神经网络没学到东西
By Hannah Peterson and George Williams ([email protected])
汉娜·彼得森( Hannah Peterson)和乔治·威廉姆斯( George Williams) ([email protected])
什么是灾难性遗忘? (What is Catastrophic Forgetting?)
Our brains are ever-evolving objects, continuously revising their structures to retain new information and get rid of the old based on our interactions with the environment. As we know, artificial neural networks with their webs of activations and connections were originally modeled after the brain. Most ANNs, however, are made to be static in structure, relying on batch learning in which they are fed many batches of independent identically distributed (IID) data at training time and their learned parameters are fixed upon deployment, which is inconsistent with the way our brains learn: We do not learn by processing random batches of data all at once, but by processing the continuous streams of causally related information we receive about our environment from our senses.
我们的大脑是不断发展的对象,它们会不断修改其结构以保留新信息,并根据与环境的相互作用来摆脱旧的信息。 众所周知,人工神经网络及其激活和连接网最初是根据大脑建模的。 但是,大多数ANN的结构都是静态的,依赖于批处理学习,在批处理学习中,它们在训练时被喂入许多批独立的均匀分布(IID)数据,并且它们的学习参数在部署时是固定的,这与方法不同我们的大脑学习:我们不是一次处理随机的数据,而是通过处理源源不断的因果关系信息来学习我们的环境。
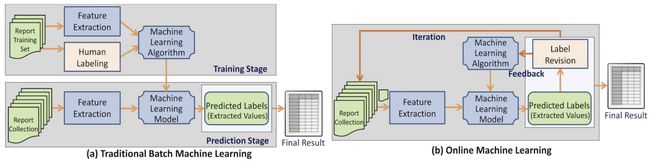
While batch learning works fine for tasks in which the precise nature of the data a model will encounter at inference is known beforehand, like in classifying specific classes of random photos, this is an unrealistic precedent in many real-world applications where a model may encounter new data after deployment. In such instances, we would want the model to adapt to deal with the new data on the fly, a process known as online learning. Additionally, in most cases the data encountered is not random but occurs in sequences of related instances, such as frames of a video or fluctuations in a stock’s price—a property that must also be taken into account when developing online learning solutions.
虽然批处理学习对于预先知道模型将在推理中遇到的数据的精确性质的任务非常有效,例如在对随机照片的特定类别进行分类时,但这在许多可能遇到模型的实际应用中是不现实的先例部署后的新数据。 在这种情况下,我们希望模型能够适应动态处理新数据的过程,这一过程称为在线学习。 此外,在大多数情况下,遇到的数据不是随机的,而是发生在相关实例的序列中,例如视频帧或股票价格的波动,这是在开发在线学习解决方案时也必须考虑的属性。
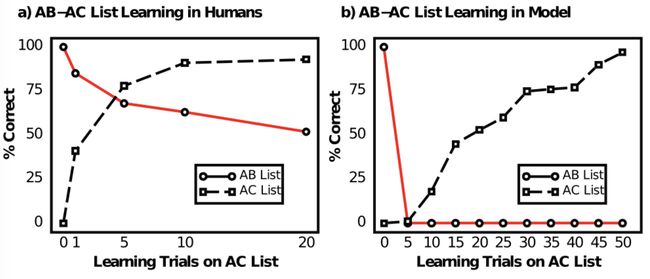
There have been several attempts to create evolving neural networks for online learning but they inevitably run into the problem of what is known as catastrophic forgetting (sometimes called catastrophic interference), where adapting to perform new tasks causes the network to “forget” those it previously learned. This phenomenon was first discovered by researchers McCloskey and Cohen all the way back in 1989 when testing a network’s ability to sequentially learn associate list tasks. In their experiment, the first task consisted of learning pairs of arbitrary words from two sets A and B, such as “locomotive - dishtowel, window - reason, bicycle - tree, etc.” The network was trained until it could perfectly recall the B associate for each A item. It then began learning a second task in which set A was paired with different words from set C, such as “locomotive - cloud, window - book, bicycle - couch, etc.” and it was tested on its ability to remember pairings from the AB list after 1, 5, 10 and 20 iterations of learning the AC list. The following graph b) shows how the network rapidly forgets the AB task after beginning to learn the AC task, as compared to human performance in the same experimental setup, which demonstrates that our brains are able to retain knowledge of previous tasks much more effectively.
已经进行了多种尝试来创建不断发展的神经网络以进行在线学习,但是它们不可避免地遇到了所谓的灾难性遗忘(有时称为灾难性干扰)的问题,在这种情况下,适应执行新任务会使网络“忘记”以前的任务学到了。 这种现象最早是由研究人员McCloskey和Cohen于1989年首次发现的,当时他测试了网络顺序学习关联列表任务的能力。 在他们的实验中,第一个任务包括从两组A和B中学习成对的任意单词,例如“机车-毛巾,窗户-原因,自行车-树等”。 对网络进行培训,直到可以完全回忆起每个A项目的B员工。 然后,它开始学习第二项任务,其中将A组与C组中的不同单词配对,例如“机车-云,窗户-书本,自行车-长沙发等”。 并且测试了它在学习AC列表的1、5、10和20次迭代后从AB列表中记忆配对的能力。 下图b)显示了网络在开始学习AC任务后如何Swift忘记AB任务,与在相同实验设置中的人为表现相比,这表明我们的大脑能够更有效地保留先前任务的知识。
It’s undoubtedly challenging to construct a network that is finite in structure but that can retain knowledge of past experiences given a continuous stream of data. Initial tactics for overcoming catastrophic forgetting relied on allocating progressively more resources to networks as new classes were learned, an approach that is ultimately unsustainable for most real-world applications. Let’s now take a look at some more recent strategies for compelling networks to remember.
构建结构有限但可以在连续数据流的情况下保留过去经验的知识无疑是一个挑战。 克服灾难性遗忘的最初策略是,随着新类的学习,逐步为网络分配更多的资源,这种方法对于大多数实际应用程序最终是不可持续的。 现在,让我们看一些吸引网络记忆的最新策略。
记忆策略 (Strategies for Remembering)
正则化(Regularization)
One heavily researched mechanism for dealing with catastrophic forgetting is regularization. As we know, a network adapts to learn new tasks by adjusting the weights of its connections, and regularization involves varying the changeability, or plasticity, of weights based on how important they are determined to be for previous tasks.
正则化是处理灾难性遗忘的一种经过深入研究的机制。 众所周知,网络通过调整连接的权重来适应学习新任务的需要,而正则化则取决于确定权重对先前任务的重要性,从而改变权重的可变性或可塑性。
In a highly cited 2017 paper, Kirkpatrick et al. introduced a regularization technique called Elastic Weight Consolidation (EWC). EWC maintains the fidelity of connections important for previously learned tasks by constraining weights to stay close to their learned values as new tasks are encountered.
在2017年被高引用的论文中,Kirkpatrick等人。 介绍了一种称为弹性权重合并(EWC)的正则化技术。 EWC通过限制权重以使其在遇到新任务时保持接近其学习值,从而保持对先前学习的任务重要的连接保真度。
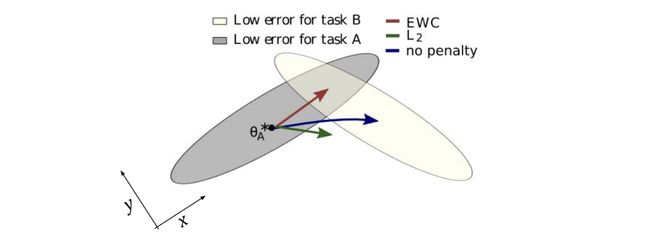
To illustrate how EWC works, let’s say we are learning some classification task A, for which our network is learning a set of weights θ. There are, in fact, multiple configurations of θ that will yield good performance on A—a general ballpark of weights represented by the gray ellipse in the diagram above. Catastrophic forgetting occurs when the network moves on to learn a different task B associated with a different ballpark of weights—the cream ellipse—and its weights are consequently adjusted such that they fall outside the ballpark for good performance on A, as illustrated by the blue arrow.
为了说明EWC的工作原理,假设我们正在学习一些分类任务A ,为此我们的网络正在学习一组权重θ 。 实际上,存在多个θ配置,它们将在A上产生良好的性能-上图中用灰色椭圆表示的一般权重范围。 灾难性的遗忘发生在网络前进以学习与不同的权重库(奶油椭圆)相关的其他任务B时,因此调整了其权重,使它们落在权库外,从而在A上表现良好,如蓝色所示箭头。
In EWC, a quadratic penalty is introduced to constrain the network parameters to stay within the low error region for task A when learning to perform B, depicted by the red arrow. The quadratic penalty acts as a “spring” of sorts to anchor the parameters to previously learned solutions, hence the name Elastic Weight Consolidation. The spring’s degree of elasticity, i.e. the degree of the quadratic penalty, differs between weights depending on how “important” the weights are determined to be for prior tasks. In the diagram, for example, task A’s 2D weight ellipsoid is longer along the x dimension than the y dimension, indicating the x weight is more important for A and thus will be afforded less elasticity than the y weight when adjusting to learn B. Failing to make the spring adaptable in this way and applying the same elasticity coefficient to each weight would result in weights not very well suited to either task, as indicated by the green arrow in the diagram.
在EWC中,引入了二次惩罚来约束网络参数,使其在学习执行B时留在任务A的低错误区域内,如红色箭头所示。 二次惩罚是将参数锚定到先前学习的解决方案的“弹簧”,因此称为弹性权重合并。 弹簧的弹性程度(即二次罚的程度)在权重之间有所不同,这取决于权重被确定为对先前任务有多“重要”。 例如,在该图中,任务A的2D重量椭球体沿x维度比y维度长,这表明x体重对A更为重要,因此在进行调整以学习B时,其权重比y轻。 未能使弹簧以这种方式适应并且无法对每个配重施加相同的弹性系数,将导致配重不能很好地适合任一任务,如图中的绿色箭头所示。
The EWC model is trained on a sequence of tasks, each task consisting of a batch of data. A task is a fixed random shuffling of pixels in the handwritten MNIST digit images. Once the model trains on data for one task, it moves on to the batch for the next task and data for previous tasks is not encountered again, which allows testing of how well EWC “remembers” how to perform previously learned tasks. The following plot shows EWC’s test performance on a sequence of three tasks A, B, and C as it proceeds through training on them.
在一系列任务上训练EWC模型,每个任务由一批数据组成。 任务是手写MNIST数字图像中的像素固定随机改组。 一旦模型针对一个任务的数据进行训练,就可以继续进行下一个任务的批处理,并且不再遇到先前任务的数据,从而可以测试EWC如何“记住”如何执行先前学习的任务。 下图显示了EWC在通过对三个任务A , B和C进行培训时对它们的测试性能。
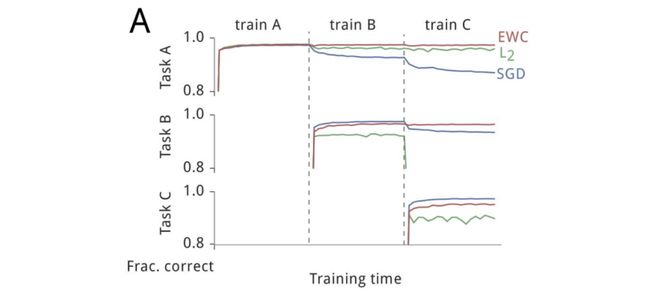
We can see how the performance of EWC remains fairly stable across previously learned tasks even as it learns new ones, as opposed to an approach that uses the same quadratic penalty for all weights (the green line) and one that doesn’t include a penalty at all, just using standard stochastic gradient descent (the blue line)—these both demonstrate catastrophic forgetting of task A, for example, as tasks B and C are learned.
我们可以看到,即使在学习新任务时,EWC的性能在以前学习的任务中也保持相当稳定,这与对所有权重使用相同的二次惩罚(绿线)并且不包含惩罚的方法相反根本上,仅使用标准的随机梯度下降(蓝线)—例如,在学习任务B和C时,这两者都显示了任务A的灾难性遗忘。
重播 (Replay)
Replay is another popular method for mitigating forgetting that involves storing some representation of previously encountered training data. The data is stored in what is referred to as a replay buffer. This technique was first proposed in the paper “iCaRL: Incremental Classifier and Representation Learning” by Rebuffi et al. in late 2016. In its replay buffer, iCaRL stores sets of images for each class encountered during training, referred to as “exemplar” images. The goal is for these images to be as representative of their respective classes as possible. For training, iCaRL processes batches of classes at a time. As a new class is encountered, a simulated training set is created with all the stored exemplars and the new data. All of this data is run through the network and its outputs for the previously learned classes are stored for the next step, in which the network’s parameters are updated. The network is updated by minimizing a loss function that integrates both classification loss and distillation loss—classification loss to prompt it to output correct labels for the newly encountered class and distillation loss to encourage it to reproduce the labels stored for the previously learned classes.
重播是缓解遗忘的另一种流行方法,它涉及存储以前遇到的训练数据的某种表示形式。 数据存储在所谓的重播缓冲区中。 Rebuffi等人在论文“ iCaRL:增量分类器和表示学习”中首次提出了这种技术。 在2016年下半年。在其重播缓冲区中,iCaRL为训练期间遇到的每个课程存储了一组图像,称为“示例性”图像。 目的是使这些图像尽可能代表各自的类别。 为了进行培训,iCaRL一次处理一批课程。 遇到新课程时,将使用所有存储的示例和新数据创建一个模拟训练集。 所有这些数据都通过网络运行,并且将其先前学习的类的输出存储下来,供下一步使用,在该步骤中更新网络参数。 通过最小化集成分类损失和蒸馏损失的损失函数来更新网络,分类损失是为了提示其输出针对新遇到的类别的正确标签,而蒸馏损失则是为了鼓励其重现为先前学习的类别存储的标签。
The network determines how to classify a given image by consulting the stored sets of exemplar images. Specifically, at inference time the exemplar images for a particular class are passed through the network to yield a set of feature vectors, which are averaged to produce a representative feature vector for that class. This is repeated for all classes and the feature vector for the test instance is compared to them all and assigned the label of the class it is most similar to. Importantly, a limit is imposed on the number of exemplar images that are stored such that if a new class is encountered after the limit is reached, images are removed from the sets of the other classes to accommodate for learning the new one. This prevents the computational requirements and memory footprint of the model from increasing unbounded as new classes are encountered.
网络通过查询存储的示例图像集来确定如何对给定图像进行分类。 具体而言,在推理时,将特定类别的示例图像通过网络,以生成一组特征向量,将其平均以生成该类别的代表性特征向量。 对所有类重复此操作,并将测试实例的特征向量与所有类进行比较,并为其分配最相似的类标签。 重要的是,对示例图像的数量施加了限制,以便在达到限制后遇到新类别时,会将图像从其他类别的集合中删除以适应学习新的类别。 这样可以防止在遇到新类时,模型的计算需求和内存占用无限制地增加。
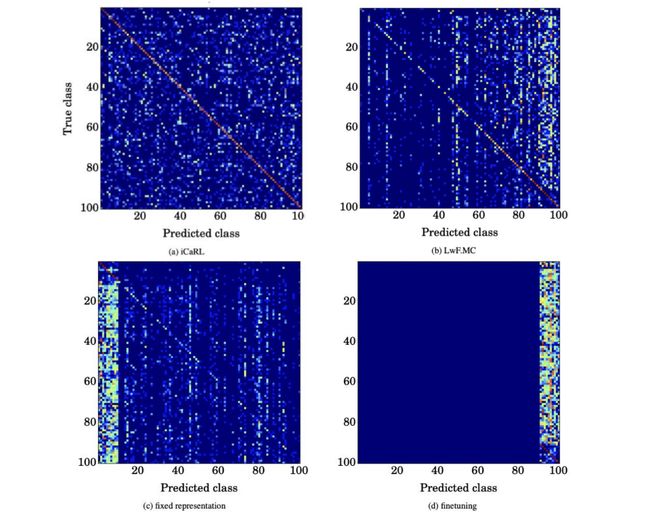
With this strategy, we can see evidence of iCaRL’s retention of previous classes (a) among the confusion matrices above. Illuminated pixels on the diagonal represent correct class predictions, and we can see that iCaRL achieves the most correct predictions as well as an even distribution of incorrect predictions as compared to other networks that are biased towards predicting initial classes (c) or more recently encountered classes (b and d).
通过这种策略,我们可以看到上述混淆矩阵中iCaRL保留了先前类别( a )的证据。 对角线上的发光像素表示正确的类别预测,并且与偏向于预测初始类别( c )或更近期遇到的类别的其他网络相比,我们可以看到iCaRL实现了最正确的预测以及错误预测的均匀分布( b和d )。
提醒 (REMIND)
iCaRL introduced the idea of storing training instances for replay to remember learned tasks and sparked a lot of research on different applications of this technique; however, all relied on storing raw representations of the training data in replay buffers, whereas the brain is known to store and replay memories as compressed representations of neocortical activity patterns. REMIND, standing for Replay using Memory INDexing, is a streaming learning model introduced by Hayes et al. in late 2019 that aims to mimic this functionality of the brain by storing feature maps of image data for replay, the first of its kind to do so. Further, many models for streaming learning involve processing input data in batches—for example, training on a batch of cat images and then on a batch of dog images—which is neither representative of how the brain works nor of most real-world deployment scenarios, where data is encountered one instance at a time in a continuous stream. Batch processing is also more resource intensive, making it unsuitable for many mobile applications, so for these reasons REMIND classifies instances one-by-one.
iCaRL引入了存储训练实例以重播以记住学习到的任务的想法,并引发了对该技术的不同应用的大量研究。 但是,所有人都依赖于将训练数据的原始表示存储在重播缓冲区中,而众所周知,大脑会以新皮层活动模式的压缩表示形式存储和重播记忆。 REMIND代表使用Memory INDexing进行重放,是Hayes等人引入的流学习模型。 在2019年下半年,它旨在通过存储图像数据的特征图进行重播来模仿大脑的这种功能,这是此类活动中的第一个。 此外,许多用于流学习的模型涉及成批处理输入数据(例如,对一批猫图像进行训练,然后对一批狗图像进行训练),这既不代表大脑如何工作,也不代表大多数实际部署场景,在连续流中一次遇到一个实例的数据。 批处理还占用大量资源,因此不适用于许多移动应用程序,因此由于这些原因,REMIND会对实例进行了逐一分类。
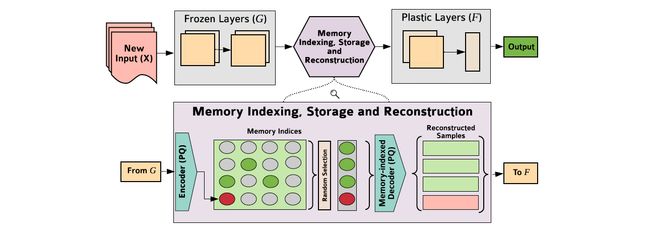
The REMIND network is split into two parts, as depicted in the diagram above: a series of frozen layers followed by a series of plastic layers, with a replay buffer in between. Training of the network begins with a “base initialization period,” in which all layers are trained on a certain number of classes in a normal offline manner to initialize their weights. After this, the weights of the frozen layers are, effectively, frozen—they remain unchanged for the remainder of training. The idea behind this is that initial neural network layers are made to generalize well across variable inputs, so it’s not necessary to update their weights as new data is encountered as they would not change significantly anyway. The feature map representations of the input images produced by the frozen layers of the network are used to train a vector quantization model that compresses the feature maps and learns how to faithfully reconstruct them. The compressed representations are what get stored in REMIND’s replay buffer, mimicking the brain’s mechanisms for storing memories as well as decreasing the size of the data so that more training instances can be stored in the buffer.
REMIND网络分为两个部分,如上图所示:一系列冻结层,然后是一系列塑料层,其间有一个重放缓冲区。 网络的训练从“基础初始化阶段”开始,在该阶段中,所有层以正常的脱机方式在一定数量的类上进行训练,以初始化其权重。 之后,有效冻结冻结层的权重-在其余训练中它们保持不变。 其背后的想法是使初始神经网络层能够很好地概括变量输入,因此,由于遇到新数据,因为它们始终不会发生重大变化,因此不必更新其权重。 由网络的冻结层产生的输入图像的特征图表示用于训练矢量量化模型,该模型压缩特征图并学习如何忠实地重建它们。 压缩的表示形式存储在REMIND的重播缓冲区中,它模仿了大脑存储内存的机制,并减小了数据的大小,以便可以在缓冲区中存储更多的训练实例。
After the base initialization period, each new training instance is run through the frozen layers of the network and combined with a number of instances that have been uniformly selected from the replay buffer and reconstructed via the learned quantization model. The mixture is then used to train the plastic layers of the network. Quantized training examples and their labels are stored in the replay buffer until it reaches its maximum capacity, at which point each time a new example is added, an example from the class with the most instances is randomly removed; this allows the model to learn new classes without expanding unbounded.
在基本初始化阶段之后,每个新的训练实例将通过网络的冻结层运行,并与已从重播缓冲区中统一选择并通过学习的量化模型进行重构的多个实例组合。 然后将混合物用于训练网络的塑料层。 量化的训练示例及其标签将存储在重播缓冲区中,直到达到最大容量为止,此时每次添加新示例时,都会从类中最多删除一个实例,而该示例将被删除。 这使模型可以学习新课程而不会无限制地扩展。
In the following plot, we can see how the test accuracy of REMIND’s online learning technique compares to others as it progresses to learn classes in an image classification task. We see that it achieves the best accuracy among the online approaches and is second only to the offline batch learning approach, where the network is retrained on random batches of all the previously encountered data as each new class is learned.
在下面的图表中,我们可以看到REMIND的在线学习技术的测试准确性在图像分类任务中学习类的过程中与其他方法的比较。 我们看到它在在线方法中达到了最高的准确性,并且仅次于离线批处理学习方法,后者是在学习每个新类时,对所有先前遇到的数据的随机批处理网络进行重新训练。
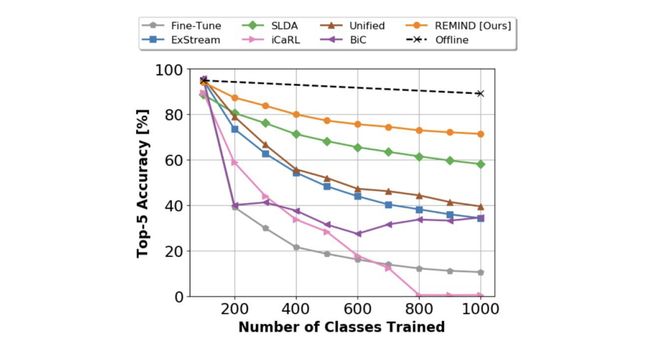
REMIND’s superior results indicate that mimicking the brain’s means of storing compressed memory representations in neural networks may be a key factor in compelling them to remember.
REMIND的优异结果表明,模仿大脑在神经网络中存储压缩记忆表示的方法可能是促使他们记忆的关键因素。
双层持续学习 (Bi-level Continual Learning)
Bi-level Continual Learning (BCL) is another online learning technique modeled after the way our brains operate. Proposed by Pham et al. in 2020, it involves two different models—a “fast-weight” model and a base model—which mirror the functionality of the hippocampus and neocortex, respectively. In our brains, the hippocampus is responsible for “rapid learning and acquiring new experiences” and the neocortex is tasked with “capturing common knowledge of all observed tasks.” To facilitate this in their model, Pham et al. employ both a generalization memory and an episodic memory buffer. The small episodic memory’s purpose is to store data from recent tasks for training the fast weight model, while the generalization memory stores data across all encountered tasks. The job of the fast weight model is to consolidate information from new samples for transfer to the base model.
双层持续学习(BCL)是另一种在线学习技术,其模仿我们的大脑运作方式。 由Pham等人提出。 在2020年,它涉及两个不同的模型-“快速体重”模型和基本模型-分别反映海马体和新皮层的功能。 在我们的大脑中,海马负责“快速学习并获得新经验”,而新大脑皮层负责“捕获所有观察到的任务的常识”。 为了在他们的模型中促进这一点,Pham等。 同时使用泛化记忆和情景记忆缓冲区。 小事件存储器的目的是存储来自最近任务的数据以训练快速权重模型,而概括存储器则存储所有遇到的任务的数据。 快速权重模型的工作是合并来自新样本的信息,以传输到基本模型。
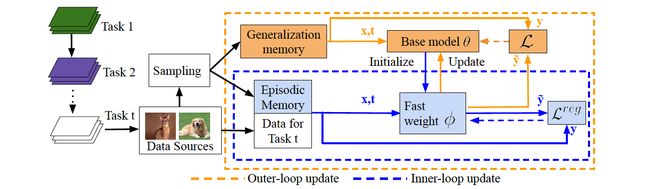
For BCL, data arrives in mini-batches corresponding to a particular class and a sample of it is put in generalization memory while most of it goes on to train the fast weight model. The fast weight model is initialized with the weights θ of the base model and is trained on the current batch of data for the particular class mixed with recently seen data from the episodic memory to arrive at a new set of weights Φ. The base model’s weights are then adjusted to factor in those from the fast weight model. While the fast weight model’s job is to quickly adapt to learn new tasks, a knowledge distillation regularizer is employed to encourage it to minimize the distance between new weights Φ it learns and its initial weights θ from the base model so that updates to the base model won’t cause it to lose too much generalization ability across tasks. After a mini batch is processed, the fast weights are discarded and re-initialized with the base model’s weights for learning the next batch of data.
对于BCL,数据以对应于特定类的小批形式到达,并将其样本放入通用存储器中,而大多数数据将用于训练快速权重模型。 快速权重模型使用基本模型的权重θ进行初始化,并在针对特定类别的当前数据批次上进行训练,并将其与情景存储器中最近看到的数据进行混合,以得出一组新的权重Φ 。 然后调整基本模型的权重,以考虑快速权重模型中的权重。 快速权重模型的工作是快速适应学习新任务,同时采用知识蒸馏规则化器来鼓励它最小化它学习的新权重Φ与基本模型中初始权重θ之间的距离,以便更新基本模型不会导致它在任务之间失去太多的泛化能力。 在处理了迷你批次后,快速权重将被丢弃,并使用基本模型的权重进行重新初始化,以学习下一批数据。
Pham et al. compare their BCL technique against several other continual learning models on a series of classification tasks and find that it generally outperforms them all. On the CIFAR100 dataset, a typical offline batch learning approach achieves 74.11% test accuracy and BCL achieves 67.75%, compared to the next best performing model that reaches 64.36%, and iCARL that achieves only 48.43% accuracy. The following graph shows how BCL and other replay techniques generally improve in performance on the CIFAR task as their episodic memory size increases, which makes sense given that a larger memory allows for a more accurate representation of the original dataset.
Pham等。 在一系列分类任务上将他们的BCL技术与其他几种持续学习模型进行比较,发现它总体上胜过它们。 在CIFAR100数据集上,典型的离线批处理学习方法可达到74.11%的测试准确度,而BCL则可达到67.75%,而性能次佳的模型达到64.36%,而iCARL则仅达到48.43%准确度。 下图显示了BCL和其他重播技术通常会随着情景存储器大小的增加而在CIFAR任务上总体上提高性能,鉴于更大的存储器可以更准确地表示原始数据集,因此这是有道理的。
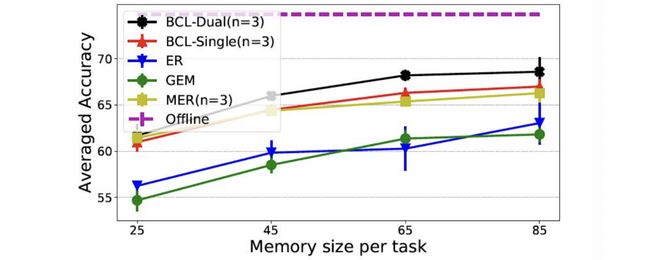
Unlike REMIND, though, BCL stores the raw, uncompressed data in its memory buffers. It would therefore be interesting to compare the performances of these two different approaches to modeling the brain’s structures for memory on the same task.
但是,与REMIND不同,BCL将原始的未压缩数据存储在其内存缓冲区中。 因此,比较这两种不同方法对同一任务的记忆记忆的大脑结构建模的性能会很有趣。
结论 (Conclusion)
Even among the incremental learning scenarios discussed here, the conditions for training are still not very representative of real-world scenarios—there aren’t many situations in which arriving data is so clearly delineated into incremental batches for each class. Given this, a new research direction is to investigate online learning with more realistic streaming scenarios where training instances stream with variable distributions. Such research would be particularly relevant for, for example, space-based applications of online learning where spacecraft may have to learn collision avoidance of previously unseen objects on the fly.
即使在这里讨论的增量学习方案中,培训的条件仍然不能很好地代表实际方案-在很多情况下,对于每个班级,如此清晰地将到达的数据划分为增量批次。 鉴于此,新的研究方向是研究具有更实际的流方案的在线学习,在这种情况下,训练实例以可变的分布进行流。 此类研究尤其适用于在线学习的基于空间的应用,其中航天器可能必须学习动态避开先前未见过的物体的碰撞。
翻译自: https://medium.com/gsi-technology/your-neural-network-will-forget-what-its-learned-39b7f578f24a
神经网络没学到东西