【NLP理论到实战】11 循环神经网络实现文本情感分类
文章目录
- 循环神经网络实现文本情感分类
-
- 目标
- 1. Pytorch中LSTM和GRU模块使用
-
- 1.1 LSTM介绍
- 1.2 LSTM使用示例
-
- 1.3 GRU的使用示例
- 1.4 双向LSTM
- 1.4 LSTM和GRU的使用注意点
- 2. 使用LSTM完成文本情感分类
-
- 2.1 修改模型
- 2.2 完成训练和测试代码
- 2.3 模型训练的最终输出
循环神经网络实现文本情感分类
目标
- 知道LSTM和GRU的使用方法及输入输出的格式
- 能够应用LSTM和GRU实现文本情感分类
1. Pytorch中LSTM和GRU模块使用
1.1 LSTM介绍
LSTM和GRU都是由
torch.nn提供
一、通过观察文档,可知LSMT的参数,
torch.nn.LSTM(input_size,hidden_size,num_layers,batch_first,dropout,bidirectional)
input_size:输入数据的形状,即embedding_dimhidden_size:隐藏层神经元的数量,即每一层有多少个LSTM单元num_layer:即RNN的中LSTM单元的层数batch_first:默认值为False,输入的数据需要[seq_len,batch_size,feature],如果为True,则为[batch_size,seq_len,feature]dropout:dropout的比例,默认值为0。dropout是一种训练过程中让部分参数随机失活的一种方式,能够提高训练速度,同时能够解决过拟合的问题。这里是在LSTM的最后一层,对每个输出进行dropoutbidirectional:是否使用双向LSTM,默认是False
二、实例化LSTM对象之后,不仅需要传入数据,还需要前一次的h_0(前一次的隐藏状态)和c_0(前一次memory*),若不传则默认初始化全为0
即:
lstm(input,(h_0,c_0))
三、LSTM的默认输出为
output, (h_n, c_n)
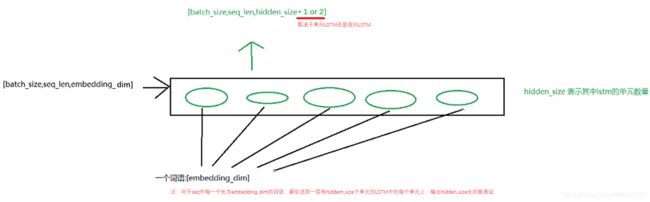
output:(batch_size, seq_len, hidden_size * num_directions)—>batch_first=Falseh_n:(num_layers * num_directions, batch_size, hidden_size)c_n:(num_layers * num_directions, batch_size, hidden_size)如下图解释上面输入输出形状变化:
- output形状——把每个时间步上的结果在seq_len这一维度上进行了拼接
- h_n形状——隐藏状态相当于在一个隐藏层中从第一个h_0一直穿到最后一个h_n,把不同层的隐藏状态在第0个维度上进行了拼接
- c_n形状——同h_n。
1.2 LSTM使用示例
假设数据输入为 input ,形状是
[10,20],假设embedding的形状是[100,30]
则LSTM使用示例如下:
batch_size = 10 # 输入一个batch的大小,即包含多少个text
seq_len = 20 # batch中一个text的长度
vocab_size = 100 # 词典总数
embedding_dim = 30 # 每个word嵌入成表征向量的维度
hidden_size = 18 # 隐藏层神经元数,即一层有多少个LSTM单元
num_layers = 2 # 隐藏层数量,即LSTM单元层数
num_directions = 1 # 单向LSTM为1,双向LSTM为2
# 构造一个batch数据
input = torch.randint(low=0, high=100, size=(batch_size, seq_len))
print(input.size()) # [10, 20]
# 数据经过embedding处理
embedding = nn.Embedding(vocab_size, embedding_dim)
input_embeded = embedding(input)
print(input_embeded.size()) # [10, 20, 30]
# 初始化隐藏和记忆cell状态,否则待会也可以不传默认初始值全为0
h_0 = torch.rand(num_layer * num_directions, batch_size, hidden_size)
c_0 = torch.rand(num_layer * num_directions, batch_size, hidden_size)
print(h_0.size()) # [2, 10, 18]
print(c_0.size()) # [2, 10, 18]
# 把embedding处理后的数据传入LSTM
lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True)
output, (h_n, c_n) = lstm(input_embeded)
print(output.size()) # [10, 20, 18]
print(h_n.size()) # [2, 10, 18]
print(c_n.size()) # [2, 10, 18]
通过前面的学习,我们知道,最后一次的h_n应该和output的最后一个time step的输出是一样的
通过下面的代码,我们来验证一下:
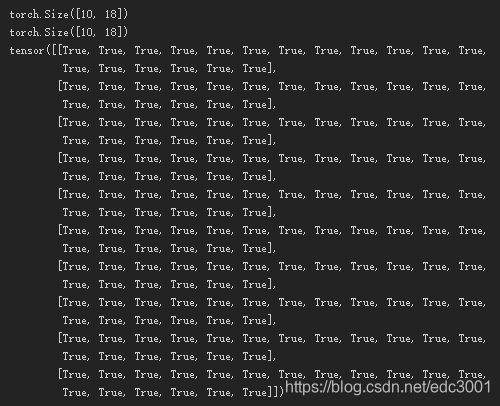
last_output = output[:,-1,:] # 获取最后一个时间步上的输出(取最后一个text)
last_hidden_state = h_n[-1,:,:] # 获取最后一次的hidden_state(取最后一层)
print(last_output==last_hidden_state)
"""
tensor([[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True],
[True, True, True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True]])
"""
1.3 GRU的使用示例
GRU模块
torch.nn.GRU,和LSTM的参数相同,含义相同,具体可参考文档
但是输入只剩下gru(input,h_0),输出为output, h_n
其形状为:
output:(seq_len, batch_size, num_directions * hidden_size)h_n:(num_layers * num_directions, batch_size, hidden_size)
则GRU使用示例如下:
batch_size = 10 # 输入一个batch的大小,即包含多少个text
seq_len = 20 # batch中一个text的长度
vocab_size = 100 # 词典总数
embedding_dim = 30 # 每个word嵌入成表征向量的维度
hidden_size = 18 # 隐藏层神经元数,即一层有多少个GRU单元
num_layers = 2 # 隐藏层数量,即GRU单元层数
num_directions = 1 # 单向GRU为1,双向GRU为2
# 构造一个batch数据
input = torch.randint(low=0, high=100, size=(batch_size, seq_len))
print(input.size()) # [10, 20]
# 数据经过embedding处理
embedding = nn.Embedding(vocab_size, embedding_dim)
input_embeded = embedding(input)
print(input_embeded.size()) # [10, 20, 30]
# 初始化隐藏和记忆cell状态,否则待会也可以不传默认初始值全为0
h_0 = torch.rand(num_layer * num_directions, batch_size, hidden_size)
print(h_0.size()) # [2, 10, 18]
# 把embedding处理后的数据传入GRU
gru = nn.GRU(input_size=embedding_dim, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True)
output, h_n = gru(input_embeded)
print(output.size()) # [10, 20, 18]
print(h_n.size()) # [2, 10, 18]
1.4 双向LSTM
如果需要使用双向LSTM,则在实例化LSTM的过程中,需要把LSTM中的参数
bidriectional设置为True,同时h_0和c_0使用num_layer*2
则双向LSTM使用示例如下:
# 双向LSTM同前,主要是nn.LSTM中参数bidirectional需要设置为True,同时h_0和c_0使用num_layer*2
batch_size = 10 # 输入一个batch的大小
seq_len = 20 # batch中一个text的长度
vocab_size = 100 # 词典总数
embedding_dim = 30 # 每个word嵌入成表征向量的维度
hidden_size = 18 # 隐藏层神经元数,即一层有多少个LSTM单元
num_layers = 2 # 隐藏层数量,即LSTM单元层数
num_directions = 2 # 单向LSTM为1,双向LSTM为2
# 构造一个batch数据
input = torch.randint(low=0, high=100, size=(batch_size, seq_len))
print(input.size()) # [10, 20]
# 数据经过embedding处理
embedding = nn.Embedding(vocab_size, embedding_dim)
input_embeded = embedding(input)
print(input_embeded.size()) # [10, 20, 30]
# 初始化隐藏和记忆cell状态,否则待会也可以不传默认初始值全为0
h_0 = torch.rand(num_layer * num_directions, batch_size, hidden_size)
c_0 = torch.rand(num_layer * num_directions, batch_size, hidden_size)
print(h_0.size()) # [2 * 2, 10, 18], 双向包括反向需要*2
print(c_0.size()) # [2 * 2, 10, 18]
# 把embedding处理后的数据传入LSTM
lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size, num_layers=num_layers,
batch_first=True, bidirectional=True)
output, (h_n, c_n) = lstm(input_embeded)
print(output.size()) # [10, 20, 18 * 2]
print(h_n.size()) # [2 * 2, 10, 18]
print(c_n.size()) # [2 * 2, 10, 18]
在单向LSTM中,最后一个time step的输出的前hidden_size个和最后一层隐藏状态h_n的输出相同,那么双向LSTM呢?
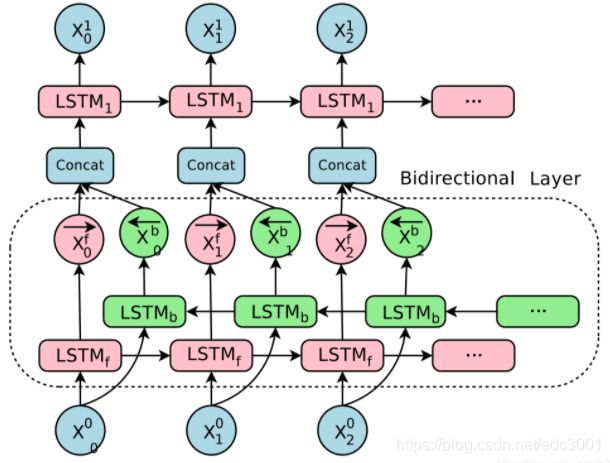
双向LSTM中:
- output:按照正反计算的结果顺序在最后一个维度进行拼接,正向第一个拼接反向的最后一个输出
- hidden state:按照得到的结果在第0个维度进行拼接,正向第一个之后接着是反向第一个(从上往下顺序是:第一层正向,第一层反向,第二层正向,第二层反向…)
- 如下图:
- 前向的LSTM中,最后一个time step的输出的前hidden_size个和最后一层向前传播h_n的输出相同
示例:
last_output = output[:,-1,:18] # 获取双向LSTM中正向的最后一个时间步的output last_hidden_state = h_n[-2,:,:] # 获取双向LSTM中正向的最后一个hidden_state(倒数第二个) print(last_output.size()) print(last_hidden_state.size()) print(last_output==last_hidden_state)结果如下:
- 后向LSTM中,最后一个time step的输出的后hidden_size个和最后一层后向传播的h_n的输出相同
示例
last_output = output[:,-1,18:] # 获取双向LSTM中反向的最后一个时间步的output >last_hidden_state = h_n[-1,:,:] # 获取双向LSTM中反向的最后一个hidden_state(倒数第一个) print(last_output.size()) print(last_hidden_state.size()) print(last_output==last_hidden_state)结果如下:
1.4 LSTM和GRU的使用注意点
- 第一次调用之前,需要初始化隐藏状态,如果不初始化,默认创建全为0的隐藏状态
- 往往会使用LSTM or GRU 的输出的最后一维的结果,来代表LSTM、GRU对文本处理的结果,其形状为
[batch_size, num_directions * hidden_size]。
- 并不是所有模型都会使用最后一维的结果
- 如果实例化LSTM的过程中,batch_first=False,则
output[-1] or output[-1,:,:]可以获取最后一维- 如果实例化LSTM的过程中,batch_first=True,则
output[:,-1,:]可以获取最后一维
- 如果结果是
(seq_len, batch_size, num_directions * hidden_size),需要把它转化为(batch_size, seq_len, num_directions * hidden_size)的形状,不能够使用view等变形的方法,需要使用output.permute(1,0,2),即交换0和1轴,实现上述效果- 使用双向LSTM的时候,往往会分别使用每个方向最后一次的output,作为当前数据经过双向LSTM的结果
- 即:
torch.cat([h_n[-2,:,:],h_n[-1,:,:]],dim=-1)- 最后的表示的size是
[batch_size,hidden_size * 2]
- 上述内容在GRU中同理
2. 使用LSTM完成文本情感分类
在前面,我们使用了word embedding去实现了toy级别的文本情感分类,那么现在我们在这个模型中添加上LSTM层,观察分类效果。
为了达到更好的效果,对之前的模型做如下修改
- MAX_LEN = 200
- 构建dataset的过程,把数据转化为2分类的问题,pos为1,neg为0,否则25000个样本完成10个类别的划分数据量是不够的
- 在实例化LSTM的时候,使用dropout=0.5,在model.eval()的过程中,dropout自动会为0
2.1 修改模型
"""
一、重写数据集类和准备数据加载类对象(dataset.py)
"""
import torch
from torch.utils.data import Dataset,DataLoader
import os
from utils import tokenize
import config
class ImdbDataset(Dataset): # 1.5重写Imdb数据集类,包括(init方法:获取所有文件路径列表)、(getitem方法:获取索引文件内容)、(len方法:计算文件总数)
def __init__(self,train=True):
root_path = '.\\data\\aclImdb'
root_path = os.path.join(root_path,'train') if train else os.path.join(root_path,'test')
all_father_path = [os.path.join(root_path,'pos'),os.path.join(root_path,'neg')]
self.all_file_path = []
for father_path in all_father_path:
file_paths = [os.path.join(father_path,file_name) for file_name in os.listdir(father_path) if file_name.endswith('.txt')]
self.all_file_path.extend(file_paths)
def __getitem__(self,index):
file_path = self.all_file_path[index]
content = tokenize(open(file_path,encoding='UTF-8').read()) # 1.6获取当前索引文件内容时,需要调用工具包分词过滤函数处理
label = 1 if file_path.split('\\')[-2] == 'pos' else 0
return content,label
def __len__(self):
return len(self.all_file_path)
def collate_fn(batch): # 1.8重写collate_fn方法(zip操作+转换为LongTensor类型操作)
contents,labels = zip(*batch)
contents = torch.LongTensor([config.ws.transform(content,max_len=config.max_len) for content in contents])
labels = torch.LongTensor(labels)
return contents,labels
def get_dataloader(train=True): # 1.3定义获取dataset和dataloader的函数
Imdb_dataset = ImdbDataset(train=True) # 1.4 调用重写的Imdb数据集类
batch_size = config.train_batch_size if train else config.test_batch_size # 1.7 划分batch大小需要根据训练集还是测试集划分,就对应数字单独写到一个配置包中需要引入
Imdb_dataloader = DataLoader(Imdb_dataset,batch_size=batch_size,shuffle=True,collate_fn=collate_fn) # 1.8获取数据集加载类,并重写参数collate_fn方法
return Imdb_dataloader
if __name__=='__main__': # 1.1测试入口,打印第一个batch结果
for idx,(x,y_true) in enumerate(get_dataloader()): # 1.2调用函数,获取dateloader,取到数据集
print('idx: ',idx)
print('text: ',x)
print('label: ',y_true)
break
"""
工具包:定义文本过滤及分词方法函数(utils.py)
"""
import re
def tokenize(text): # 1.6.1 定义文本过滤及分词函数
filters = ['!', '"', '#', '$', '%', '&', '\(', '\)', '\*', '\+', ',', '-', '\.', '/', ':', ';', '<', '=', '>',
'\?', '@', '\[', '\\', '\]', '^', '_', '`', '\{', '\|', '\}', '~', '\t', '\n', '\x97', '\x96', '”', '“', '<.*?>']
text = re.sub("|".join(filters), " ", text, flags=re.S)
return [word.lower() for word in text.split()]
"""
配置包:用于配置保存常用的常量及模型(config.py)
"""
import pickle
train_batch_size = 512
test_batch_size = 500
max_len = 200
ws = pickle.load(open('./model/TextSentiment/ws_lstm.pkl', 'rb'))
hidden_size = 128
num_layers = 2
bidriectional = True
dropout = 0.4
"""
二、文本序列化(word2sequence.py)
"""
class Word2Sequence: # 1.定义文本转序列类,包含六个方法:(init方法:初始化词-序列字典和词频字典)、(fit方法:统计词频得到词频字典)、(build_vocab方法:由全部文本和条件构造词-序列字典和序列-词字典)、(transform方法:将一个文本转化为数字序列)、(inverse_transform方法:将一个数字序列转化为文本)、(len方法:统计词-序列字典的长度)
UNK_TAG = '' # 表示未知字符
PAD_TAG = '' # 表示填充符
UNK = 0 # 未知字符对应数字序列中的数字
PAD = 1 # 填充字符对应数字序列中的数字
def __init__(self): # 1.1 init方法:初始化词-序列字典和词频字典
self.wordToSequence_dict = {
# 初始化词—序列字典
self.UNK_TAG:self.UNK,
self.PAD_TAG:self.PAD
}
self.count_dict = {
} # 初始化词频字典
def fit(self,text): # 1.2 fit方法:统计所有文本的词频得到词频字典
for word in text: # 构造词频字典
self.count_dict[word] = self.count_dict.get(word,0)+1
def build_vocab(self,min_count=None,max_count=None,max_features=None): # 1.3 build_vocab方法:由全部文本和条件构造词-序列字典和序列-词字典
if min_count is not None:
self.count_dict = {
word:count for word,count in self.count_dict.items() if count>=min_count}
if max_count is not None:
self.count_dict = {
word:count for word,count in self.count_dict.items() if count<=max_count}
if max_features is not None: # key=lambda x: x[-1] 为对前面对象中最后一维数据(即value)的值进行排序。
self.count_dict = dict(sorted(self.count_dict.items(),key=lambda x: x[-1],reverse=True)[:max_features])
for word in self.count_dict: # 将词频字典中的每一个词依次递增转为数字,形成所有文本词的词-序列字典
self.wordToSequence_dict[word] = len(self.wordToSequence_dict)
self.sequenceToWord_dict= dict(zip(self.wordToSequence_dict.values(),self.wordToSequence_dict.keys())) # 反转得到所有词文本的序列-词字典
def transform(self,text,max_len=None): # 1.4 transform方法:将一个文本转化为数字序列
if max_len is not None:
if len(text)>max_len:
text = text[:max_len]
else:
text = text + [self.PAD_TAG] * (max_len-len(text))
return [self.wordToSequence_dict.get(word,self.UNK) for word in text]
def inverse_transform(self,sequence): # 1.5 inverse_transform方法:将一个数字序列转化为文本
return [self.sequenceToWord_dict.get(num,self.UNK_TAG) for num in sequence]
def __len__(self): # 1.6 len方法:统计词-序列字典的长度)
return len(self.wordToSequence_dict)
if __name__=='__main__': # 测试入口,模拟字典的构建及转换效果
one_batch_text = (['今天','菜','很','好'],['今天','去','吃','什么']) # 模拟一个batch的text
ws = Word2Sequence() # 初始化文本转序列类示例
for text in one_batch_text: # 遍历所有文本构建词频字典
ws.fit(text)
ws.build_vocab(max_features=6) # 利用传入限制条件的词频字典构建所有词文本的词-序列字典
print(ws.wordToSequence_dict)
new_text = ['去','吃','什么','菜','好','不','好','呀']
result1 = ws.transform(new_text,max_len=10)
result2 = ws.inverse_transform(result1)
print(result1)
print(result2)
"""
三、主函数,即整合前两大步骤:分别构建训练集和测试集dataloader中所有batch的text的字典,并保存为模型(main.py)
"""
from dataset import get_dataloader
from word2sequence import Word2Sequence
import pickle
from tqdm import tqdm
if __name__ == '__main__':
ws = Word2Sequence()
train_dataloader = get_dataloader(train=True)
test_dataloader = get_dataloader(train=False)
for one_batch_text, labels in tqdm(train_dataloader):
for text in one_batch_text:
ws.fit(text)
for one_batch_text, labels in tqdm(test_dataloader):
for text in one_batch_text:
ws.fit(text)
ws.build_vocab()
print(len(ws))
# 构建完整个字典后,保存实例化对象成文件
pickle.dump(ws, open('.\\model\\TextSentiment\\ws_lstm.pkl', 'wb'))
"""
四、构建模型(model.py)
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import config
class LstmImdbModel(nn.Module):
def __init__(self):
super(LstmImdbModel, self).__init__()
# word embedding操作,将每次词随机初始化嵌入为词向量
self.emb = nn.Embedding(
num_embeddings=len(config.ws), embedding_dim=300)
self.lstm = nn.LSTM(input_size=300, hidden_size=config.hidden_size, num_layers=config.num_layers,
batch_first=True, bidirectional=config.bidriectional, dropout=config.dropout) # 加入一个双向LSTM神经网络
self.fc = nn.Linear(2*config.hidden_size, 2) # 通过一个简单的全连接层进行学习
def forward(self, input): # input.size():[512, 200]
x = self.emb(input) # x.size():[512, 200, 300]
# x.size():[512, 200, 2*config.hidden_size]
x, (h_n, c_n) = self.lstm(x)
# 获取正反两个方向最后一次的output,进行concat操作
output_forward = h_n[-2, :, :]
output_backward = h_n[-1, :, :]
output = torch.cat([output_forward, output_forward],
dim=-1) # [batch_size, 2*hidden_size]
out = self.fc(output) # out.size():[512,2]
return F.log_softmax(out, dim=-1)
"""
五、模型的训练和评估(train_test.py)
"""
from model import LstmImdbModel
import torch
import torch.nn.functional as F
from dataset import get_dataloader
import os
import numpy as np
Imdb_model = LstmImdbModel()
optimizer = torch.optim.Adam(Imdb_model.parameters(),lr=1e-3)
if os.path.exists('./model/TextSentiment/imdb_lstm_model.pkl'):
Imdb_model.load_state_dict(torch.load('./model/TextSentiment/imdb_lstm_model.pkl'))
optimizer.load_state_dict(torch.load('./model/TextSentiment/imdb_lstm_optimizer.pkl'))
def train(epoch):
train_dataloader = get_dataloader(train=True)
for idx,(x,y_true) in enumerate(train_dataloader):
y_predict = Imdb_model(x)
loss = F.nll_loss(y_predict,y_true)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if not(idx % 10):
print('Train epoch:{} \t idx:{:>3} \t loss:{}'.format(epoch,idx,loss.item()))
if not(idx % 20):
torch.save(Imdb_model.state_dict(), './model/TextSentiment/imdb_lstm_model.pkl')
torch.save(optimizer.state_dict(), './model/TextSentiment/imdb_lstm_optimizer.pkl')
def test():
loss_list = []
acc_list = []
Imdb_model.eval()
test_dataloader = get_dataloader(train=False)
for idx, (x, y_true) in enumerate(test_dataloader):
with torch.no_grad():
y_predict = Imdb_model(x)
cur_loss = F.nll_loss(y_predict, y_true)
pred = y_predict.max(dim=-1)[-1]
cur_acc = pred.eq(y_true).float().mean()
loss_list.append(cur_loss)
acc_list.append(cur_acc)
print(np.mean(acc_list), np.mean(loss_list))
if __name__=='__main__':
test()
for i in range(5):
train(i)
test()
2.2 完成训练和测试代码
为了提高程序的运行速度,可以考虑把模型放在gup上运行,那么此时需要处理一下几点:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.to(device)- 除了上述修改外,涉及计算的所有tensor都需要转化为CUDA的tensor
- 初始化的
h_0,c_0- 训练集和测试集的
input,traget
- 在最后可以通过
tensor.cpu()转化为torch的普通tensor
"""
配置包:用于配置保存常用的常量及模型(config.py)
"""
import pickle
import torch
train_batch_size = 512
test_batch_size = 500
max_len = 200
ws = pickle.load(open('./model/TextSentiment/ws_lstm.pkl', 'rb'))
hidden_size = 128
num_layers = 2
bidriectional = True
dropout = 0.4
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
"""
五、模型的训练和评估(train_test.py)
"""
from model import LstmImdbModel
import torch
import torch.nn.functional as F
from dataset import get_dataloader
import os
import numpy as np
import config
Imdb_model = LstmImdbModel().to(config.device)
optimizer = torch.optim.Adam(Imdb_model.parameters(),lr=1e-3)
if os.path.exists('./model/TextSentiment/imdb_lstm_model.pkl'):
Imdb_model.load_state_dict(torch.load('./model/TextSentiment/imdb_lstm_model.pkl'))
optimizer.load_state_dict(torch.load('./model/TextSentiment/imdb_lstm_optimizer.pkl'))
def train(epoch):
train_dataloader = get_dataloader(train=True)
for idx,(x,y_true) in enumerate(train_dataloader):
x,y_true = x.to(config.device),y_true.to(config.device)
y_predict = Imdb_model(x)
loss = F.nll_loss(y_predict,y_true)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if not(idx % 10):
print('Train epoch:{} \t idx:{:>3} \t loss:{}'.format(epoch,idx,loss.item()))
if not(idx % 20):
torch.save(Imdb_model.state_dict(), './model/TextSentiment/imdb_lstm_model.pkl')
torch.save(optimizer.state_dict(), './model/TextSentiment/imdb_lstm_optimizer.pkl')
def test():
loss_list = []
acc_list = []
Imdb_model.eval()
test_dataloader = get_dataloader(train=False)
for idx, (x, y_true) in enumerate(test_dataloader):
with torch.no_grad():
x,y_true = x.to(config.device),y_true.to(config.device)
y_predict = Imdb_model(x)
cur_loss = F.nll_loss(y_predict, y_true)
pred = y_predict.max(dim=-1)[-1]
cur_acc = pred.eq(y_true).float().mean()
loss_list.append(cur_loss)
acc_list.append(cur_acc)
print(np.mean(acc_list), np.mean(loss_list))
if __name__=='__main__':
test()
for i in range(2):
train(i)
test()
2.3 模型训练的最终输出
输出结果如下:(可以看见经过5个epoch训练,准确度达到91.29%左右)
- 注:大家可以把上述代码改为GRU,或者多层LSTM继续尝试,观察效果
0.50008 0.6938739
Train epoch:0 idx: 0 loss:0.6952251195907593
Train epoch:0 idx: 10 loss:0.6912798285484314
Train epoch:0 idx: 20 loss:0.6922942996025085
Train epoch:0 idx: 30 loss:0.6936517953872681
Train epoch:0 idx: 40 loss:0.6920375823974609
0.54528 0.6877126
Train epoch:1 idx: 0 loss:0.6881553530693054
Train epoch:1 idx: 10 loss:0.6865140795707703
Train epoch:1 idx: 20 loss:0.6727651953697205
Train epoch:1 idx: 30 loss:0.6800484657287598
Train epoch:1 idx: 40 loss:0.6654863357543945
0.57739997 0.67385924
Train epoch:2 idx: 0 loss:0.6788107752799988
Train epoch:2 idx: 10 loss:0.6566324830055237
Train epoch:2 idx: 30 loss:0.6512351632118225
Train epoch:2 idx: 40 loss:0.6584490537643433
0.63084006 0.5930069
Train epoch:3 idx: 0 loss:0.6028856635093689
Train epoch:3 idx: 10 loss:0.580773115158081
Train epoch:3 idx: 20 loss:0.5621671676635742
Train epoch:3 idx: 30 loss:0.49137082695961
Train epoch:3 idx: 40 loss:0.42168936133384705
0.84552 0.37732562
Train epoch:4 idx: 0 loss:0.35117626190185547
Train epoch:4 idx: 10 loss:0.34060919284820557
Train epoch:4 idx: 20 loss:0.34198158979415894
Train epoch:4 idx: 30 loss:0.3405914306640625
Train epoch:4 idx: 40 loss:0.31769031286239624
0.91291994 0.2382923