Python爬虫学习笔记-第二十课(Scrapy进阶中)
Scrapy进阶中
- 1.案例练习——腾讯招聘
-
- 1.1 思路分析
- 1.2 完整代码
- 1.3 需求升级
- 1.3 完善代码
- 2. 案例练习——古诗文
-
- 2.1 思路分析
- 2.2 完整代码
- 3. Scrapy Shell
- 4. Settings 配置补充
1.案例练习——腾讯招聘
代码需求 :爬取工作岗位(标题),并进行翻页,点击职位后,获取详情页的数据。
相应链接:https://careers.tencent.com/search.html?index=1
1.1 思路分析
打开开发者选项,确定页数的element,里面并不包含对应页数的url地址。
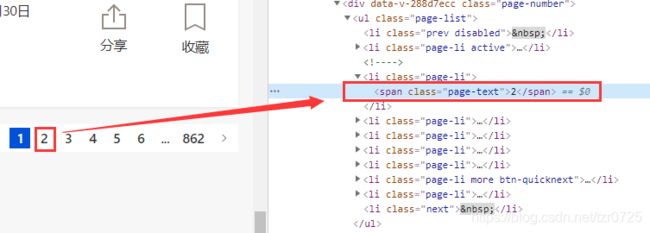
换一种思路,直接观察页数的url,寻找规律:
https://careers.tencent.com/search.html?index=1 第一页
https://careers.tencent.com/search.html?index=2 第二页
https://careers.tencent.com/search.html?index=3 第三页
现在查看要爬取的数据是否是静态的:


在网页源码中找不到数据,显然网页数据是通过ajax动态加载的。这个时候一般有两种方案,一种是通过selenium,点击页面元素加载想要的数据,另一种是分析数据接口,通常在XHR里寻找,如下图:

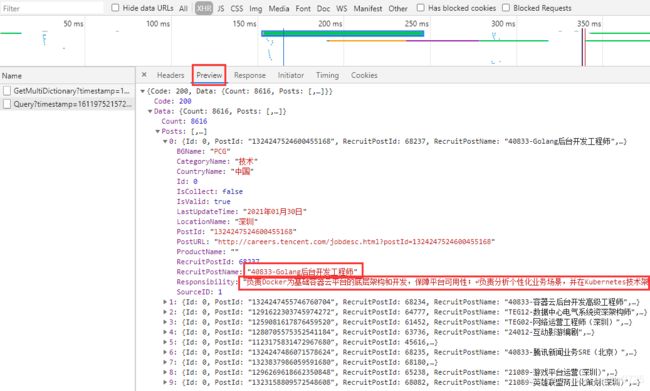
这样,我们就找到了真正的数据接口。因此,之前提及的页数url不能够作为起始的url地址。需要的url为:

写成文本格式:
# 第一页
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1611749603633&countryId=&cityId=&bgIds=&productId=
&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn
# 第二页
https://careers.tencent.com/tencentcareer/api/post/Querytimestamp=1611975215727&countryId=&cityId=&bgIds=&productId=
&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=2&pageSize=10&language=zh-cn&area=cn
只需要动态替换pageIndex的值就可以实现翻页。
整体的思路是:向分析出的url发起请求,获得相应后解析数据,完成单页的操作后,进行翻页处理。
1.2 完整代码
# 爬虫代码
import scrapy
import json
from day20.tencent.tencent.items import TencentItem
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['tencent.com']
base_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
start_urls = [base_url.format(1)]
def parse(self, response):
item = TencentItem()
# 解析数据
total_data = json.loads(response.text)
for job in total_data['Data']['Posts']:
item['job_name'] = job['RecruitPostName']
print(item)
# 翻页处理
for page in range(2, 3):
next_url = self.base_url.format(page)
yield scrapy.Request(next_url)
# items代码
import scrapy
class TencentItem(scrapy.Item):
# define the fields for your item here like:
job_name = scrapy.Field()
运行结果:

1.3 需求升级
现尝试获取详情页里面的工作职责:
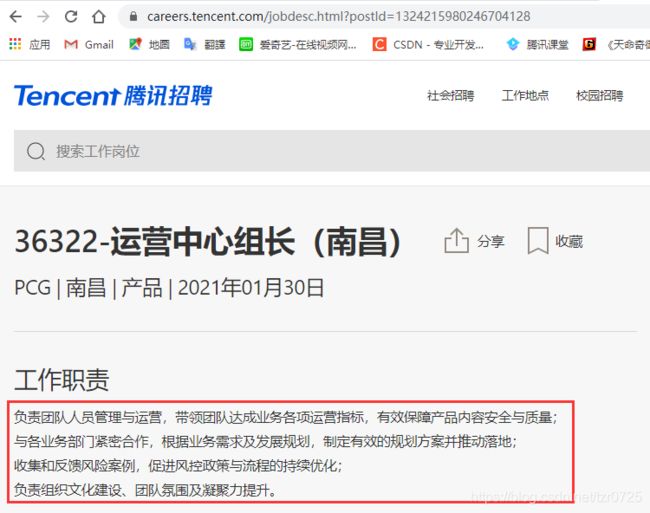
同样地,这个数据在网页源代码中也找不到:

正确的出处如下(与之前一样的查找方法):
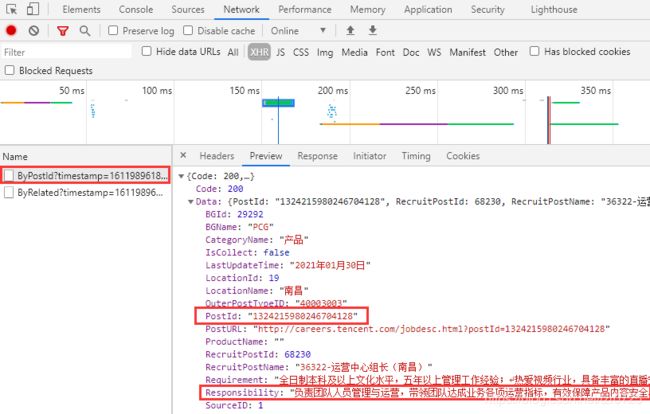
对应的url为:
https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1611989618957&postId=1324215980246704128&language=zh-cn
上述url中的postId来源于之前获取的响应数据:

因为我们要获取每一个工作岗位的详情页里面的工作职责,通过页面分析之后,发现postid就是代表的每一个岗位。
所以,整理一下大致的思路:获取到岗位名字的同时,保存对应的postId;想要获取进一步的详细信息时,将详情页url中的postId动态替换,继续获取响应,解析数据即可。
1.3 完善代码
# 爬虫代码
import scrapy
import json
from day20.tencent.tencent.items import TencentItem
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['tencent.com']
base_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
detial_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?postId={}&language=zh-cn'
start_urls = [base_url.format(1)]
def parse(self, response):
item = TencentItem()
# 解析数据
total_data = json.loads(response.text)
for job in total_data['Data']['Posts']:
item['job_name'] = job['RecruitPostName']
# 获取postId, 获得完整的详情页数据url
postId = job['PostId']
real_detail_url = self.detial_url.format(postId)
yield scrapy.Request(
url=real_detail_url,
callback=self.detail_content,
meta={
'item': item} # 向回调函数传递数据, 格式为字典
)
# 翻页处理
for page in range(2, 3):
next_url = self.base_url.format(page)
yield scrapy.Request(next_url)
# 处理详情页数据爬取逻辑的回调函数
def detail_content(self, response):
# 如何传递数据
item = response.meta.get('item') # 字典中取出'item'的值
result = json.loads(response.text)
item['job_duty'] = result['Data']['Responsibility']
print(item)
# items代码
import scrapy
class TencentItem(scrapy.Item):
# define the fields for your item here like:
job_name = scrapy.Field()
job_duty = scrapy.Field()
运行结果:

关于scrapy.Request():
url——本次循环结束后,继续发起请求的url;
callback——回调函数,其实就是发起请求时需要额外处理的爬虫逻辑;
meta——可以实现不同解析函数之间的数据传递,比如上述例子中可以将item对象传递给回调函数。
2. 案例练习——古诗文
代码需求 :笔者之前的博客中,已经爬取了诗歌的标题、作者、朝代以及具体内容。现在增加一项数据,点击诗歌标题,进入相应的详情页后,爬取它的译文。
2.1 思路分析
首先,确认爬取内容是静态数据,其标签分布如下图:

上图的“译文及注释”对应的详情页url来源如下:

它是标签上层a标签中属性href的值。
所以,整体的思路大致为:爬取诗歌标题的同时,也爬取对应详情页的url,yield一个Request对象时,调用回调函数来爬取详情页中的译文及注释。
2.2 完整代码
# 爬虫代码
import scrapy
from day20.gsw.gsw.items import GswItem
class GushuSpider(scrapy.Spider):
name = 'poem'
# 增加一个域名
allowed_domains = ['gushiwen.org', 'gushiwen.cn']
# 修改起始的url
start_urls = ['https://www.gushiwen.org/default_1.aspx']
def parse(self, response):
poem_divs = response.xpath('//div[@class="cont"]')
item = GswItem()
for poem_div in poem_divs:
# 获取诗歌的标题
poem_title = poem_div.xpath('./p/a/b/text()').extract_first()
detail_url = poem_div.xpath('./p/a/@href').extract_first()
# 标题非空
if poem_title:
item['title'] = poem_title
yield scrapy.Request(
url=detail_url,
callback=self.getTranslation,
meta={
'item': item}
)
def getTranslation(self, response):
item = response.meta.get('item')
origin_translation = response.xpath('//div[@class="contyishang"]//p/text()').extract()
translation = ''.join(origin_translation).strip()
item['translation'] = translation
print(item)
运行结果:

3. Scrapy Shell
作用:是一个终端,可以在未启动spider时尝试调试代码。
打开Pycharm命令行终端,输入如下命令:
>>> scrapy shell www.baidu.com

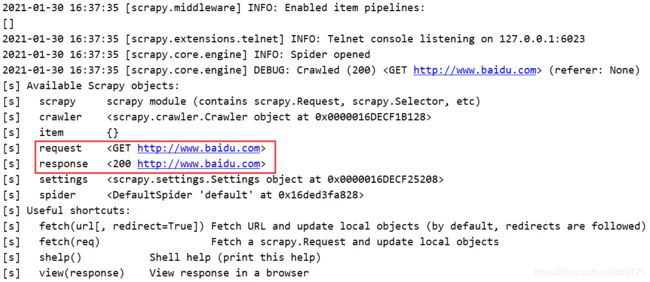
输出了许多内容,其实绝大多数都与运行scrapy程序时输出的log信息类似。
尝试查看网页源代码:
>>> response.text

查看一些其它信息:
>>> response.url
'http://www.baidu.com'
>>> response.encoding
'utf-8'
笔者这里用古诗文网站简单测试一下:
scrapy shell https://www.gushiwen.cn/


对response采用xpath语句获取诗歌的标题:
>>> response.xpath('//div[@class="cont"]//b/text()')

4. Settings 配置补充
存放的是一些配置文件,可以在里面定义一些常量,方便其它模块调用,一般用大写字母来命名。
举个例子,settings.py文件的内容如下:
BOT_NAME = 'gsw'
SPIDER_MODULES = ['gsw.spiders']
NEWSPIDER_MODULE = 'gsw.spiders'
LOG_LEVEL = 'WARNING'
# 添加自定义变量
AUTHOR_NAME = 'Tangzr'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure a delay for requests for the same website (default: 0)
DOWNLOAD_DELAY = 1
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# Configure item pipelines
ITEM_PIPELINES = {
'gsw.pipelines.GswPipeline': 300,
}
在爬虫文件中引用该变量:
print('spider first method: ', AUTHOR_NAME)
print('spider second method: ', self.settings.get('AUTHOR_NAME'))
在管道中引用该变量:
print('pipline first method: ', AUTHOR_NAME)
print('pipline second method: ', spider.settings.get('AUTHOR_NAME'))
运行结果:
