最大的代理可能是敌对的。在第3.6节通过实验说明了我们算法的性能。
5. 实验部分
实验目的:测试集成了联邦平均算法和 SignSGD算法的混合区块链的影响,评估系统的惩罚结构和安全性评估。
使用hyperledger提供的fabric docker containers,把它部署在m5.12xlarge EC2实例上。
使用openssl生成自签名证书颁发机构(CA),并向由CA签名的对等节点办法客户端证书。编写Nodejs脚本来控制chaincode的部署和命令驱动例程中通道的创建,Nodejs脚本来充当hyperledger结构和ethereum网络之间的连接。实验使用以太坊智能合约自动生成技术在公链上支付罚款。初始时,每个账户都有10个以太坊。
signSGD使用了二进制到base64的转换器,将参与者提供的参数转换为base64并上传到chaincode。使用Fabric提供的对等二进制文件来上传参数。
文章没有给出训练准确性方面的结果。(因为作者认为不会有误差,没必要给出)
由于基于智能合约的区块链的特性,模型性能可能会发生较大的变化,所以作者为了了解影响整体性能的因素,在不同的聚合方案和不同的DL模型大小下进行了一轮更新实验。为了实验,作者基于常用的DL模型调整了DL模型的大小(即DL模型使用的可训练参数的数量。例如,AlexNet有约6000万个可训练参数;VGG16等比较新的架构有约1.6亿个可训练参数)。实验改变每轮更新的参数数量来测试性能,参数的数量范围是从5000万到3亿个(这个范围涵盖了大多数的DL模型)。
6. 实验结果
6.1 单合约 V.S. 多合约 (SignSGD)
每个客户端在每轮中要上传10K(20000个字符)的参数,这就意味着每个函数调用客户端最多加载13300个base64字符。对于本地和AWS设置,作者比较了使用单合约和多合约来上传参数并随后执行聚合的情况。如果有多个合约,参数加载到超分类账本框架上是并行完成的,智能合约的每一系列上传都有自己的线程在后台运行。
对于单线程/单合约系统,参数最多被350个事务加载,每个更新后都有一个事件更新,以通知客户端发送另一个更新。
因为参数是按顺序上传的,在本地和远程服务设备中,上传参数最多花5分钟。然后将合约数量增加到2倍,上传参数的时间在60秒内。随着合约数量的进一步增加,上传时间明显缩减。32个并行合约时,能实现任何的signSGD在9秒内上传完成。如果使用48个并行合约上传所有的参数,上传时间时5秒。这是使用私链而不用公链的主要优势(事务吞吐量高,20000个/秒)。如果有更好的处理能力,甚至能够在几分之一秒内上传完所有参数。
图4是参数上传时间随并行合约数量的变化。

如表1所示,任何联邦学习signSGD设置,聚合时间总是小于5秒,(3亿个参数时)。如果将表1和图4相加,对于当前系统中的每个worker,5-10轮的话,运行聚合和参数上传所需的总时间不到1.5分钟。
(下面两个表的结果都是展示的最坏情况下的数据。应该是作者做了多次重复实验)

6.2 单合约 V.S. 多合约 (FedAvg)
每个客户端每轮加载130KB(33000 float32)。实验设置与signSGD相同。对于参数的顺序上传,需要25分钟。
如上图4,随着合约数的增加,上传时间显著缩短。16个并行合约时,约3分钟。48个合约时,上传3.3亿个参数需要大约1.5分钟。
如表1(b),联邦平均的聚合时间都在10秒以内(因为它是在分类账上完成的,并且只消耗一个事务来返回结果)。将表1(b)和图4相加,对于每个结点,5-10个周期,大约需要12分钟。
6.3 参数变化的性能分析
图5是参数上传时间随每次更新参数数量的变化。(16个并行合约时)
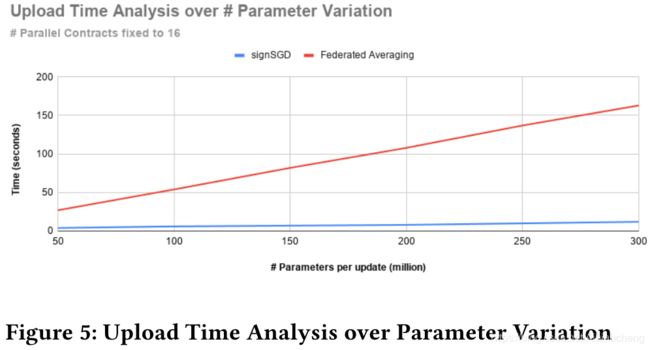
如图5所示,通过部署的并行合约的数量不变(16个),增加联邦学习算法要上传的参数数量,将所有参数上传到私链所需时间逐渐增加。
对于signSGD,上传5000万个参数到私链大概需要4秒,上传3亿个参数需要12秒。
对于联邦平均,向私链上传5000万参数需要27秒,上传3亿参数需要163秒。
6.1-6.2-6.3都在说明:在混合区块链设置上可以实现通信高效的联邦学习。
6.4 混合链 V.S. 全公链
作者还部署了一个执行与golang hyperledger chaincode 相同操作的并行智能合约,并将其在以太坊私链上。
执行联邦平均操作时,将参数上传到以太坊智能合约中时,耗时1300多秒。而聚合过程耗时约450秒。全公链的耗时都远高于混合链的耗时。
6.5 公链的Gas和时间分析
首先介绍一下Gas是什么。
Gas:以太坊上的每笔交易都会被收取一定数量的燃料Gas,设置Gas的目的时限制交易执行所需的工作量,同时为交易的执行支付费用。当EVM执行交易时,Gas将按照特定规则被逐渐消耗。Gas价格由交易创建者设置,发送账户预付的交易费用 = GASPRICE * Gas amount。如果执行结束还有Gas剩余,这些Gas将被返还给发送账户。无论执行到什么位置,一旦Gas被耗尽就会触发一个out-of-gas异常。同时,当前调用帧所做的所有状态修改都将被回滚。——引用自《区块链技术指南》(邹均等著)机械工业出版社 2018.
一个以太坊Gas的价格是0.02 ![]() (微 以太)。
(微 以太)。
如图3(a),第一轮将SHA256哈希上传到公链所需的Gas量接近95000Gas(折合0.0019 Ether),后面每轮将消耗25000Gas(折合0.0005Ether)来上传SHA256。第一次上传成本高是因为它要初始化智能合约上的数据结构。
如图3(b),从客户端上传的SHA256哈希在35秒到75秒之间变化。这意味着公链上的每个事务确认都独立于哈希的大小,因此如果考虑性能,在公链上存储真实参数时不可靠的。

7. 攻击者检测算法的性能
作者模拟了K个代理进行R轮的联邦学习,其中F部分被破坏(什么意思?)。假设一个对手通过向原始实例添加特洛伊木马,并将其标记为目标类,从而破坏腐败代理的本地数据集。除此此外,对手不能查看和修改诚实代理的更新,或者不能影响诚实代理和聚合服务器完成的计算。服务器每轮统一采样![]() 个代理进行训练,其中
个代理进行训练,其中![]() 。Those agents locally train for E epochs with a batch size of B before sending their updates.
。Those agents locally train for E epochs with a batch size of B before sending their updates.
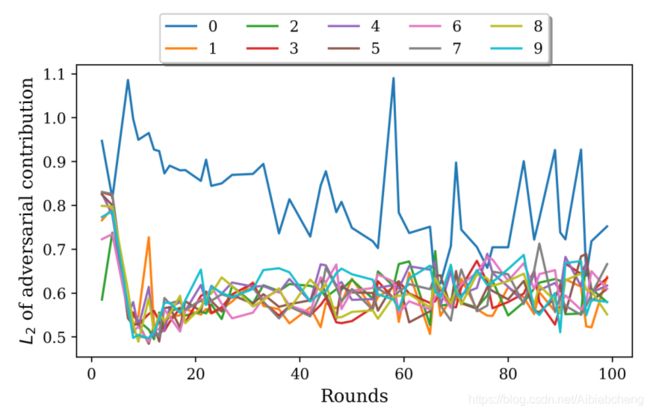
作者在CIFAR10数据集上测试检测算法,使用了一个由1.2M个参数组成的5层CNN(两层卷积,随后是max-pooling,最后是两个有丢失的完全连接层)。能够在下面四种设置的三种检测到敌对代理。
前两种情况下,实验设了10个代理,其中一个是敌手。图7是后门损失减少的回合的中对攻击贡献的L2范数。攻击者是0号,可以看出它在后门攻击中拥有最大的L2范数。
第一个图是独立同分布的,第二个图是非独立同分布的。在非iid环境中,代理人的贡献方差更高。计算这些回合的平均L2贡献,0号代理位于顶部,值为0.78,其次是9号代理(0.67)、6号代理(0.65).在iid中,数据在代理之间均匀分布,而在非iid设置中,通过从浓度为0.5的迪利克雷分布采样来分布每个类。
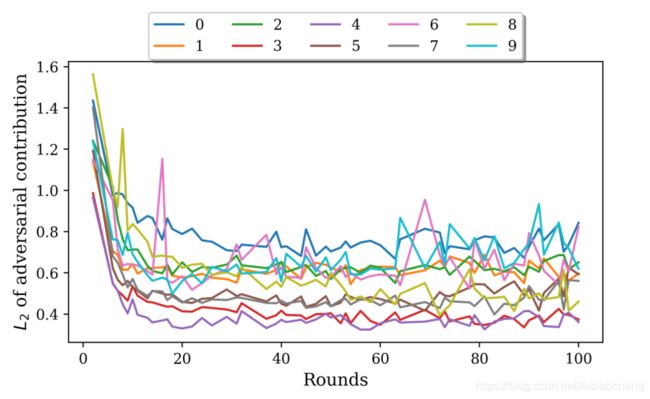

实验3:设置100个代理,其中10个敌手。聚合服务器每轮从代理中统一抽取10个。作者的检测算法在iid情况下能供很好的检测出敌对代理(100%);但是在非iid情况下,效果较差(只找到了4个)。作者怀疑是因为non-iid情况下,对抗贡献的方差较高。