多测师肖sir_高级讲师_第2个月第6讲python之模块(001)

一个项目中有很多个包,目录不能导入
包是有_init_.py 文件





备注:
1、未调用时,显灰色
2、一个模块中只要导入一次就可以
模块的导入方法一:
格式: import +模块名
import time # 导入time模块
print(‘dcs杭州大佬!!’)
time.sleep(5)
print (‘多测师都是万元户’)

模块导入方法二:
from 包名.模块名称 import +指定的类、函数、方法(指定具体的一个类或方法)
案例:
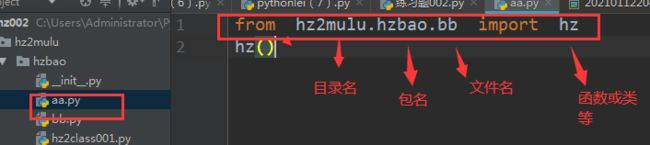
场景一:bb模块中定义一个函数hz, aa文件来调用bb文件中函数hz
aa文件如下:
bb文件如下:

模块导入方法三:from 包名.模块名称 import +*( * 星号所有的意思)
场景一:不使用*情况;bb文件中有两个函数hz,hz02,hz03在aa文件调用函数hz, hz02,hz03函数无法运行。
bb文件
aa文件

场景二:ss 文件使用 * 能调用bb文件可以全部函数
bb文件

aa文件

场景三:使用别名去读取。
格式 from 模块名 import 函数名 as 别名
案例1:
aa文件:
from hz2mulu.hzbao.bb import hz as s
s()

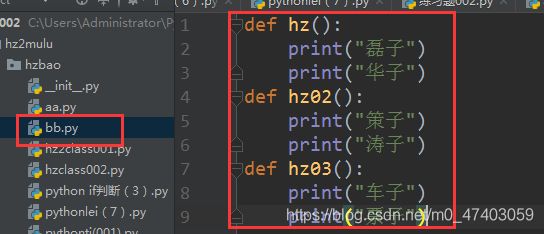
bb文件:
def hz():
print(“磊子”)
print(“华子”)
def hz02():
print(“策子”)
print(“涛子”)
def hz03():
print(“车子”)
print(“票子”)
案例2:模块之间使用别名的调用
time 模块
场景一: time() #1970到现在的经过的秒数
场景1.1:
import time #导入time模块
#time() #1970到现在的经过的秒数
print(time.time()) # 打印结果:1599531503.0335734
场景1.2:
from time import * #导入time模块
rint(time()) #打印结果:1599531503.0335734
场景二:ctime 固定格式的当前时间
场景2.1:
from time import * #导入time模块
print(ctime()) 打印结果: Tue Nov 24 20:49:22 2020
场景2.2:
import time #导入time模块
print(time.ctime()) #打印结果:Tue Nov 24 20:48:05 2020
场景三:sleep (秒数) 休眠 单位
场景3.1:
import time #导入time模块
print(“杭州多测师”)
time.sleep(3)
print(“杭州多测师”)
场景3.2:
#from time import * #导入time模块
print(“杭州多测师”)
sleep(3)
print(“多测师”
场景四:asctime转换为asc码显示当前时间
场景4.1
from time import * #导入time模块
print(asctime()) # 打印结果:Tue Nov 24 21:08:50 2020
场景4.2
import time #导入time模块
print(time.ctime()) #打印结果:Tue Nov 24 21:08:50 2020
场景五:strftime 时间格式化
场景5.1
#import time #导入time模块
#print(time.strftime(’%Y-%m-%d-%H-%M-%S’))
打印结果:2020-11-24-21-22-27
场景5.2
from time import * #导入time模块
print(strftime("%H-%M-%S-%Y-%m-%d")
")) 打印时间:2020-11-24-21-23-33

random 模块
import random #导入random模块
场景1:random 随机生成0开头的浮点数 #:如0.7994286057106206
print(random.random())
场景2:randint 在指定范围内随机一位
print(random.randint(1,5)) #随机取一位 取值的位数包含开始位 会重复

场景3:randrange# ,只取一个值,返回指定递增基数集合中的一个随机数,基数默认值为1。
print(random.randrange(1,100,2)) #打印结果:87
根据range函数:(起始,结束,隔位) 我们只取一个;
场景4:#指定生成偶数,只取一个值 print(random.randrange(0,100,2)) #打印结果:96

场景5: sample 列表中随机取自己定义的个数的值
案例1:
a=[1,2,3,4,5,6,7,8,9,10]#定义一个列表
print(random.sample(l,4))
案例2:
a=[1,2,3,4,5,“a”,“b”,“c”,“d”,“e”]
print(random.sample(a,4))

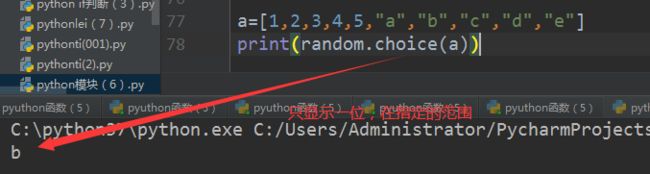
场景6:choice在当前列表中随机取一个值
a =[1,2,3,4,5]
print(random.choice(a)) 打印结果:一个值
场景7:随机取洗牌把列表中的值无规律的输出
a =[1,2,3,4,5,6]
random.shuffle(a)
print(a)
打印结果:[6, 2, 3, 1, 5, 4]
备注:shuffle 先洗牌,在打印
总结下:
random 随机生成0开头的小数
randint 指定范围内取值
randrange 递增随机取值
sample 抽样
choice 随机取一个
shuffle 洗牌

string 模块
#场景一:digits #生成0-9的整数
import string
print(string.digits) #0123456789
#场景二:hexdigits #生成0-9的整数+大小写的a-f和A-F’’’
print(string.hexdigits)#0123456789abcdefABCDEF
#场景三:ascii_uppercase #生成26个大写字母
print(string.ascii_uppercase) #ABCDEFGHIJKLMNOPQRSTUVWXYZ
#场景四:ascii_lowercase #生成26个小写字母
print(string.ascii_lowercase) #abcdefghijklmnopqrstuvwxyz
#不同的导入方法一也可以
from string import *
#print (digits)
练习题:
#1、使用random模块随机生成手机号码、自己定义手机号码开头为1
#2、用random模块随机生成6位数验证码’’’
练习1:
方法一:
from random import *
import string
num=string.digits
d=[“1”,]
for i in range(10):
a=choice(num)
d.append(a)
print(’’.join(d))
方法二:
from random import *
from string import *
a=digits
b=sample(a,8)
b=’’.join(b)
c=input(‘请输入手机号开始3位:’)
print(c+b)

方法三:
from random import *
import string
def fun():
d=[ ]
num=string.digits
for i in range(10):
a=choice(num)
d.append(a)
print(“1”+"".join(d))
fun() 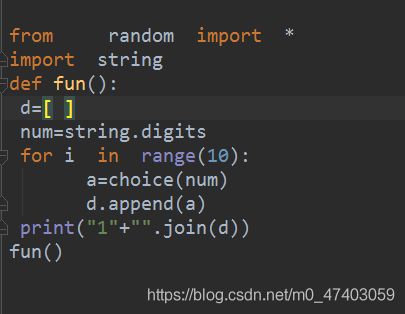
方法四:
import random
for i in range(1):
print(‘1’+’’.join( str(random.choice(‘0123456789’)) for i in range(10) ))
练习2:验证码6位数字+大小写字母
方法一:
import random
import string
def fun():
d=[]
num=string.digits+string.ascii_uppercase+string.ascii_lowercase
for i in range(6):
a=random.choice(num)
d.append(a)
print("".join(d))
fun()
方法二:
import random
import string
num=string.digits+string.ascii_uppercase+string.ascii_lowercase
#print(num)
a=random.sample(num,6)
print("".join(a))
方法三:
import random
for i in range(1):
print(’’.join( str(random.choice(‘abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789’)) for i in range(6) ))
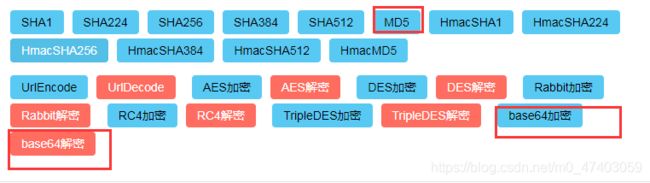
加密算法:
MD5 ,RSA,AES,DES,BASE
DES以64位为分组对数据加密,加密和解密用的是同一个算法.
RSA加密算法是一种非对称加密算法(在公开密钥加密和电子商业中RSA被广泛使用)
AES Rijndael加密法对称密钥加密中最流行的算法之一 (AES为分组密码)。
DES 算法为密码体制中的对称密码体制,(DES以64位为分组对数据加密,加密和解密用的是同一个算法.)
base64 编码
常见的加密方法:
Base64编码
Base64编码是一种用64个字符来表示任意二进制数据的方法
base64是python内置的模块可以直接进行base64的编码和解码
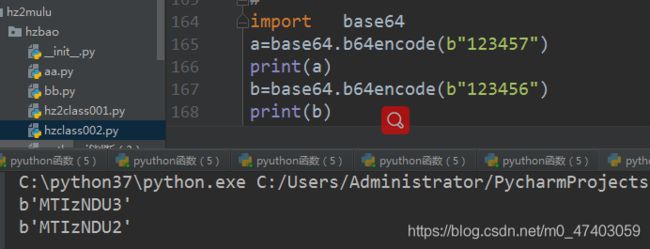
import base64
a=base64.b64encode(b"123456")
print (a)
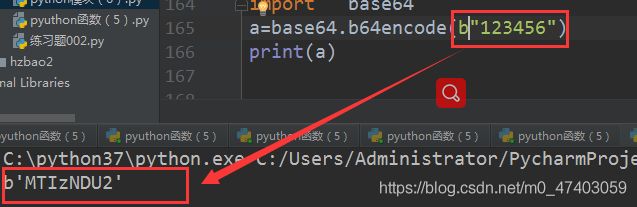
#编码
import base64
b=base64.b64encode(b"hello word")
print (b)
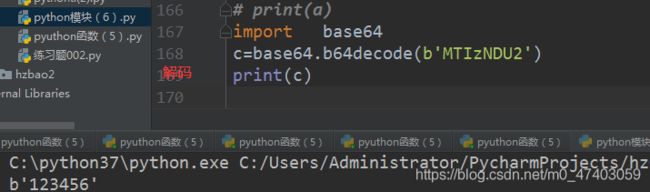
#解码
c=base64.b64decode(b’aGVsbG8gIHdvcmQ=’)
print ©
注意:base64编码 一、ASCII是包含的字符,二是二进制数据
DM5加密
MD5 定义:md5,是一种算法.可以将一个字符串,或文件,或压缩包,执行md5后,就可以生成一个固定长度为128bit的串,这个串,基本上是唯一的
由因为MD5模块在python3中被移除,在python3中使用hashlib模块进行md5操作
Hash,译做“散列”,也有直接音译为“哈希”的。把任意长度的输入,通过某种hash算法,
变换成固定长度的输出,该输出就是散列值,也称摘要值。该算法就是哈希函数,也称摘要函数。
MD5是最常见的摘要算法,速度很快,生成结果是固定的16字节,通常用一个32位的16进制字符串表示。
SHA1算法更安全点,它的结果是20字节长度,通常用一个40位的16进制字符串表示。
而比SHA1更安全的算法是SHA256和SHA512等等,不过越安全的算法越慢,并且摘要长度更长。
在线加解密:
http://encode.chahuo.com/
https://tool.oschina.net/encrypt?type=2
hash.digest() 返回摘要,作为二进制数据字符串值,
hash.hexdigest() 返回摘要,作为十六进制数据字符串值,
hash.copy() 复制
hashlib主要提供字符加密功能,将md5和sha模块整合到了一起;
支持md5,sha1, sha224, sha256, sha384, sha512等算法。
场景一:
import hashlib #导入hashlib模块
md5 =hashlib.md5() #创建一个对象:md5
md5.update(b’123456’) #通过md5对象来调用update方法对某个值进行加密处理
print(md5.hexdigest()) #通过hexdigest将md5加密密码进行十六进制转换输出
hexdigest() #十六进制转换方法
如果直接使用
print(md5) #变成了对象形式
注意:
1、在Python3中需要加上一个:b 在Python2中不需要
2、hash = hashlib.md5() # md5对象,md5不能反解,但是加密是固定的,就是关系是一一对应,所以有缺陷,可以被对撞出来


场景二: import hashlib #导入hashlib模块
#一个通用的构造方法,name是某种算法的字符串名称,data是可选的bytes类型待摘要的数据。
hashlib.new(name[, data])
例子2.1: print(hashlib.md5(b’123456’).hexdigest())
#32位加密方法:e10adc3949ba59abbe56e057f20f883e

例子2.2:sha256 32位的加密方式
#SHA256是安全散列算法SHA系列算法之一,摘要长度为256bits,即32个字节,故称SHA256
h = hashlib.new(‘sha256’,b"123456") print (h.hexdigest())

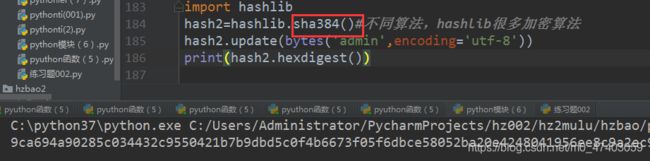
例子2.3 sha384
import hashlib
hash2=hashlib.sha384()#不同算法,hashlib很多加密算法
hash2.update(bytes(‘admin’,encoding=‘utf-8’))
print(hash2.hexdigest())
拓展:
面试题目:
如果当前表中有两个数据此数据都是十万行,如何让当前两行的数据一样
#通过md5来对这两个数据进行加密处理那么当前的数据就能一致
通过加密,如果不一致,那么加密的编码不同。
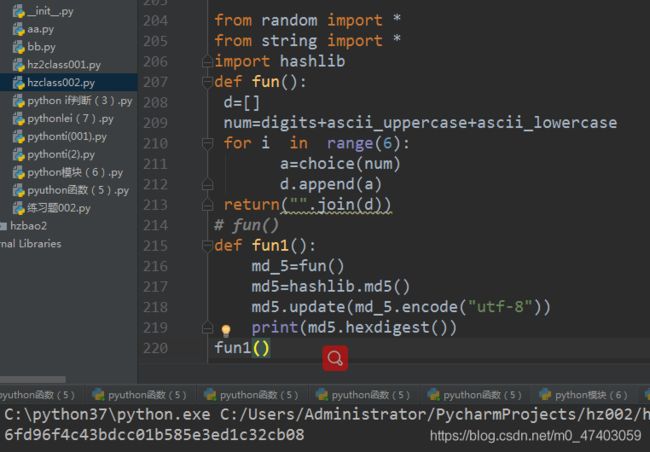
1、练习:
通过md5加密算法把随机生成的6位数验证码进行加密返回16进制的字符串
方法一:
from random import *
from string import *
import hashlib
def fun():
d=[]
num=digits+ascii_uppercase+ascii_lowercase
for i in range(6):
a=choice(num)
d.append(a)
return("".join(d))
fun()
def fun1():
md_5=fun()
md5=hashlib.md5()
md5.update(md_5.encode(“utf-8”))
print(md5.hexdigest())
fun1()
方法二:
from random import *
from string import *
from hashlib import*
num=list(digits+ascii_lowercase+ascii_uppercase)
a=’’.join(sample(num,6))
print(a)
b=md5()
b.update(a.encode(‘utf-8’))
print(b.hexdigest())

os模块
os 模块对于目录,文件路径常用的模块
总:先导入os模块(import os )
场景一:getcwd()获取当前操作文件它对应路径(相对路径)
场景一:getcwd()获取当前操作文件它对应路径
print(os.getcwd())
#打印结果:C:\Users\Administrator\PycharmProjects\hz002\hz2mulu\hzbao

场景二:os.path.isfile()#:判断当前是否为文件,返回布尔值是文件则True否者Fals
a_path=‘F:\aa.rar’ #lesson包
b_path=’ F:\linux’#目录
c_path='C:\Users\Administrator\PycharmProjects\untitled\python\005之模块.py ’ # 当前的项目包
d_path='D:\bao\sql.txt ’ #text文件
e_path=‘F:\dcs\DCS课程安排\second\第二个月课程\第1天html\老肖\js\index.html’ #html文件
print(os.path.isfile(a_path)) #ture
print(os.path.isfile(b_path)) #false 目录不是file
print(os.path.isfile(c_path)) # ture .py文件是file
print(os.path.isfile(d_path)) #ture .txt 文件是file
print(os.path.isfile(e_path)) #True .html 后缀是file
总结:
file: .py,.txt,.html,.doc ,.rar压缩包
不是file: 本地目录名(文件夹),python的包,pyhton的目录
场景三:exists 判断文件是否存在
3.1判断是否存在的文件夹
3.1.1 判断目录存在的情况
#import os #导入os模块
dir = os.path.exists(‘C:\Users\Default’)#存在的目录
#print(‘dir:’, dir)
#打印结果:dir: True
3.1.2判断目录不存在的情况
import os #导入os模块
dir1= os.path.exists(‘C:\Users\Defaultaaa’)#存在的文件
print(‘dir:’, dir1)
3.2判断文件
3.2.1判断文件存在
file = os.path.exists(‘D:\sql.txt’)#不存在的文件
print(‘file:’, file)
#打印结果:file: True
3.2.2判断文件不存在
#file = os.path.exists(‘D:\sql.txt’)#不存在的文件
#print(‘file:’, file)
#打印结果:file: False
备注:existe 可以判断文件,也可以判断目录
******判断目录,并哦谈过mkdir创建
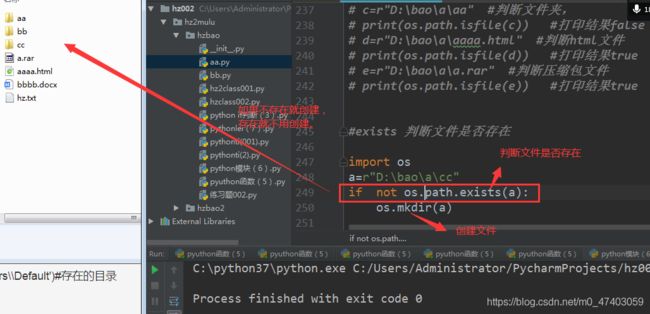
3.3 判断文件是否存在,不存在则创建 通过mkdir创建(exists,mkdir)
3.3.1
import os
import os
a=r"D:\bao\a\cc"
if not os.path.exists(a):
os.mkdir(a)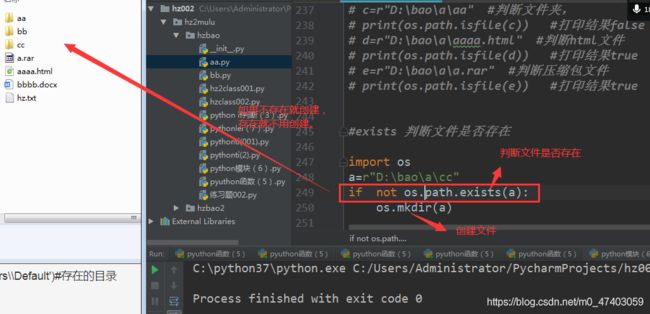
备注:*****判断文档,通过exists ,直接创建并用 open 以及wirt写入等
3.3.2判断文件是否存在,不存在则创建 ,创建以后再追加或覆盖
import os
import codecs
#codecs专门用作编码转换,当我们要做编码转换的时候可以借助codecs很简单的进行编码转换
判断文件是否存在,不存在则创建,创建以后再追加或覆盖
import os
import codecs
file1 = ‘D:\bao\a\vvv.txt’
if not os.path.exists(file1): #w是覆盖,a是追加,a+,w+是如不存在就创建
os.mkdir(“vvv.txt”)
with codecs.open(file1,‘a’,encoding=‘utf-8’) as f:
f.write(“bbbbb”)

场景四:os.remove() #删除
4.1成功移除.py的文件
a_path=r’D:\bao\dd.py’ #.py文件
os.remove(a_path) #成功移除.py的文件
4.2成功移除html文件
b_path=r’D:\bao\bb.html’ #html文件
os.remove(b_path) #成功移除html文件
4.3成功移除docx文件
import os
#c_path=r’D:\bao\ss.docx’#docx文件
#os.remove(c_path) #成功移除docx文件,
4.4无法删除目录
#d_path=r’D:\bao\dd’ #目录
os.remove(d_path)#移除目录 #注意目录是指dd ,无法删除
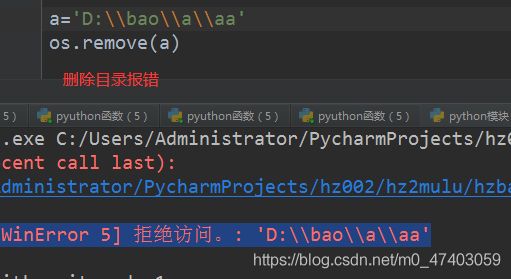
4.5成功删除压缩包
l_path=r’D:\bao\aa.rar’#压缩包
os.remove(l_path) #移除包 #删除成功
在os模块中对应remove可以移除文件,
场景五:isdir() #判断是否为目录 #以布尔值的方式返回
#5.1判断不是目录的文件,返回false
import os
d_path=‘D:\bao\bb.txt’ #txt文件
print(os.path.isdir(d_path))#txt文件 False
5.2判断是目录的文件,返回ture
import os
e_path=‘D:\bao\多测师’ #html文件
print(os.path.isdir(l_path)) #目录 True
场景六:listdir 获取当前路径下的所有的目录和文件
import os
a_path=‘D:\bao’ #lesson包
print(os.listdir(a_path))
打印结果:[‘aa.docx’, ‘bao.rar’, ‘bb.html’, ‘bb.txt’, ‘cc.html’, ‘py.py’, ‘多测师’]
场景七:
a=“D:\bao\a\aa”
print(os.path.isdir(a))
b=“D:\bao\a\hz.txt”
print(os.path.isdir(b))
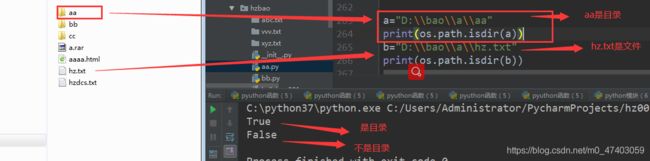
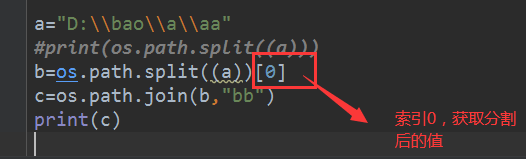
场景七:os.path.split():对某个路径进行分割,目录和文件
要求:把路径分隔以后,再通过索引取出分隔后的值,在使用得到的值进行拼接,拼接成新的路劲
import os 导入os模块
#第一步先使用split分割
a_path =“D:\bao”
print(os.path.split(a_path))
#第二步在根据索引取值
path=os.path.split(a_path)[0]
#第三步在拼接
b_path=os.path.join(path,11.py)
print(b_path)
场景八:abspath通过名称来获取当前名称对应的路径
8.1根据一个文件名获取绝对路径
案例1:
a_path=“ss.py”
print(os.path.abspath(a_path))
案例2:
print(os.path.abspath(“aa.py”))

场景九:mkdir 创建一个目录
a_path=‘D:/bao/hzdcs11’ 新建的目录绝对路径和目录名
os.mkdir(m_path, 755)#打印结果: ‘D:/bao/hzdcs11’
注意点:目录要设置权限,777或755

场景十:rename 重命名目录和文件
案例1
#os.rename() #更改目录的名称
old_path=‘D:\bao\ee’ #原目录名
new_path=‘D:\bao\oo’ #新目录名
os.rename(old_path,new_path) #kk的目录换成oo 注意路径的转义
案例2:
os.rename(“D:\bao\a\ss”,“D:\bao\a\ff”)
#固定格式如下:
场景一: 获取到当前操作对象中它的一个项目的绝对路径固定语法
a_path=os.path.abspath(os.path.dirname(os.getcwd()))
print(a_path)
场景二:
2.1获取到当前文件的绝对路径,直接通过 split对目录和文件进行了分割
file_path=os.path.split(os.path.realpath(file))
print(file_path)
2.2获取到当前文件的绝对路径,直接通过 split对目录和文件进行了分割,只取目录
file_path=os.path.split(os.path.realpath(file))[0]
print(file_path)
2.3获取到当前文件的绝对路径,直接通过 split对目录和文件进行了分割,只取文件
file_path=os.path.split(os.path.realpath(file))[1]
print(file_path)
重点:
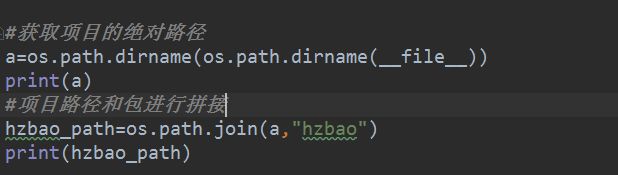
#获取项目的绝对路径
a=os.path.dirname(os.path.dirname(file))
print(a)
#项目路径和包进行拼接
hzbao_path=os.path.join(a,“hzbao”)
print(hzbao_path)
===============================================================
re 模块:
正则匹配:使用re模块实现
1、什么正则表达式?
正则表达式是一种对字符和特殊字符操作的一种逻辑公式,从特定的字符中,用正则表达字符串来过滤的逻辑。
基本介绍:(1)正则表达式是一种文本模式;
(2)帮助我们检查字符是否与某种模式匹配
(3)re模块使python语言拥有全部的真正表达式功能,从python1.5版本起增加了re模块
2、正则表达式作用?
(1)快速高效的查找和分析字符串 比对字符,也叫模式匹配;具有查找,比对,匹配,替换,插入,添加,删除等能力
案例一:把一个字符中的所有数字匹配出来,\d findall
案例二:编写爬虫收集数据,首先得到网页源码,(比如html),要提取有效数据(比如img字符),使用正则匹配出来;
(2)实现一个编译查找,一般在日处理文件处理时用的多
3、认识我们正则表达式中特殊元素?
re模块数量词匹配:
预定义字符集匹配:
\d:数字0-9
\D:非数字
\s:空白字符
\n:换行符
\w 匹配字母数字
\W 匹配非字母数字
^:表示的匹配字符以什么开头
$:表示的匹配字符以什么结尾
:匹配前面的字符0次或n次 eg:ab (* 能匹配a 匹配ab 匹配abb )
+:匹配+前面的字符1次或n次
?:匹配?前面的字符0次或1次
{m}:匹配前一个字符m次
{m,n}:匹配前一个字符m到n次(包括n次),m或n可以省略,mn都是
#1、findall # 从第一个字符开始查找,找到全部相关匹配为止,找不到返回一个空列表[] #
#2、match
#从第一个字符开始匹配,如果第一个字符不是要匹配的类型、则匹配失败并报错
注意:如果规则带了’+’,则匹配1次或者多次,无’+'只匹配一次
3、compile # 编译模式生成对象,找到全部相关匹配为止,找不到返回一个列表[]
4、search
#从第一个字符开始查找、一找到就返回第一个字符串,找到就不往下找,找不到则报错
案例展示:
第一步:导入re模块
import re 导入re模块
#re查找的相关方法
场景一: findall
#1.1 findall查找字符存在,显示字符
a = re.findall(“m”, “bmcmdm1m3mm”)
#print(a) #打印结果:[‘m’, ‘m’, ‘m’, ‘m’, ‘m’, ‘m’]

1.2 findall查找字符不存在,返回空列表
import re
a=“abcdef$1gadb2vfhge”
b=re.findall(“x”,a)
print(b)
print("".join(b))

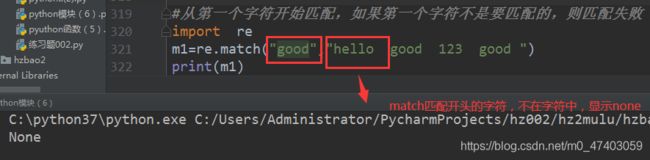
场景二:match 匹配开头
m1 = re.match(“good”, “hello good 123 good”)
#print(m1) #打印结果:none
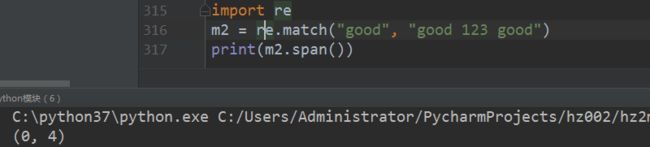
#m2 = re.match(“good”, “good 123 good”)
#print(m2.span) #打印结果:

group 以str形式返回对象中match的元素
start 返回开始位置
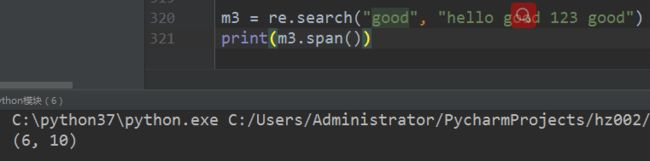
场景三:search 匹配第一个
案例1`:
import re
m3 = re.search(“good”, “hello good 123 good”) #调换位置,good不在第一
print(m3.span()) #打印结果:

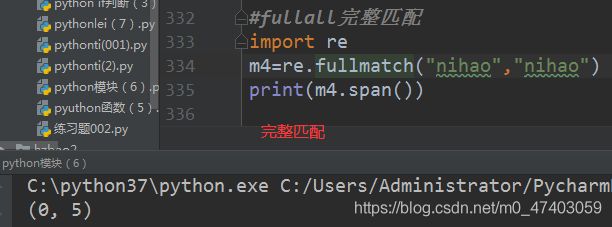
场景四:fullmatch完整匹配
4.1案例fullmath 匹配一个整体字符
m4 = re.fullmatch(“hello word”, “hello word”)
print(m4) #打印结果:
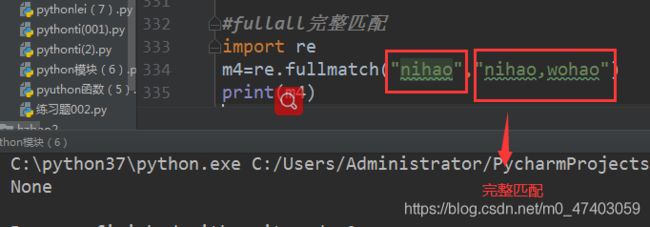
4.2 案例 fullmath 匹配字符不是整体,返回的结果是none
import re
m4=re.fullmatch(“nihao”,“nihao,wohao”)
print(m4)
4.3案例 :使用字符 .* 所用 ,h.*d
m5 = re.fullmatch(“h.*d”, “hello word”)
print(m5) #打印结果:

场景五:finditer 返回的结果是一个迭代对象(了解)
可迭代对象里的数据是匹配到的所有结果,是一个re.Match对象
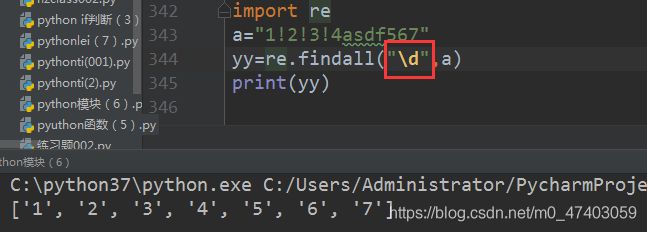
#场景一:\d表示0-9的数字
a=“1!2!3!4asdf567”
yy =re.findall("\d",a) # \d表示0-9的数字
print(yy)
#打印结果:[‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’]
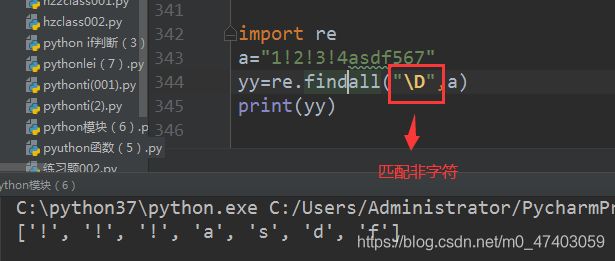
#场景二: #非数字
y2=re.findall("\D" ,a) #非数字
print(y2) #打印结果:[’!’, ‘!’, ‘!’, ‘a’, ‘s’, ‘d’, ‘f’]
场景三:\s 空白字符
a=“1!2!3!4 asdf5 67” #有两个空格
s =re.findall("\s",a) # \d表示0-9的数字
print(s) # 打印结果:[’ ', ’ ']

场景四:\n
3.1 re.S 使 . 匹配包括换行在内的所有字符
m = re.search(“m.*5”, “324mfafae\n54321432”, flags=re.S)
print(m) #
场景一:符号^:表示的匹配字符以什么开头
1.1 匹配字符是以a开头
import re
a=“abcd1”
c=re.match("^a",a)
print©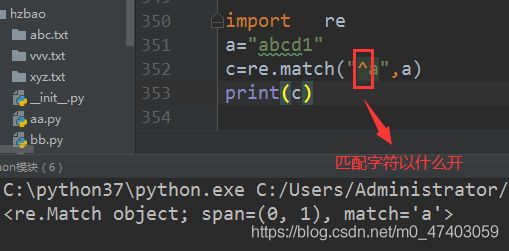
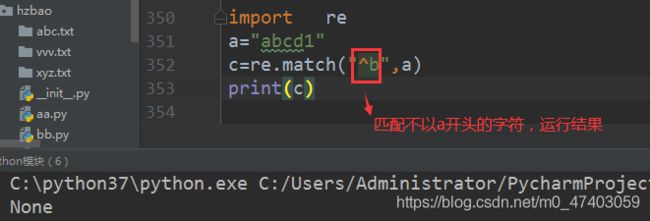
1.2 匹配字符不是以a开头
案例1:
import re
a=“abcd1”
c=re.match("^b",a)
print©
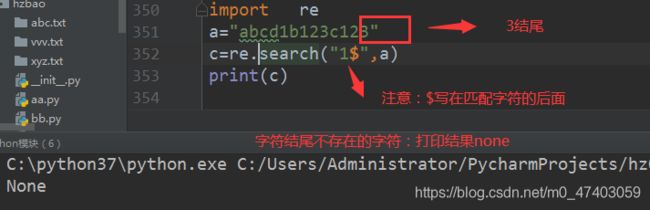
场景二符号$:表示的匹配字符以什么结尾
备注:使用search去匹配
2.1 不 存 在 的 情 况 下 , 返 回 结 果 n o n e i m p o r t r e a = " a b c d 1 b 123 c 123 " c = r e . s e a r c h ( " 1 不存在的情况下,返回结果none import re a="abcd1b123c123" c=re.search("1 不存在的情况下,返回结果noneimportrea="abcd1b123c123"c=re.search("1",a)
print©
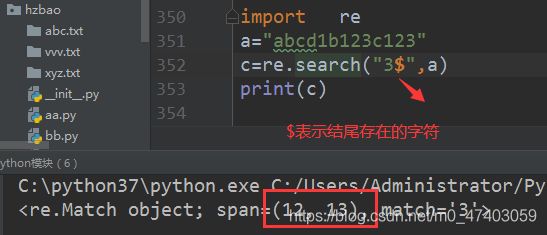
2.2 存 在 某 个 字 符 结 尾 的 情 况 , i m p o r t r e a = " a b c d 1 b 123 c 123 " c = r e . s e a r c h ( " 3 存在某个字符结尾的情况, import re a="abcd1b123c123" c=re.search("3 存在某个字符结尾的情况,importrea="abcd1b123c123"c=re.search("3",a)
print© :打印结果
场景三:符号*:匹配前面的字符0次或n次(?????)
案例1:
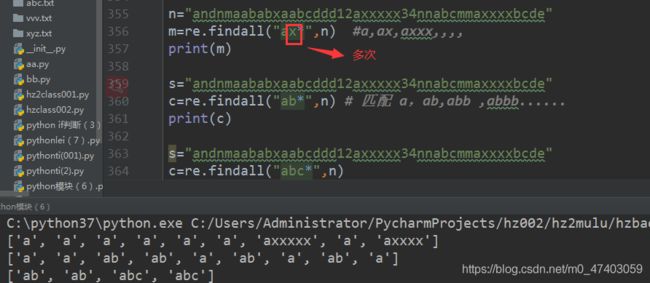
备注:匹配 前面第一个字符, 其他字符为一个整体匹配
n=“andnmaababxaabcddd12axxxxx34nnabcmmaxxxxbcde”
m=re.findall("ax",n) #a,ax,axxx,
print(m)
结果:[‘a’, ‘a’, ‘a’, ‘ax’, ‘a’, ‘a’, ‘axxxxx’, ‘axxxx’]
案例2
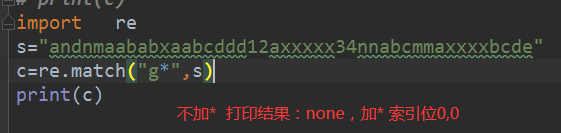
没有匹配到
import re
s=“andnmaababxaabcddd12axxxxx34nnabcmmaxxxxbcde”
c=re.match("g",s)
print©
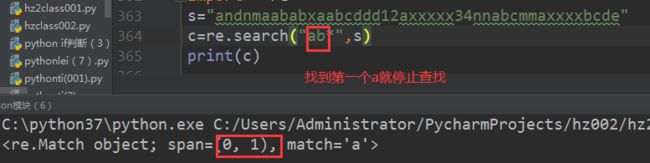
案例3
import re
s=“andnmaababxaabcddd12axxxxx34nnabcmmaxxxxbcde”
c=re.search(“ab*”,s)
print©
案例4:
print(re.search(‘a*’,‘aaaabac’).group()) # aaaa
ab* 能匹配a 匹配ab 匹配abb

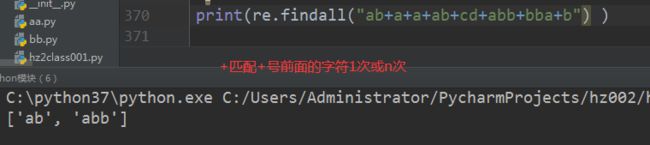
场景四:符号+:匹配+前面的字符1次或n次
print(re.findall(“ab+”,“ab+cd+abb+bba”) ) # [‘ab’, ‘abb’]
print(re.findall(‘ab+’,‘aabadfbab’)) # [‘ab’, ‘ab’]
场景五:符号?:匹配?前面的字符0次或1次
5.1
n=“andnmaababxaabcddd12axxxxx34nnabbcmmaxxxxbcde”
m=re.findall(“abc?”,n)
print(m)
打印结果:
[‘ab’, ‘ab’, ‘abc’, ‘ab’]
print(re.search(‘a?’,‘alaex’).group()) # a
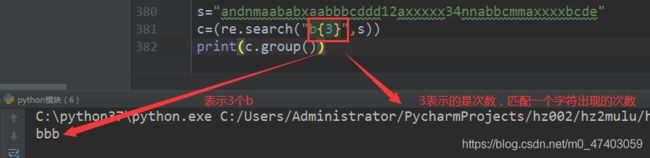
场景六:符号{m}:匹配前一个字符m次
s=“andnmaababxaabbbcddd12axxxxx34nnabbcmmaxxxxbcde”
c=(re.search(“b{3}”,s))
print(c.group())
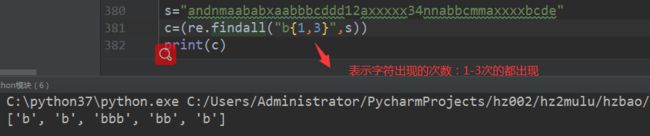
场景七:符号{m,n}:匹配前一个字符m到n次(包括n次),m或n可以省略,mn都是
print(re.findall(“ab{1,3}”,“abb abc abbcbbb”)) # [‘abb’, ‘ab’, ‘abb’]
备注:{} 用来限定出现的次数
#{N} 匹配前面紧跟字符精确到N次 [1-9][0-9]{2},匹配100到999的整数,{2}表示[0-9]匹配两个数字
{N,} 匹配前面紧跟字符最少N次
{N,M} 匹配前面紧跟字符的至少N次,最多M次 [0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3},匹配IP地址,其中.号是特殊字符,需要使用转义字符
#备注:匹配{}前的字符,{}内的数字就是匹配字符前一个数字的次数
拓展知识一:
#dir()内置方法可以查看对象有什么方法
#print(dir(m1)) #打印出方法:endpos,end,group,span
[‘class’, ‘copy’, ‘deepcopy’, ‘delattr’, ‘dir’, ‘doc’, ‘eq’, ‘format’, ‘ge’, ‘getattribute’, ‘getitem’, ‘gt’, ‘hash’, ‘init’, ‘init_subclass’, ‘le’, ‘lt’, ‘ne’, ‘new’, ‘reduce’, ‘reduce_ex’, ‘repr’, ‘setattr’, ‘sizeof’, ‘str’, ‘subclasshook’, ‘end’, ‘endpos’, ‘expand’, ‘group’, ‘groupdict’, ‘groups’, ‘lastgroup’, ‘lastindex’, ‘pos’, ‘re’, ‘regs’, ‘span’, ‘start’, ‘string’]
#我们就讲 span()和group
#print(m1.pos, m1.endpos) # pos 开始索引 endpos结束索引 取头不取尾
print(m1.span()) # 开始下标 和结束下标 取头不取尾 类似切片
##使用group()匹配字符串的结果
print(m1.group()) #打印结果xp
group方法表示正则表达式的分组
#1.在正则表达式里使用()表示一个分组
#2.如果没有分组,默认只有一组
#3.分组的下标从0开始
4、0表示整个组
#正则表达式有四个分组
m2 = re.search("(a9.)(8.)(3.*)", “a91a,8o,3pp”)
#print(m2.group()) # “a91a,8o,3pp” 匹配所有,把整个正则表达式当着一个整体
#print(m2.group(0)) # 第0组, 同group()
#print(m2.group(1)) # a91a, 第2组
#print(m2.group(2)) # 8o, 第3组
#print(m2.group(3)) # 3pp 第4组
print(m2.group(4)) #报错 没有第5组
print(m2.groups()) # 匹配结果是一个元组 (‘a91a,’, ‘8o,’, ‘3pp’)
groupdict 获取到分组 组成的字典
print(m2.groupdict()) # 这里返回结果是一个{}
m3 = re.search(r"(?Pa9.)(?P8.)(3.*)", “a91a,8o,3pp”)
#print(m3.groupdict()) # {‘name’: ‘a91a,’, ‘key1’: ‘8o,’}
可以通过group(名字) 来取值
print(m3.group(“name”)) # a91a,
既然是一个字典就可以通过key拿到 value
print(m3.groupdict()[“key1”]) # 8o,
#备注:大写的p,<>后面不要空格
#-----可以通过分组名和分组的下标获取 匹配的值—
print(m3.group(“name”)) # a91a,
#print(m3.group(1)) # a91a,
#---------------------------------------------------------------------
拓展知识二:re.compile方法的使用
import re
#在re模块里,可以使用re.方法调用函数,还可以调用re.compile得到一个对象
m = re.search(r"m.*f", “24mfdafoo”)
print(m.group())
生成一个匹配规则
#r = re.compile(r"m.*f")
#m1= r.search(“24mfdafoo”)
print(m1.group())
拓展知识三:
标志匹配符
re.I 忽略大小写(常用)
re.L 做本地化识别(locale-aware)匹配(少用)
#re.M 多行匹配,能匹配到换行\n,影响 ^ 和 $
re.S 使 . 匹配包括换行在内的所有字符
#re.U 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
#re.X 该标志通过给予更灵活的格式,以便将正则表达式写得更易于理解。
备注:(1)re.后面的字符都是大写
(2)flags=re.s 可以省略flags
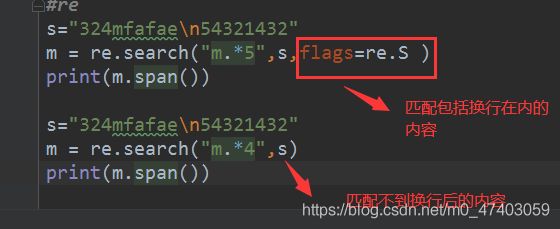
场景一. re.s 匹配任意一个字符包括\n换行符
m = re.search(“m.*5”, “324mfafae\n54321432”, flags=re.S)
print(m) #
场景2: re.I 忽略大小写(i)
n = re.search(“Xa”, “xA1”, re.I) # 忽略大小写(常用)
print(group.n) #打印结果:

场景3:
#------re.M 能匹配到换行—
3.1
y = re.findall("\w+KaTeX parse error: Undefined control sequence: \n at position 13: ", "I am rdj\̲n̲ ̲hello word\n, t…结尾
print(y) # [‘app’]
3.2
flag = re.M 加上看看,匹配以数字字母下划线至少1个 结尾的
理解为:匹配到每行的结尾
y = re.findall("\w+KaTeX parse error: Undefined control sequence: \n at position 13: ", "I am rdj\̲n̲ ̲hello word\n, t…结尾
print(y) # [‘rdj’, ‘word’, ‘app’]

拓展知识四:
{} 用来限定出现的次数
{N} 匹配前面紧跟字符精确到N次 [1-9][0-9]{2},匹配100到999的整数,{2}表示[0-9]匹配两个数字
{N,} 匹配前面紧跟字符最少N次
{N,M} 匹配前面紧跟字符的至少N次,最多M次 [0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3},匹配IP地址,其中.号是特殊字符,需要使用转义字符
场景一:{}前的字符匹配的个数
#m4 = re.search(“3{2}”,“a11333”)
print(m4.group()) # 33
场景2:匹配3的字符,从1个开始,多个3也可以,查找就停止
m4 = re.search(“3{1,}”,“a131333333”)
print(m4.group()) # 3 打印结果是1个3
#m4 = re.search(“3{1,}”,“a11333333”)
print(m4.group()) # 333333
场景三:匹配3的字符最多2次,包含了1次,只要出现11 3就停止查找
3.1
#m4 = re.search(“113{,2}”,“a11333333a”)
#print(m4) # 1133
3.2
m4 = re.search(“113{,2}”,“113a11333333a”)
print(m4.group()) # 113
场景四:匹配3开始找1到4个都可以,找到停止
m4 = re.search(“3{1,4}”,"a11333333a11333333)
#print(m4) # 打印结果:3333
m4 = re.search(“3{1,4}”,“a131333333a11333333”)
print(m4.group()) # 打印结果是一个3
m4 = re.search(“3{1,4}”,“a133433333a11333333”)
print(m4.group()) # 打印结果是一个33
拓展知识五:sub替换
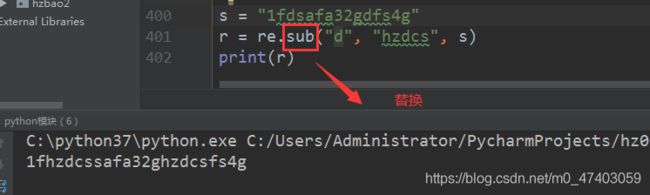
5.1
s = “1fdsafa32gdfs4g”
r = re.sub("\d", “我”, s)
print® # 我fdsafa我我gdfs我g
5.2
content=‘Extra strings Hello 123 456 World_This is a Regex Demo Extra strings’
content=re.sub(’\d+’,’’,content)
print(content)
