论文总结 | Dialogue Relation Extraction with Document-level Heterogeneous Graph Attention Networks
原文地址:https://arxiv.org/pdf/2009.05092.pdf
代码地址:https://github.com/declare-lab/dialog-HGAT
1.论文工作
1.提出基于注意力的异构图神经网络用于对活关系抽取。
2.设计消息传递机制以获取句子间的长距离信息。
2.相关知识
2.1 GAT
【图结构】之图注意力网络GAT详解
2.2 HGNN
有多个类型的节点或边的图称为非对称图神经网络。
3.模型介绍
任务定义:
给定一个包含 N N N条语句的对话 D = u 1 , u 2 , . . . u n D={u_1,u_2,...u_n} D=u1,u2,...un,有一组参数对 A = ( x 1 , y 1 ) , . . . A={(x_1,y_1),...} A=(x1,y1),...,找出参数对 ( x i , y i ) (x_i,y_i) (xi,yi)之间的关系类型。
模型如Figure 2所示,模型分为三个阶段:
1.语句编码
2.消息传递
3.关系分类
3.1语句编码
-
对于每条语句(utterance),构建局部BiLSTM:
e = [ e w ; w p ; e t ] e=[e_w;w_p;e_t] e=[ew;wp;et]
e w e_w ew:使用GloVe初始化
e p e_p ep:POS信息
e t e_t et:实体类型信息h j i ⃗ = L S T M L ( h j − 1 i ⃗ , e j i ) \vec {h_j^i}=LSTM_L(\vec{h^i_{j-1}},e_j^i) hji=LSTML(hj−1i,eji)
第 i i i条语句中,第 j j j层信息由第 j − 1 j-1 j−1层输出和本层输入得到。
将双边获得的第 j j j层信息向量拼接得 h j i h_j^i hji。 -
最大池化 h j i h_j^i hji,得到各条语句的 c i c_i ci。
-
对于整段对话(Dialogue),构建全局BiLSTM:
c i c_i ci作为各层输入,得到各层输出 U i U_i Ui
3.2消息传递
异构图:
共有5种节点:
- 语句(utterance):使用3.1中全局BiLSTM的输出初始化;
- 单词(word):本段对话所有单词,使用GloVe初始化;
- 对话者(speaker):specific embedding初始化;
- 参数(argument):specific embedding初始化;
- 实体类型(entity-type):created Entity-Tpye embedding初始化;
其中单词节点、对话者结点、参数节点称为基础节点(basic nodes)
共有5种边:
- 语句----单词:语句中出现的单词;使用POS信息初始化(获取对话的全局语义信息和单词的局部语法信息)
- 语句----说话者:
- 语句----参数:参数定位
- 单词----实体类型:一个单词可有多种实体类型
- 参数----实体
后四种边随机初始化。
图注意力机制:
F ( h i , h j ) = L e a k y R e L U ( a T ( W i ∗ h i ; W j ∗ h j ; E i j ) ) ( 1 ) F(h_i,h_j)=LeakyReLU(a^T(W_i*h_i;W_j*h_j;E_{ij}))(1) F(hi,hj)=LeakyReLU(aT(Wi∗hi;Wj∗hj;Eij))(1)
a i j = s o f t m a x ( F ( h i , h j ) ) = e x p ( F ( h i , h j ) ) ∑ k e x p ( F ( h i , h k ) ( 2 ) a_{ij}=softmax(F(h_i,h_j))=\frac{exp(F(h_i,h_j))}{\sum{_k}exp(F(h_i,h_k)}(2) aij=softmax(F(hi,hj))=∑kexp(F(hi,hk)exp(F(hi,hj))(2)
h i ′ = ∣ ∣ k = 1 K σ ( ∑ j a i j k ∗ W q k ∗ h j i ) ( 3 ) h_i^\prime=||^K_{k=1}\sigma(\sum_ja_{ij}^k*W_q^k*h_j^i)(3) hi′=∣∣k=1Kσ(j∑aijk∗Wqk∗hji)(3)
(1)式中 E i j E_{ij} Eij为边矩阵, j j j为节点 i i i的邻居;
(3)式表明此为K头注意力,经非线性激活后将输出拼接(||)
消息传递:
共经历5次更新:
V u → V b → V t → V b → V u → V b V_u \rightarrow V_b\rightarrow V_t\rightarrow V_b \rightarrow V_u\rightarrow V_b Vu→Vb→Vt→Vb→Vu→Vb
其中 V u V_u Vu包括utterance node, V b V_b Vb包括word node、speaker node、argument node, V t V_t Vt包括entity-type node
增加残差连接(residual connection)避免梯度消失:
h i ^ = h i ˉ + h i ′ ( 4 ) \hat{h_i}=\bar{h_i}+h_i^\prime(4) hi^=hiˉ+hi′(4)其中 h i ˉ \bar{h_i} hiˉ为图注意力层的输出, h i ′ h_i^\prime hi′为原始输入。
???在消息传递中,除了图注意力操作,还有两层前馈神经网络:
h i n e w = F F N ( h i ^ ) ( 5 ) h_i^{new}=FFN({\hat{h_i}}) (5) hinew=FFN(hi^)(5)
每次更新包括式子(1)-(5)的操作。
3.3关系分类
取第二阶段的参数节点 T x , T y T_x,T_y Tx,Ty,以及参数对应的单词节点 e x , e y e_x,e_y ex,ey。
e x ′ = [ m a x p o o l ( T x ) ; m a x p o o l ( e x ) ] e_x^\prime=[maxpool(T_x);maxpool(e_x)] ex′=[maxpool(Tx);maxpool(ex)]
e y ′ = [ m a x p o o l ( T y ) ; m a x p o o l ( e y ) ] e_y^\prime=[maxpool(T_y);maxpool(e_y)] ey′=[maxpool(Ty);maxpool(ey)]
e ′ = [ e x ′ ; e y ′ ] e^\prime=[e_x^\prime;e_y^\prime] e′=[ex′;ey′]
P ( r ∣ e x , e y ) = σ ( W e ∗ e ′ + b e ) r P(r|e_x,e_y)=\sigma(W_e*e^\prime+b_e)_r P(r∣ex,ey)=σ(We∗e′+be)r
4.实验
使用DialogRE数据集。
超参数设置如表1.

NER Embedding Dimension???
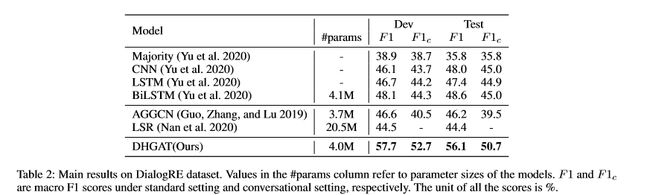
实验结果如表2.
Ablation Study(对照试验)如表3.

5.误差分析
实体类型影响输出???