计算机网络(7)网络安全
网络安全问题概述
计算机网络面临的安全性威胁
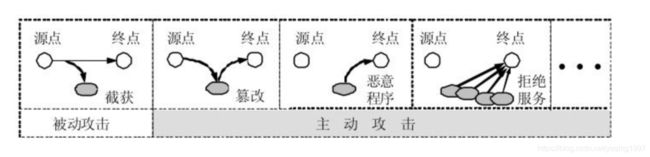
- 被动攻击
指攻击者从网络上窃听他人的通信内容。通常把这类攻击称为 截获 。
在被动攻击中,攻击者只是观察和分析某一个 协议数据单元 PDU而不干扰信息流。即使这些数据对攻击者来说是不易理解的,他也可通过观察PDU的协议控制信息部分,了解正在通信的协议实体的地址和身份,研究PDU的长度和传输的频度,以便了解所交换的数据的某种性质。这种被动攻击又称为 流量分析 (traffic analysis)。 - 主动攻击
(1)篡改 攻击者故意篡改网络上传送的报文。这里也包括彻底中断传送的报文,甚至把完全伪造的报文传送给接收方。这种攻击方式有时也称为“更改报文流”。
(2)恶意程序 恶意程序(rogue program)种类繁多,对网络安全威胁较大的主要有以下几种:
● 计算机病毒 (computer virus),一种会“传染”其他程序的程序,“传染”是通过修改其他程序来把自身或其变种复制进去完成的。
● 计算机蠕虫 (computer worm),一种通过网络的通信功能将自身从一个结点发送到另一个结点并自动启动运行的程序。
● 特洛伊木马 (Trojan horse),一种程序,它执行的功能并非所声称的功能而是某种恶意的功能。如一个编译程序除了执行编译任务以外,还把用户的源程序偷偷地复制下来,则这种编译程序就是一种特洛伊木马。计算机病毒有时也以特洛伊木马的形式出现。
● 逻辑炸弹 (logic bomb),一种当运行环境满足某种特定条件时执行其他特殊功能的程序。如一个编辑程序,平时运行得很好,但当系统时间为13日又为星期五时,它删去系统中所有的文件,这种程序就是一种逻辑炸弹。
(3)拒绝服务 指攻击者向因特网上的某个服务器不停地发送大量分组,使因特网或服务器无法提供正常服务。在2000年2月7日至9日美国几个著名网站遭黑客袭击,使这些网站的服务器一直处于“忙”的状态,因而无法向发出请求的客户提供服务。这种攻击被称为 拒绝服务 DoS (Denial of Service)。若从因特网上的成百上千的网站集中攻击一个网站,则称为 分布式拒绝服务 DDoS (Distributed Denial ofService)。
计算机网络安全的内容
- 保密性
- 安全协议的设计
- 访问控制
一般的数据加密模型
用户A向B发送 明文 X,但通过 加密算法 E运算后,就得出 密文 Y。

加密和解密用的密钥K(key),明文通过加密算法变成密文的一般表示方法。

在传送过程中可能出现密文的 截取者(或 攻击者 、入侵者 )。接收端利用解密算法D运算和解密密钥K,解出明文X。
解密算法是加密算法的逆运算。在进行解密运算时,如果不使用事先约定好的密钥就无法解出明文。

两类密码体制
对称密钥密码体制
所谓 对称密钥密码体制 ,即 加密密钥与解密密钥是相同的密码体制 。
数据加密标准 DES属于对称密钥密码体制。
DES是一种分组密码。在加密前,先对整个的明文进行分组。每一个组为64位长的二进制数据。然后对每一个64位二进制数据进行加密处理,产生一组64位密文数据。最后将各组密文串接起来,即得出整个的密文。使用的密钥为64位(实际密钥长度为56位,有8位用于奇偶校验)。
DES的保密性仅取决于对密钥的保密,而算法是公开的。
公钥密码体制
公钥密码体制(又称为公开密钥密码体制)的概念是由斯坦福(Stanford)大学的研究人员Diffie与Hellman于1976年提出的。公钥密码体制 使用不同的加密密钥与解密密钥 。
公钥密码体制的产生主要是因为两个方面的原因,一是由于对称密钥密码体制的 密钥分配 问题,二是由于对 数字签名 的需求。
在对称密钥密码体制中,加解密的双方使用的是相同的密钥。但怎样才能做到这一点呢?一种是事先约定,另一种是用信使来传送。在高度自动化的大型计算机网络中,用信使来传送密钥显然是不合适的。如果事先约定密钥,就会给密钥的管理和更换都带来了极大的不便。若使用高度安全的 密钥分配中心 KDC (KeyDistribution Center),也会使得网络成本增加。
RSA体制 ,它是一种基于数论中的大数分解问题的体制。
在公钥密码体制中,加密密钥 PK(public key,即 公钥 )是向公众公开的,而 解密密钥 SK(secret key,即 私钥 或 秘钥 )则是需要保密的。加密算法 E 和解密算法 D也都是公开的。
公钥密码体制的加密和解密过程有如下特点:
(1) 密钥对产生器产生出接收者B的一对密钥:加密密钥PKB和解密密钥SKB。发送者A所用的加密密钥PKB就是接收者B的公钥,它向公众公开。而B所用的解密密钥SKB就是接收者B的私钥,对其他人都保密。
(2) 发送者A用B的公钥PKB通过E运算对明文X加密,得出密文Y,发送给B。

B用自己的私钥SKB通过D运算进行解密,恢复出明文,即

(3) 虽在计算机上可以容易地产生成对的PKB和SKB。但从已知的PKB实际上不可能推导出SKB,即从PKB到SKB是“ 计算上不可能的 ”。
(4) 虽然公钥可用来加密,但却不能用来解密,即

(5) 先后对X进行D运算和E运算或进行E运算和D运算,结果都是一样的:


任何加密方法的安全性取决于密钥的长度,以及攻破密文所需的计算量 ,而不是简单地取决于加密的体制(公钥密码体制或传统加密体制)。
数字签名
数字签名必须保证能够实现以下三点功能:
(1) 接收者能够核实发送者对报文的签名。也就是说,接收者能够确信该报文的确是发送者发送的。其他人无法伪造对报文的签名。这就叫做 报文鉴别 。
(2) 接收者确信所收到的数据和发送者发送的完全一样而没有被篡改过。这就叫做 报文的完整性 。
(3) 发送者事后不能抵赖对报文的签名。这就叫做 不可否认 。
为了进行签名,A用其私钥SKA对报文X进行D运算。D运算本来叫做解密运算。还没有加密怎么就进行解密呢?这并没有关系。因为 D 运算只是得到了某种不可读的密文。在图中写上的是“D运算”而不写上“解密运算”就是为了避免产生这种误解。A把经过D运算得到的密文传送给B。B为了核实签名,用A的公钥进行E运算,还原出明文X。请注意,任何人用A的公钥PKA进行E运算后都可以得出A发送的明文。可见图中的D运算和E运算都不是为了解密和加密,而是为了进行签名和核实签名。

除A外没有别人持有A的私钥SKA,所以除A外没有别人能产生密文DSKA(X)。这样,B就相信报文X是A签名发送的。这就是报文鉴别的功能。
其他人如果篡改过报文,但并无法得到A的私钥 SKA来对X进行加密。B对篡改过的报文进行解密后,将会得出不可读的明文,就知道收到的报文被篡改过。这样就保证报文完整性的功能。
若A要抵赖曾发送报文给B,B可把X 及DSKA(X)出示给进行公证的第三者。第三者很容易用PKA去证实A确实发送X给B。这就是不可否认的功能。
这里的关键都是没有其他人能够持有A的私钥SKA。
但上述过程仅对报文进行了签名。对报文 X 本身却未保密。因为截获到密文DSKA(X)并知道发送者身份的任何人,通过查阅手册即可获得发送者的公钥PKA,因而能知道报文的内容。若采用图所示的方法,则可同时实现秘密通信和数字签名。图中SKA和SKB分别为A和B的私钥,而PKA和PKB分别为A和B的公钥。

鉴别
鉴别和加密并不相同。鉴别是要验证通信的对方的确是自己所要通信的对象,而不是其他的冒充者 。鉴别可分为两种。一种是报文鉴别,即所收到的报文的确是报文的发送者所发送的,而不是其他人伪造的或篡改的。另一种则是实体鉴别。实体可以是一个人,也可以是一个进程(客户或服务器)。
报文鉴别
当我们传送不需要加密的报文时,应当使接收者能用很简单的方法 鉴别报文的真伪。
报文摘要 MD (Message Digest)是进行报文鉴别的简单方法。
A把较长的报文X经过报文摘要算法运算后得出很短的报文摘要H。然后用自己的私钥对H进行D运算,即进行数字签名。得出已签名的报文摘要。这个已签名的报文摘要通常称为 报文鉴别码 MAC (Message Authentication Code)。现在把报文鉴别码MAC追加在报文X后面发送给B。B收到“报文X + 报文鉴别码MAC”后,首先把报文鉴别码MAC和报文X分离。然后再做两件事。
第一,用A的公钥对报文鉴别码MAC进行E 运算,还原出报文摘要H。
第二,对报文X进行报文摘要运算,看是否能够得出同样的报文摘要H。如一样,就能以极高的概率断定收到的报文是A产生的。否则就不是。
报文摘要的优点就是:仅对短得多的定长报文摘要H进行数字签名要比对整个长报文进行数字签名要简单得多,所耗费的计算资源也小得多,但对鉴别报文X 来说,效果是一样的。也就是说,报文X和报文鉴别码MAC合在一起,是不可伪造的,是 可检验 的和 不可否认 的。

报文摘要算法就是一种 散列函数 。这种散列函数也叫做 密码编码的检验和 ,因为它的性质和前面我们多次提到的检验和十分相似。我们知道,检验和是用来防止通信时偶然出现的差错,但报文摘要算法却是防止报文被人恶意篡改。
报文摘要算法是精心选择的一种 单向(one-way)函数 。
可以很容易地计算出一个长报文 X的报文摘要 H,可是要想从报文摘要 H 反过来找到原始的报文 X,则实际上是不可能的。此外,若想找到任意两个报文,使得它们具有相同的报文摘要,那么实际上也是不可能的。
上述的概念表明:若(M, H )是发送者产生的“报文和报文摘要对”,则攻击者不可能伪造出另一个报文,使得该报文与M具有同样的报文摘要H。发送者还可以对报文摘要H进行数字签名,使报文成为可检验的又不可否认的。
实体鉴别
实体鉴别和报文鉴别不同。报文鉴别是对每一个收到的报文都要鉴别报文的发送者,而实体鉴别是在系统接入的全部持续时间内对和自己通信的对方实体只需验证一次。
最简单的实体鉴别过程如图所示。在图中的A向远端的B发送有自己的身份A(例如,A的姓名)和口令的报文,并且使用双方约定好的共享对称密钥 KAB进行加密。图中A发送给B的报文的左上方的小锁表示报文已被加密,而加密用的对称密钥 KAB就标注在小锁的左边。B收到此报文后,用共享对称密钥KAB进行解密,因而鉴别了实体A的身份。

这种简单的鉴别方法具有明显的漏洞。例如,入侵者C可以从网络上截获A发给B的报文,C并不需要破译这个报文(因为这可能得花很长时间)而是直接把这个由A加密的报文发送给B,使B误认为C就是A;然后B就向伪装是A的C发送许多本来应当发给A的报文。这就叫做 重放攻击 (replay attack)。C甚至还可以截获A的IP地址,然后把A的IP地址冒充为自己的IP地址(这叫做IP欺骗),使B更加容易受骗。
为了对付重放攻击,可以使用 不重数 (nonce)。不重数就是一个 不重复使用的大随机数 ,即“一次一数”。在鉴别过程中不重数可以使B能够把重复的鉴别请求和新的鉴别请求区分开。

A首先用明文发送其身份A和一个不重数RA给B。接着,B响应A的查问,用共享的密钥KAB对RA加密后发回给A,同时也给出了自己的不重数RB。最后,A再响应B的查问,用共享的密钥KAB对RB加密后发回给B。这里很重要的一点是A和B对不同的会话必须使用不同的不重数集。由于不重数不能重复使用,所以C在进行重放攻击时无法重复使用所截获的不重数。
在使用公钥密码体制时,可以对不重数进行签名鉴别。例如在图中,B用其私钥对不重数RA进行签名后发回给A。A用B的公钥核实签名。如能得出自己原来发送的不重数RA,就核实了和自己通信的对方的确是B。同样,A也用自己的私钥对不重数 RB进行签名后发送给B。B用A的公钥核实签名,鉴别了A的身份。
公钥密码体制虽然不必在互相通信的用户之间秘密地分配共享密钥,但仍有受到攻击的可能。
C冒充是A,发送报文给B,说:“我是A”。
B选择一个不重数RB,发送给A,但被C截获了。
C用自己的私钥SKC冒充是A的私钥,对RB加密,并发送给B。
B向A发送报文,要求对方把解密用的公钥发送过来,但这报文也被C截获了。
C把自己的公钥PKC冒充是A的公钥发送给B。
B用收到的公钥PKC对收到的加密的RB进行解密,其结果当然正确。于是B相信通信的对方是A,接着就向A发送许多敏感数据,但都被C截获了。
B只要打电话询问一下A就能戳穿骗局,因为A根本没有和B进行通信。
" 中间人攻击 ”(man-in-the-middleattack)就更加具有欺骗性。

A想和B通信,向B发送“我是A”的报文,并给出了自己的身份。这个报文被“中间人”C截获,C把这个报文原封不动地转发给B。B选择一个不重数RB发送给A,但同样被C截获后也照样转发给A。
中间人C用自己的私钥SKC对RB加密后发回给B,使B误以为是A发来的。A收到RB后也用自己的私钥SKA对RB加密后发回给B,但中途被C截获并丢弃。B向A索取其公钥,这个报文被C截获后转发给A。
C把自己的公钥 PKC冒充是A的公钥发送给B,而C也截获到A发送给B的公钥PKA。
B用收到的公钥PKC(以为是A的)对数据DATA加密,并发送给A。C截获后用自己的私钥SKC解密,复制一份留下,然后再用A的公钥PKA对数据DATA加密后发送给A。A收到数据后,用自己的私钥SKA解密,以为和B进行了保密通信。其实,B发送给A的加密数据已被中间人C截获并解密了一份。但A和B却都不知道。
密钥分配
由于密码算法是公开的,网络的安全性就完全基于密钥的安全保护上。
密钥分配(或 密钥分发 )是密钥管理中最大的问题。密钥必须通过最安全的通路进行分配。
可以派非常可靠的信使携带密钥分配给互相通信的各用户。这种方法称为 网外分配方式 。
但随着用户的增多和网络流量的增大,密钥更换频繁(密钥必须定期更换才能做到可靠),派信使的办法已不再适用,而应采用网内分配方式 ,即对密钥自动分配。
对称密钥的分配
目前常用的密钥分配方式是设立 密钥分配中心 KDC (Key Distribution Center)。KDC是大家都信任的机构,其任务就是给需要进行秘密通信的用户临时分配一个会话密钥(仅使用一次)。
用户A和B都是KDC的登记用户。A和B在KDC登记时就已经在KDC的服务器上安装了各自和KDC进行通信的 主密钥(master key)KA和KB。

❶ 用户A向密钥分配中心KDC发送时用明文,说明想和用户B通信。在明文中给出A和B在KDC登记的身份。
❷ KDC用随机数产生“一次一密”的会话密钥 KAB供A和B的这次会话使用,然后向A发送回答报文。这个回答报文用A的密钥 KA加密。这个报文中包含有这次会话使用的密钥KAB和请A转给B的一个 票据 (ticket),它包含A和B在KDC登记的身份,以及这次会话将要使用的密钥KAB。这个票据用B的密钥KB加密,因此A无法知道此票据的内容,因为A没有B的密钥KB。当然A也不需要知道此票据的内容。
❸ 当B收到A转来的票据并使用自己的密钥KB解密后,就知道A要和他通信,同时也知道KDC为这次和A通信所分配的会话密钥KAB。
此后,A和B就可使用会话密钥KAB进行这次通信了。
KDC还可在报文中加入时间戳,以防止报文的截取者利用以前已记录下的报文进行重放攻击。会话密钥 KAB是一次性的,因此保密性较高。而KDC分配给用户的密钥KA和KB,都应定期更换,以减少攻击者破译密钥的机会。
最出名的密钥分配协议是Kerberos V5.
Kerberos既是鉴别协议,同时也是KDC,它已经变得很普及。Kerberos使用比DES更加安全的 先进的加密标准 AES (Advanced EncryptionStandard)进行加密。

Kerberos使用两个服务器:鉴别服务器 AS (Authentication Server)、票据授予服务器 TGS (Ticket-Granting Server)。Kerberos只用于客户与服务器之间的鉴别,而不用于人对人的鉴别。
在图中,A是请求服务的客户,而B是被请求的服务器。A通过Kerberos向B提出请求服务。
Kerberos需要通过以下六个步骤鉴别的确是A(而不是其他别人冒充A)向B请求服务后,才向A和B分配会话使用的密钥。
❶ A用明文(包括登记的身份)向鉴别服务器AS表明自己的身份。AS就是KDC,它掌握各实体登记的身份和相应的口令。AS对A的身份进行验证。只有验证结果正确,才允许A和票据授予服务器TGS进行联系。
❷ AS向A发送用A的对称密钥KA加密的报文,这个报文包含A和TGS通信的会话密钥 KS以及AS要发送给TGS的票据(这个票据是用TGS的对称密钥 KTG加密的)。A并不保存密钥 KA,但当这个报文到达A时,A就键入其口令。若口令正确,则该口令和适当的算法一起就能生成出密钥 KA。这个口令随即被销毁。密钥KA用来对AS发送过来的报文进行解密。这样就提取出会话密钥 KS(这是A和TGS通信要使用的)以及要转发给TGS的票据(这是用密钥KTG加密的)。
❸ A向TGS发送三个项目:
● 转发鉴别服务器AS发来的票据。
● 服务器B的名字。这表明A请求B的服务。请注意,现在A向TGS证明自己的身份并非通过键入口令(因为入侵者能够从网上截获明文口令),而是通过转发AS发出的票据(只有A才能提取出)。票据是加密的,入侵者伪造不了。
● 用KS加密的时间戳T。它用来防止入侵者的重放攻击。
❹ TGS发送两个票据,每一个都包含A和B通信的会话密钥KAB。给A的票据用KS加密;给B的票据用B的密钥 KB加密。请注意,现在入侵者不能提取 KAB,因为不知道KA和KB。入侵者也不能重放步骤❸,因为入侵者不能把时间戳更换为一个新的(因为不知道KS)。如果入侵者在时间戳到期之前,非常迅速地发送步骤❸的报文,那么对TGS发送过来的两个票据仍然不能解密。
❺ A向B转发TGS发来的票据,同时发送用KAB加密的时间戳T。
❻ B把时间戳T加1来证实收到了票据。B向A发送的报文用密钥KAB加密。
以后,A和B就使用TGS给出的会话密钥KAB进行通信。
公钥的分配
在公钥密码体制中,如果每个用户都具有其他用户的公钥,就可实现安全通信。看来好像可以随意公布用户的公钥。其实不然。
设想用户A要欺骗用户B。A可以向B发送一份伪造是C发送的报文。A用自己的秘密密钥进行数字签名,并附上A自己的公钥,谎称这公钥是C的。B如何知道这个公钥不是C的呢?显然,这需要有一个值得信赖的机构来将公钥与其对应的实体(人或机器)进行 绑定 (binding)。这样的机构就叫作 认证中心 CA (Certification Authority),它一般由政府出资建立。每个实体都有CA发来的 证书 (certificate),里面有公钥及其拥有者的标识信息(人名或IP地址)。此证书被CA进行了数字签名。任何用户都可从可信的地方(如代表政府的报纸)获得认证中心CA的公钥,此公钥用来验证某个公钥是否为某个实体所拥有(通过向CA查询)。
因特网使用的安全协议
网络层安全协议( IPsec协议)
IPsec就是“IP安全(Security)协议”的缩写。
在IPsec协议族中有两个最主要的协议:鉴别首部AH (Authentication Header)协议和 封装安全有效载荷ESP (Encapsulation Security Payload)协议。AH协议提供源点鉴别和数据完整性,但不能保密。而ESP协议比AH协议复杂得多,它提供源点鉴别、数据完整性和保密。IPsec支持IPv4和IPv6。
AH协议的功能都已包含在ESP协议中,因此使用ESP协议就可以不使用AH协议。
使用IPsec协议的IP数据报称为IPsec数据报,它可以在两个主机之间、两个路由器之间或在一个主机和一个路由器之间发送。
在发送IPsec数据报之前,在源实体和目的实体之间必须创建一条网络层的逻辑连接,即 安全关联SA (SecurityAssociation)。这样,IPsec就把传统的因特网无连接的网络层变为具有逻辑连接的一个层 。安全关联是从源点到终点的 单向连接 ,它能够提供安全服务。如要进行双向的安全通信,则需要建立两个方向的安全关联。假定某公司有一个公司总部和在外地的一个分公司。总部需要和这个分公司以及分公司中的n个员工进行安全的双向通信。那么,在这种情况下,一共需要创建(2 + 2n)条安全关联SA。在这些安全关联SA上传送的就是安全的IPsec数据报。下图是一条从路由器R1到R2的安全关联SA的示意图。IPsec数据报就是在安全关联SA连接上传送的。

当路由器R1要通过SA发送IPsec数据报时,路由器R1必须维护这条安全关联SA的状态信息,以便知道如何把IP数据报进行加密和鉴别。
同理,路由器R2也要维护关于一条SA的状态信息,以便当IPsec数据报通过SA到达路由器R2时进行解密和鉴别。

IPsec数据报有以下两种不同的工作方式。
第一种工作方式是 运输方式 (transport mode)。运输方式是在整个运输层报文段的后面和前面分别添加一些控制字段,构成IPsec数据报。这种方式把整个运输层报文段都保护起来,因此很适合于主机到主机之间的安全传送,但这需要使用IPsec的主机都运行IPsec协议。
第二种工作方式是 隧道方式 (tunnel mode)。隧道方式是在一个IP数据报的后面和前面分别添加一些控制字段,构成IPsec数据报。显然,这需要在IPsec数据报所经过的所有路由器都运行IPsec协议。IPSec的隧道方式常用来实现 虚拟专用网 VPN。
把运输层报文段(或IP数据报)封装成IPsec数据报的过程。具体的步骤如下。
(1)在运输层报文段(或IP数据报)后面添加ESP尾部。ESP尾部有三个字段。第一个字段是填充字段,里面填充的是全0。第二个字段是填充长度(8位),指出填充字段的字节数。为什么要再添加一些0呢?这是因为我们通常都是以具有一定字节长度的数据块为单位进行数据加密的。当运输层报文段(或IP数据报)的长度不是加密规定的数据块长度的整数倍时,就必须用0进行填充。每个0占据的长度是一个字节。不难看出,8位填充长度的最大值是255。但实际上,填充很少会用到这个最大值。ESP尾部的第三个字段是“下一个首部”(8位),其数值指明,在接收端,有效载荷应当上交到什么地方。
(2) 按照安全关联SA指明的加密算法和密钥,对“运输层报文段(或IP数据报)+ESP尾部”一起进行加密。
(3)在已加密的这部分的前面,添加ESP首部。ESP首部有两个字段,都是32位。第一个字段存放安全参数索引SPI。通过同一个SA的所有IPsec数据报都使用同样的SPI值。第二个字段是序号。这个序号属于鉴别的部分,因此可用来防止重放攻击。请注意,当分组重传时序号也不重复。
(4) 按照SA指明的算法和密钥,对“ESP首部 + 运输层报文段(或IP数据报)+ESP尾部”生成报文鉴别码MAC。
(5) 把MAC添加在ESP尾部的后面。
(6) 生成新的IP首部(通常就是20字节长,其协议字段的值是50),这就是下图中的“IPsec的首部”。这个首部就是标准的IP数据报的首部。
ESP尾部中的“下一个首部”字段是很重要的,因为若没有这个字段,在收到IPsec数据报并进行鉴别和解密后,就无法知道应将有效载荷送交到何处。

图(a)是运输方式。当接收端收到IPsec数据报后,根据IPsec首部的协议字段(50),把首部后面的所有字段都上交给ESP进行鉴别和解密。再根据解密后得到的ESP尾部中“下一个首部”的值(6),把有效载荷上交给TCP。
图(b)是隧道方式。当接收端收到IPsec数据报后,根据IPsec首部的协议字段(50),把首部后面的所有字段都上交给ESP进行鉴别和解密。再根据解密后得到的ESP尾部中“下一个首部”的值(4),把有效载荷上交给IP。IP找到IP首部中的协议字段,其数值是6,就把IP首部后面的字段(即TCP报文段)都交给TCP。
一个发送IPsec数据报的实体可能要用到很多条安全关联SA。那么这些SA是存放在什么地方呢?这就是IPsec的一个重要构件,叫做 安全关联数据库 SAD (Security Association Database)。当一个主机要发送IPsec数据报时,就要在SAD中查找相应的SA,以便获得必要的信息来对该IPsec数据报实施安全保护。同样,当一个主机要接收IPsec数据报时,也要在SAD中查找相应的SA,以便获得信息来检查该分组的安全性。
一个主机要发送的数据报并非都必须进行加密。很多信息使用普通的数据报用明文发送就可以了。因此,除了安全关联数据库SAD,我们还需要另一个数据库,这就是 安全策略数据库 SPD (Security Policy Database)。SPD指明什么样的数据报需要进行IPsec处理。这取决于源地址、源端口、目的地址、目的端口,以及协议的类型等。因此,当一个IP数据报到达时,SPD指出应当做什么(使用IPsec还是不使用),而SAD则指出,如果需要使用IPsec,那么应当怎样做(使用哪一个SA)。
对于大型的、地理位置分散的系统,为了创建SAD,我们需要使用自动生成的机制,这就是使用 因特网密钥交换 IKE(Internet Key Exchange)协议。IKE的用途就是为IPsec创建安全关联SA。
传输层安全协议 (安全套接字层SSL (Secure Socket Layer) 运输层安全TLS (Transport Layer Security))
安全套接字层SSL (Secure Socket Layer)
SSL作用在端系统应用层的HTTP和运输层之间,在TCP之上建立起一个安全通道,为通过TCP传输的应用层数据提供安全保障。
SSL提供的安全服务可归纳为以下三种:
(1) SSL服务器鉴别,允许用户证实服务器的身份。支持SSL的客户端通过验证来自服务器的证书,来鉴别服务器的真实身份并获得服务器的公钥。
(2) SSL客户鉴别,SSL的可选安全服务,允许服务器证实客户的身份。
(3) 加密的SSL会话,对客户和服务器间发送的所有报文进行加密,并检测报文是否被篡改。

以万维网应用为例来说明SSL的工作过程。
销售商的万维网服务器B使用SSL为顾客A提供安全的在线购物。为此,万维网服务器使用SSL的默认服务端口443来取代普通万维网服务的80端口,并且该安全网页URL中的协议标识用https替代http。当顾客点击该网站链接建立TCP连接后,先进行浏览器和服务器之间的握手协议,完成加密算法的协商和会话密钥的传递,然后进行安全数据传输。其简要过程如下(实际步骤要复杂得多):
(1) 协商加密算法 。浏览器A向服务器B发送浏览器的SSL版本号和一些可选的加密算法,B从中选定自己所支持的算法,并告知A。
(2) 服务器鉴别 。服务器B向浏览器A发送一个包含其RSA公钥的数字证书,A使用该证书的认证机构CA的公开发布的RSA公钥对该证书进行验证。
(3) 会话密钥计算 。由浏览器A随机产生一个秘密数,用服务器B的RSA公钥进行加密后发送给B。双方根据协商的算法产生一个共享的对称会话密钥。
(4) 安全数据传输 。双方用会话密钥加密和解密它们之间传送的数据并验证其完整性。

运输层安全TLS (Transport Layer Security)
在SSL 3.0的基础上设计了TLS协议,为所有基于TCP的网络应用提供安全数据传输服务。
应用层安全协议 (有关电子邮件的安全协议)
为电子邮件提供安全服务的协议PGP
PGP (Pretty Good Privacy)是Zimmermann于1995年开发出的。它是一个完整的电子邮件安全软件包,包括加密、鉴别、电子签名和压缩等技术。PGP并没有使用什么新的概念,它只是把现有的一些加密算法(如RSA公钥加密算法或MD5报文摘要算法)综合在一起而已。
PGP的工作原理并不复杂。它提供电子邮件的安全性、发送方鉴别和报文完整性。
假定A向B发送电子邮件明文 X,现在用PGP进行加密。A有三个密钥:自己的私钥、B的公钥和自己生成的一次性密钥。B有两个密钥:自己的私钥和A的公钥。
A需要做以下几件事:

(1) 对明文邮件X进行MD5报文摘要运算,得出报文摘要H。用A的私钥对H进行数字签名,得出报文鉴别码MAC,把它拼接在明文X后面,得到报文(X + MAC)。
(2) 使用A自己生成的一次性密钥对报文(X + MAC)进行加密。
(3) 用B的公钥对A生成的一次性密钥进行加密。
(4) 把加了密的一次性密钥和加了密的报文(X + MAC)发送给B。
在图中有三个“加密”是不同的作用。第一次加密是用A的私钥对报文摘要 H 进行加密。第二次加密是用A的一次性密钥对报文(X + MAC)是加密,而第三次性加密是用B的公钥对A的一次性密钥加密。
B收到加密的报文后要做以下几件事:

(1) 把被加密的一次性密钥和被加密的报文(X + MAC)分离开。
(2) 用B自己的私钥解出A的一次性密钥。
(3) 用解出的一次性密钥对报文(X + MAC)进行解密,然后分离出明文X和MAC。
(4) 用A的公钥对MAC进行签名核实,得出报文摘要H。
(5) 对X进行报文摘要运算,得出报文摘要,看是否和H一样。如一样,则电子邮件的发送方鉴别就通过了,报文的完整性也得到肯定。
系统安全:防火墙与入侵检测
防火墙
防火墙 (firewall)作为一种访问控制技术,通过严格控制进出网络边界的分组,禁止任何不必要的通信,从而减少潜在入侵的发生,尽可能降低这类安全威胁所带来的安全风险。由于防火墙不可能阻止所有入侵行为,作为系统防御的第二道防线, 入侵检测系统 (Intrusion Detection System)通过对进入网络的分组进行深度分析与检测发现疑似入侵行为的网络活动,并进行报警以便进一步采取相应措施。
防火墙 是一种特殊编程的路由器,安装在一个网点和网络的其余部分之间,目的是实施访问控制策略。这个访问控制策略是由使用防火墙的单位自行制定的。这种安全策略应当最适合本单位的需要。下图指出防火墙位于因特网和内部网络之间。因特网这边是防火墙的外面,而内部网络这边是防火墙的里面。一般都把防火墙里面的网络称为“ 可信的网络 ”(trusted network),而把防火墙外面的网络称为“ 不可信的网络 ”(untrusted network)。

防火墙技术一般分为两类,即:
(1) 分组过滤路由器 是一种具有分组过滤功能的路由器,它根据过滤规则对进出内部网络的分组执行转发或者丢弃(即过滤)。过滤规则基于分组的网络层或运输层首部的信息,例如:源/目的IP地址、源/目的端口、协议类型(TCP或UDP),等等。我们知道,TCP的端口号指出了在TCP上面的应用层服务。
例如,端口号23是TELNET,端口号119是USENET新闻网,等等。所以,如果在分组过滤器中将所有目的端口号为23的 入分组 (incoming packet)都进行阻拦,那么所有外单位用户就不能使用TELNET登录到本单位的主机上。同理,如果某公司不愿意其雇员在上班时花费大量时间去看因特网的USENET新闻,就可将目的端口号为119的 出分组 (outgoing packet)阻拦住,使其无法发送到因特网。
分组过滤可以是无状态的,即独立地处理每一个分组。也可以是有状态的,即要跟踪每个连接或会话的通信状态,并根据这些状态信息来决定是否转发分组。例如,一个目的地是某个客户动态分配端口(该端口无法事先包含在规则中)的进入分组被允许通过的唯一条件是:该分组是该端口发出合法请求的一个响应。这样的规则只能通过有状态的检查来实现。
分组过滤路由器的优点是简单高效,且对于用户是透明的,但不能对高层数据进行过滤。例如,不能禁止某个用户对某个特定应用进行某个特定的操作,不能支持应用层用户鉴别等。这些功能需要使用应用网关技术来实现。
(2) 应用网关也称为 代理服务器 (proxy server),它在应用层通信中扮演报文中继的角色。一种网络应用需要一个应用网关,万维网缓存就是一种万维网应用的代理服务器。在应用网关中,可以实现基于应用层数据的过滤和高层用户鉴别。
所有进出网络的应用程序报文都必须通过应用网关。当某应用客户进程向服务器发送一份请求报文时,先发送给应用网关,应用网关在应用层打开该报文,查看该请求是否合法(可根据应用层用户标识ID或其他应用层信息)。如果请求合法,应用网关以客户进程的身份将请求报文转发给原始服务器。如果不合法,报文则被丢弃。例如,一个邮件网关在检查每一个邮件时,根据邮件地址,或邮件的其他首部,甚至是报文的内容(如,有没有某些像“导弹”“核弹头”等关键词)来确定该邮件能否通过防火墙。
应用网关也有一些缺点。首先,每种应用都需要一个不同的应用网关(可以运行在同一台主机上)。其次,在应用层转发和处理报文,处理负担较重。另外,对应用程序不透明,需要在应用程序客户端配置应用网关地址。
通常可将这两种技术结合使用,上图所画的防火墙就同时具有这两种技术。它包括两个分组过滤路由器和一个应用网关,它们通过两个局域网连接在一起。
入侵检测系统
入侵检测系统 IDS(Intrusion Detection System)对进入网络的分组执行深度分组检查,当观察到可疑分组时,向网络管理员发出告警或执行阻断操作(由于IDS的“误报”率通常较高,多数情况不执行自动阻断)。
IDS能用于检测多种网络攻击,包括网络映射、端口扫描、DoS攻击、蠕虫和病毒、系统漏洞攻击等。
入侵检测方法一般可以分为 基于特征的入侵检测 和 基于异常的入侵检测 两种。
基于特征的IDS维护一个所有已知攻击标志性特征的数据库。每个特征是一个与某种入侵活动相关联的规则集,这些规则可能基于单个分组的首部字段值或数据中特定比特串,或者与一系列分组有关。当发现有与某种攻击特征匹配的分组或分组序列时,则认为可能检测到某种入侵行为。这些特征和规则通常由网络安全专家生成,机构的网络管理员定制并将其加入到数据库中。
基于特征的IDS只能检测已知攻击,对于未知攻击则束手无策。
基于异常的IDS通过观察正常运行的网络流量,学习正常流量的统计特性和规律,当检测到网络中流量某种统计规律不符合正常情况时,则认为可能发生了入侵行为。例如,当攻击者在对内网主机进行ping搜索时,或导致ICMP ping报文突然大量增加,与正常的统计规律有明显不同。但区分正常流和统计异常流是一个非常困难的事情。至今为止,大多数部署的IDS主要是基于特征的,尽管某些IDS包括了某些基于异常的特性。