Apache RocketMQ 4.8.0,DLedger 模式全面提升!
简介:“童年的雨天最是泥泞,却是记忆里最干净的曾经。凛冬散尽,星河长明,新的一年,万事顺遂,再见,2020!”

作者 | RocketMQ社区
来源|阿里巴巴云原生公众号
“童年的雨天最是泥泞,却是记忆里最干净的曾经。凛冬散尽,星河长明,新的一年,万事顺遂,再见,2020!”
走过这个岁末,万众期待的 Apache RocketMQ 4.8.0 终于发布了,在这个版本中社区对 RocketMQ 完成大量的优化和问题修复。更重要的是,该版本从性能、稳定性、功能三个方面大幅度提升 DLedger 模式能力。
DLedger 是 OpenMessaging 中一个基于 Raft 的 CommitLog 存储库实现,从 RocketMQ 4.5.0 版本开始,RocketMQ 引入 DLedger 模式来解决了 Broker 组内自动故障转移的问题,而在 4.8.0 版本中社区也对 RocketMQ DLedger 模式进行了全面升级。
性能升级
- 异步化 pipeline 模式
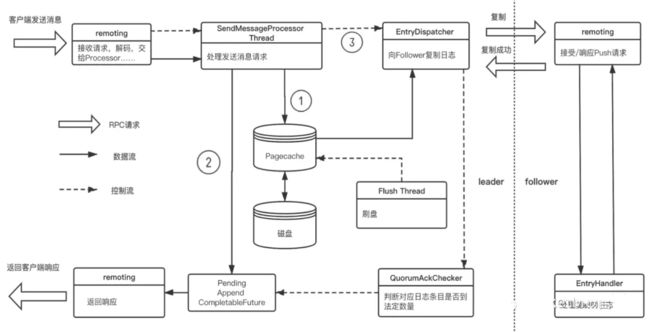
RocketMQ 4.7.0 重新升级了同步双写的架构,利用异步化 pipeline 模式大幅提升了同步双写的性能。在 RocketMQ 4.8.0 中,社区将这一改进应用到 DLedger 模式中, 下图展示了 DLedger 模式下 broker 处理发送消息的过程。在原本的架构中, SendMessageProcessor 线程对每一个消息的处理,都需要等待多数派复制成功确认,才会返回给客户端,而在新版本中,利用 CompletableFuture 对线程处理消息的过程进行异步化改造,不再等待多数派的确认即可对下一个请求进行处理,Ack 操作由其他线程确认之后再进行结果处理并返回给客户端。通过对复制过程进行切分并将其流水线化,减少线程的长时间等待,充分利用 CPU,从而大幅提高吞吐量。
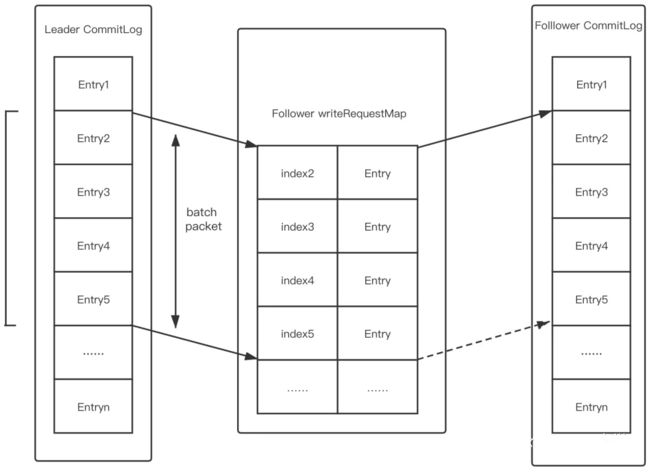
- 批量日志复制
Batch 一直是性能优化的重要方式,在新版本中,可以通过设置 isEnableBatchPush=true 来开启 DLedger 模式的批量复制。通过将多条数据聚合在一个包中进行发送,可以降低收发包的个数,从而降低系统调用和上下文的切换。在数据发送压力比较大,并且可能达到系统收发包瓶颈的情况下,批量复制能显著提高吞吐量。值得注意的是,DLedger 模式下的批量复制并不会对单个包进行延时的攒批处理,因此不会影响单个消息的发送时延。
除了上述的性能优化,社区还对 DLedger 模式下影响性能的锁、缓存等做了数项性能优化,使 DLedger 模式下的性能提升数倍。
稳定性升级
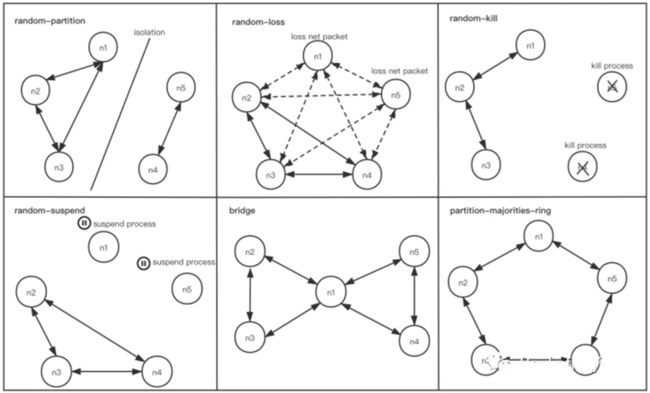
为了验证和测试 Dledger 模式的可靠性,除了本地对 DLedger 模式进行了各种各样的测试,社区利用 OpenMessaging-Chaos 框架对 RocketMQ DLedger 模式进行了大量 Chaos 测试。OpenMessaging-Chaos 是一个利用故障注入来验证各种消息平台一致性和高可用性的测试框架,在 OpenMessaging-Chaos 的测试中,客户端并发地向待测试集群发送和接收消息,中间会间隔性地对集群进行故障注入,最后给出测试结果,包括是否丢消息,是否有重复消息,集群平均故障恢复时间等。利用 OpenMessaging-Chaos,我们验证了 DLedger 模式在以下故障注入场景下的表现:
-
random-partition(fixed-partition)故障随机挑选节点进行网络隔离,模拟常见的对称网络分区。
-
random-loss 故障随机挑选节点并对这些节点接收和发送的网络包进行按比例丢弃,模拟一些节点网络较差的情况。
-
random-kill(minor-kill、major-kill、fixed-kill)故障模拟常见的进程崩溃情况。
-
random-suspend(minor-suspend、major-suspend、fixed-suspend)故障模拟一些慢节点的情况,比如发生 Full GC、OOM 等。
-
bridge 和 partition-majorities-ring 故障模拟比较极端的非对称网络分区。
以 minor-kill 故障注入为例,我们部署 5 个节点组成一组 DLedger 模式的 RocketMQ broker 进行 Chaos 测试。minor-kill 故障注入会随机挑选集群中少数节点进程杀死,由于杀死少数节点,即使集群不可用也能在一段时间内恢复,方便测试集群平均故障恢复时间。
测试过程中我们设置四个客户端并发向 RocketMQ DLedger 集群发送和接收消息,故障注入时间间隔为 100s,即 100s 正常运行,100s 故障注入,一直循环,整个阶段一共持续 2400s。测试结束后,OpenMessaging-Chaos 会给出测试结果和时延图。下图展示了整个测试过程中入队操作的时延情况。
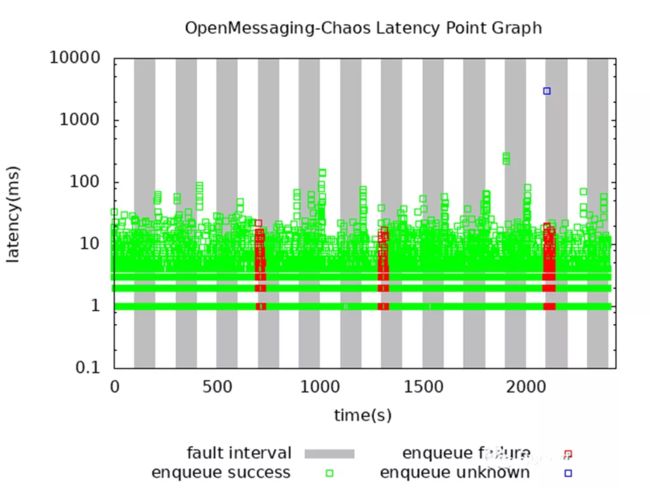
图中纵坐标是是时延,横坐标是测试时间,绿色框表示数据发送成功,红色框表示数据发送失败,蓝色框表示不确定是否数据添加成功,灰色部分表示故障注入的时间段。可以看出一些故障注入时间段造成了集群短暂的不可用,一些故障时间段则没有,这是合理的。由于是随机网络分区,所以只有杀死的少数节点包含 leader 节点时才会造成集群重新选举,但即使造成集群重新选举, DLedger 模式在一段时间后也会恢复可用性。
下图是测试结束后 OpenMessaging-Chaos 给出的统计结果,可以看到一共成功发送了 11W 个数据,没有数据丢失,这表明即使在故障下,RocketMQ DLedger 模式仍旧满足 At Least Once 的投递语义。此外,RTOTestResult 表明 12 次故障时间段一共发生了 3 次集群不可用的情况(与上述时延图一致),但每次集群都能在 30 秒以内恢复,平均故障恢复时间在 22 秒左右。
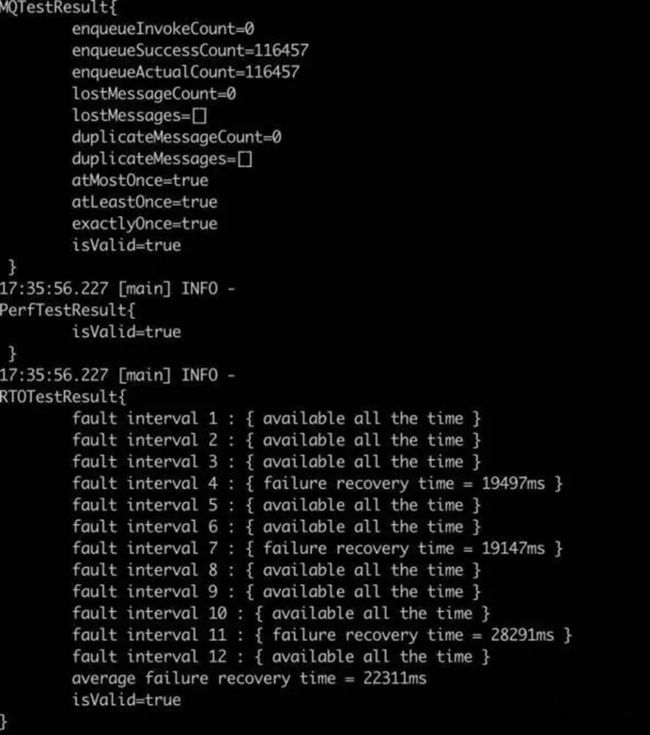
在 OpenMessaging Chaos 测试过程中,我们发现了 DLedger 模式存在的数个隐性问题并进行了修复,提高了 DLedger 模式下对进程异常崩溃、慢节点、对称/非对称网络分区、网络丢包的容错能力,也进一步验证了 DLedger 模式的可靠性。
功能升级
- DLedger 模式支持 Preferred Leader
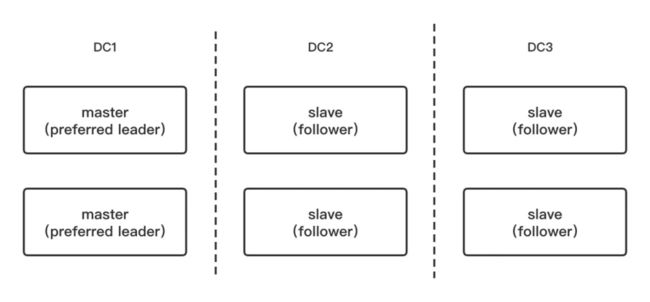
在旧版本中一组 Broker 中选谁作为 Leader 完全是随机的。但是在新版中我们可以通过配置 preferredLeaderId 来指定优先选举某个节点为 Leader,如下图所示,通过在三个机房部署 DLedger 模式的 broker 组,利用 preferred leader 可以更好的实现机房对齐的功能,图中 DC1 中服务更好,我们可以优先选择在 DC1 中部署 Master。此外,利用 preferred leader 还可以更好实现 DLedger 集群混部,从而充分利用机器资源。
- DLedger 模式支持批量消息
从 RocketMQ 4.8.0 开始,DLedger 模式支持批量消息发送,从而在消息类型的支持上完全与 Master-Slave 部署形态保持一致。
除了对 DLedger 模式的大量优化,本次 RocketMQ 版本一共包含 Improvement 25 个,Bug Fix 11 个,文档和代码格式优化 16 个。据不完全统计,这些贡献来自近 40 位 RocketMQ 社区的 Contributor,感谢大家的积极参与。也非常期待有更多的用户、厂商、开发者参与到 RocketMQ 建设中来,加入 Apache RocketMQ 社区,永远不会太迟!
原文链接:https://developer.aliyun.com/article/781029?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。