Java多线程模拟搜索引擎建立倒排索引
倒排索引
是搜索引擎的核心技术,对海量的文本(文档、网页),搜索引擎需要建立搜索索引。
倒排索引原理
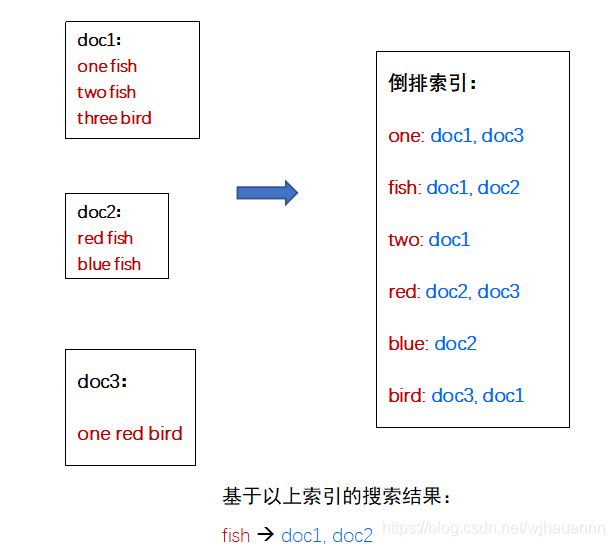
这里,doc1、doc2、doc3可以理解为网页或文档。
要求:
(1)数据输入
鹿鼎记.txt 笑傲江湖.txt 倚天屠龙记.txt
(2)输出数据
样例:
沙和尚=鹿鼎记.txt->1 典故=鹿鼎记.txt->7 笑傲江湖.txt->1
冯府=鹿鼎记.txt->4
倒转剑=倚天屠龙记.txt->7 笑傲江湖.txt->1 鹿鼎记.txt->2
死相报=鹿鼎记.txt->1 出喀=笑傲江湖.txt->1
内掩=笑傲江湖.txt->1
全权=鹿鼎记.txt->1
下歉仄=倚天屠龙记.txt->2 笑傲江湖.txt->1
元殿=鹿鼎记.txt->1
入林=鹿鼎记.txt->2 笑傲江湖.txt->2
僧盘=倚天屠龙记.txt->1
…
…
本题明显需要使用hanlp进行分词与hashmap
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class unit {
HashMap<String,Integer> filefrequency;//此处Key为文件名,Value为频数
public unit(){
filefrequency = new HashMap<>();
}
public unit(String filename){
filefrequency = new HashMap<>();
put(filename);
}
public void put(String filename){
if(filefrequency.containsKey(filename)){
int tmp=filefrequency.get(filename);
filefrequency.put(filename,tmp+1);
}else{
filefrequency.put(filename,1);
}
}
public String toString(){
//用作后文输出到文件构建字符串
Iterator it = filefrequency.entrySet().iterator();
String str="";
while(it.hasNext()){
Map.Entry entry = (Map.Entry)it.next();
str= str+entry.getKey()+"->"+entry.getValue()+" ";
}
return str;
}
}
主程序内的Hashmap中Key为关键词 Value为unit类,以此实现三个独立计数器。
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.dictionary.stopword.CoreStopWordDictionary;
import com.hankcs.hanlp.seg.common.Term;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.*;
public class bbb {
public static void main(String[] args) throws IOException {
File file1 = new File("鹿鼎记.txt");
File file2 = new File("笑傲江湖.txt");
File file3 = new File("倚天屠龙记.txt");
HashMap<String,unit> hashmap = new HashMap<>();//主程序hashmap
Scanner sc = new Scanner(file1);
String filename = file1.getName();
while(sc.hasNextLine()){
String buffer = sc.nextLine();
List<Term> list = CoreStopWordDictionary.apply(HanLP.segment(buffer));
for(Term i : list) {
hashput(hashmap, i, filename);
}
}
//此处本可使用多线程处理,但数据量比较小,嫌麻烦,直接复制粘贴
sc = new Scanner(file2);
filename = file2.getName();
while(sc.hasNextLine()){
String buffer = sc.nextLine();
List<Term> list = CoreStopWordDictionary.apply(HanLP.segment(buffer));
for(Term i : list) {
hashput(hashmap, i, filename);
}
}
sc = new Scanner(file3);
filename = file3.getName();
while(sc.hasNextLine()){
String buffer = sc.nextLine();
List<Term> list = CoreStopWordDictionary.apply(HanLP.segment(buffer));
for(Term i : list) {
hashput(hashmap, i, filename);
}
}
//输出索引数据部分
File tarfile = new File("索引数据.txt");
tarfile.createNewFile();
FileOutputStream fos = new FileOutputStream(tarfile);
Iterator it = hashmap.entrySet().iterator();
while(it.hasNext()){
Map.Entry<String,unit> entry = (Map.Entry)it.next();
unit unit=entry.getValue();
String str = entry.getKey()+"="+unit.toString()+"\r\n";
fos.write(str.getBytes());
}
fos.close();
System.out.println("end");
}
static void hashput(HashMap<String,unit> hashmap,Term i,String filename){
if(hashmap.containsKey(i.word)){
unit unit = hashmap.get(i.word);
unit.put(filename);
}else{
hashmap.put(i.word,new unit(filename));
}
}
}
最后生成生成索引数据文件:
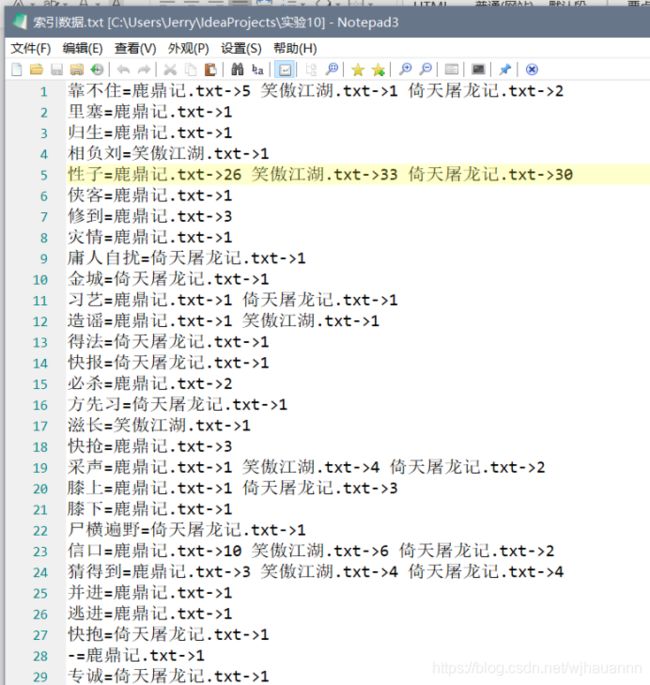
闲来无事实现了一下多线程创建
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.dictionary.stopword.CoreStopWordDictionary;
import com.hankcs.hanlp.seg.common.Term;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.*;
public class bbb {
public static void main(String[] args) throws IOException {
File file1 = new File("鹿鼎记.txt");
File file2 = new File("笑傲江湖.txt");
File file3 = new File("倚天屠龙记.txt");
HashMap<String,unit> hashmap = new HashMap<>();
Thread t1= new Thread(new mythread(file1,hashmap));
Thread t2= new Thread(new mythread(file2,hashmap));
Thread t3= new Thread(new mythread(file3,hashmap));
t1.start();
t2.start();
t3.start();
try {
t1.join();
t2.join();
t3.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
File tarfile = new File("索引数据.txt");
tarfile.createNewFile();
FileOutputStream fos = new FileOutputStream(tarfile);
Iterator it = hashmap.entrySet().iterator();
while(it.hasNext()){
Map.Entry<String,unit> entry = (Map.Entry)it.next();
unit unit=entry.getValue();
String str = entry.getKey()+"="+unit.toString()+"\r\n";
fos.write(str.getBytes());
}
fos.close();
System.out.println("end");
}
public static void hashput(HashMap<String,unit> hashmap,Term i,String filename){
if(hashmap.containsKey(i.word)){
unit unit = hashmap.get(i.word);
unit.put(filename);
}else{
hashmap.put(i.word,new unit(filename));
}
}
}
class mythread implements Runnable{
File file;
HashMap<String,unit> hashmap;
public mythread(File file,HashMap<String,unit> hashmap){
this.file=file;
this.hashmap=hashmap;
}
@Override
public void run() {
try {
Scanner sc = new Scanner(file);
String filename = file.getName();
while (sc.hasNextLine()) {
String buffer = sc.nextLine();
List<Term> list = CoreStopWordDictionary.apply(HanLP.segment(buffer));
for (Term i : list) {
bbb.hashput(hashmap, i, filename);
}
}
}catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}