⭐李宏毅2020作业2---logistic regression
找资料链接
理论:
线性回归和逻辑回归的对比:
第一步:创建一个函数(区别是是否通过sigmoid函数)
第二步:创建loss(逻辑回归是通过交叉熵计算)
第三步:梯度下降法,找到最小的loss


逻辑回归一般采用逻辑回归问题
数据预处理:
- 读取文件转换成numpy数组
- 将数据整理为使用的格式(y_train是标签)
- 归一化(让各个部分“单位”相同)
程序:
定义的函数和作用:
- _shuffle:打乱数据顺序,类似于重新洗牌,进行分批次训练(即每次将一部分数据喂给模型进行训练,计算损失)
- _sigmoid:激活函数
- _f(X,w,b):向前传播,计算激活值
- _predict(X, w, b):预测
- _accuracy(Y_pred, Y_label):计算准确度
- _cross_entropy_loss:交叉熵损失函数
- _gradient:计算梯度值,用于更新w和b
使用函数:
1.np.random.seed(0)作用:
使得随机数据可预测。当我们设置相同的seed,每次生成的随机数相同。如果不设置seed,则每次会生成不同的随机数
2.split(',')[1:] :
先用split(',')方法将字符串以","开割形成一个字符串数组,然后再通过切片[1:]取出所得数组中的第二个元素以后的值
3.路径:
../ 表示当前文件所在的目录的上一级目录
./ 表示当前文件所在的目录(可以省略)
/ 表示当前站点的根目录(域名映射的硬盘目录)
注:
- path:"\"为字符串中的特殊字符,加上r后变为原始字符串,则不会对字符串中的"\t"、"\r" 进行字符串转义
- 用一个"\"取消第二个"\"的特殊转义作用,即为"\\"
4.函数读取:
- read(),一次读取全部内容到内存。
with open('file.txt', 'r') as f:
print(f.read()) with方式可以避免没有关闭资源文件产生错误
- readlines(),with方式,逐行读取。
with open("file.txt") as lines:
for line in lines:
print(line)
- readlines(),open方式,逐行读取。
# 打开文件
f = open("file.txt", "r")
print ("文件名为: ", f.name)
for line in f.readlines(): #依次读取每行
line = line.strip() #去掉每行头尾空白
print ("读取的数据为: %s" % (line))
# 关闭文件
fo.close()5.with...as的用法:
是简化版的try except finally语句
try…except...finally用法:
try:
## normal block
except A:
## exc A block
except:
## exc other block
else:
## noError block
finally: # 是否异常都执行该代码块
print("Successfully!")执行流程:
–>执行normal block
–>发现有A错误,执行 exc A block(即处理异常)
–>执行finally
–>结束
如果没有A错误呢?
–>执行normal block
–>发现B错误,开始寻找匹配B的异常处理方法,发现A,跳过,发现except others(即except:),执行exc other block
–>执行finally
–>结束
如果没有错误呢?
–>执行normal block
–>全程没有错误,跳入else 执行noError block
–>执行finally
–>结束with expression [as variable]:
with-block 注意:1.with所求值的对象必须有一个__enter__()方法,一个__exit__()方法。2. as可以省略
紧跟with后面的语句被求值后,返回对象的__enter__()方法被调用,这个方法的返回值将被赋值给as后面的变量。当with后面的代码块全部被执行完之后,将调用前面返回对象的__exit__()方法
with…as语句执行顺序:
–>执行expression里面的__enter__函数,它的返回值会赋给as后面的variable(如果不写as variable返回值会被忽略)
–>执行with-block中的语句,无论是否成功,执行expression中的__exit__函数。
如果with-block执行成功,则exception_type,exception_val, trace的输入值都是null。
如果with-block出错了,就会变成像try/except/finally语句一样,exception_type, exception_val, trace 这三个值系统会分配值。6.命名
- 以单下划线_开头的命名
一般用于模块中的"私有"定义的命名。
-
仅开头带双下划线__的命名
用于对象的数据封装,以此命名的属性或者方法为类的私有属性或者私有方法
- 前后均带有双下划线__的命名
一般用于特殊方法的命名,用来实现对象的一些行为或者功能,比如__new__()方法用来创建实例,__init__()方法用来初始化对象,x + y操作被映射为方法x.__add__(y),序列或者字典的索引操作x[k]映射为x.__getitem__(k),__len__()、__str__()分别被内置函数len()、str()调用等等。
7.np.arange()用法:
函数返回一个有终点和起点的固定步长的排列,如[1,2,3,4,5],起点是1,终点是6,步长为1。
参数个数情况: np.arange()函数分为一个参数,两个参数,三个参数三种情况
1)一个参数时,参数值为终点,起点取默认值0,步长取默认值1。
2)两个参数时,第一个参数为起点,第二个参数为终点,步长取默认值1。
3)三个参数时,第一个参数为起点,第二个参数为终点,第三个参数为步长。其中步长支持小数
例:
input: x=np.arange(10)
output: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
8.if后面作用(也可以不写):
定义了需要被标准化的列。如果输入为None,则表示所有列都需要被标准化。
可以省略直接用X[ : , :],训练集和测试集都是二维数组
if specified_column == None:
specified_column = np.arange(X.shape[1])
9.求均值方差
X_mean:训练集中每一列的均值。X_std:训练集中每一列的方差。- reshape(1, -1)转换成一行
10.numpy.clip(a, a_min, a_max, out=None)
a : array
a_min : 要限定范围的最小值
a_max : 要限定范围的最大值
out : 要输出的array,默认值为None,也可以是原array
>>> a = np.arange(10)
>>> np.clip(a, 1, 8)
array([1, 1, 2, 3, 4, 5, 6, 7, 8, 8])激活函数公式: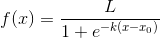
sigmoid_scores = [1 / float(1 + np.exp(- x)) for x in inputs]
11.multiply 数量积 np.matmul() 矢量积
12.np.sum(a, axis=None, dtype=None, out=None, keepdims=np._NoValue)
axis的取值有三种情况:1.None,2.整数, 3.整数元组。
当axis为0时,是压缩行,即将每一列的元素相加,将矩阵压缩为一行
当axis为1时,是压缩列,即将每一行的元素相加,将矩阵压缩为一列
13.数组.T
数组进行转置
14.np.abs(x)
计算数组各元素的绝对值
15.分批进行方法
除以批次之后要取整
作业概述:
输入:人们的个人信息
输出:0(年收入≤50K)或1(年收入>50K)
模型: logistic regression 或者 generative model
给定训练集spam_train.csv,要求根据每个ID各种属性值来判断该ID对应角色是Winner还是Losser(收入是否大于50K),这是一个典型的二分类问题。
import numpy as np
np.random.seed(0)
X_train_path ='./X_train'
Y_train_path = './Y_train'
X_test = './X_test'
#读取数据,不要第一行第一列
with open(X_train_path) as f:
next(f)#跳过第一行
#去掉换行,以,分割,跳过第一列
X_train = np.array([line.strip('\n').split(',')[1:] for line in f],dtype = float)
with open(Y_train_path) as f:
next(f)#跳过第一行
#去掉换行,以,分割,跳过第一列
Y_train = np.array([line.strip('\n').split(',')[1:] for line in f],dtype = float)
with open(X_test) as f:
next(f)#跳过第一行
#去掉换行,以,分割,跳过第一列
X_test = np.array([line.strip('\n').split(',')[1:] for line in f],dtype = float) 数据预处理:
标准化:
def _normalize(data,train=True,X_mean = None, X_std = None):
#numpy.ndarray.shape 表示数组的维度,返回一个元组,这个元组的长度就是维度的数目,即 ndim 属性(秩)。
#append(arr, values, axis=None)
if train:
X_mean = np.mean(data[:,:],0).reshape(1,-1)
X_std = np.std(data[:,:],0).reshape(1,-1)
#归一化计算,用1e-8防止除零
data = (data-X_mean)/(X_std+1e-8)
return data,X_mean,X_std
X_train,X_mean,X_std = _normalize(X_train,train=True)
#X_mean = None, X_std = None,如果不提前定义在x_test时会出现未定义
#不能定义,X_mean = X_mean, X_std = X_std,会显示函数未定义
X_test,_ ,_= _normalize(X_test,train=False,X_mean = X_mean,X_std = X_std) 分割训练集和验证集:
def _train_data_split(X,Y,rate):
#强制转换为整形避免出现数据不为整数的情况
train_rate = int(len(X)*rate)
#y_train 是标签
return X[:train_rate],X[train_rate:],Y[:train_rate],Y[train_rate:]
x_train,y_train,x_val,y_val = _train_data_split(X_train,Y_train,0.9)打乱训练集顺序:
def _shuffle(X,Y):
random = np.arange(len(x))
np.random.shuffle(random)#直接返回值
return X[random],Y[random]模型:
激活函数:
def _sigmoid():
return 1/(1+np.exp(-z))function:
def _f(X,w,b):
return _sigmoid(np.matmul(w,X)+b)loss:
def _loss(y_lable,y_pre):
loss = -np.dot(y_lable,np.log(y_pre))-np.dot((1-y_lable),np.log(1-y_pre))梯度下降:
def _grad(w,b,step,X,Y_label):
y_pre = _f(X,w,b)
pred_error = Y_label - y_pre
# 梯度下降法更新,学习率随时间衰减
w = w - learning_rate/np.sqrt(step) * (-np.sum(pred_error * X.T, 1))
b = b - learning_rate/np.sqrt(step) * (-np.sum(pred_error))
return w,b准确率:
def _acc():
return (1-np.mean(np.abs(Y_pred - Y_label)))开始训练:
设置训练集验证集:
train_size = X_train.shape[0]
val_size = x_val.shape[0]
test_size = X_test.shape[0]
data_dim = X_train.shape[1]w,b初始化:
w = np.zeros((data_dim,))
b = np.zeros((1,))设置超参数:
batch_size = 8
learning_rate = 0.1
epoch = 10主函数:
for epoch in range(epoch):
# 每个epoch都会重新洗牌
X_train, Y_train = _shuffle(X_train, Y_train)
for i in range(int(np.floor(train_size/batch_size))):
X = X_train[idx*batch_size:(idx+1)*batch_size]
Y = Y_train[idx*batch_size:(idx+1)*batch_size]
w ,b = _grad(w,b,step,X,Y_label)
step = step + 1
# 参数总共更新了max_iter × (train_size/batch_size)次
# 计算训练集的损失值和准确度
y_train_pred = _f(X_train, w, b)
Y_train_pred = np.round(y_train_pred)
train_acc.append(_accuracy(Y_train_pred, Y_train))
train_loss.append(_cross_entropy_loss(y_train_pred, Y_train) / train_size)
# 计算验证集的损失值和准确度
y_dev_pred = _f(X_dev, w, b)
Y_dev_pred = np.round(y_dev_pred)
dev_acc.append(_accuracy(Y_dev_pred, Y_dev))
dev_loss.append(_cross_entropy_loss(y_dev_pred, Y_dev) / dev_size)
print('Training loss: {}'.format(train_loss[-1]))
print('Development loss: {}'.format(dev_loss[-1]))
print('Training accuracy: {}'.format(train_acc[-1]))
print('Development accuracy: {}'.format(dev_acc[-1]))参考资料:
参考资料1
参考资料2
参考资料3