pytorch 对抗样本_图像分类比赛tricks:“观云识天”人机对抗大赛:机器图像算法赛道-天气识别—百万奖金...

最终决赛排名:第五名(和兴路天团)
比赛数据集:
链接: https://pan.baidu.com/s/1yykdqqxXY_9eCgioHfAmTg
提取码: kbxy
参赛背景(“观云识天”人机对抗大赛)
根据大赛组织方提供的图片数据训练算法,能够区分降雨、降雪、冰雹、露、霜、雾(霾)、雾凇、雨凇、电线积冰9种天气现象。
赛题分析
数据存在的问题:
- 数据量小
- 样本不均衡
- 数据集噪声大
- 对天气知识的先验知识不足
解决方案
- 数据清洗
- 数据增强:几何变换、CutMix等
- 数据不均衡
- 标签平滑
- 双损失函数
- 优化器:RAdam LookAhead
- 深度模型ResNeXt101系列,EfficientNet系列。
- 注意力机制
- SVM替换softmax层
- 模型融合:VotingClassifier
- TTA:测试时增强
比赛思路
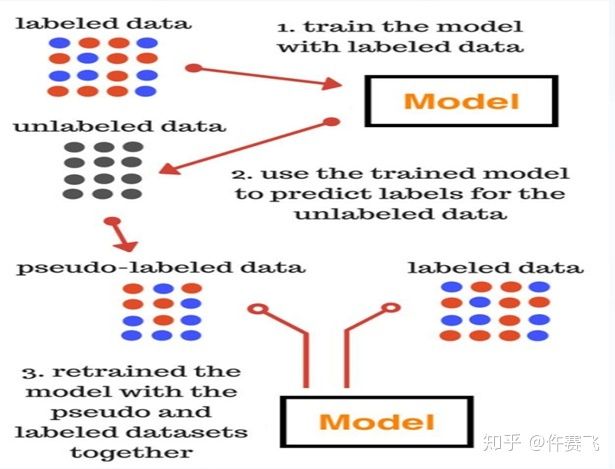
1.数据清洗
借助弱监督方式引入外部数据集中的高质量数据——解决了自行扩展数据集带来的测试偏移。步骤如下:
- 使用训练数据建立模型
- 预测爬取的数据的标签,对外部数据进行伪标签标注。
- 结合样本分布和混淆矩阵的结果,设置了多级阈值,选择可信度高的数据,组合成新的数据集
- 重复1,2,3。
2.数据增强
- 几何变换——只进行水平翻转和平移0.05
transforms.RandomAffine(degrees=0, translate=(0.05, 0.05)),
transforms.RandomHorizontalFlip()2. CutMix
CutMix正规化器的Pytorch官方实现
3.数据不均衡
在数据层面和算法层面同时测试选取—— 上采样和class_wight相结合
- 上采样——通过混淆矩阵和验证集的随机化设置,提取模型预测错误的数据,然后按照一定的权重进行数据复制扩充,为了减少上采样可能带来的过拟合问题,我们对扩充的数据进行了区域裁剪,使数据更倾向于需要关注的部分。
- class_weight——将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)。该参数在处理非平衡的训练数据(某些类的训练样本数很少)时,可以使得损失函数对样本数不足的数据更加关注。
4.数据标签平滑
目的:减小过拟合问题
平滑过后的样本交叉熵损失就不仅考虑到了训练样本中正确的标签位置的损失,也稍微考虑到其他错误标签位置的损失,导致最后的损失增大,导致模型的学习能力提高,即要下降到原来的损失,就得学习的更好,也就是迫使模型往增大正确分类概率并且同时减小错误分类概率的方向前进。
#!/usr/bin/python
# -*- encoding: utf-8 -*-
import torch
import torch.nn as nn
class LabelSmoothSoftmaxCE(nn.Module):
def __init__(self,
lb_pos=0.9,
lb_neg=0.005,
reduction='mean',
lb_ignore=255,
):
super(LabelSmoothSoftmaxCE, self).__init__()
self.lb_pos = lb_pos
self.lb_neg = lb_neg
self.reduction = reduction
self.lb_ignore = lb_ignore
self.log_softmax = nn.LogSoftmax(1)
def forward(self, logits, label):
logs = self.log_softmax(logits)
ignore = label.data.cpu() == self.lb_ignore
n_valid = (ignore == 0).sum()
label = label.clone()
label[ignore] = 0
lb_one_hot = logits.data.clone().zero_().scatter_(1, label.unsqueeze(1), 1)
label = self.lb_pos * lb_one_hot + self.lb_neg * (1-lb_one_hot)
ignore = ignore.nonzero()
_, M = ignore.size()
a, *b = ignore.chunk(M, dim=1)
label[[a, torch.arange(label.size(1)), *b]] = 0
if self.reduction == 'mean':
loss = -torch.sum(torch.sum(logs*label, dim=1)) / n_valid
elif self.reduction == 'none':
loss = -torch.sum(logs*label, dim=1)
return loss
if __name__ == '__main__':
torch.manual_seed(15)
criteria = LabelSmoothSoftmaxCE(lb_pos=0.9, lb_neg=5e-3)
net1 = nn.Sequential(
nn.Conv2d(3, 3, kernel_size=3, stride=2, padding=1),
)
net1.cuda()
net1.train()
net2 = nn.Sequential(
nn.Conv2d(3, 3, kernel_size=3, stride=2, padding=1),
)
net2.cuda()
net2.train()
with torch.no_grad():
inten = torch.randn(2, 3, 5, 5).cuda()
lbs = torch.randint(0, 3, [2, 5, 5]).cuda()
lbs[1, 3, 4] = 255
lbs[1, 2, 3] = 255
print(lbs)
import torch.nn.functional as F
logits1 = net1(inten)
logits1 = F.interpolate(logits1, inten.size()[2:], mode='bilinear')
logits2 = net2(inten)
logits2 = F.interpolate(logits2, inten.size()[2:], mode='bilinear')
# loss1 = criteria1(logits1, lbs)
loss = criteria(logits1, lbs)
# print(loss.detach().cpu())
loss.backward()
5.双损失函数
categorical_crossentropy 和 Label Smoothing Regularization :在对原始标签进行平滑的过程中,可能存在某些数据对标签变化特别敏感,导致损失函数的异常增大,使模型变得不稳定,为了增加模型的稳定性所以使用双损失函数——categorical_crossentropy 和 Label Smoothing Regularization,即保证了模型的泛化能力,又保证了数据不会对标签过于敏感,增加了模型的稳定性。
criterion = L.JointLoss(first=nn.crossentropyloss(), second=LabelSmoothSoftmaxCE(),
first_weight=0.5, second_weight=0.5)6.优化器
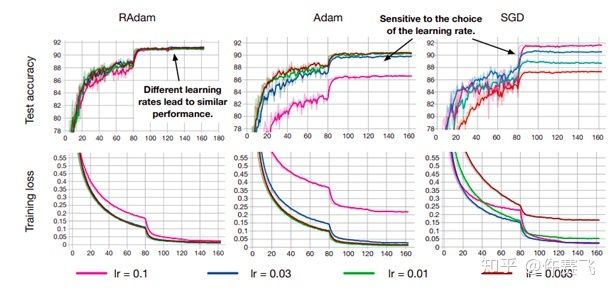
RAdam LookAhead:兼具Adam和SGD两者的优化器RAdam,收敛速度快,鲁棒性好LookAhead对SGD进行改进,在各种深度学习任务上实现了更快的收敛 。
将RAdam和LookAhead结合在了一起,形成名为Ranger的新优化器。在ImageNet上进行了测试,在128px,20epoch的测试中,Ranger的训练精度达到了93%,比目前FastAI排行榜榜首提高了1%。

7.选择的模型
ResNeXt101系列,EfficientNet系列。
- resnext101_32x16d_wsl
- resnext101_32x8d_wsl
- efficientnet-b4
- efficientnet-b5
8.注意力机制
在模型中加入SE&CBAM注意力机制——提升网络模型的特征提取能力。

- channel attention的过程。比SE多了一个 global max pooling(池化本身是提取高层次特征,不同的池化意味着提取的高层次特征更加丰富)。其第2个池化之后的处理过程和SE一样,都是先降维再升维,不同的是将2个池化后相加再sigmod和原 feature map相乘输出结果。

class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)2. spatial attention 的过程。将做完 channel attention 的feature map 作为输入,之后作2个大小为列通道的维度池化,每一次池化得到的 feature map 大小就为 h * w * 1 ,再将两次池化的 feature map 作基于通道的连接变成了大小为 h * w * 2 的 feature map ,再对这个feature map 进行核大小为 7*7 ,卷积核个数为1的卷积操作(通道压缩)再sigmod,最后就是熟悉的矩阵全乘。
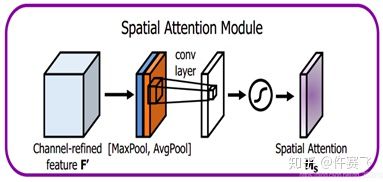
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)9.SVM替换softmax层
抽取出模型的最后一层,将其接入SVM,用训练数据动态训练SVM分类器,再使用训练好的SVM分类器进行预测。
深度学习模型有支持向量机无法比拟的非线性函数逼近能力,能够很好地提取并表达数据的特征,深度学习模型的本质是特征学习器。然而,深度模型往往在独立处理分类、回归等问题上难以取得理想的效果。对于 SVM 来说,可以利用核函数的思想将非线性样本映射到高维空间,使其线性可分,再通过使数据集之间的分类间隔最大化来寻找最优分割超平面,在分类问题上表现出许多特有优势。但实质上,SVM 只含有一个隐层,数据表征能力并不理想。因此将深度学习方法与 SVM 相结合,构造用于分类的深层模型。利用深度学习的无监督方式分层提取样本高级特征,然后将这些高级特征输入 SVM 模型进行分类,从而达到最优分类精度。
10.模型融合
多模型融合的策略,Stacking,VotingClassifier—— 提升分类准确率
Stacking方法: Stacking 先从初始数据集训练出初级学习器,然后”生成”一个新数据集用于训练次级学习器。在这个新数据集中,初级学习器的输出被当作样例输入特征,而初始样本的标记仍被当作样例标记。stacking使用交叉验证的方式,初始训练集 D 被随机划分为 k 个大小相似的集合 D1 , D2 , … , Dk,每次用k-1 个部分训练 T 个模型,对另个一个部分产生 T 个预测值作为特征,遍历每一折后,也就得到了新的特征集合,标记还是源数据的标记,用新的特征集合训练一个集合模型。

11.TTA:测试时数据增强(保证数据增强的几何变换和tta一致)
可将准确率提高若干个百分点,它就是测试时增强(test time augmentation, TTA)。这里会为原始图像造出多个不同版本,包括不同区域裁剪和更改缩放程度等,并将它们输入到模型中;然后对多个版本进行计算得到平均输出,作为图像的最终输出分数。
tta_model = tta.TTAWrapper(model,tta.fliplr_image2label)