网页爬虫的原理
原文地址: https://zhuanlan.zhihu.com/p/35324806
这篇文章的定位是,给有一些python基础,但是对爬虫一无所知的人写的。文中只会涉及到爬虫最核心的部分,完全避开莫名其妙的坑或概念,让读者觉得爬虫是一件非常简单的事情,而事实上爬虫确实是一件非常简单的事情(如果你不是以爬虫为工作的话)。
本文分为如下几个部分
- 引言
- 概念介绍
- HTML介绍
- 解析代码介绍
- chrome检查工具介绍
引言
简单理解网络爬虫就是自动抓取网页信息的代码,可以简单理解成代替繁琐的复制粘贴操作的手段。首先必须声明,爬虫的对象必须是你已经看到的网页,比如你不能说你想找到知乎上哪个用户的关注人数最多,就希望通过写一个爬虫来帮你爬到答案。你必须明确地知道这个人,找到他的主页,然后才能用爬虫来抓取他页面上的信息。下面我们用一个简单的例子来展示爬虫的工作流程。感觉多数教程第一篇都使用的是豆瓣top250,我们这里换一个,抓取CSDN首页的文章标题,链接在这里,页面样子是这样的
抓取标题完整代码如下
`import requests # 导入网页请求库from bs4 import BeautifulSoup # 导入网页解析库# 传入URLr = requests**.**get('https://www.csdn.net/')
# 解析URLsoup = BeautifulSoup(r**.text, 'html.parser') content_list = soup.**find_all('div', attrs = {'class': 'title'})
for content in content_list: print(content**.h2.a.**text)`
这样就会打印出所有标题,展示一部分如下

上述过程是一个最简单的完整爬虫流程,可以看出它的功能就是把那些标题复制粘贴到一起,免除了手动操作的繁琐。其实爬虫一般就是做这些事的,比如我们需要用链家的数据进行分析,看到链家的页面是这样的
我们想获取每个房子的标题、几室几厅、多少平米、朝向、装修、价格等等字段(即指标),就可以通过爬虫进行定位,自动化抓取这100页所有房子的这些字段信息。比如100页里有2000个房子,总共抓取10个字段,爬虫运行结束就可以得到一个2000行10列的excel表格。
注:如果还没有安装上面两个库的读者可以在命令行下分别运行下面两行命令完成安装
pip install requests pip install beautifulsoup4
概念介绍
知道了爬虫是用来干什么的之后,我们来介绍一些最常见到的概念
1.URL
URL中文称为统一资源定位符,其实可以理解成网页的链接,比如上面的https://www.csdn.net/就是一个URL。
但是更广义的URL不只是我们常看到的网页资源链接,而是资源在网页中的定位标识。我们通常说的网页是一个资源,网页中加载的每一张图片也是一个资源,它们在互联网中也有唯一的定位URL。比如我们从CSDN网页上随便找一张图片

这个链接https://csdnimg.cn/feed/20180330/49f4cd810ad4606e3c45ed9edb16a8b8.jpg就是这个图片资源的定位符,将这个链接输入浏览器中就会显示出这张图片,所以说这张图片也对应一个URL。
不过知道这么回事就好,我们通常所说的传入URL指的就是把网页的链接传进去。上面代码中
r **=** requests**.**get('
就是在将URL传入请求函数。
2.网页请求
说到网页请求,就有必要讲一下我们平常浏览网页时,信息交互的模式大概是什么样的。我们平常用浏览器浏览网页的时候,鼠标点了一个链接,比如你现在点击这里,其实浏览器帮你向这个网页发送了请求(request),维护网页的服务器(可以理解为CSDN公司里的一台电脑,在维护这CSDN上的各个网页)收到了这个请求,判定这个请求是有效的,于是返回了一些响应信息(response)到浏览器,浏览器将这些信息进行渲染(可以理解成 处理成人能看懂的样子),就是你看到的网页的样子了。发送请求与接收请求的过程就和 发微信和收到回复的过程类似。
而现在我们要用代码来模拟鼠标点击的过程。上面的requests.get就是让代码帮你向这个网页发送了这个请求,如果请求被判定为有效,网页的服务器也会把信息传送给你,传送回来的这些信息就被赋值到变量r之中。所以这个变量r里就包含有我们想要的信息了,也包括那些我们想要提取的标题。
我们可以print(r.text)看一下里面有什么东西
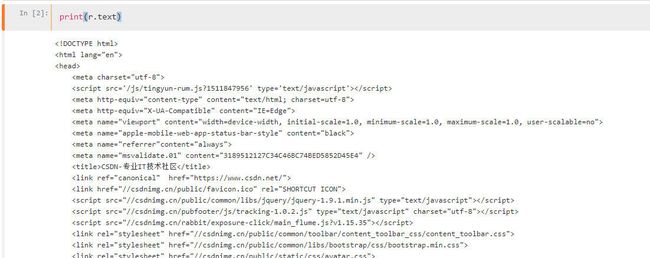
我们再看一下网页的源代码(如何看懂这个源码,以及这个源码怎么查看下一节HTML会详细讲到)

源代码和r.text其实是一模一样的东西。r.text其实就是一个字符串,字符串中有我们刚刚抓取到的所有标题,我们只要通过字符串匹配方法(比如正则表达式)将他们提取出来就可以了。这样说是不是感觉爬虫非常简单呢?只要这样傻瓜操作
r = requests.get('
再直接从r.text字符串中提取信息即可。其实爬虫就是这么简单。
但是解析是怎么回事呢,为什么刚刚不直接用正则而要用bs4呢?因为方便,但是正则也是完全可以的,只是相对麻烦一些、需要写更多的代码而已。
3.网页解析
网页解析其实就从网页服务器返回给我们的信息中提取我们想要数据的过程。其实使用正则表达式提取我们要的标题的过程也可以称为网页解析。
因为当前绝大多数网页源代码都是用HTML语言写的,而HTML语言时非常有规律性的,比如我们要的所有文章标题都具有相同结构,也就是说它周围的字符串都是非常类似的,这样我们才能批量获取。所以就有大佬专门封装了如何从HTML代码中提取特定文本的库,也就是我们平时说的网页解析库,如bs4 lxml pyquery等,其实把他们当成处理字符串的就可以了。
为了更清楚地了解如何对网页进行解析,我们需要先粗略掌握HTML代码的结构。
HTML介绍
引用维基百科中的一段话来介绍HTML
超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。HTML是一种基础技术,常与CSS、JavaScript一起被众多网站用于设计令人赏心悦目的网页、网页应用程序以及移动应用程序的用户界面[1]。网页浏览器可以读取HTML文件,并将其渲染成可视化网页。
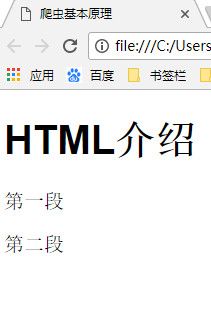
为了让读者对HTML有更清楚的认识,我们来写一点简单的HTML代码。用文本编辑器(记事本也可以)创建一个名字为a.html的文件,在里面写下如下代码
****
HTML介绍
第一段
第二段
保存,然后你双击这个文件,就会自动用浏览器打开,然后你就能看到下面这个样子的页面
你如果按照我的操作来做的话,你已经创建了一个简单的网页,现在你看到的所有网页都是这样设计的,只是比你的复杂一点而已,不信你去看看刚才截图下来的网页源代码图片。
接下来,我们来看一下HTML语言的特点。最重要的一点是,文本都是被标签(h1标签 p标签)夹在中间的,而这些标签都是特定的,有专门用途的。比如
就表示一级标题,包在里面的文本自然会被放大显示;而
标签则表示段落。
再看上面的源代码截图,head meta script title div li每一个都是标签,层层嵌套。我们完全不需要知道总共有哪些种标签,也不需要知道这些标签都是用来干什么的,我们只要找到我们要的信息包含在什么标签里就行了。比如使用正则表达式就直接用
(.*?)
但是事实好像没有那么简单,看上面的截图标签怎么是这样的