神经网络衣服分类器详解(Fashion-MNIST数据集)
文章目录
- 前言
- 一、Fashion-MNIST是什么?
- 二、代码实现
-
- 1.引入库
- 2.读取数据集
- 3.数据预处理
- 4.搭建神经网络
- 5.编译和训练神经网络模型
- 6.神经网络预测
- 总结
前言
每个想要学习深度学习、图像识别的同学,想要用到神经网络,入门的实例必定是MNIST手写数字集,这是所有人都绕不开的,我也是,我之前写了三篇关于MNIST的博文。en…但这个数据集毕竟只有手写数字,有时候并不是能够满足我们开发的要求,于是,Fashion-MNIST出现了。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Fashion-MNIST是什么?
这个数据集是我们国家的一个大佬制作的,还发表了论文:Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms,其中值得我们关注的是数据制作的方法:最原始图片是背景为浅灰色的,分辨率为7621000 的JPEG图片。然后经过resampled 到 5173 的彩色图片。然后依次经过以下7个步骤,最终得到28*28的灰度图。
2017年8月27日,Fashion-MNIST图片库在GitHub上开源,MNIST的时代宣告终结。
这不是巧合,而是Fashion-MNIST蓄谋已久。它克隆了MNIST的所有外在特征:
60000张训练图像和对应Label;
10000张测试图像和对应Label;
10个类别;
每张图像28x28的分辨率;
4个GZ文件名称都一样;
对于已有的MNIST训练程序,只要修改下代码中的数据集读取路径,或者残暴的用Fashion-MNIST数据集文件将MNIST覆盖,替换就瞬间完成了。
不同的是,Fashion-MNIST不再是抽象符号,而是更加具象化的人类必需品——服装,共10大类。
我认为对于衣服的识别,相比于手写数字的识别更加有意义。相比之下,Fashion-MNIST更难,有一位博主对于MNIST可以达到95%识别率的训练代码,去训练Fashion-MNIST,最后模型识别率猛降了10个百分点。对于一个人工智能算法,是否可用的一个根本性度量标准就是:不亚于人类。

二、代码实现
1.引入库
代码如下(示例):
from __future__ import absolute_import, division, print_function, unicode_literals
# 载入TensorFlow 和 tf.keras
import tensorflow as tf
from tensorflow import keras
# 载入 辅助包
import numpy as np
import matplotlib.pyplot as plt
# 输出当前的tf版本
# print(tf.__version__)
2.读取数据集
代码如下(示例):
#从网站下载数据=========================================
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
(1)残暴的用Fashion-MNIST数据集文件将MNIST覆盖,替换就瞬间完成了。
(2)再将训练图像、训练标签和测试图像、测试标签读取出来就可以了。和之前的MNIST读取并没有分别。
(3)定义整理一个衣服类别数组,到最后预测的时候,可以根据索引值查找模型预测的是哪一类衣服。
3.数据预处理
代码如下(示例):
train_images = train_images / 255.0 #像素的值除以255。
test_images = test_images / 255.0
在训练网络之前,有必要对数据进行预处理。试着调查最初的图像就会明白,像素的值是从0到255之间的数值。
4.搭建神经网络
代码如下(示例):
model = keras.Sequential([ #选择序贯模型
keras.layers.Flatten(input_shape=(28, 28)), #Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。
#28*28变为1*784 Flatten不影响batch的大小。
keras.layers.Dense(128, activation='relu'),#添加全连接层,输出空间维度(节点)为128,激活函数为relu,作用是分类
keras.layers.Dense(10, activation='softmax')#添加全连接层,输出空间维度为10,激活函数为softmax
])
# 设定层:一个Flatten层、2个全连接层
构成神经网络的基本构成要素是层(layer)。从输入的数据抽出“特征”。那些“特征”是更“有意义”的东西。
#深度学习模型大部分都是由简单的层叠组成的。在大部分层,例如tf.keras.layers.Dense,有训练中学习的参数。
5.编译和训练神经网络模型
代码如下(示例):
model.compile(optimizer='adam', #Adam优化器,adam有默认的学习率,所以不用写lr大小,作用:自适应动态调整学习率
loss='sparse_categorical_crossentropy',#损失函数
metrics=['accuracy']) #评价函数为正确率
model.fit(train_images, train_labels, epochs=5)#训练5个回合
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2) #model.evaluate函数预测给定输入的输出,
#verbose=2 为每个epoch输出一行记录
print("test_loss:", test_loss, " 测试准确率为:", test_acc)
6.神经网络预测
代码如下(示例):
predictions = model.predict(test_images)
predictions[0]
np.argmax(predictions[0])#返回一个numpy数组中最大值的索引值。当一组中同时出现几个最大值时,返回第一个最大值的索引值。
此时预测的是测试集图像的第一个值,通过np.argmax()函数将回一个numpy数组中最大值的索引值。这个值就是模型预测的衣服类别,这个数值也是我们之前整理的衣服类别数组中对应的那个索引值。
## 7.预测运行结果
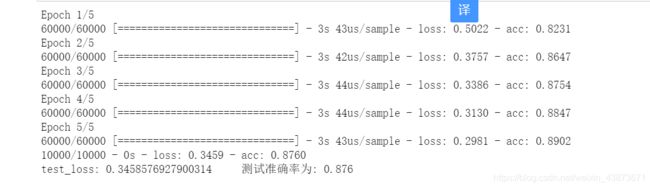

能够看出,测试准确率为87.6%,最后模型预测数据集第一张衣服的种类索引值为9,即最后一个种类,通过查找数组,发现模型预测第一张图片是Ankle boot类别。
总结
这个神经网络模型的搭建使用了全连接神经网络,没有涉及到卷积神经网络的卷积和池化操作,这也是识别率偏低的直接原因,后期可以在神经网络模型中添加卷积层和池化层来提高识别率,降低损失率。另外在后期也实现了将以图表的形式呈现出来预测的结果,这样更加有利于使用者的观感。大大提高了舒适度。