7 Papers | 腾讯王者荣耀绝悟AI;ICLR高分论文Reformer
点击上方“深度学习技术前沿”,选择“星标”公众号
资源干货,第一时间送达
本周 7 Papers 包含多篇 AAAI 2020、ICLR 2020 入选论文,如腾讯 AI Lab 游戏 AI 研究、提高 Transformer 性能的研究等。
目录:
Mastering Complex Control in MOBA Games with Deep Reinforcement Learning
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
BackPACK: Packing more into backprop
Deep Audio Prior
REFORMER: THE EFFICIENT TRANSFORMER
TextTubes for Detecting Curved Text in the Wild
Joint Commonsense and Relation Reasoning for Image and Video Captioning
论文 1:Mastering Complex Control in MOBA Games with Deep Reinforcement Learning
作者:Deheng Ye、Zhao Liu、Mingfei Sun 等
论文链接:https://arxiv.org/abs/1912.09729
摘要:在本文中,来自腾讯人工智能实验室和天美工作室的研究者对多玩家在线竞技场(Multi-player Online Battle Arena,MOBA)1v1 游戏中复杂行动的强化学习问题进行了研究。与围棋和雅达利等传统 1v1 游戏相比,MOBA 1v1 游戏中玩家的状态和行动空间问题更加复杂,这导致很难开发出人类玩家级别的游戏策略。因此,研究者提出了一个深度强化学习框架,从系统和算法两方面来解决上述问题。系统具有低耦合度和高扩展性,因而可以实现大范围内的有效探索。算法包含几项新颖的策略,如控制依赖解耦(control dependency decoupling)、行动 mask、目标注意力和 dual-clip 近端策略优化(proximal policy optimization,PPO),从而使得提出的执行器-评估器(Actor-Critic)网络可以在系统中获得有效地训练。通过 MOBA 游戏《王者荣耀》的测试,训练的 AI 智能体可以在 1v1 游戏模式中击败顶尖职业玩家。
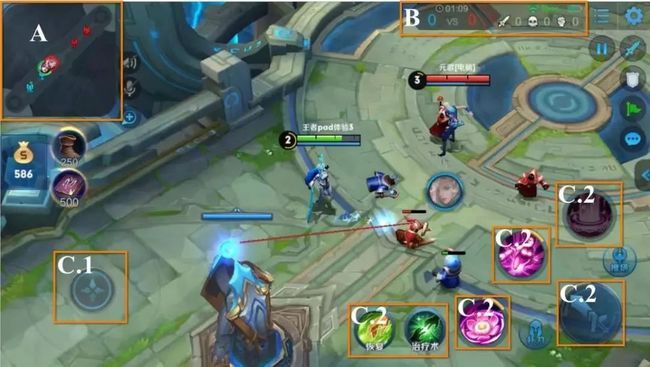
王者荣耀 1v1 游戏 UI 界面。在主屏幕中,左上角的 A 为小地图、右上角 B 为控制面板、左下角 C.1 为移动控制、右下角的 C.2 为技能控制。实验表明,AI 智能体能在多种不同类型的英雄上能击败顶级职业玩家。
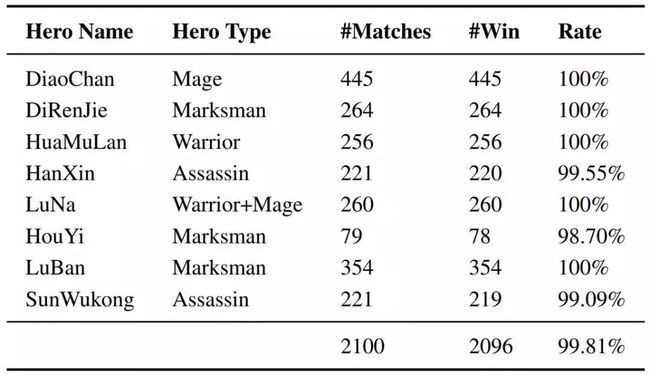
表 4:AI 与不同顶级人类玩家的比赛结果。
推荐:腾讯王者荣耀人工智能「绝悟」的论文入选 AAAI 2020。在研究测试中,AI 玩露娜和顶级选手单挑时也赢了个 3:0。
论文 2:PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
作者:Jingqing Zhang、Yao Zhao、Mohammad Saleh、Peter J. Liu
论文链接:https://arxiv.org/pdf/1912.08777.pdf
摘要:当在文本摘要等下游 NLP 任务上进行微调时,大规模文本语料库上具有自监督目的(self-supervised objective)的预训练 Transformer 取得了很大的成功。但是,尚未有研究涉及到专门针对抽象式文本摘要(abstractive text summarization)的预训练目的。此外,不同领域之间也缺少系统化评估。
因此,在本文中,来自帝国理工学院和谷歌大脑团队的研究者提出了大规模文本语料库上具有新的自监督目的的大型 Transformer 预训练编码器-解码器模型 PEGASUS(Pre-training with Extracted Gap-sentences for Abstractive Summarization)。与抽取式文本摘要(extractive summary)相似,在 PEGASUS 模型中,输入文档中删除或 mask 重要句子,并与剩余句子一起作为输出序列来生成。研究者在新闻、科学、故事、说明书、邮件、专利以及立法议案等 12 项文本摘要下游任务上测试了 PEGASUS 模型,结果表明该模型在全部 12 项下游任务数据集上取得了 SOTA 结果(以 ROUGE score 衡量)。此外,该模型在低资源(low-resource)文本摘要中也有非常良好的表现,在仅包含 1000 个示例的 6 个数据集上超越了以往的 SOTA 结果。

PEGASUS 的基础架构是一个标准的 Transformer 编码器-解码器。

在 12 个下游任务数据集上,PEGASUS_LARGE 和 PEGASUS_BASE 与以往 SOTA 的结果对比。
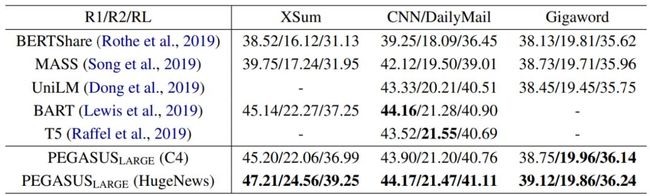
在 XSum、CNN/DailyMail 和 Gigaword 数据集上,PEGASUS_LARGE 与其他模型的结果对比。
推荐:研究者展示了预训练语料库、gap-sentence ratio 和词汇量对文本生成的影响,并证明提出的 PEGASUS 模型可以非常快速地适应未知的文本摘要数据集。
论文 3:BackPACK: Packing more into backprop
作者:Felix Dangel、Frederik Kunstner、Philipp Hennig
论文链接:https://arxiv.org/abs/1912.10985
摘要:自动微分框架只在计算平均小批量(mini-batch)梯度时进行优化。但在理论上,小批量梯度方差或 Hessian 矩阵近似值等其他数量可以作为梯度实现高效的计算。研究人员对这些数量抱有极大的兴趣,但目前的深度学习软件不支持自动计算。此外,手动执行这些数量非常麻烦,效率低,生成代码的共享性也不高。这种情况阻碍了深度学习的进展,并且导致梯度下降及其变体的研究范围变窄。与此同时,这种情况还使得复现研究以及新提出需要这些数量的方法之间的比较更为复杂。因此,为了解决这个问题,来自图宾根大学的研究者在本文中提出一种基于 PyTorch 的高效框架 BackPACK,该框架可以扩展反向传播算法,进而从一阶和二阶导数中提取额外信息。研究者对深度神经网络上额外数量的计算进行了基准测试,并提供了一个测试最近几种曲率估算优化的示例应用,最终证实了 BackPACK 的性能。

在真实网络上同时计算梯度和一阶或二阶扩展与单独计算梯度的开销基准对比。

第一版 BackPACK 框架支持的功能。
推荐:本文提出的 BackPACK 框架丰富了自动微分程序包的句法,从而为平均批量梯度下的优化器提供额外的可观察量。
论文 4:Deep Audio Prior
作者:Yapeng Tian、Chenliang Xu、Dingzeyu Li
论文链接:https://arxiv.org/abs/1912.10292
摘要:众所周知,深度卷积神经网络专门用于从大量数据中蒸馏出压缩和鲁棒的先验。在训练数据集缺失时,研究人员往往有兴趣运用深度网络。在本文中,来自罗切斯特大学和 Adobe Research 的研究者提出了一种深度音频先验框架(Deep Audio Prior,DAP),它在单个音频文件中利用到了网络结构和时态信息。具体而言,他们证明,一个随机初始化的神经网络可以与精心设计的音频先验一道使用,以解决盲源分离、交互式音频编辑、音频纹理合成以及音频同时分离等富有挑战性的音频问题。为了理解 DAP 的鲁棒性,研究者利用各种声源创建了一个用于声源分离的基准数据集 Universal-150。实验结果表明,与以往的研究工作相比,DAP 在定性和定量评估层面都取得了更好的音频效果。
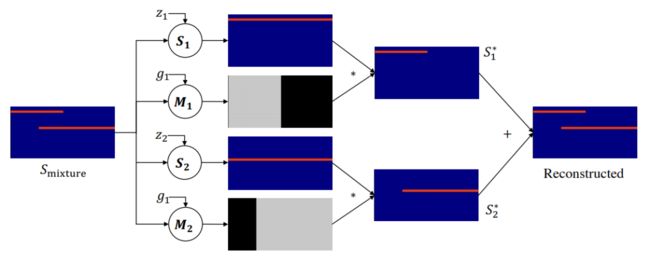
以合成声音混合光谱图表示的 DAP 框架。由于随机噪声作为输入,研究者利用了两个声音预测网络 S_1 和 S_2 以及两个 mask 模块化网络 M_1 和 M_2,以实现声源分离。
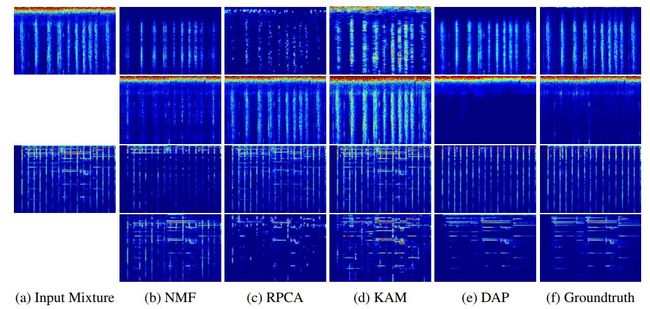
不同盲源分离方法在 Universal-150 基准上的音频效果对比。从定性上来看,DAP 的效果显著优于 NMF、RPCA、KAM 等方法。
推荐:本文提出的 DAP 框架要求零训练数据(Zero Training Data),并且得益于它的通用和无监督属性,该框架的潜在应用可以获得保证。
论文 5:REFORMER: THE EFFICIENT TRANSFORMER
作者:Nikita Kitaev、Lukasz Kaiser、Anselm Levskaya
论文链接:https://openreview.net/pdf?id=rkgNKkHtvB
摘要:大型的 Transformer 往往可以在许多任务上实现 sota,但训练这些模型的成本很高,尤其是在序列较长的时候。在 ICLR 的入选论文中,我们发现了一篇由谷歌和伯克利研究者发表的优质论文。文章介绍了两种提高 Transformer 效率的技术,最终的 Reformer 模型和 Transformer 模型在性能上表现相似,并且在长序列中拥有更高的存储效率和更快的速度。论文最终获得了「8,8,6」的高分。在最开始,文章提出了将点乘注意力(dot-product attention)替换为一个使用局部敏感哈希(locality-sensitive hashing)的点乘注意力,将复杂度从 O(L2 ) 变为 O(L log L),此处 L 指序列的长度。此外,研究者使用可逆残差(reversible residual layers)代替标准残差(standard residuals),这使得存储在训练过程中仅激活一次,而不是 n 次(此处 n 指层数)。最终的 Reformer 模型和 Transformer 模型在性能上表现相同,同时在长序列中拥有更高的存储效率和更快的速度。
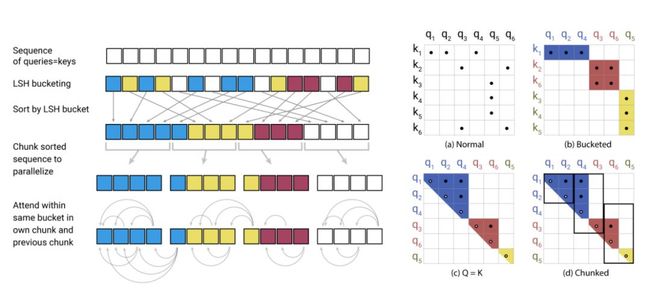
简化的局部敏感哈希注意力,展示了 hash-bucketing、排序和分块步骤,并最终实现注意力机制。
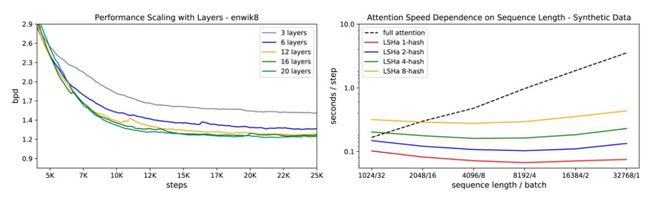
图左:在 enwik8 上 LSH 注意力随层数增加的性能变化曲线;图右:全注意力和 LSH 注意力的评估速度呈现出不同的曲线变化。
推荐:Transformer 是近期 NLP 领域里的经典模型,但因为算力消耗过大,对于个人研究者来说一直不太友好。近日一篇入选 ICLR 2020 的研究提出了「Reformer」,把跑 Transformer 模型的硬件要求压缩到了只需一块 GPU,同时效果不变。
论文 6:TextTubes for Detecting Curved Text in the Wild
作者:Joel Seytre、Jon Wu、Alessandro Achille
论文链接:https://arxiv.org/pdf/1912.08990.pdf
摘要:在本文中,亚马逊的三位研究者提出了一种用于自然图像中曲线文本的检测器 TextTubes。他们围绕场景文本实例(scene text instance)的中轴线,将它们作为 tube 进行建模,并提出了一个参数化不变(parametrization-invariant)的损失函数。研究者训练了一个两阶曲线文本检测器,并在曲线文本基准 CTW-1500 和 Total-Text 上评估。他们提出的检测器实现并甚而提升了 SOTA 性能,其中 CTW-1500 基准上的 F-score 提升了 8 个百分点。

研究者利用提出的模型和曲线文本检测器 TextTubes 做出的推理。现实生活中的物体通常包含嵌入式和弯曲的文本,检测这些文本往往会采取输出四边形的错误方法。

不同文本表示三种不同方法的文本检索结果对比。(a)为原始图像,(b)和(c)表示长方形和四边形的检索方法会产生重叠,并且在捕捉文本时往往将大量的背景噪声(background noise)作为文本信息,同时在一个特定的 box 中包含多个文本实例。(d)中绿色的为 ground truth 多边形,品红色的为多边形的中轴线,箭头表示 tube 的半径。
推荐:本文提出的 TextTubes 检测器对文本实例非常有效,并且也能够泛化至姿态估计等具有复杂但相关中轴线的其他任务。
论文 7:Joint Commonsense and Relation Reasoning for Image and Video Captioning
作者:Jingyi Hou、Xinxiao Wu、Xiaoxun Zhang 等
论文链接:https://wuxinxiao.github.io/assets/papers/2020/C-R_reasoning.pdf
摘要:本文对北京理工大学、阿里文娱摩酷实验室合作的论文《Joint Commonsense and Relation Reasoning for Image and Video Captioning》进行解读。在此论文中,研究者们提出了一种联合常识和关系推理的图像视频文本描述生成方法。该方法通过迭代学习算法实现,交替执行以下两种推理方式:(1) 常识推理,将视觉区域根据常识推理,嵌入到语义空间中从而构成语义图;(2) 关系推理,将语义图通过图神经网络编码,生成图像视频文字描述。
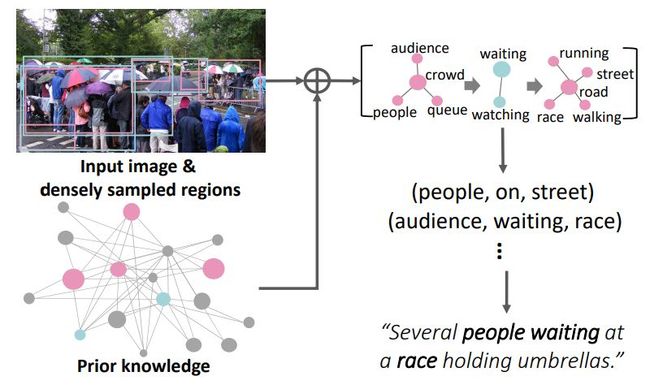
基于常识推理的图像视频文字描述生成示例图。
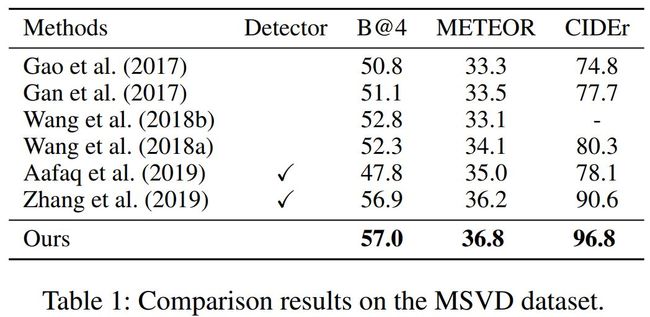
MSVD 数据集上各方法的对比结果。

MSCOCO 数据集上各方法的对比结果。
推荐:本文提出的方法利用先验知识交替迭代执行常识推理和关系推理,生成语义图来学习物体之间的语义关系,从而准确描述图像视频的内容。在图像和视频数据集上的实验表明,该方法优于其他最新方法。