利用Tensorboard、Hook、CAM、LIME简单记录训练过程中的数据或者图片
几个常见的模型记录插件介绍
- Tensorboard
-
- 记录数据
-
- 记录简单数据的方法
- 进行模型监控
- 记录图片
-
- 记录简单图片
- 模型的卷积核及特征图可视化
-
- 卷积核可视化
- 特征图可视化
- 模型可视化
- Hook
-
- 记录运算过程中间变量
- 记录特征图
- CAM
-
- Grad-CAM
- LIME
Tensorboard
记录数据
记录简单数据的方法
1.add_scalar() 记录标量
2.add_scalars() 记录多个值
在谷歌Colaboratory里跑以下代码
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
import numpy as np
np.random.seed(47) # 固定随机数
# ----------------------------------- 0 SummaryWriter -----------------------------------
# flag = 0
flag = 1
if flag:
max_epoch = 100
writer = SummaryWriter( comment='test_comment', filename_suffix="test_suffix")
for x in range(max_epoch):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.add_scalars('data/scalar_group', {
"xsinx": x * np.sin(x), "xcosx": x * np.cos(x)}, x)
writer.close()
接着运行
# Load the TensorBoard notebook extension
%load_ext tensorboard
%tensorboard --logdir='./runs'
就能看到以下画面
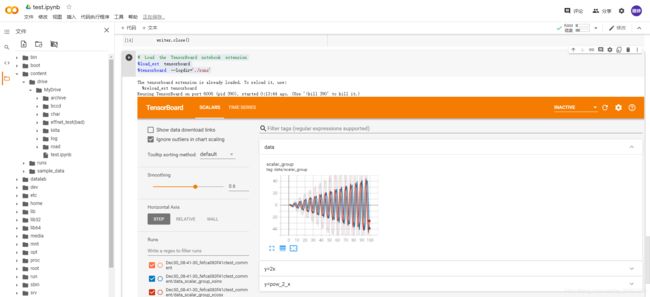
进行模型监控
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
iter_count += 1
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
# 记录数据,保存于event file
writer.add_scalars("Loss", {
"Train": loss.item()}, iter_count)
writer.add_scalars("Accuracy", {
"Train": correct / total}, iter_count)
# 每个epoch,记录梯度,权值
for name, param in net.named_parameters():
writer.add_histogram(name + '_grad', param.grad, epoch)
writer.add_histogram(name + '_data', param, epoch)
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss.item())
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct / total))
# 记录数据,保存于event file
writer.add_scalars("Loss", {
"Valid": np.mean(valid_curve)}, iter_count)
writer.add_scalars("Accuracy", {
"Valid": correct_val / total_val}, iter_count)
记录图片
记录简单图片
1.add_image()
import os
import torch
import time
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.utils as vutils
np.random.seed(47) # 固定随机数
# ----------------------------------- 3 image -----------------------------------
# flag = 0
flag = 1
if flag:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# img 1 random
fake_img = torch.randn(3, 512, 512)
writer.add_image("fake_img", fake_img, 1)
time.sleep(1)
# img 2 ones
fake_img = torch.ones(3, 512, 512)
time.sleep(1)
writer.add_image("fake_img", fake_img, 2)
# img 3 1.1
fake_img = torch.ones(3, 512, 512) * 1.1
time.sleep(1)
writer.add_image("fake_img", fake_img, 3)
# img 4 HW
fake_img = torch.rand(512, 512)
writer.add_image("fake_img", fake_img, 4, dataformats="HW")
# img 5 HWC
fake_img = torch.rand(512, 512, 3)
writer.add_image("fake_img", fake_img, 5, dataformats="HWC")
writer.close()
跑完的结果如下

2.torchvision.utils.make_ grid
制作网格图像
例子
data_batch, label_batch = next(iter(train_loader))
img_grid = vutils.make_grid(data_batch, nrow=4, normalize=False, scale_each=False)
writer.add_image("input img", img_grid, 0)
得到以下的显示

模型的卷积核及特征图可视化
如果不借助tensorboard,可以自己用代码写,具体教程如下https://cloud.tencent.com/developer/article/1674254
这里的可视化包含
1.卷积核可视化
2.特征图可视化
3.模型可视化
卷积核可视化
import torch.nn as nn
from PIL import Image
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
import torchvision.utils as vutils
import torchvision.models as models
import numpy as np
import torch
np.random.seed(47) # 固定随机数
# ----------------------------------- kernel visualization -----------------------------------
# flag = 0
flag = 1
if flag:
# 这句话很重要!不计算梯度,否则会报错
with torch.no_grad():
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
alexnet = models.alexnet(pretrained=True)
kernel_num = -1
vis_max = 1
for sub_module in alexnet.modules():
if isinstance(sub_module, nn.Conv2d):
kernel_num += 1
if kernel_num > vis_max:
break
kernels = sub_module.weight
c_out, c_int, k_w, k_h = tuple(kernels.shape)
for o_idx in range(c_out):
kernel_idx = kernels[o_idx, :, :, :].unsqueeze(1) # make_grid需要 BCHW,这里拓展C维度
kernel_grid = vutils.make_grid(kernel_idx, normalize=True, scale_each=True, nrow=c_int)
writer.add_image('{}_Convlayer_split_in_channel'.format(kernel_num), kernel_grid, global_step=o_idx)
kernel_all = kernels.view(-1, 3, k_h, k_w) # 3, h, w
kernel_grid = vutils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=8) # c, h, w
writer.add_image('{}_all'.format(kernel_num), kernel_grid, global_step=322)
print("{}_convlayer shape:{}".format(kernel_num, tuple(kernels.shape)))
writer.close()
效果

特征图可视化
代码
import cv2
with torch.no_grad():
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 数据
path_img = "/content/gdrive/My Drive/road/data/IMG/center_2020_01_13_12_20_50_070.jpg" # your path to image
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
norm_transform = transforms.Normalize(normMean, normStd)
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
norm_transform
])
img_pil = Image.open(path_img).convert('RGB')
if img_transforms is not None:
img_tensor = img_transforms(img_pil)
img_tensor.unsqueeze_(0) # chw --> bchw
# 模型
alexnet = models.alexnet(pretrained=True)
# forward
convlayer1 = alexnet.features[0]
fmap_1 = convlayer1(img_tensor)
# 预处理
fmap_1.transpose_(0, 1) # bchw=(1, 64, 55, 55) --> (64, 1, 55, 55)
fmap_1_grid = vutils.make_grid(fmap_1, normalize=True, scale_each=True, nrow=8)
writer.add_image('feature map in conv1', fmap_1_grid, global_step=322)
writer.close()
效果图
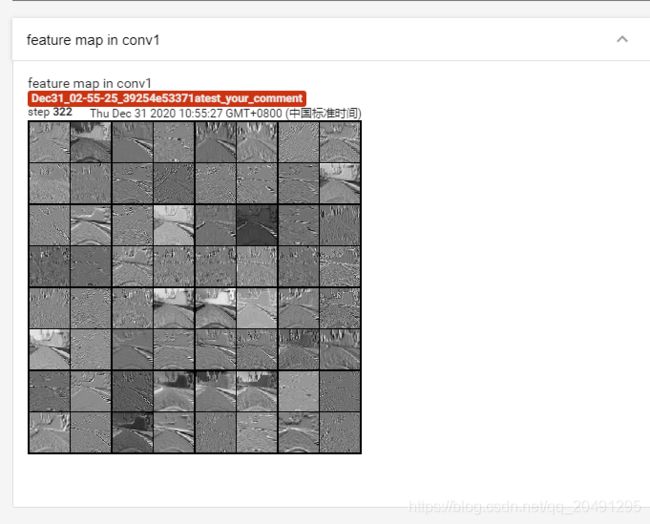
模型可视化
代码
from torchsummary import summary
with torch.no_grad():
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 模型
fake_img = torch.randn(1, 3, 32, 32)
vgg = VGG_16()
writer.add_graph(vgg, fake_img)
writer.close()
# 这里可以选 “cuda”or“cpu”
print(summary(vgg, (3, 512, 512), device="cpu"))
效果

Hook
记录运算过程中间变量
主要功能介绍
1.torch.Tensor.register_ hook(hook)
注册一个反向传播hook函数。
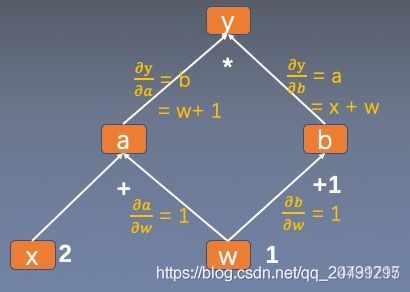
在反向传播结束后,非叶子节点a和b的梯度会被释放掉。现使用hook函数捕获其梯度。
使用例子
import torch
import torch.nn as nn
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
a_grad = list()
def grad_hook(grad):
a_grad.append(grad)
handle = a.register_hook(grad_hook)
y.backward()
# 查看梯度
print("gradient:", w.grad, x.grad, a.grad, b.grad, y.grad)
print("a_grad[0]: ", a_grad[0])
handle.remove()
2.torch.nn.Module.register_forward _hook
注册module的前向传播hook函数
例子

class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 2, 3)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
return x
def forward_hook(module, data_input, data_output):
fmap_block.append(data_output)
input_block.append(data_input)
def forward_pre_hook(module, data_input):
print("forward_pre_hook input:{}".format(data_input))
def backward_hook(module, grad_input, grad_output):
print("backward hook input:{}".format(grad_input))
print("backward hook output:{}".format(grad_output))
# 初始化网络
net = Net()
net.conv1.weight[0].detach().fill_(1)
net.conv1.weight[1].detach().fill_(2)
net.conv1.bias.data.detach().zero_()
# 注册hook
fmap_block = list()
input_block = list()
net.conv1.register_forward_hook(forward_hook)
#net.conv1.register_forward_pre_hook(forward_pre_hook)
#net.conv1.register_backward_hook(backward_hook)
# inference
fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W
output = net(fake_img)
"""
loss_fnc = nn.L1Loss()
target = torch.randn_like(output)
loss = loss_fnc(target, output)
loss.backward()
"""
# 观察
print("output shape: {}\noutput value: {}\n".format(output.shape, output))
print("feature maps shape: {}\noutput value: {}\n".format(fmap_block[0].shape, fmap_block[0]))
print("input shape: {}\ninput value: {}".format(input_block[0][0].shape, input_block[0]))
3.torch.nn.Module.register forward pre_ hook
功能:注册module前向传播前的hook函数
上例子注释的部分
记录特征图
import torch.nn as nn
import numpy as np
from PIL import Image
import torchvision.transforms as transforms
import torchvision.utils as vutils
from torch.utils.tensorboard import SummaryWriter
import torchvision.models as models
np.random.seed(47) # 固定随机数
# ----------------------------------- feature map visualization -----------------------------------
with torch.no_grad():
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 数据
path_img = "/content/gdrive/My Drive/road/data/IMG/center_2020_01_13_12_20_50_070.jpg" # your path to image
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
norm_transform = transforms.Normalize(normMean, normStd)
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
norm_transform
])
img_pil = Image.open(path_img).convert('RGB')
if img_transforms is not None:
img_tensor = img_transforms(img_pil)
img_tensor.unsqueeze_(0) # chw --> bchw
# 模型
vgg_16 = VGG_16()
# 注册hook
fmap_dict = dict()
for name, sub_module in vgg_16.named_modules():
if isinstance(sub_module, nn.Conv2d):
key_name = str(sub_module.weight.shape)
fmap_dict.setdefault(key_name, list())
n1, n2 = name.split(".")
def hook_func(m, i, o):
key_name = str(m.weight.shape)
fmap_dict[key_name].append(o)
vgg_16._modules[n1]._modules[n2].register_forward_hook(hook_func)
# forward
output = vgg_16(img_tensor)
# add image
for layer_name, fmap_list in fmap_dict.items():
fmap = fmap_list[0]
fmap.transpose_(0, 1)
nrow = int(np.sqrt(fmap.shape[0]))
fmap_grid = vutils.make_grid(fmap, normalize=True, scale_each=True, nrow=nrow)
writer.add_image('feature map in {}'.format(layer_name), fmap_grid, global_step=322)
效果
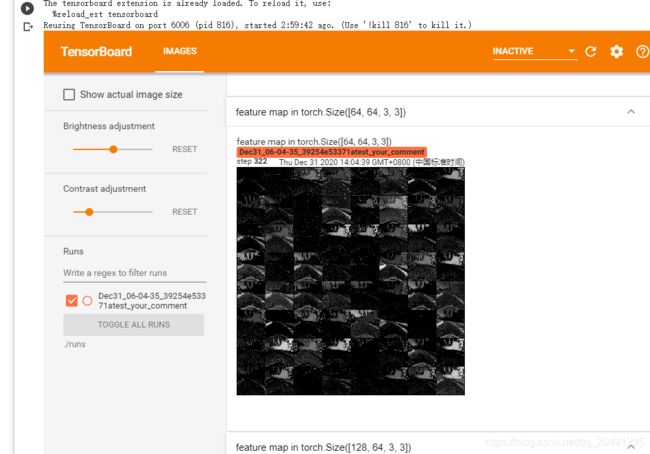
CAM
先说说cam的功能,他可以得到一个类似于热力图的东西,用于定位图像中与类别相关的区域,如下图所示。

再具体说CAM做了什么,我们知道在分类网络里,CNN包含2部分,一个是卷积,负责提取图像特征,另一部分是GAP+分类,传统做法是接入全连接层。
这里解释一下GAP是什么:
Global Average Pooling,GAP直接从 feature map 的通道信息下手,比如我们现在的分类有N种,那么最后一层的卷积输出的 feature map 就只有N个通道,然后对这个 feature map 进行全局池化操作,获得长度为N的向量,这就相当于直接赋予了每个通道类别的意义。

示例代码:
from keras.layers import GlobalAveragePooling2D,Dense
from keras.applications import VGG16
from keras.models import Model
def build_model():
base_model = VGG16(weights="imagenet",include_top=False)
#在分类器之前使用
gap = GlobalAveragePooling2D()(base_model)
predictions = Dense(20,activation="softmax")(gap)
model = Model(inputs=base_model.input,outputs=predictions)
return model
CNN网络最后一层可以认为高度抽象类别特征。所以CAM基于最后一层特征进行可视化。
CAM将CNN分类器替换为GAP+类别数目大小的全连接层后重新训练。假设最后一层有n张特征图,记为A1…An。分类层中一个神经元对应一类,一个神经元有n个权重。如下图所示。对某一类别c,生成方式为


生成的热力图是和最后一层特征图大小一致。需要进行上采样得到与原图大小一致的CAM
Grad-CAM
CAM的缺点很明显,需要重新训练。Grad-CAM克服上述取点。
Grad-CAM的整体结构如下图所示:
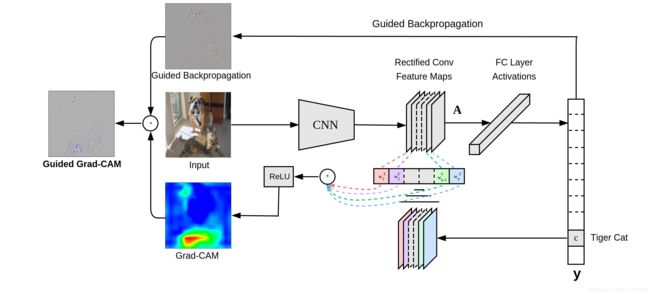
Grad-CAM的主要改动在于求权重w过程,用梯度的全局平均计算权值。
详细推导过程可以看论文https://ramprs.github.io/static/docs/IJCV_Grad-CAM.pdf
pytorch实现代码:https://github.com/jacobgil/pytorch-grad-cam
LIME
通过将图像分割成“超像素”并关闭或打开超像素来创建图像的变化。超像素是具有相似颜色的互连像素,可以通过将每个像素替换为用户定义的颜色(例如灰色)来关闭。用户还可以指定在每个排列中关闭超像素的概率。
代码可以参考:Pytorch例子演示及LIME使用例子