计算机组成原理知识点汇总(考研用)——第二章:数据的表示和运算
计算机组成原理知识点汇总(考研用)——第二章:数据的表示和运算
本文参考于《2021年计算机组成原理考研复习指导》(王道考研),《计算机组成原理》
思维导图:
文章目录
- 计算机组成原理知识点汇总(考研用)——第二章:数据的表示和运算
-
- 2.数据的表示和运算
-
- 2.1 数制与编码
-
- 2.1.1 进位计数制及其相互转换
-
- 1.进位计数法
- 2.不同进制数之间的相互转换
- 2.1.2 真值与机器数
- 2.1.3 BCD码(此部分大纲已删除)
- 2.1.4 字符与字符串
-
- 1.字符编码ASCII码
- 2.汉字的表示和编码
- 2.1.5 校验码(大纲已删除)
-
- 1.奇偶校验码
- 2.海明(汉明)校验码
- 3.循环冗余校验(CRC)码
- 2.2 定点数的表示与运算
-
- 2.2.1 定点数的表示
-
- 1.无符号数与有符号数的表示
- 2.机器数的定点表示
- 3.原码、补码、反码、移码
- 2.2.2 定点数的运算
-
- 1.定点数的移位运算
- 2.原码定点数的加减法运算
- 3.补码定点数的加减法运算
- 4.符号拓展
- 5.溢出概念与判别方法
- 6.定点数的乘法运算
- 7.定点数的除法运算
- 2.2.3 C语言中的整数类型及类型转换
-
- 1.有符号数和无符号数的转换
- 2.不同字长整数之间的转换
- 2.2.4 数据的存储和排列
-
- 1.数据的大端方式和小端方式存储
- 2.数据按边界对齐方式存储
- 2.3 浮点数的表示与运算
-
- 2.3.1 浮点数的表示
-
- 1.浮点数的表示格式
- 2.规格化浮点数
- 3.浮点数的表示范围(考研大纲中已删除)
- 4.IEEE754标准
- 5.定点、浮点表示的区别
- 2.3.2 浮点数的加减运算
-
- 1.对阶
- 2.尾数求和
- 3.规格化
- 4.舍入
- 5.溢出判断
- 6.C语言中的浮点数类型及类型转换
- 2.4 算术逻辑单元(ALU)
-
- 2.4.1 串行加法器和并行加法器
-
- 1.一位全加器
- 2.串行加法器
- 3.并行加法器
- 2.4.2 算术逻辑单元的功能和结构
2.数据的表示和运算
2.1 数制与编码
2.1.1 进位计数制及其相互转换
在计算机系统内部,所有的信息都是用二进制进行编码的,这样做的原因有:
- (1)二进制只有两种状态,使用有两个稳定状态的物理器件就可以表示二进制数的每一位,制造成本较低
- (2)二进制位1和0正好与逻辑值真和假对应,为计算机实现逻辑运算和程序中的逻辑判断提供了便利条件
- (3)二进制的编码和运算规则都很简单,通过逻辑门电路能方便地实现算术运算
1.进位计数法
在进位计数法中,每个数位所用到的不同数码的个数称为基数,如10进制的基数为10。每个数码所表示的数值等于该数码本身乘以一个与它所在数位有关的常数,这个常数称为位权。一个进位数的数值大小就是它的各位数码按权相加。
2.不同进制数之间的相互转换
- (1)二进制转为8进制和16进制
对于一个二进制混合数(既包含整数部分,又包含小数部分),在转换时应以小数点为界。其整数部分,从小数点开始往左数,将一串二进制数分为3位(八进制)一组或4位(16进制)一组,在数的最左边可根据需要加0补齐;对于小数部分,从小数点开始往右数,也将一串二进制数分为3位一组或4位一组,在数的最右边也可根据需要加0补齐。
例:(1111000010.01101)2=(1702.32)8=(3C2.68)16 - (2)十进制数转换为任意进制数
采用基数乘除法,这种转换方法对十进制数的整数部分和小数部分分别进行处理,对整数部分用除基取余法,对小数部分用乘基取整法,最后将整数部分与小数部分的转换结果拼接起来。
除基取余法(整数部分的转换):整数部分除基取余,最先取得的余数为数的最低位,最后取得的余数为数的最高位(除基取余,先余为低,后余为高,因为后余乘以基数的幂次更高),商为0时结束
例:将(123.6875)10转换为二进制
整数部分:
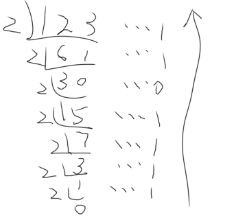
(123)10=(1111011)2
乘基取整法(小数部分的转换):小数部分乘基取整,最先取得的整数为数的最高位,最后取得的整数为数的最低位(乘积取整,先整为高,后整为低,因为后整要除以更多基数的幂次) ,乘积为1.0或满足精度要求时结束
小数部分:
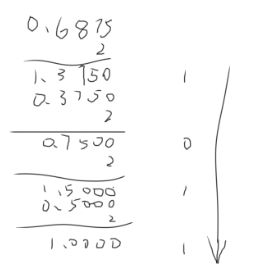
(0.6875)10=(0.1011)2
所以,(123.6875)10=(1111011.1011)2
在计算机中,小数和整数不一样,整数可以连续表示,但小数是离散的(二进制表示小数时只能用1/(2n)的和的任意组合表示),所以并不是每一个十进制小数都可以准确地用二进制表示。但任意一个二进制小数都可用十进制小数表示。
2.1.2 真值与机器数
+15,-8这种带+或-符号的数称为真值,真值是机器数所代表的实际值
在计算机中,通常采用数的符号与数值一起编码的方法来表示数据,常用的有原码、补码、反码表示法。这几种表示法都将数据的符号数字化,通常用0表示正,用1表示负,如0,101(逗号“,”并不实际存在,只是用来区分符号位与数值位,约定整数的数值位与符号位之间用逗号隔开,小数的符号位与数值位之间用小数点隔开)表示+5。这种把符号数字化的数称为机器数。
2.1.3 BCD码(此部分大纲已删除)
二进制编码的十进制数(Binary-Coded Decimal,BCD)通常采用4位二进制数来表示一位十进制数中的0~9这10个数码,有6种状态为冗余状态。
常用的BCD码:
- (1)8421码(最常用):是一种有权码,权值从高到低依次为8421。若两个8421码相加之和<=(1001)2即(9)10,则不需要修正;若相加之和>=(1010)2即(10)10,则要加6修正(从1010到1111这6个为无效码,当运算结果落于这个区间时,需要将运算结果+6),并向高位进位,进位可在首次相加或修正时产生。

- (2)余3码:是一种无权码,是在8421码的基础上加(0011)2形成的,因每个数都多余3,因此称余3码。如8——>1011;
- (3)2421码:是一种有权码,权值从高到低分别为2,4,2,1,特点是>=5的4位二进制数中最高位为1,小于5的最高位为0。如5——>1011
2.1.4 字符与字符串
1.字符编码ASCII码
普遍采用的一种字符系统是7位二进制编码的ASCII码(最早是7位,后来扩充为8位,在7位时期,为满足被8整除条件,需加1位空位才能使用),它可表示10个十进制数码、52个英文大小写字母及一定数量的专用符号,共128个字符。
0~9的ASCII码值为48(011 0000)~57(011 1001),即去掉高3位,只保留低4位,正好是二进制形式的0~9
2.汉字的表示和编码
汉字的编码包括汉字的输入编码、汉字内码、汉字字形码三种,它们是计算机中用于输入、内部处理和输出三种用途的编码。区位码用2字节表示一个汉字,每字节用七位码。区位码是4位十进制数,前2位是区码,后2位是位码,所以称为区位码。如汉字“学”的区位码为4907(十进制),用2个字节的二进制可以表示为00110001 00000111。
国标码将10进制的区位码转换为16进制数后,再在每字节上加上20H。国标码两字节的最高位都是0,ASCII码的最高位也为0。为了便于区分中文和英文字符,将国标码两字节的最高位都改为1,这就是汉字内码
区位码和国标码都是输入码,它们与汉字内码的关系(16进制)为:
国标码=(区位码)16+2020H 汉字内码=(国标码)16+8080H
2.1.5 校验码(大纲已删除)
校验码是指能够发现或能自动纠正错误的数据编码,也称检错纠错编码。校验码的原理是通过增加一些冗余码,来检验或纠错编码。
通常某种编码都由许多码字构成,任意两个合法码字之间最少变化的二进制位数(在一种编码系统中,任意两组合法代码之间的最少二进制位数的差异),称为数据校验码的码距(或称编码的最小距离)(如1100和1101之间的码距为1,因为只有最低位翻转了。而1001和0010之间的码距为3,因为只有1位没有变化)。对于码距不小于2的数据校验码,开始具有检错的能力。码距越大,检错、纠错的能力越强,而且检错能力总是大于等于纠错能力。
1.奇偶校验码
在原编码上加一个校验位,它的码距等于2(例如对于奇校验码来说,任意两个校验码之间,如果想不同,最少变换两个位置的码元才可以完成。例如对于10011来说,如果我任意反转一个码元,1的个数肯定为偶数个,所以我至少反转两个才可以是另一个奇校验码,偶校验码同理。所以奇偶校验码的码距为2),可以检测出一位错误(或奇数位错误),但不能确定出错的位置,也不能够检测出偶数位错误,增加的冗余位称为奇偶校验位。
 奇偶校验实现的方法:由若干位有效信息(如1B)再加上一个二进制位(校验位)组成校验码。校验位的取值(0 or 1)将使整个校验码中1的个数为奇数或偶数。
奇偶校验实现的方法:由若干位有效信息(如1B)再加上一个二进制位(校验位)组成校验码。校验位的取值(0 or 1)将使整个校验码中1的个数为奇数或偶数。
奇校验码:整个校验码(有效信息位和校验位)中1的个数为奇数
偶校验码:整个校验码(有效信息位和校验位)中1的个数为偶数
例:1001101的奇校验码为1 1001101,偶校验码为0 1001101
奇偶校验码的缺点:具有局限性,奇偶校验只能发现数据代码中奇数位的出错情况,但不能纠正错误,常用于对存储器数据的检查或传输数据的检查。
用一位奇偶校验能检测出一位主存错误的百分比为()
A.0 B.1 C.0.5 D.无法计算
答案:B;
若出现一位主存错误,一定能检测出
2.海明(汉明)校验码
海明码实际上是一种多重奇偶校验码。其实现原理是在有效信息位中加入几个校验位形成海明码,并把海明码的每个二进制位分配到几个奇偶校验组中。当某一位出错后,就会引起有关的几个校验位的值发生变化,这不但可以发现错位,还能指出错位的位置。汉明码有一位纠错能力。
根据纠错理论:L-1=D+C且D>=C
即编码最小码距L(编码最小距离)越大,其检测错误的位数D越大,纠正错误的位数C也越大,且纠错能力恒<=检错能力
例:在n=4,k=3时,求1010的海明码
- (1)确定海明码的位数
n为有效信息位数,k为校验位的位数,则n和k应满足n+k<=2^k-1
校验码一共有2^k种取值方式。其中需要一种取值方式表示数据正确,剩下 2 ^k-1种取值方式表示有一位数据出错。因为编码后的二进制串有n+k位,固得上式
海明码位数为n+k=7<=2^3-1。设信息位为D4D3D2D1(1010),校验位为P3P2P1,对应的海明码为H7H6H5H4H3H2H1
- (2)确定校验位的分布
规定校验位Pi在海明位号为2i-1的位置上,其余各位为信息位,因此有:
P1的海明位号为1,即H1为P1;P2的海明位号为2,即H2为P2;P3的海明位号为4,即H4为P3;海明位号各位的分布如下:
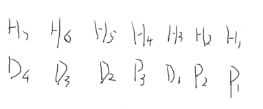
- (3)分组以形成校验关系
每个数据位用多个校验位进行校验,被校验数据位的海明位号等于校验该数据位的各校验位海明位号之和
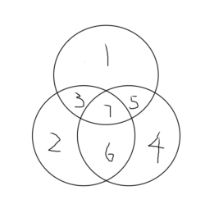
D1放在H3上,由P2P1校验;D2放在H5上,由P3P1校验;D3放在H6上,由P3P2校验;D4放在H7上,由P3P2P1校验;
-
(4)校验位取值
校验位Pi的值为第i组(由该校验位校验的数据位)所有位求异或
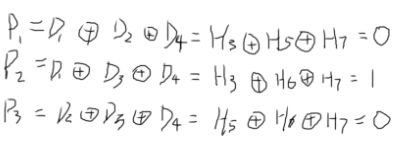
1010对应的海明码为1010010 -
(5)海明码的校验原理
每个校验组分别利用校验位和参与形成该校验位的信息位进行奇偶校验检查,构成k个校验方程:

若S3S2S1的值为000,则说明无错;否则说明出错,且这个数就是错误位的位号,如S3S2S1=001,说明第一位出错,即H1出错,直接将该位取反就达到了纠错目的。
3.循环冗余校验(CRC)码
循环冗余校验码(Cyclic Redundancy Check,CRC)码可发现并纠正信息在存储或传送过程中连续出现的多位错误代码
CRC的基本思想是:在K位信息码后再拼接R位的校验码,整个编码的长度为N位,因此这种编码也称为(N,K)码
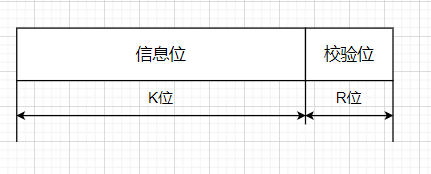
在发送端,将要传送的K位二进制信息码左移R位,将它与生成多项式G(x)做模2除法,生成一个R位校验码,并附在信息码后,构成一个新的二进制码(CRC码),共K+R位。在接收端,利用生成多项式对接受到的编码做模2除法,以检测和确定出错的位置,若无错则整除,其中生成多项式是接收端和发送端的一个约定。
任意一个二进制数码都可用一个系数仅为0 or 1的多项式与其对应。生成多项式G(x)的最高幂次为R,转换成对应的二进制数有R+1位。例如:![]()
设生成多项式为G(x)=x3+x2+1,信息码为101001,求对应的CRC码:
R=生成多项式最高幂次=3,K=6,N=9,生成多项式对应的二进制码为1101
- (1)移位
将原信息码左移R位,低位补0,得到101001000 - (2)相除
对移位后的信息码,用生成多项式进行模2除法,产生余数。模2除法:模2减即对每位做异或运算,模2除法和算术除法类似,但每位除(减)的结果不影响其他位,即不借位。
模2加法和减法的结果相同,都是做异或运算
- (3)纠错和检错
接收端收到的CRC码,用生成多项式G(x)做模2除法,若余数为0,则码字无错。若某一位出错,余数不为0,当出现不为0的余数后,一方面对余数补0继续做模2除,另一方面将被检测的校验码字循环左移,移满一个循环后,得到一个纠正后的码字。
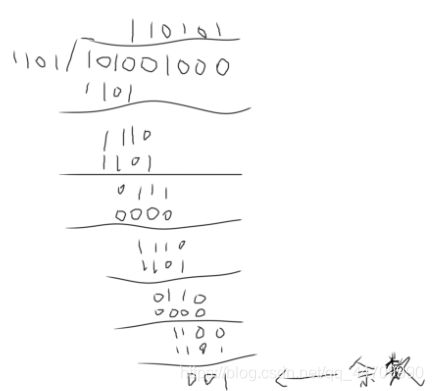
得到余数为001,则报文101001编码后,即CRC码为101001 001,若接收端收到的CRC码C9C8C7C6C5C4C3C2C1为101001 011,将这个数与1101进行模2除,得余数为010,则说明C2出错,将C2取反即可。
例题:在CRC中,接收端检测出某一位数据错误后,纠正的方法是()
A.请求重发 B.删除数据 C.通过余数值自行纠正 D.以上均可
答案:D;CRC可以纠正一位或多位错误(由多项式G(x)决定),而实际传输中纠正方法可以按需求进行选择,在计算机网络中,ABC三种方法都是很常见的
例题:说明CRC码的纠错原理和方法。对4位有效信息(1100)求循环校验码,选择生成多项式(1011)
答案:在CRC码中,选择适当的生成多项式G(x),在计算机二进制信息M(x)的长度确定时,余数与CRC出错位的对应关系是不变的,因此可以用余数作为判断出错位置的依据而纠正错码。CRC码的检错方法如下:接受数据时,将接收的CRC码与G(x)相除,若余数为0,则表明数据正确;若余数不为0,说明数据有错。若G(x)选择适当,余数还可以判断出错的位置,从而实现纠错。
1100的循环校验码为1100 010
2.2 定点数的表示与运算
2.2.1 定点数的表示
1.无符号数与有符号数的表示
在计算机中参与运算的机器数有两类:无符号数和有符号数
- (1)无符号数
指整个机器字长的全部二进制位均为数值位,没有符号位,相当于数的绝对值。若机器字长为8位,则数的表示范围为0~2^8-1,即0 ~255 - (2)有符号数
0正1负,通常约定二进制的最高位为符号位,即将符号位放在有效数字的前面,组成有符号数
有符号数的机器表示有原码、补码、反码、移码,约定X为真值,[X]原为原码,[X]补为补码,[X]反为反码,[X]移为移码。
2.机器数的定点表示
根据小数点的位置是否固定,在计算机中有两种数据格式:定点表示和浮点表示。定点表示的数称为定点数,浮点表示的数称浮点数。采用定点数的机器称为定点机。
在定点机中,由于小数点的位置固定不变,故当机器处理的数不是纯小数或纯整数时,必须乘上一个比例因子,否则将溢出。
定点表示即约定机器数中小数点位置是固定不变的,小数点不再使用“.”表示,而是约定它的位置。通常采用两种约定:将小数点的位置固定在数据的最高位之前(定点小数),或固定在最低位之后(定点整数)
-
(1)定点小数
定点小数是纯小数,约定小数点位置在符号位之后、有效数值部分最高位之前。若数据X的形式为X=x0.x1x2…xn(其中x0为符号位,x1~xn是数值的有效部分,也称尾数,x1为最高有效位),则在计算机中的表示形式为:(设机器字长为n+1位)
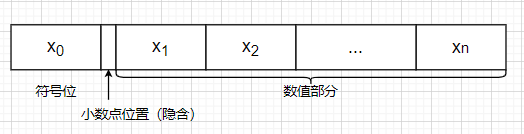
当x0=0,其余均为1时,X为最大正数1-2-n。x0=1,其余均为1时,X为其(原码)所能表示的最大负数-(1-2-n) -
(2)定点整数
定点整数是纯整数,约定小数点位置在有效数值部分最低位之后。

当x0=0,其余均为1时,X为最大正数2n-1。x0=1,其余均为1时,X为其(原码)所能表示的最大负数-(2n-1)
3.原码、补码、反码、移码
(1)原码表示法
用机器数的最高位表示该数的符号,其余的各位表示数的绝对值,故原码表示又称带符号的绝对值表示。
- 纯小数的原码定义

例如:字长为8位,x=+0.1101,[x]原=0.1101000;x=-0.1101,[x]原=1.1101000
若字长为n+1,原码小数的表示范围为-(1-2-n)~1-2-n(关于原点对称)
- 纯整数的原码定义
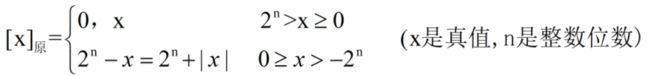
例如:字长为8位,x=+1110,[x]原=0,0001110;x=-1110,[x]原=1,0001110
若字长为n+1,原码整数的表示范围为-(2n-1)~2n-1(关于原点对称)
真值0的原码表示有正0和负0两种形式。[+0]原=0 0000和[-0]原=1 0000
(2)补码表示法
时钟指向6点,若要它指向3点,可顺时针转9格,也可逆时针转3格,6-3=3,6+9=15。时针转一圈能指示12小时,12在时钟里是不被显示而自动丢失的,15-12=3,15点和3点均显示3。在数学上称12为模,写为mod 12,称+9是-3以12为模的补数,记为 − 3 ≡ + 9 -3 \equiv +9 −3≡+9(mod 12),或者说,对于模12,-3和9互为补数
只要确定了模,就可找到一个与负数等价的正数(该正数即为负数的补数)来代替此负数,这样就可把减法运算用加法实现
补数概念中的结论有:a.一个负数可用它的正补数代替,而这个正补数可用模加上负数本身得到;b.一个正数和一个负数互为补数时,它们的绝对值之和即为模数;c.正数的补数即该正数本身
补码表示法中的加减法统一用加法实现
- 纯小数的补码定义
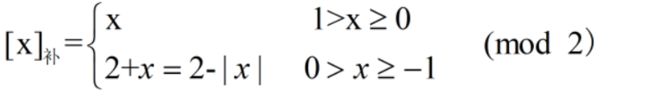
例如,字长为8位,x=+0.1001,[x]补=0.1001000;x=-0.0110,[x]补=1.1010000
若字长为n+1,补码的表示范围为-1~1-2-n(比原码多表示-1)
- 纯整数的补码定义
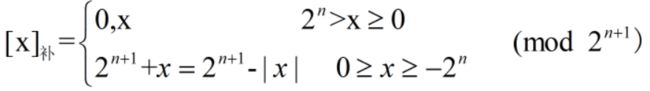
例如,字长为8位,x=+1010,[x]补=0,0001010;x=-1101,[x]补=1,1110011
若字长为n+1,补码的表示范围为-2n~2n-1(比原码多表示-2n)
真值0的补码表示是唯一的。即[+0]补=[-0]补=0.0000,由定义得[-1]补=10.0000-1.0000=1.0000,对于小数,补码比原码多表示一个-1(这是因为补码中的0只有1种表示形式,故它能比原码多表示一个-1)。对于整数,[-8]补=10000-1000=1000,补码比原码多表示一个-2n(因为补码没有负0,故诸如10000000这样的数表示的是8位补码的最小数-128)
- 由原码求补码、由补码求原码
正数原补码相同,[x]补=[x]原
对于负数,原码符号位不变,数值部分按位取反,末尾加1即得补码(取反加1,同样适用于由补码求原码) - 补码的算术移位
将[x]补的符号位与数值位一起右移一位并保持原符号位数值不变,可实现除法功能(除以2)。
变形补码,又称模4补码,双符号位的补码小数,其定义为:
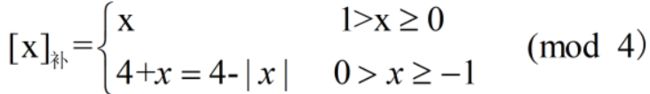
模4补码双符号位00表示正,11表示负,用在完成算术运算的ALU部件中
(3)反码表示法
反码通常用来作为由原码求补码或由补码求原码的中间过渡
- 纯小数的反码定义
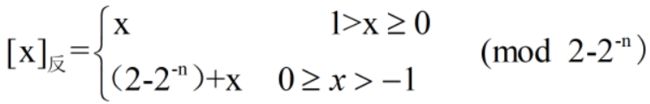
例如,字长为8位,x=+0.0110,[x]反=0.0110000;x=-0.0110,[x]补=1.1001111
若字长为n+1,反码的表示范围为-(1-2-n)~1-2-n(与原码纯小数的表示范围相同,关于原点对称)
真值0的反码表示不唯一,[+0]反=0 .0000和[-0]反=1.1111
- 纯整数的反码定义
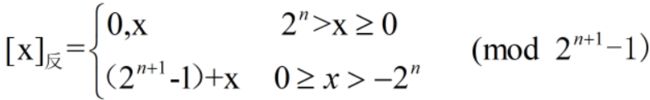
例如,字长为8位,x=+1011,[x]反=0,0001011;x=-1011,[x]反=1,1110100
若字长为n+1,反码的表示范围为-(2n-1)~2n-1(与原码纯整数的表示范围相同,关于原点对称)
真值、原码、补码、反码及[-x]补的转换规律为:
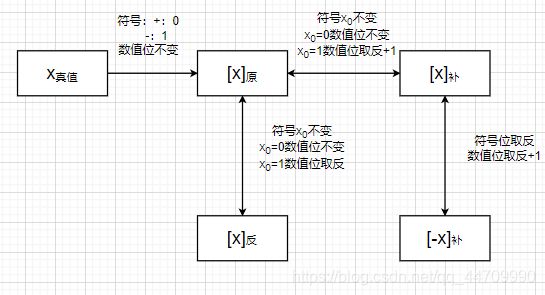
(4)移码表示法
能直接从移码形式判断其真值的大小,又因为检验移码的特殊值较容易,因此移码常用来表示浮点数的阶码。它只能表示整数。
移码就是在真值X上加上一个常数(偏置值),通常这个常数取2^n,相当于X在数轴上向正方向偏移了若干单位。移码定义为:
![]()
例如,字长为8位,x=+10101,[x]移=1,0010101;x=-10101,[x]移=0,1101011
移码的特点:
-
移码中0的表示唯一,[+0]移=2 ^ n+0=[-0]移=2^n-0=100…0(n个0)
-
一个真值的移码和补码仅差一个符号位,[x]补的符号位取反即得[x]移(1正0负,与其他机器数符号位取值正好相反),反之亦然
-
移码全0时,对应真值的最小值-2^n;移码全1时,对应真值的最大值
2 ^ n-1 -
移码保持了数据原有的大小顺序,移码大真值就大,移码小真值就小
长度为n+1的定点数,按不同编码方式表示的数据范围如下表:
例题:对真值0表示形式唯一的机器数是()
答案:补码和移码
例题:若定点整数为64位,含一位符号位,采用补码表示,所能表示的绝对值最大负数为()
答案:-263
例题:5位二进制定点小数,用补码表示时,最小负数是()
A.0.111 B.1.0001 C.1.111 D.1.0000
答案:D;
例题:下列关于补码和移码关系的叙述中,()是不正确的
A.相同位数的补码和移码表示具有相同的数据表示范围
B.0的补码和移码表示相同
C.同一个数的补码和移码表示,其数值部分相同,而符号相反
D.一般用移码表示浮点数的阶,而补码表示定点整数
答案:B
例题:若[x]补=1,x1x2x3x4x5x6,其中xi取0 or 1,若要x>-32,应当满足
A.x1为0,其他各位任意
B.x1为1,其他各位任意
C.x1为1,x2…x6中至少有1位为1
D.x1为0,x2…x6中至少有1位为1
答案:C
例题:设x为整数,[x]补=1,x1x2x3x4x5,若要x<-16,应当满足
A.x1~x5至少有一个为1
B.x1为0,x2~x5至少有一个为1
C.x1为0,x2~x5任意
D.x1为1,x2~x5任意
答案:C
例题:设x为真值,x*为其绝对值,满足 [ -x * ]补=[ -x ]补,当且仅当()
A.x任意 B.x为正数 C.x为负数 D.以上说法都不对
答案:D;当且仅当x为正数或0时
例题:关于模4补码,下列说法正确的是()
A.模4补码和模2补码不同,它更容易检查乘除运算中的溢出问题
B.每个模4补码存储时只需一个符号位
C.存储每个模4补码需要两个符号位
D.模4补码,在算术与逻辑部件中为一个符号位
答案:B;模4补码具有模2补码的全部优点且更易检查加减运算中的溢出问题,而不是乘除运算;存储模4补码仅需一个符号位,因为任何一个正确的数值,模4补码的两个符号位总是相同的,只在把两个模4补码的数送往ALU完成加减运算时,才把每个数的符号位的值同时送到ALU的双符号位中,即只在ALU中采用双符号位
例题:若寄存器内容为10000000,若它等于-0,则为()
A.原码 B.补码 C.反码 D.移码
答案:A;值等于-0说明只有可能是原码或反码(因为补码和移码表示0时是唯一的)
例题:在计算机中,通常用来表示主存地址的是()
A.移码 B.补码 C.原码 D.无符号数
答案:D;
例题:由3个1和5个0组成的8位二进制补码,能表示的最小整数是()
答案:-125
例题:证明:在定点小数表示中,[x]补+[y]补=2+(x+y)=[x+y]补
答案:分四种情况;(1)x>0,y>0:[x]补+[y]补=x+y=[x+y]补=2+x+y(mod 2);
(2)x>0,y<0:x+y有大于或小于0两种情况,[x]补+[y]补=2+x+y;若x+y>0,进位2丢失,[x]补+[y]补=x+y,又[x+y]补=x+y,得证。若x+y<0,[x+y]补=2+x+y,得证。
(3)x<0,y>0,与(2)同,把xy互换即可
(4)x<0,y<0:[x]补+[y]补=2+(2+x+y),因为1<2+x+y<2,进位2丢失,[x]补+[y]补=2+x+y=[x+y]补
结论:在模2意义下,任意两数的补码之和等于两数之和的补码,对定点整数也成立。
例题:假设有2个整数x和y,x=-68,y=-80,采用补码形式(含1位符号位)表示,x和y分别存放在寄存器A和B中。另外,还有两个寄存器C和D。ABCD都是8位的寄存器。请回答下列问题(二进制序列要求用16进制表示)
(1)寄存器A和B中的内容分别是什么
(2)x和y相加后的结果存放在寄存器C中,寄存器C中的内容是什么?此时,溢出标志位OF是什么?符号标志位SF是什么?进位标志位CF是什么?
(3)x和y相减后的结果存放在寄存器D中,寄存器D中的内容是什么?此时,溢出标志位OF是什么?符号标志位SF是什么?进位标志位CF是什么?
答案:(1)A、B内容分别为BCH、B0H;(2)6CH,OF=1,SF=0,CF=1;(3)0CH,OF=0,SF=0,CF=1
2.2.2 定点数的运算
1.定点数的移位运算
二进制表示的机器数在相对于小数点作n位左移或右移时,其实质就是该数乘以或除以2^n
移位运算根据操作对象的不同分为算术移位和逻辑移位。有符号数的移位称为算术移位,逻辑移位的操作对象是逻辑代码,可视为无符号数
- (1)算术移位
算术移位的对象是有符号数,在移位过程中符号位保持不变
对于正数,由于[x]原=[x]补=[x]反=真值,因此移位后出现的空位均用0填充。对于负数,由于原码、补码、反码的表示形式不同,因此当机器数移位时,对其空位的填补规则也不同。(不论是正数还是负数,移位后其符号位均不变,且移位后都相当于对真值补0,根据补码、反码的特性,在负数时填充代码有区别)
对于原码,左移一位若不产生溢出,相当于乘以2,右移一位,若不考虑因移出而舍去的末位尾数,相当于除以2。
不同机器数算术移位后的空位填补规则为:
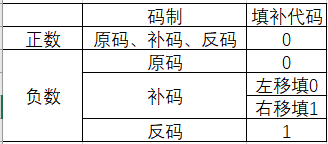
负数的原码数值部分与真值相同,在移位时只要使符号位不变,其空位均填0;负数的反码各位除符号位外与负数的原码正好相反,因此移位后所填的代码应与原码相反,即全部填1。
在由原码得补码的过程中(由高位到低位找到最后一个1后,后面的照抄),当对其由低位向高位找到第一个1时,在此1左边的各位均与对应的反码相同,在此1右边的各位(包括1在内)均与对应的原码相同。因此负数的补码左移时,因空位出现在低位,填补的代码与原码相同,即填0;右移时空位出现在高位,填补的代码与反码相同,即填1。 - (2)逻辑移位
逻辑移位将操作数视为无符号数,逻辑左移时,高位移丢,低位填0,右移时,低位移丢,高位填0;逻辑移位不管是左移还是右移,都填0; - (3)循环移位
循环移位分为带进位标志位CF的循环移位(大循环)和不带进位标志位的循环移位(小循环)
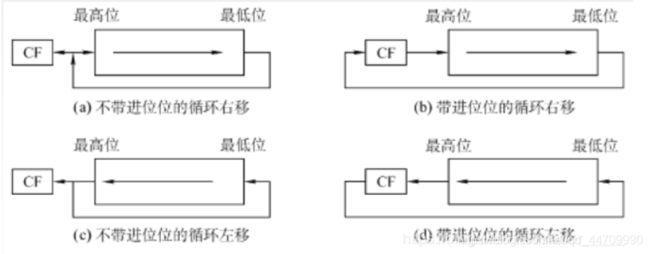
(a)不带进位的循环右移:操作数循环右移位,空出的高位部分由移出的低位部分来填充。同时,CF中只保存最后一次移出的那一位的内容
(b)带进位的循环右移:操作数连同CF位循环右移,用原CF的值填补空出的位,移出的位再进入CF。
(c)不带进位的循环左移:操作数循环左移位,空出的低位部分由移出的高位部分来填充。同时,CF中只保存最后一次移出的那一位的内容
(d)带进位的循环左移:操作数连同CF位循环左移,用原CF的值填补空出的位,移出的位再进入CF。
循环移位操作适合将数据的低字节数据和高字节数据互换
例题:一个8位寄存器内的数值为11001010,进位标志寄存器C为0,若将此8位寄存器循环左移(不带进位位)1位,则该8位寄存器和标志寄存器内的数值分别为()
答案:10010101 ; 1
例题:已知32位寄存器R1中存放的变量x的机器码为8000 0004H,当x为int类型时,乘除法采用移位操作,x的真值是多少?x/2的真值是多少?x/2存放在R1中的机器码是什么?2x的真值是多少?2x存放在R1中的机器码是多少?
答案:x为补码,x的真值为4-231,x/2的真值为2-230,x/2的机器码为C0000002H,2x的真值为8-232,发生溢出(能表示的最小数为-231)2x的机器码为8000 0008H
例题:下列关于各种移位的说法正确的是()
1.假设机器数采用反码表示,当机器数为负时,左移时最高数位丢0,结果出错;右移时最低数位丢0,影响精度
2.在算术移位的情况下,补码左移的前提条件是其原最高有效位与原符号位要相同
3.在算术移位的情况下,双符号位的移位操作只有低符号位需要参加移位操作
A.1,3 B.2 C.3 D.1,2,3
答案:D;双符号位的最高符号位代表真正的符号,而低位符号位用于参与移位操作以判断是否发生溢出
2.原码定点数的加减法运算
加法规则:先判符号位,若相同,则绝对值相加,结果符号位不变;若不同,则做减法,绝对值大的数减绝对值小的数,结果符号位与绝对值大的数相同。
减法规则:两个原码表示的数相减,首先将减数符号取反,然后将被减数与符号取反后的减数按原码加法进行运算。
3.补码定点数的加减法运算
计算机系统中普遍采用补码加减运算。补码运算符号位与数值位按同样规则一起参与运算,符号位运算产生的进位要丢掉,结果的符号位由运算得出。补码加减运算公式:
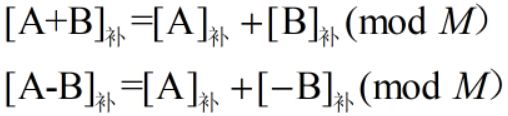
当参与运算的数是定点小数时,模M=2;参与运算的数是定点整数时,模M=2n+1,mod M运算是为了将溢出位丢掉
若做加法,两数补码直接相加;若做减法,则将被减数补码与减数的机器负数的补码相加。
例:机器字长为8位(含一位符号位),A=15,B=24,求[A+B]补和[A-B]补
[A]补=00001111,[B]补=00011000,[-B]补=11101000,[A+B]补=00100111,对应真值39,[A-B]补=11110111,对应真值-9
实现补码定点加减法的基本硬件配置框图如下:

图中寄存器A、X、加法器的位数相等,其中A存放被加数(或被减数)的补码,X存放加数(或减数)的补码。当作减法时,由“求补控制逻辑”将 X ‾ \overline{X} X送至加法器,并使加法器的最末位外来进位为1,以达到对减数求补的目的。运算结果溢出时,通过溢出判断电路置1溢出标记V。GA为加法标记,GS为减法标记
补码加减运算控制流程如图所示:
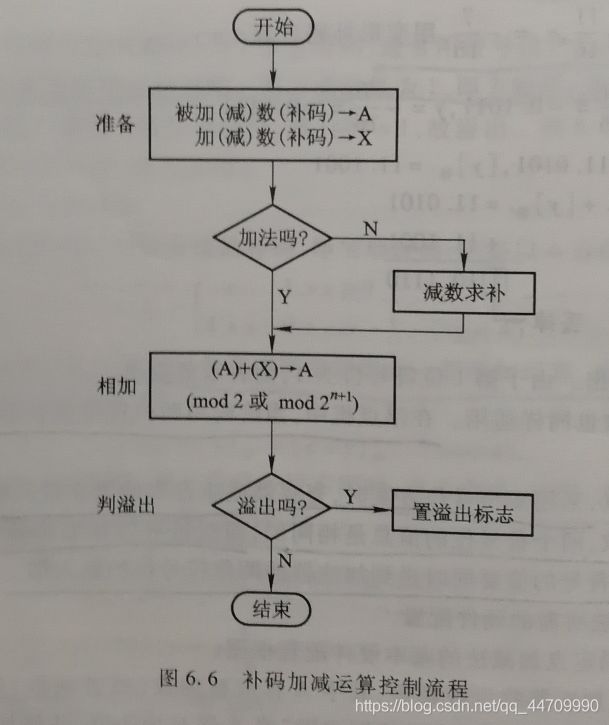
加(减)法运算前,被加(减)数的补码在A中,加(减)数的补码在X中。若是加法,直接完成(A)+(X)——>A(mod 2 或 mod 2n+1)的运算;若是减法,则需对减数求补,再和A寄存器中的内容相加,结果送A。最后完成溢出判断。
例题:假定有符号整数采用补码表示,若int型变量x和y的机器数分别是FFFF FFDFH和0000 0041H,则x,y的值(10进制)及x-y的机器数分别是()
答案:x=-33,y=65,x-y的机器数为FFFF FF9EH
4.符号拓展
在计算机算术运算中,有时必须把采用给定位数表示的数转换成具有不同位数的某种表示形式。例如,某个程序要将一个8位数与一个32位数相加,要想得到正确的结果,在将8位数与32位数相加之前,必须把8位数转换成32位数形式,这称为符号拓展。
正数的符号拓展即原有形式的符号位移动到新形式的符号位上,新表示形式的所有附加位都用0填充
负数的符号拓展方法则根据机器数的不同而不同。原码表示负数的符号拓展方法与正数相同,此时符号位为1。补码表示负数的符号拓展方法:原有形式的符号位移动到新形式的符号位上,新表示形式的所有附加位都用1(对于整数)或0(对于小数)进行填充。反码表示负数的符号拓展方法:原有形式的符号位移动到新形式的符号位上,新表示形式的所有附加位都用1进行填充。
5.溢出概念与判别方法
称大于机器所能表示的最大正数为上溢,小于机器所能表示的最小负数为下溢。定点小数的表示范围为|x|<1,如图:

仅当两个符号相同的数相加或两个符号相异的数相减才有可能产生溢出,如两个正数相加结果符号位为1,一个负数减一个正数,结果符号位为0
补码定点数加减运算溢出判断的方法有3种:
- (1)采用一位符号位
由于减法运算在机器中是用加法器实现的,因此无论是加法还是减法,只要参加操作的两个数符号相同,结果又与原操作数不同,则表示结果溢出
设A的符号位As,B的符号位为Bs,运算结果的符号位Ss,则溢出逻辑表达式为:(110或001)
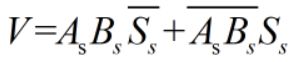
V=0表示无溢出,V=1表示有溢出 - (2)采用双符号位
双符号位法也称模4补码。运算结果的两个符号位Ss1Ss2相同,表示未溢出;不同表示溢出,此时最高位符号位代表真正的符号
符号位的各种情况:
Ss1Ss2=00;结果为正,未溢出
Ss1Ss2=01;结果为正,溢出
Ss1Ss2=10;结果为负,溢出
Ss1Ss2=11;结果为负,未溢出
溢出逻辑表达式为: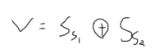
V=1溢出,V=0无溢出
采用双符号位时,寄存器或主存中的操作数只需保存1位符号位即可。因为任何正确的数,两个符号位的值总是相同的,而双符号位在加法器中又是必要的,故在相加时,寄存器中1位符号的值要送到加法器的两个符号位的输入端
- (3)采用一位符号位根据数据位的进位情况判断溢出
若符号位的进位Cs与最高位的进位C1相同,则说明没有溢出,否则有溢出。溢出的逻辑判断表达式为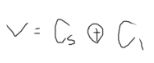
V=1有溢出,V=0无溢出
6.定点数的乘法运算
乘法操作由累加和右移操作实现。根据机器数的不同,可分为原码一位乘法和补码一位乘法。
- (1)原码一位乘法
原码一位乘法的特点是符号位与数值位是分开求的,乘积符号由两个数的符号位异或形成,而乘积的数值部分是两个数的绝对值相乘之积。
设[X]原=xs.x1x2…xn,[Y]原=ys.y1y2…yn,运算规则如下:
a. 被乘数与乘数均取绝对值参与运算,结果符号位为两个符号位的异或
b.部分积的长度同被乘数,取n+1位,以便存放乘法过程中绝对值大于等于1的值(进位时最高位改变的情况),初值为0
c.从乘数的最低位yn开始判断:若yn=1,则部分积加上被乘数|x|,然后右移一位;若yn=0,则部分积加上0,然后右移一位.部分积右移一位的同时,乘数也右移一位,由次低位作为新的末位,空出最高位放部分积的最低位(每次做加法时,被乘数仅与原部分积的高位相加,其低位被移至乘数所空出的高位位置)
d.重复步骤c,判断n次
由于乘积的数值部分是两数绝对值相乘的结果,因此原码一位乘法运算过程中的右移操作均为逻辑右移
考虑到运算时可能出现绝对值大于1的情况(进位时最高位改变的情况,但此刻并非溢出;若取单个符号位,最高位改变可能被当成溢出处理),所以部分积和被乘数取双符号位
例:设机器字长为5位(含一位符号位,n=4),x=-0.1101,y=0.1011,采用原码一位乘法求x*y
|x|=00.1101,|y|=00.1011

符号位为1,得x * y=-0.10001111
原码一位乘运算的基本硬件配置框图如下:
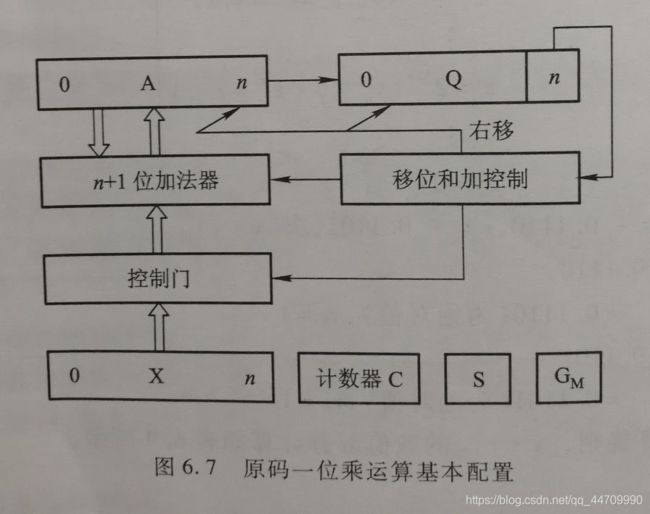
图中A、X、Q均为n+1位的寄存器,其中X存放被乘数的原码,Q存放乘数的原码。移位和加控制电路受末位乘数Qn的控制(当Qn=1时,A和X内容相加后,A、Q右移一位;当Qn=0时,只作A、Q右移一位的操作)。计数器C用于控制逐位相乘的次数。S存放乘积的符号。GM为乘法标记
原码一位乘控制流程如图:
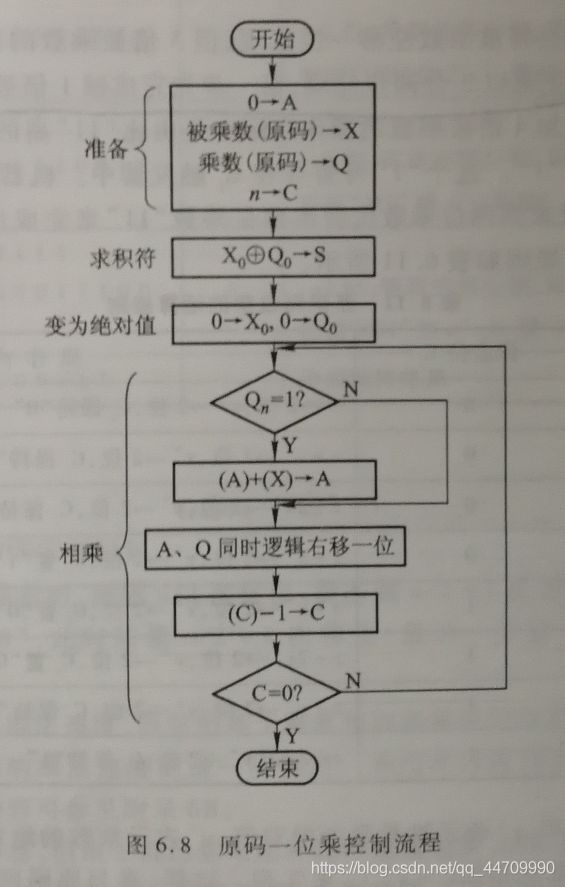
乘法运算前,A寄存器被清零,作为初始部分积,被乘数原码在X中,乘数原码在Q中,计数器C中存放乘数的位数n。乘法开始后,首先通过异或运算,求出乘积的符号并存于S,接着将被乘数和乘数从原码形式变为绝对值。然后根据Qn的状态决定部分积是否加上被乘数,再逻辑右移一位,重复n次。
例题:在原码一位乘法中,()
A.符号位参加运算
B.符号位不参加运算
C.符号位参加运算,并根据运算结果改变结果中的符号位
D.符号位不参加运算,并根据运算结果确定结果中的符号
答案:B;在原码一位乘中,符号位不参加运算,符号位单独处理
- (2)补码一位乘法(Booth算法)
这是一种有符号数的乘法,采用相加和相减操作计算补码数据的乘积。
设[X]补=xs.x1x2…xn,[Y]补=ys.y1y2…yn,运算规则如下:
a.符号位参与运算,运算的数均以补码表示
b.被乘数一般取双符号位参与运算,部分积取双符号位,初值为0,乘数可取单符号位
c.乘数末位增设附加位yn+1,且初值为0
d.根据(yn,yn+1)的取值来确定操作

e.移位按补码右移规则进行
f.按照上述算法进行n+1步操作,但第n+1步不再移位(共进行n+1次累加和n次右移),仅根据yn与yn+1的比较结果做相应的计算
例:设机器字长为5位(含一位符号位,n=4),x=-0.1101,y=0.1011,采用Booth算法求x*y
[x]补=11.0011,[-x]补=00.1101,[y]补=0.1011
[x * y]补=1.01110001,x * y=-0.10001111 - (3)乘法运算总结

7.定点数的除法运算
笔算除法的右移除数可以用左移余数的方法代替,最后得到的余数乘上2-n才是真正的余数;笔算除法求商是从高位向低位求的,转换为将每一位商写到寄存器的最低位,并把原来的部分商左移一位。
除法运算可转换成累加——左移(逻辑左移),根据机器数的不同,可分为原码除法和补码除法
- (1)原码除法运算(不恢复余数法)
原码除法主要采用原码不恢复余数法,也称原码加减交替除法。特点是商符和商值是分开进行的,商符由两个操作数的符号位异或形成。求商值的规则如下:
设被除数[X]原=xs.x1x2…xn,除数[Y]原=ys.y1y2…yn,则
a.商的符号
b.商的数值:|Q|=|X|/|Y|
求|Q|的不恢复余数法运算规则如下:
a.符号位不参与运算
b.先用被除数减去除数(|X|-|Y|=|X|+(-|Y|)=|X|+[-|Y|]补),当余数为正时,商上1,余数和商左移一位,再减去除数;当余数为负时,商上0,余数和商左移一位,再加上除数。
c. 当第n+1步余数为负时,需加上|Y|得到第n+1步正确的余数(余数与被除数同号)
例:设机器字长为5位(含一位符号位,n=4),x=0.1011,y=0.1101,采用原码加减交替除法求x/y
|x|=0.1011,|y|=0.1101,[|y|]补=0.1101,[-|y|]补=1.0011

Qs=0,得x/y=+0.1101,余0.0111 x 2-4 - (2)补码除法运算(加减交替法)
补码一位除法的特点是,符号位与数值位一起参与运算,商符自然形成。除法第一步根据被除数和除数的符号决定是做加法还是减法;上商的原则根据余数和除数的符号位共同决定,同号上商1,异号上商0;最后一步商恒置1。
加减交替法的规则如下:
a.符号位参与运算,除数与被除数均用补码表示,商和余数也用补码表示
b.若被除数与除数同号,则被除数减去除数;若被除数与除数异号,则被除数加上除数。
c.若余数与除数同号,则商上1,余数左移1位减去除数;若余数与除数异号,则商上0,余数左移一位加上除数
d.重复执行c操作n次
e.若对商的精度没有特殊要求,则一般采用末位恒置1法
例:设机器字长为5位(含一位符号位,n=4),x=0.1000,y=-0.1011,采用补码加减交替除法求x/y
采用2位符号位,[x]原=00.1000,[x]补=00.1000,[y]原=11.1011,
[y]补=11.0101,[-y]补=00.1011
得[x/y]补=1.0101,余0.0111 x 2-4 - (3)除法运算总结

2.2.3 C语言中的整数类型及类型转换
1.有符号数和无符号数的转换
int main()
{
short x=-4321;
unsigned short y=(unsigned short)x;
printf("x=%d,y=%u\n",x,y);
}
上述代码会输出x=-4321,y=61215
x=(1110 1111 0001 1111)2,y=(1110 1111 0001 1111)2
x为补码表示,y为无符号的二进制真值,被解释为61215。将short int 强制转换成unsigned short 只改变数值,而两个变量对应的每一位都是一样的。强制类型转换的结果保持位值不变,仅改变了解释这些位的方式。
int main()
{
unsigned short x=65535;
short y=(short)x;
printf("x=%u,y=%d\n",x,y);
}
输出x=65535,y=-1
2.不同字长整数之间的转换
int main()
{
int x=165537,u=-34991; //int型占用4B
short y=(short)x,v=(short)u; //short型占用2B
printf("x=%d,y=%d\n",x,y);
printf("u=%d,v=%d\n",u,v);
}
输出x=165537,y=-31071,u=-34991,v=30545
其中x、y、u、v的16进制表示分别为0x000286a1、0x86a1、0xffff7751、0x7751。当大字长变量向小字长变量强制类型转换时,系统把多余的高位字长部分直接截断,低位直接赋值。
int main()
{
short x=-4321;
int y=x;
unsigned short u=(unsigned short)x;
unsigned int v=u;
printf("x=%d,y=%d\n",x,y);
printf("u=%u,v=%u\n",u,v);
}
输出x=-4321,y=-4321,u=61215,v=61215
x、y、u、v的16进制表示分别是0xef1f、0xffffef1f、0xef1f、0x0000ef1f;
短字长整数到长字长整数的转换,不仅要使对应的位值相等,高位部分还会扩展为原数字的符号位。(短字长到长字长的转换,在位值相等的条件下还要补充高位的符号位,转换后所表示的数值与原数值一样)
char类型为8位ASCII码整数,其转换为int时,在高位部分补0即可
例题:一个C语言程序在一台32位机器上运行。程序中定义了三个变量xyz,其中x和z为int型,y为short型。当x=127,y=-9时,执行语句z=x+y后,xyz的值分别是()
答案:x=0000007FH,y=FFF7H,z=00000076H,y将被强制转换为int型,扩充的位数用1填补
例题:假定在一个8位字长的计算机中运行如下C程序段:
unsigned int x=134;
unsigned int y=246;
int m=x;
int n=y;
unsigned int z1=x-y;
unsigned int z2=x+y;
int k1=m-n;
int k2=m+n;
(1)执行上述程序段后,变量m和k1的值分别是多少(用10进制表示)
(2)上述程序段涉及有符号整数加减、无符号整数加减运算,这四种运算能否利用同一个加法器辅助电路实现?简述理由
(3)计算机内部如何判断有符号整数加减运算的结果是否发生溢出?上述程序段中,哪些有符号整数运算语句的执行结果会发生溢出
答案:(1)m=-122,k1=-112;
(2)能。n位加法器实现的是模2n无符号整数加法运算。对于无符号整数a和b,a+b可直接用加法器实现,而a-b可用a加b的补数实现,即
a-b=a+[-b]补(mod 2n),所以n位无符号整数加减运算都可在n位加法器中实现。由于有符号整数用补码表示,补码加减运算公式为
[a+b]补=[a]补+[b]补(mod 2n);[a-b]补=[a]补+[-b]补(mod 2n),所以n位有符号整数加减运算都可在n位加法器中实现
(3)有符号整数加减运算的溢出判断规则为:若加法器的两个输入端(加法)的符号相同,且不同于输出端(和)的符号,则结果溢出,或加法器完成加法操作时,若次高位(最高数位)的进位和最高位(符号位)的进位不同,则结果溢出
有符号整数运算语句中,int k2=m+n会溢出
例题:

答案:(1)n=0时,n-1的机器数为全1,值为unsigned类型可表示的最大数,循环判断条件永真。若都定义为int型,不会死循环,n-1=-1,当i=0时循环判断条件不成立,循环退出
(2)相等,各为00FFFFFFH,4B7FFFFFH;
(3)float型数只有24位有效位,舍入后数值增大,所以比f1(24)大1
(4)得到的sum的机器数为全1,作为int型解释时为-1。最大n值是30
(5)对应的值是无穷大,不溢出的最大n为126,不舍入的最大n为23
2.2.4 数据的存储和排列
1.数据的大端方式和小端方式存储
在存储数据时,数据从低位到高位可按从左至右排列,也可按从右到左排列。通常用最低有效字节(LSB)和最高有效字节(MSB)来分别表示数的低位和高位。例如,在32位计算机中,一个int型变量i的机器数为01 23 45 67H,其最高有效字节MSB=01H,最低有效字节LSB=67H。
现代计算机基本上都采用字节编址,即每个地址编号中存放1字节。不同类型的数据占用的字节数不同,int和float型数据占4B,double型数据占8B,而程序中对每个数据只给定一个地址。
多字节数据都存放在连续的字节序列中,根据数据中各字节在连续字节序列中的排列顺序不同,可采用两种排列方式:大端方式(big endian)和小端方式(little endian)

大端方式按从最高有效字节到最低有效字节的顺序存储数据,即最高有效字节存放在前面;小端方式按从最低有效字节到最高有效字节的顺序存储数据,即最低有效字节存放在前面。
例如,反汇编得到:4004d3: 01 05 64 94 04 08 add %eax,0x8049464
其中4004d3是16进制表示的地址,01 05 64 94 04 08是指令的机器代码,add %eax,0x8049464是指令的汇编形式,该指令的第二个操作数是一个立即数0x8049464。执行指令时,从指令代码的后4字节中取出该立即数,可知采用的是小端方式存储。(在小端方式存储的机器代码中,字节是按相反顺序显示的)
2.数据按边界对齐方式存储
假设存储字长为32位,可按字节、半字和字寻址。对于机器字长为32位的计算机,数据以边界对齐方式存放,半字地址一定是2的整数倍,字地址一定是4的整数倍,这样无论所取的数据是字节、半字还是字,均可一次性访存取出。所存储的数据不满足上述条件时,填充空白字节。使用这种方式浪费了一些存储空间,提高了取指令和数据的速度(空间换时间)。
数据不按边界对齐方式存储时,可充分利用存储空间,但半字长或字长的指令可能会存储在两个存储字中,此时需2次访存,且对高低字节的位置进行调整、连接之后才能得到所要的指令或数据。

2.3 浮点数的表示与运算
2.3.1 浮点数的表示
1.浮点数的表示格式
浮点数即小数点的位置能浮动的数,通常,浮点数表示为N=rE x M,r是浮点数阶码的底(隐含),与尾数的基数相同,通常r=2。E和M都是有符号的定点数,E称为阶码,M称为尾数。浮点数由阶码和尾数两部分组成。

阶码是整数,阶符Jf和阶码的位数m共同反映浮点数的表示范围及小数点的实际位置;数符Sf代表浮点数的符号;尾数的位数n反映浮点数的精度;基数r越大,可表示的浮点数范围越大,所表示的数的个数越多,但浮点数精度下降
2.规格化浮点数
为提高运算的精度,需充分利用尾数的有效数位,通常采取浮点数规格化形式,即规定尾数的最高数位必须是一个有效值。非规格化浮点数需要进行规格化操作才能变成规格化浮点数。规格化操作即指通过调整一个非规格化浮点数的尾数和阶码的大小,使非0的浮点数在尾数的最高数位上保证是一个有效值。
左规:将尾数算术左移一位、阶码减1(基数为2时)的方法称为左规,左规可能要进行多次。
右规:当浮点数运算的结果尾数出现溢出(双符号位为01或10)时,将尾数算术右移一位,阶码加1(基数为2时)的方法称为右规。需要右规时,只需进行一次。
规格化浮点数的尾数M的绝对值应满足条件1/r<=|M|<=1。
若r=2,则有1/2<=|M|<=1。
规格化表示的尾数形式如下:
- (1)原码规格化后
正数为0.1xx…x的形式,其最大值表示为0.11…1,最小值表示为0.100…0。尾数的表示范围为1/2<=M<=(1-2-n)。
负数为1.1xx…x的形式,其最大值表示为1.10…0,最小值表示为1.11…1。尾数的表示范围为-(1-2-n)<=M<=-1/2。 - (2)补码规格化后
正数为0.1xx…x的形式,其最大值表示为0.11…1,最小值表示为0.100…0。尾数的表示范围为1/2<=M<=(1-2-n)。
负数为1.0xx…x的形式,其最大值表示为1.01…1,最小值表示为1.00…0。尾数的表示范围为-1<=M<=-(1/2+2n)。
当浮点数尾数的基数为2时,原码规格化数的尾数最高位一定是1,补码规格化数的尾数最高位一定与尾数符号位相反。基数不同,浮点数的规格化形式也不同。当基数为4时,原码规格化形式的尾数最高2位不全为0,规格化时,尾数左/右移2位,阶码减/加1;当基数为8时,原码规格化形式的尾数最高3位不全为0,规格化时,尾数左/右移3位,阶码减/加1
例题:采用规格化的浮点数最主要是为了()
A.增加数据的表示范围 B.方便浮点运算
C.防止运算时数据溢出 D.增加数据的表示精度
答案:D;
例题:设浮点数共12位。其中阶码含1位阶符共4位,以2为底,补码表示;尾数含1位数符共8位,补码表示,规格化。则该浮点数所能表示的最大正数是()
答案:27-1;
例题:已知X=-0.875 x 21,Y=0.625 x 22,设浮点数格式为阶符1位,阶码2位,数符1位,尾数3位,通过补码求出Z=X-Y的二进制浮点数规格化结果是()
答案:0111011;浮点数表示为:X=001 1001 Y=010 0101;
-Y=010 1011;X的尾数部分为11.001,右规后为11.100;-Y的尾数部分为11.011,X、-Y尾数相加(运算时采用双符号位,但存储时只存储一位符号位即可),得10.111,右规得11.011(双符号位的最高符号位代表真正的符号,而低位符号位用于参与移位操作以判断是否发生溢出。双符号位设置的意义就在于用低符号位容纳最高数位产生的进位,而用高符号位表示真正的符号。双符号位10右规符号位变成11,双符号位01右规符号位变成00,10表示负溢出,右规之后还是负数,即变成11),最后的结果为0111011
例题:已知十进制数x=-5/256、y=+59/1024,按机器补码浮点运算规则计算x-y,结果用二进制表示,浮点数格式如下:阶符取2位,阶码取3位,数符取2位,尾数取9位
答案:11101,11.011000100
例题:设浮点数字长32位,其中阶码部分8位(含一位阶符),尾数部分24位(含1位数符),当阶码的基值分别是2和16时:
(1)说明基值2和16在浮点数中如何表示
(2)当阶码和尾数均用补码表示,且尾数采用规格化形式时,给出两种情况下所能表示的最大正数真值和非零最小正数真值
(3)在哪种基值情况下,数的表示范围大
(4)两种基值情况下,对阶和规格化操作有何不同
答案:(1)浮点机中一旦基值确定了就不会再改变,所以基值2和16在浮点数中是隐含表示的,并不出现在浮点数中;
(2)r=2时,最大正数真值2127 x (1-2-23),最小正数真值2-129
r=16时,最大正数真值16127 x (1-2-23),最小正数真值16-129(尾数数据位最高4位不全为0)
(3)r=16时,数的表示范围大
(4)对阶中,需要小阶向大阶看齐,基值为2的浮点数尾数右移一位,阶码加1,基值为16的浮点数尾数右移4位,阶码加1。规格化时,若为原码规格化,若基值为2的浮点数尾数最高有效位出现0,需尾数左移1位,阶码减1;当基数为16时,原码规格化形式的尾数最高4位若全为0,尾数左移4位,阶码减1
例题:设浮点数的格式如下(阶码和尾数均用补码表示,基为2)

(1)将27/64转换为浮点数
(2)将-27/64转换为浮点数
答案:(1)1111,0110110000;(2)1111,1001010000
例题:两个规格化浮点数进行加减法运算,最后对结果规格化时,能否确定需要右规的次数?能否确定需要左规的次数?
答案:两个n位数的加减运算,其和/差最多为n+1位,因此有可能需要右规,但右规最多一次。由于异号数相加或同号数相减,其和/差的最少位数无法确定,因此左规的次数也无法确定,但最多不会超过尾数的字长n位次(正数最多n-1次,负数最多n次)。
3.浮点数的表示范围(考研大纲中已删除)
设阶码和尾数均用补码表示,阶码部分共K+1位(含一位阶符),尾数部分共n+1位(含一位数符),浮点数表示范围如下:
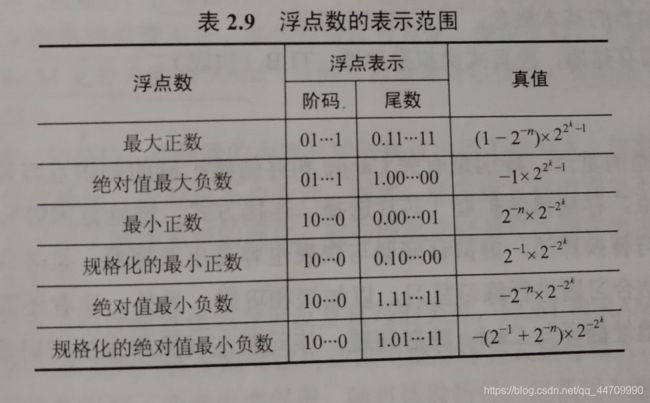
运算结果大于最大正数时称为正上溢,小于绝对值最大负数时称为负上溢,正上溢和负上溢统称上溢。数据一旦产生上溢,计算机必须中断运算操作,进行溢出处理。当运算结果在0至最小正数之间时称为正下溢,在0至绝对值最小负数之间称为负下溢,正下溢和负下溢统称下溢。数据下溢时,浮点数值趋于0,计算机将其当做机器零处理。

例题:什么是浮点数的溢出?什么情况下发生上溢出?什么情况下发生下溢出?
答案:浮点数的运算结果可能出现以下几种情况:
1.阶码上溢出。一个正指数超过了最大允许值时,浮点数发生上溢出。若结果是正数,则发生正上溢出;若结果是负数,则发生负上溢出。这种情况为软件故障,通常要引入溢出故障处理程序处理
2.阶码下溢出。一个负指数比最小允许值还小时,浮点数发生下溢出。一般机器把下溢出时的值置为0。不发生溢出故障。
3.尾数溢出。当尾数最高有效位有进位时,发生尾数溢出。此时进行右规,直到尾数不溢出为止。此时,只要阶码不发生上溢出,浮点数就不会溢出(运算结果超过尾数表示范围不一定溢出,只有规格化后阶码超出所能表示的范围时,才发生溢出)
4.非规格化尾数。当数值部分高位不是一个有效值时(如原码时为0或补码时与符号位相同),尾数为非规格化形式。此时进行左规,直到尾数为规格化形式为止。
4.IEEE754标准
按照IEEE754标准的浮点数格式如图:
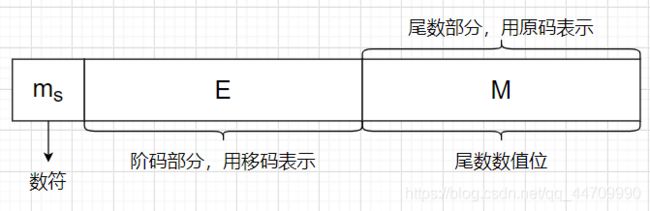
IEEE754标准规定常用的浮点数格式有短浮点数(单精度、float型)、长浮点数(双精度、double型)、临时浮点数
IEEE754标准的浮点数(除临时浮点数外),是尾数用采取隐藏位策略的原码表示,且阶码用移码表示的浮点数。
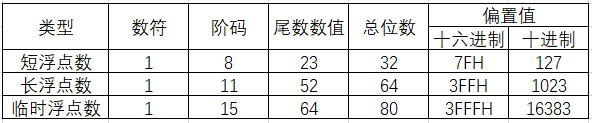
以短浮点数为例,最高位为数符位,其后是8位阶码,以2为底,用移码表示,阶码的偏置值为28-1-1=127;其后23位是原码表示的尾数数值位。对于规格化的2进制浮点数,数值的最高位总是1,为了能使尾数多表示一位有效位,将这个1隐含,因此尾数数值实际上是24位。隐含的1是一位整数。在浮点格式中表示的23位尾数是纯小数。例如,(12)10=(1100)2,规格化后结果为1.1x23,其中整数部分的1将不存储在23位尾数内。(短浮点数与长浮点数都采用隐含尾数最高数位的方法,临时浮点数又称扩展精度浮点数,无隐含位)
为何要用移码表示阶码:a.移码比较大小更方便;b.检验移码的特殊值时较容易
移码即真值+偏置值。偏置值为127,而非128的原因是:指数可以为正数也可以为负数,为将负数转变为正数(为了不在阶码中引入阶符),实际的指数值要加上偏置值。
-127~+127加上127即得到 0 ~ +254,然而阶码值E的范围为1~254,因为阶码为0时表示指数为负无穷大,整个数无穷接近于0,可将0用于表示0(尾数也为0时)或非规格化数(尾数不为0时)。为什么不加128呢?因为255为8位全1,也有特殊用途,当阶码值为255时(指数为正无穷),若尾数部分为0,则表示无穷大;若尾数部分不为0,则认为这是一个“非数值”(浮点数运算错误)
阶码是以移码形式存储的。对于短浮点数,偏置值为127;对于长浮点数,偏置值为1023。存储浮点数阶码部分之前,偏置值要先加到阶码真值上。例如1.1x23,阶码值为3,在短浮点数中,移码表示的阶码为130(82H);在长浮点数中,阶码为1026(402H)
IEEE754标准中,规格化的短浮点数真值为:(-1)s x 1.M x 2 E-127;规格化长浮点数真值为:(-1)s x 1.M x 2 E-1023
短浮点数E的取值为1~ 254(8位表示),M为23位,共32位;长浮点数E的取值为1~2046(11位表示),M为52位,共64位。IEEE754标准浮点数的范围为:

例题:按照IEEE754标准规定的32位浮点数(41A4C000)16对应的10进制数是()
A.4.59375 B.-20.59375 C.-4.59375 D.20.59375
答案:D;
例题:假定采用IEEE754标准中的单精度浮点数格式表示一个数为45100000H,则该数的值是()
A.(+1.125)10 x 210 B.(+1.125)10 x 211
C.(+0.125)10 x 211 D.(+0.125)10 x 210
答案:B;
例题:已知两个实数x=-68,y=-8.25,它们在C语言中定义为float型变量,分别存放在寄存器A和B中。另外还有两个寄存器C和D。ABCD都是32位的寄存器。请问(要求用16进制表示2进制序列)x和y相减后的结果存放在D中,D中的内容是什么
答案:IEEE754标准,x的浮点数表示为
1 1000 0101 0001000 0000 0000 0000 0000
即x=-1.0001 x 26
y的浮点数表示为
1 1000 0010 000 0100 0000 0000 0000 0000,对阶后为:
1 1000 0101 001 0000 1000 0000 0000 0000,
即y=-0.00100001 x 26
进行尾数原码减法,得x-y=-0.11101111 x 26=-1.1101111 x 25,浮点表示为C26F0000H
例题:对下列每个IEEE754单精度数值,解释它们所表示的是哪种数字类型(规格化数、非规格化数、无穷大、0)。当它们表示某个具体数值时,给出该数值。
(1)0b0000 0000 0000 0000 0000 0000 0000 0000
(2)0b0100 0010 0100 0000 0000 0000 0000 0000
(3)0b1000 0000 0100 0000 0000 0000 0000 0000
(4)0b1111 1111 1000 0000 0000 0000 0000 0000
答案:前面的0b意思是数字的表示形式为二进制
(1)+0;(2)规格化数,25 x (1.1)2;
(3)非规格化数,尾数首位无隐藏的整数1,阶码全0时有特殊规定为
2-126 ,因此(3)表示2-126 x (-0.1)2;
(4)负无穷
5.定点、浮点表示的区别
-
(1)数值的表示范围
若定点数和浮点数的字长相同,则浮点表示法所能表示的数值范围将远远大于定点表示法 -
(2)精度
精度指一个数所含有效数值位的位数。对于字长相同的定点数和浮点数来说,浮点数虽然扩大了数的表示范围,但精度降低了(要用字长的一部分表示阶码,尾数部位的有效位数减少) -
(3)数的运算
浮点数包括阶码和尾数两部分,运算时不仅要做尾数的运算,还要做阶码的运算,而且运算结果要求规格化 -
(4)溢出问题
在定点运算中,当运算结果超出数的表示范围时,发生溢出;浮点运算中,运算结果超出尾数表示范围时不一定溢出,只有规格化后阶码超出所能表示的范围时,才发生溢出
对于位数相同的定点数与浮点数,可表示的浮点数个数比定点数个数多吗?
否,可表示的数据个数取决于编码所采用的位数。编码位数一定,编码出来的数据个数是一定的。n位编码只能表示2^n个数,所以对于相同位数的定点数与浮点数来说,可表示的数据个数应该一样多(有时可能由于一个值有2个或多个编码对应,编码个数会有少量差异)
2.3.2 浮点数的加减运算
阶码运算和尾数运算分开进行。浮点数的加减运算一律采用补码。
1.对阶
对阶的目的是使两个操作数的小数点位置对齐,即使得两个数的阶码相等。先求阶差,然后以小阶向大阶看齐的原则,将阶码小的尾数右移一位(基数为2),阶加1,直到两个数的阶码相等为止。尾数右移时,舍弃掉有效位会产生误差,影响精度
2.尾数求和
将对阶后的尾数按定点数加减运算规则计算
3.规格化
以双符号位为例,当尾数大于0时,其补码规格化形式为:
[S]补=00.1xx…x
当尾数小于0时,其补码规格化形式为:
[S]补=11.0xx…x
当尾数的最高数值位与符号位不同时,即为规格化形式。规格化分为左规和右规
-
(1)左规
当尾数出现00.0xx…x或11.1xx…x时,需左规,尾数左移一位,阶码减1,直到尾数为00.1xx…x或11.0xx…x -
(2)右规
当尾数求和结果溢出(如尾数为10.xx…x或01.xx…x)时,需右规,尾数右移1位,阶码加1
4.舍入
在对阶和右规的过程中(进行了右移),可能会将尾数低位丢失,引起误差。常见的舍入方法有:0舍1入法和恒置1法
0舍1入法:类似于4舍5入,尾数右移时,被移去的最高数值位为0,则舍去;被移去的最高数值位为1,则在尾数的末位加1。这样做可能会使尾数再一次溢出,此时需再做一次右规。
恒置1法:尾数右移时,都使右移后的尾数末位恒置1,此方法有使尾数变大和变小(尾数为负时)两种可能。
5.溢出判断
当尾数之和(差)出现10.xx…x或01.xx…x时,并不表示溢出,需将此数右规后,根据阶码判断结果是否溢出
浮点数溢出与否是由阶码的符号决定的。以双符号位补码为例,当阶码的符号位出现01时,即阶码大于最大阶码,表示上溢,进入中断处理;当阶码的符号位出现10时, 阶码小于最小阶码,表示下溢,按机器零处理。
例题:浮点数加、减运算过程一般包括对阶、尾数运算、规格化、舍入和判断溢出等步骤。设浮点数的阶码和尾数均采用补码表示,且位数分别为5和7(均含2位符号位)。若有两个数X=27x29/32和Y=25x5/8,则用浮点加法计算X+Y的最终结果是()
A.00111 1100010 B.00111 0100010 C.01000 0010001 D.溢出
答案:D;
例题:下列关于对阶操作说法正确的是()
A.在浮点加减运算的对阶操作中,若阶码减小,则尾数左移
B.在浮点加减运算的对阶操作中,若阶码增大,则尾数右移;若阶码减小,则尾数左移
C.在浮点加减运算的对阶操作中,若阶码增大,则尾数右移
D.以上都不对
答案:C;对阶操作,是将小的阶码调整到与大的阶码一致(小的向大的对齐),只可能尾数右移,因此不存在阶码减小,尾数左移的情况
例题:下列关于舍入的说法,正确的是()
1.不仅仅只有浮点数需要舍入,定点数在运算时也可能要舍入
2.在浮点数舍入中,只有左规时可能要舍入
3.在浮点数舍入中,只有右规时可能要舍入
4.在浮点数舍入中,左右规格化均可能要舍入
5.舍入不一定产生误差
答案:5;舍入是浮点数的概念,定点数没有舍入的概念;浮点数舍入的情况有2种:对阶(对阶时需要尾数右移)与右规;舍入不一定产生误差
6.C语言中的浮点数类型及类型转换
C语言中的float和double类型分别对应于IEEE754单精度浮点数和双精度浮点数。long double类型对应于扩展双精度浮点数,但其长度和格式随编译器和处理器类型的不同而不同。在C程序中等式的赋值和判断中会出现强制类型转换,以char->int->long->double和float->double最为常见,从前到后范围和精度都从小到大,转换过程中没有损失。
- (1)从int转换为float时,虽然不会发生溢出,但int可以保留32位,float保留24位(尾数+隐含位),可能有数据舍入,若从int转换为double则不会出现
- (2)从int或float转换为double时,由于double的有效位数更多,因此能保留精确值
- (3)从double转换为float时,由于float表示范围更小,因此可能发生溢出,由于有效位数变少,可能被舍入
- (4)从float或double转换为int时,因为int没有小数部分,所以数据可能会向0方向被截断(仅保留整数部分),影响精度,由于int的表示范围更小,可能发生溢出
2.4 算术逻辑单元(ALU)
运算器由算术逻辑单元ALU、累加器、状态寄存器和通用寄存器组等组成。ALU的基本功能包括加减乘除四则运算,与或非,异或等逻辑运算,以及移位、求补等操作。
运算器的操作和操作种类由控制器决定。运算器处理的数据来自存储器;处理后的结果数据通常送回存储器,或暂存在运算器中。
2.4.1 串行加法器和并行加法器
加法器是由全加器再配以其他必要的逻辑电路组成的,根据组成加法器的全加器个数是单个还是多个,加法器有串行和并行之分。
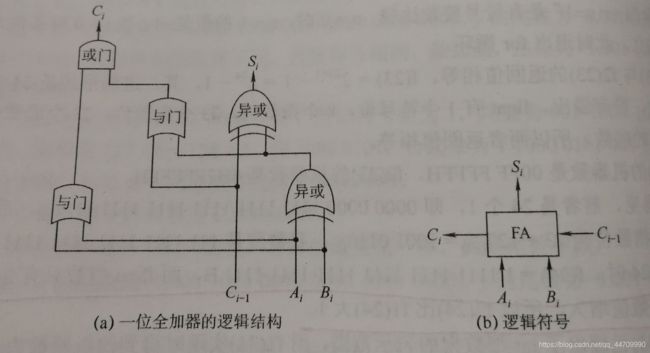
1.一位全加器
全加器(FA)是最基本的加法单元,有加数Ai、加数Bi与低位传来的进位Ci-1共三个输入,有本位和Si与向高位的进位Ci共两个输出。
全加器的逻辑表达式如下:

一位全加器的逻辑结构和逻辑符号为:
2.串行加法器
在串行加法器中,有一个全加器,数据逐位串行送入加法器中进行运算。若操作数长n位,则加法就要分n次进行,每次产生1位和,并且逐行地送回寄存器。进位触发器用来寄存进位信号,以便参与下一次运算。
3.并行加法器
并行加法器由多个全加器组成,其位数与机器的字长相同,各位数据同时运算。并行加法器可同时对数据的各位相加。虽然操作数的各位是同时提供的,但低位运算所产生的进位会影响高位的运算结果,并行加法器的最长运算时间主要是由进位信号的传递时间决定的,而每个全加器本身的求和延迟只是次要因素。
提高并行加法器速度的关键是尽量加快进位产生和传递的速度
并行加法器的进位产生和传递如下:
并行加法器中的每个全加器都有一个从低位送来的进位输入和一个传送给高位的进位输出。通常将传递进位信号的逻辑线路连接起来构成的进位网络称为进位链。
进位表达式为:
Ci=Gi+PiCi-1(Gi=1或PiCi-1=1时,Ci=1)
Gi是进位产生函数,Gi=AiBi;Pi是进位传递函数,Pi=Ai ⨁ \bigoplus ⨁Bi
当Ai与Bi都为1时,Ci=1,即有进位信号产生,所以将AiBi称为进位产生函数或本地进位,并以Gi表示。Ai ⨁ \bigoplus ⨁Bi=1且Ci-1=1时,Ci=1。这种情况可视为第i-1位的进位信号Ci-1可通过本位向高位传送,因此,把Ai ⨁ \bigoplus ⨁Bi称为进位传递函数(进位传递条件),并以Pi表示
并行加法器的进位通常分为串行进位与并行进位
- (1)串行进位
把n个全加器串接起来,就可以进行2个n位数的相加,这种加法器称为串行进位的并行加法器,串行进位又称行波进位,每级进位直接依赖于前一级的进位,即进位信号是逐级形成的。
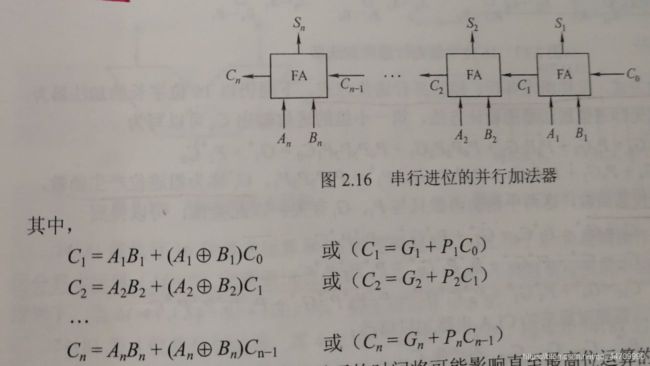
并行加法器的最长运算时间主要是由进位信号的传递时间决定的,位数越多延迟时间就越长,而全加器本身的求和延迟为次要因素。 - (2)并行进位
并行进位又称先行进位、同时进位,其特点是各级进位信号同时形成。
采用并行进位的方式可加快进位产生和传递的速度,即将各级低位产生的本级G和P信号依次同时送到高位各全加器的输入,以使它们同时形成进位信号,各进位信号表达式如下:
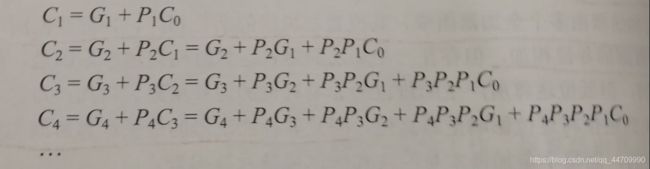
上述各式中所有的进位输出仅由Gi、Pi及最低进位输入C0决定,而不依赖于其低位的进位输入Ci-1,因此各级进位输出可同时产生。
这种进位方式是快速的,与字长无关。但随加法器位数增加,电路结构会很复杂。实际情况下可采用分组并行进位方式,把n位全加器分为若干小组,小组内的各位之间实行并行快速进位,小组与小组之间可采用串行进位方式,也可采用并行快速进位方式。有以下两种情况: - a.单级先行进位方式(单重分组跳跃进位),又称组内并行、组间串行进位方式。以16位加法器为例,可分为4组,每组4位。第一小组组内的进位逻辑函数C1C2C3C4是同时产生的,实现上述进位逻辑的电路称为4位先行进位电路CLA。利用4位CLA电路及进位产生/传递电路和求和电路可构成4位CLA加法器。用4个这样的CLA加法器构成的16位单级先行进位加法器如图所示:

- b.多级先行进位方式,又称组内并行、组间并行进位方式。仍以16位字长的加法器为例,分析两级先行进位加法器的设计方法。第一小组的进位输出C4可以写为:

这种电路称为成组先行进位电路(BCLA)。利用这种4位的BCLA电路及进位产生与传递电路和求和电路可构成4位BCLA加法器。16位的两级先行进位加法器可由4个BCLA加法器和1个CLA电路构成:

2.4.2 算术逻辑单元的功能和结构
ALU的基本结构为:

Ai和Bi为输入变量;Ki为控制信号,Ki的不同取值可决定该电路做哪种算术运算或逻辑运算;Fi为输出函数。
典型的4位ALU芯片74181外特性如下:

M的值用来区分算术运算(M=0)和逻辑运算(M=1),S3~S0的不同取值可实现不同的操作。74181为4位并行加法器,其4位进位是同时产生的,用4片74181芯片可组成16位ALU,其片内进位是快速的,但片间进位是逐片传递的,即组内并行(74181片内)、组间串行(74181片间),如图:
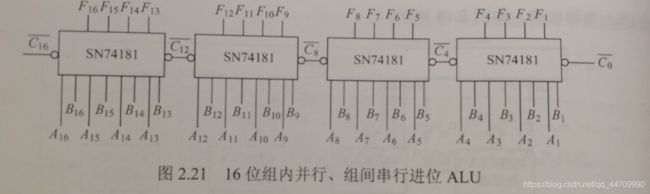
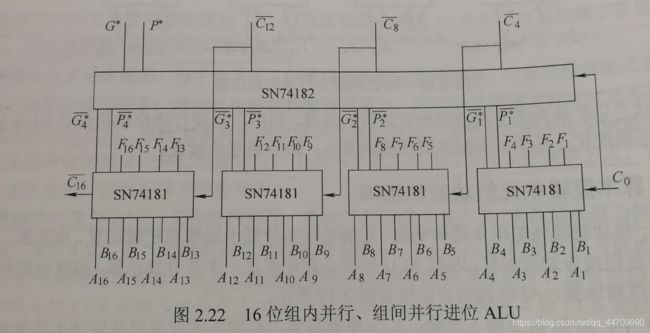
若把16位ALU中的每4位作为一组,即将74181芯片与74182芯片(先行进位芯片)配合,用类似位间快速进位的方法来实现16位ALU(4片ALU组成),则能得到16位的两级先行进位ALU,即组内并行(74181片内)、组间并行(74181片间),如图:
例题:在串行进位的并行加法器中,影响加法器运算速度的关键因素是()
A.门电路的级延迟 B.元器件速度 C.进位传递延迟 D.各位加法器速度的不同
答案:C;
例题:组成一个运算器需要多个部件,但下面的()不是组成运算器的部件
A.状态寄存器 B.数据总线 C.ALU D.地址寄存器
答案:D;数据总线供ALU与外界交互数据使用,地址寄存器不属于运算器,而属于存储器