Pandas学习(一)——预备知识(Python基础NumPy基础)
第一次参加DataWhale的组队学习,哈哈哈,期待满满!
1.1.1、语法糖
两个比较实用的语法糖是列表(字典)推导式和条件赋值

这个例子举得很好,把两个语法糖结合在一起展现了。
我自己还尝试了一个。我现在想把这个字典里的所有的键值对拼接成一个字符串。
没学语法糖的时候我是这么做的。
dict1 = {
'a':1,'b':3,'c':2}
s = ''
for key, val in dict1.items():
s = s + key + '_' + str(val) + '_'
print(s) # a_1_b_3_c_2_
但是学了语法糖后,我可以用一行搞定:
s = '_'.join([key + '_' + str(val) for key, val in dict1.items()])
print(s) # a_1_b_3_c_2
注意到这边打印结果少了一个下划线。字符串join方法作用是把下划线插入到可迭代对象之间。
1.1.2、zip函数,压缩与解压

这个压缩和解压看起来还是挺有意思的,zip作用是把不同序列对应元素取出来再打包,*操作符可以把压缩好的序列解压缩(只解压最外一层)。
BTW还有个**操作符,其作用是对字典解压缩,这个在输入函数关键字参数kwargs的时候有用
1.2.1、Numpy数组构造

我以前学NumPy的时候从来没发现字符也可以作为ndarray的元素,有被惊到。
这边
U是Unicode的意思,原来如此~长知识了
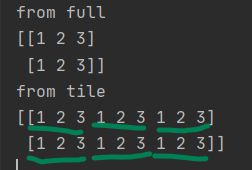
np.tile, np.full方法的对比
两个方法都接受两个参数,第一个是shape,第二个是数组或数值;区别是tile的第一个参数是原数组,第二个参数才是shape,并且是把数组当作一个整体去填充的,故返回的数组与传入数组shape常常不一致,而full返回的数组shape就是指定的shape。tile跟MATLAB中的repmat是很像的~
a = np.array([1,2,3])
b = np.full((2,3), a)
c = np.tile(a, (2,3))
print('from full')
print(b)
print('from tile')
print(c)
1.2.2、array合并
除了教程里的np.c_和np.r_,其实还有np.hstack,np.vstack,np.dstack,np.concatenate可以拼接数组,这两者之间的主要区别就是,后面四种是函数,必须用(),而前面两种不是,要用[],看例子:
a = np.array([1,2,3])
b = np.array([2,3,4])
x = np.r_[a,b]
y = np.c_[a,b]
print(x) # [1 2 3 2 3 4]
print(y) # [[1 2]
# [2 3]
# [3 4]]
m = np.hstack((a,b))
n = np.vstack((a,b))
print(m) # [1 2 3 2 3 4]
print(n) # [[1 2 3]
# [2 3 4]]
注意:hstack和vstack只能接受一个参数也就是一个tuple,所以使用这两个函数必须得有双重括号,这也是我经常犯的一个错误。
可以从首字母联想记忆,r–>row按行拼接,c–>column,按列拼接,h–>horizontal,水平拼接,v–>vertical,垂直拼接,d–>deep,按深度(页)拼接,concatenate–>任意拼接,需指定axis。
真好,边学Python边背单词~
1.2.2、array变形
reshape可以指定按C(C语言)还是按F(Fortran)顺序读原数组且填充新的数组,注意,读取和写入都是按照这个order,F跟MATLAB的顺序是一样的,不过我一般不指定这个关键字参数。
这里拓展一下,总结一下numpy中把数组拉平(变一维)和扩充维度的方法。
- 拉平方法:array.flatten(), array.reshape(-1), array.ravel()
a = np.array([[1,2,3,4]])
print(a) # [[1,2,3,4]]
print(a.flatten()) # [1,2,3,4]
print(a.reshape(-1)) # [1,2,3,4]
print(a.ravel()) # [1,2,3,4]
- 扩维方法: array.reshape, np.expand_dims, np.newaxis
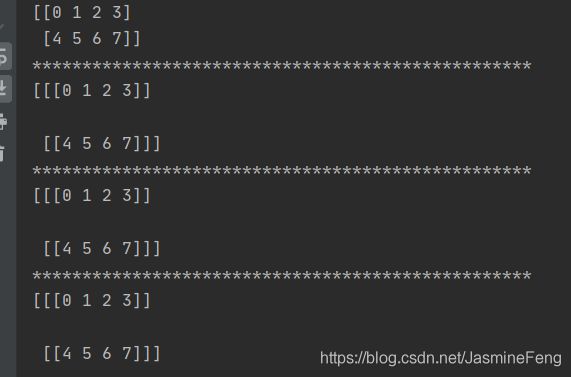
a = np.arange(8).reshape(2,4)
print(a)
print('*'*50)
print(a.reshape((2,1,4)))
print('*'*50)
print(np.expand_dims(a,axis=1))
print('*'*50)
print(a[:,np.newaxis,:])
打印结果:(新数组两页,每页是1×4)
1.2.3、切片与索引
布尔索引可以用np.ix_,欸,这个我倒是没用过,有点意思
74行输入意思是第0个维度取第0、2个,第1个维度取第0、2个,所以最后得到的数有2×2=4个,位置分别在(0,0),(0,2),(2,0),(2,2)。
一个想提的但教程里没说的是对与布尔值构成的数组取非是不能用not的,会报错,应该用取补运算符~。ndarray[~np.isnan(ndarray)]
1.2.4、常用函数
- np.where,作用有两个,一个只给condition作参数,那么找出数组中满足给定condition的元素,返回其索引;另一个是给condition、两种操作(一共三个参数),对数组中满足和不满足给定condition的元素分别进行不同的操作,并返回处理后的新数组(跟map函数有点像哦?)
a = np.arange(8).reshape(2,4)
b = np.where(a>4,a**2,0)
print(a) # [[0 1 2 3]
# [4 5 6 7]]
print(b) # [[0 0 0 0]
# [0 25 36 49]]
这边把大于四的数变成平方,否则置零。
a = np.arange(8).reshape(2,4)
c = np.where(a>4)
print(c) # (array([1, 1, 1], dtype=int64), array([1, 2, 3], dtype=int64))
返回一个元组,元组由两个arrays构成,第0个是行索引构成的array,第1个是列索引构成的array。
顺便比较一下np.argwhere:
d = np.argwhere(a>4)
print(d) # [[1 1]
# [1 2]
# [1 3]]
argwhere返回的也是一个索引,不过更直观一些,可以理解为返回坐标值,相当于是where返回的压缩zip(知识串起来了有木有!)
- np.diff与np.grad对比
教程里貌似只提了diff也就是向前(后)差分,但我个人更喜欢用gradient梯度,因为gradient返回的数组元素个数是与原数组相同的。gradient时,第一个用向后差分,最后用向前差分,其余用中心差分。
a = np.array([1,2,4,8,16])
print(np.diff(a)) # [1 2 4 8]
print(np.gradient(a)) # [1. 1.5 3. 6. 8. ]
注意gradient返回数组的dtype是float(默认float64)
- np.nan一类函数

这个以前也没注意过,如果数组里有NaN的话,应该用nan开头的一类统计函数。
BTW, NaN != NaN
np.quantile这个pandas库里也有,numpy里就不细说了~
np.corrcoef & np.cov

直接调用这两个方法当然可以,但也可以自己用NumPy编一个函数~
def my_cov(a, b):
m = a.shape[0]
x = np.c_[a, b]
x = x - x.mean(axis=0) # 0中心化
cov = x.T.dot(x) / (m-1) # 分母是样本数-1
return cov
def my_corr_coef(a,b):
cov = my_cov(a,b)
a_cov = cov[0, 0]
b_cov = cov[1, 1]
ab_cov = np.sqrt(a_cov * b_cov)
y = np.array([[a_cov, ab_cov], [ab_cov, b_cov]])
r = cov / y
return r
a = np.array([1,3,5,9])
b = np.array([1,5,3,-9])
print(my_cov(a,b))
print(my_corr_coef(a,b))
打印结果与教程一样的,这里不展示了~
然后就是axis的问题,很多初学者这边都会踩坑,我当时也是用了很久才想明白,我觉得记行还是列不太好,容易混淆,我自己的记忆方法是这样的:
首先我们得弄明白shape,行与列永远是shape的最后两个数,且最后一个一定是列,倒数第二个一定是行,然后我们把行与列构成的二维数组看作一个整体。如果shape一共有三个数(a,row,col),那么第0维是a的话就代表有a页二维(row×col)数组;同样地如果shape一共有四个数,(a,b,row,col),那么就代表有a个{b页的二维(row×col)}数组。
axis与shape中的每个数是一一对应的,axis=0,1,2分别对应shape的第0,1,2维。比方说求均值吧,我们得把每个值加起来,假设x的shape(4,2),你可以想象执行相加操作的时候有一个类似于指针的东西在移动,那么x.sum(axis=0)意味着第1维不动,第0维在动,也就是说指针先在1的位置,然后3、5、7。
这些统计函数中还有一个容易踩坑的地方是keepdims关键字,比方说在0中心化的时候,这个关键字是很有用的。这个关键字从字面意思上理解就是保持维数不变,什么意思呢,比方说我上面这个(4,2)的数组,按理说在sum或者mean以后会变成(1,2)这个形状,但其实你不指定keepdims的话(缺省值False),numpy会进一步对(1,2)进行压缩,最终输出的形状是(2,)
x = np.arange(1,9).reshape((4,2))
print(x)
s1 = x.mean(axis=0)
print(s1) # [4. 5.]
print(s1.shape) # (2,)
这种情况问题还不大,毕竟NumPy有广播机制。但是下面这种情况问题就出现了,我想对每一行做0中心化(去均值),因此减去每一行的均值(有个指针在每一列上从左向右移动):
x = np.arange(1,9).reshape((4,2))
print(x)
mu = x.mean(axis=1)
x_0center = x - mu
print(mu)
print(mu.shape)
print(x_0center)
这时,弹出一条error:
ValueError: operands could not be broadcast together with shapes (4,2) (4,)
什么意思呢,就是我做完mean后得到的mu是从(4,1)被压缩成(4,),这个时候没办法广播!
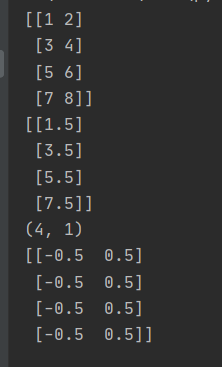
所以这个时候就必须指定keepdims为真了:
x = np.arange(1,9).reshape((4,2))
print(x)
mu = x.mean(axis=1,keepdims=True)
x_0center = x - mu
print(mu)
print(mu.shape)
print(x_0center)
打印结果:
1.2.5、广播机制
请注意能够广播的条件是两个数组中必须有一个对应维度是一致的,不对应那也没用,比方说上面的(4,2)和(4,)就不能广播再运算(当然如果有标量那另当别论,标量跟任何数组运算都能广播吧)
P.S.我们应该认为(4,)中的4是最后一个维度而不是第一个维度,所以能不能广播应该检查它与(4,2)中的2是否一致而不是4
1.2.6、向量与矩阵的运算
np.dot既可以做向量内积,又可以做矩阵乘法,如果是做矩阵乘法,与@操作符等价。
np.linalg.norm 对于向量来说,常用范数有L2范数也就是欧几里得范数(平方和再开方),L1范数(绝对值之和),L0范数(非零元素个数),无穷范数(最大绝对值)对矩阵常用的是Frobenius范数,他是L2范数在矩阵的扩充。用order关键字指定。
P.S. 这边linalg全名linear algebra,懂的都懂~
练习题
1.3.1、列表推导式写矩阵乘法
果然我太菜了,我用了两次列表推导式,还用了numpy的reshape。。。
import numpy as np
M1 = np.random.randn(2,3)
M2 = np.random.randn(3,4)
a = [M1[i, k] * M2[k, j] for i in range(M1.shape[0]) for j in range(M2.shape[1]) for k in range(M1.shape[1])]
res = np.array([np.sum(a[m] + a[m + 1] + a[m + 2]) for m in range(0, len(a), M1.shape[1])]).reshape(M1.shape[0],
M2.shape[1])
print(((res - M1 @ M2)<1e-15).all()) # True
答案:[[sum([M1[i, k]*M2[k,j] for k in range(M1.shape[1])]) for j in range(M2.shape[1])] for i in range(M1.shape[0])]
注意:这里有列表嵌套才能形成(2,4)的形状,我原来就没有考虑到嵌套的问题,所以求得的a是拉平的。
1.3.2、更新矩阵

做我是做出来了,自我感觉也挺高效:B = A * np.sum(1/A,axis=1,keepdims=True)
不过答案我看了好一会儿才看明白,B = A*(1/A).sum(1).reshape(-1,1)
这里确实犯傻了,我一开始还以为A*(1/A)不是应该得到全为1的矩阵吗。。。
.点操作符的运算优先级高于乘法运算符(希望没人跟我一样犯傻),这边先执行sum,再执行reshape,最后才相乘
sum(1)其实就是sum(axis=1),因为没有指定keepdims=True,所以要reshape一下才能广播~。
1.3.3、卡方统计量

思路很简单,按照公式一步步来就好了
B = np.dot(A.sum(axis=1,keepdims=True),A.sum(axis=0,keepdims=True))/A.sum() # 我的
B1 = A.sum(0)*A.sum(1).reshape(-1, 1)/A.sum() # 答案
chi2 = ((A-B)**2/B).sum()
按我的理解,答案这个其实不是广播,小白慎用,反正我是小白。。。老老实实按照dot乘法算吧。

下面分别给出待改进函数、我的改进函数,以及答案的改进。L_res都一样的(这个不用怀疑)
我的思路是既然 ∣ ∣ B i − U j ∣ ∣ 2 2 ||B_i-U_j||_2^2 ∣∣Bi−Uj∣∣22是相减得到的,那我就减呗~,但是不能直接减,因为形状不对,所以我先把B扩维到(m,1,p),U转置为(n,p),这样减出来的就是(m,n,p),然后就在axis=-1也就是最后一维上移动我们的指针(还记得我前面那个比喻吗,因为我现在要求的是每一行的L2范数的平方)。
答案用了数学的技巧,(感觉也算不上技巧,无非就是公式的变形而已:) )
def solution(B=B, U=U, Z=Z):
L_res = []
for i in range(m):
for j in range(n):
norm_value = ((B[i]-U[:,j])**2).sum()
L_res.append(norm_value*Z[i][j])
return sum(L_res)
def my_solution():
L_res = (np.linalg.norm(np.expand_dims(B, axis=1) - U.T,axis=-1)**2 * Z).sum()
def answer():
L_res= ((np.ones((m, n)) * (B ** 2).sum(1).reshape(-1, 1) + np.ones((m, n)) * (U ** 2).sum(0) - 2 * B @ U) * Z).sum()
下面来检验一下性能:
t0 = timeit.timeit('solution()' ,'from __main__ import solution',number=300)
t1 = timeit.timeit('my_solution()' ,'from __main__ import my_solution',number=300)
t2 = timeit.timeit('answer()' ,'from __main__ import answer',number=300)
print(t0,'s') # 11.0360933s
print(t1,'s') # 1.3576491999999991s
print(t2,'s') # 0.08481260000000113s
我的改进相比于原方法提升了十倍左右性能,不过答案更绝,性能提升了十几倍。。。我估计,我的时间主要耗在norm的计算上了?
1.3.5、连续整数最大长度

这题扔我我还真没啥思路,真要写只能暴力计算了。。。
答案很巧妙啊(下面代码是在命令行敲的,第三、四行下划线_代表上次输出的结果)
a = np.array([1,2,5,6,7])
np.r_[1,np.diff(a)!=1,1]
# array([1, 0, 1, 0, 0, 1], dtype=int32)
np.nonzero(_)
# (array([0, 2, 5], dtype=int64),)
np.diff(_).max()
3
相当于是在数组的起点与终点分别做了标记,把不连续的点置一,那么连续区间的长度就是相邻标记的差,实在是妙!学到了哈哈
终于把第一章学完了!!无所谓,也有点累:)
大家一起加油鸭~