OpenStack环境手动部署解析
文章目录
- 前言
- 一 OpenStack架构
-
- 1.1 OpenStack架构
-
- 1.1.1 按照不同的功能和通用性划分不同的项目,拆分子系统
- 1.1.2 按照逻辑计划,规范子系统之间的通信
- 1.1.3 通过分层设计整个系统架构
- 1.2 OpenStack概念架构
-
- 1.2.1 以架构维度来看的话
-
- 1.2.1.1 全局组件:
- 1.2.1.2 辅助组件/其它组件:
- 1.2.1.3 核心组件:
- 1.3 OpenStack逻辑架构
-
- 1.3.1 展示的内容:
- 1.3.2 解析
- 1.4 OpenStack组件通信关系
- 1.5 OpenStack物理架构
- 1.5 组件分析:
-
- 1.5.1 控制节点(调度器)
-
- 1.5.1.1 解析
- 1.5.2 计算节点
-
- 1.5.2.1 解析
- 1.5.3 网络节点
-
- 1.5.3.1 解析
- 1.5.4 存储节点
-
- 1.5.4.1 解析
- 二 OpenStrack模块介绍
-
- 2.1 控制台Horizon(图形化界面)
-
- 2.1.1 Horizon特点
- 2.2 身份认证模块Keystone
-
- 2.2.1 Keystone涉及概念
- 2.2.2 身份认证模块Keystone
- 2.3 镜像模块Glance
-
- 2.3.1 Glance主要组件
- 2.3.2 镜像的格式
- 2.4 网络模块Neutron
-
- 2.4.1 实现功能
- 2.5 虚拟网络
-
- 2.5.1 组网模型
- 2.6 块存储Cinder
-
- 2.6.1 Cinder功能
- 2.6.2 Cinder组件
- 2.7 对象存储swift
-
- 2.7.1 Swift特点
- 2.7.2 Swift组件
- 2.7.3 Swift存储结构
- 三 OpenStack 环境部署
-
- 3.1 部署准备
- 3.2 部署思路:
- 3.3 部署流程
-
- 3.3.1 关闭防火墙
- 3.3.2 免交互
- 3.3.3 安装基础环境依赖包
- 3.3.4 设置时间同步
- 3.3.5 设置任务计划
- 3.3.6 安装,配置MariaDB
- 3.3.7 安装RabbitMQ(消息队列)
- 3.3.8 安装memcached
- 3.3.9 安装etcd
- 总结
前言
搭建openstack基础环境架构来进一步熟悉了解openstack服务部署流程
一 OpenStack架构
1.1 OpenStack架构
OpenStack作为开源,可扩展,富有弹性的云操作系统,其设计基本原则
1.1.1 按照不同的功能和通用性划分不同的项目,拆分子系统
a.按照不同的功能划分不同的服务,并且服务之间相互隔离,只通过API作为统一交互入口相互对接
b.按照功能和通用性划分不同服务,将一个整理功能划分为各个子服务/子功能,方便管理,排障
1.1.2 按照逻辑计划,规范子系统之间的通信
a.API之间进行交互会有特定/通用的方式对不同组件之间的通讯方式进行规范
b.性质:隔离,各个子功能模块之间只会通过一个公共的API进行交互/通讯
c.各个子功能模块遵循一些规范进行通信(API HTTP)
1.1.3 通过分层设计整个系统架构
分层(以架构为单位),三层:
a.全局组件
b.辅助组件
c.核心组件
以单个核心服务/组件进行分层:
a.API(只通过API进行内外部交互,内部:核心组件;外部:openstack相对应核心组件内部而言为外部)
b.子功能模块(单个核心服务,参照物:维度)
c.其它(每个核心组件各自特色,个性化组件)
以上之间都可以通过消息队列/代理(rabbitmq)进行通讯。
作为组件与组件之间通讯/交互/数据传输的载体以解决单个服务的通讯方式瓶颈
API(预处理)
1.向keystone进行申请认证请求的合法性和权限
2.下发任务,会根据请求的功能需求,将不同的任务交给不同的组件来完成,统一收集结果和需要提供的资源,整合在一起,响应请求。
4.不同的功能子系统间提供统一的API接口
各组件之间通过统一的API接口进行交互/通讯/数据传输/调用
1.2 OpenStack概念架构

1.2.1 以架构维度来看的话
分为:全局组件,核心组件,辅助组件
1.2.1.1 全局组件:
Keystone:身份认证服务,提供认证,管理全局权限,认证和授权的组件
Ceilometer:计量服务,监控,监控整个集群架构的状态
Horizon:控制面板服务,可以使用openstack架构中的所有功能
1.2.1.2 辅助组件/其它组件:
提供一些必要的管理和资源服务
Ironic:裸金属(裸机)提供基本的硬件资源
Trove:数据库,管理数据库的服务(关系,非关系);存储openstack实例数据,各组件之间调用,使用情况;日志文件
Heat:对数据进行分析,编排,处理,精细化管理
Sahara:
1.2.1.3 核心组件:
维持openstack虚拟机/示例正常运行的组件
Nova(计算服务):
Glance(镜像服务):
Neutron(网络服务):
Swift(对象存储服务):
Cinder(块存储服务):
由nova将资源收集整合,统一提供给虚拟机
如果要添加其他一些功能,关联,调用一些功能组件的API或者把功能对应的API暴露出来后,供给其它组件去对接,调用(openstack的灵活性)


1.3 OpenStack逻辑架构
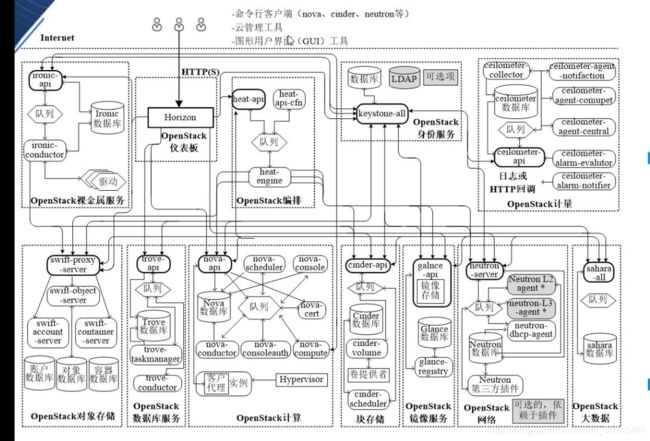
1.3.1 展示的内容:
1.首先展示了内部核心组件,辅助组件,全局组件
2.各核心/辅助组件组件是怎么对接的(API对接,通讯方式可以为消息代理)
3.展示了各组件中,一部分核心的功能模块
4.展示OpenStack原生架构(基础)
第三方功能模块
1.辅助原生架构的组件可以更完善更合理的运行
2.增加一些功能(原生架构没有或者不完善的--特定场景)
1.3.2 解析
全局,架构层面
OpenStack包括若干个称为OpenStack服务的独立组件,所有服务均可通过一个公共身份服务进行身份验证,除了那些需要管理权限的命令,每个服务之间均可通过公共API进行交互
1.以架构的维度来理解:
OpenStack分为多个核心组件,核心组件之间只/仅通过一个公共的API进行对接/通讯。同时每个核心组件,都由一个对立的用户进行管理(会对用户授权)
2.使用http进行交互
httpd承载API
HTTPD提供一个展示web页面的方式,并且表示是以HTTP进行通讯

单个服务,核心组件(维度)
每个OpenStack服务又由若干组件组成。包含多个进程。所有服务至少有一个API进程,用于侦听API请求,对这些请求进行预处理,并将它们传送到该服务的其它组件。除了认证服务,实际工作都是由具体的进程完成的
restful请求:外部想要访问/查询/调用,内部的资源的请求
API负责接收请求,对请求进行预处理,并且把它们发给后端对应的功能模块,它本身不负责具体过程处理
预处理:
1.API向keystone进行权限认证
2.根据请求需求把请求分发给对应的功能模块进行处理

至于一个服务的进程之间通信,则使用AMQP消息代理,服务的状态存储在数据库中
以核心组件维度来理解
1.API
2.子功能模块
3.其它(rabbitmq 消息队列)
使用AMQP消息代理原因
因为以服务本身拥有的消息传递和消息交互的通讯方式,进行通讯与数据传输会存在严重的瓶颈问题
openstack本身架构非常的复杂,庞大,处理的数据量非常多时,消息传递速率,效率及合理性会有一个严格的划分,需要使用一个队列(AMQP消息代理)去作为中间的承载,而这样的一个服务叫rabbitmq(消息队列)
1.4 OpenStack组件通信关系
openstack内部根据功能可以划分不同的通讯方式
1.基于AMQP协议的通信
用于每个项目内部各个组件之间的通信
2.基于SQL的通信
用于各个项目内部的通信
3.基于HTTP协议进行通信
通过各项目的API建立的通信关系,API都是RESTful Web API
解析:
RESTful:标准化通讯协议
httpd->提供了一个可视化的web页面(http承载API)->API->API会有自己的具体位置,而这个具体的位置可以是URL(域名,网址)
http通过域名与域名,IP地址+端口进行通信
openstack中的API是一个很核心的概念
restful:是一种交互/通讯的规范
web:由Apache承载API,Apache提供了一个Web展示页面
API:组件和组件对接的技术(点到点)
URL->对接->URL(域名)
endpoint--->endpoint(端点)
OpenStack是一种模块化的设计
HTTPD也是一种模块化的设计
4.通过Native API实现通信
OpenStack各组件(原生架构)和第三方软硬件(外部组件)之间的通信
1.5 OpenStack物理架构

1.5 组件分析:
整个OpenStack是由控制节点,计算节点,网络节点,存储节点,四大部分组成。(这四个节点也可以单机部署)
其中:
提供者网络openstack架构内部网络
自服务网络:负责连通外部,与存储服务器集群进行关联
1.5.1 控制节点(调度器)
负责对其余几点的控制,包含虚拟机创建、迁移、网络分配、存储分配等等
控制节点架构:
控制节点包括以下服务
管理支持服务
基础管理服务
扩展管理服务
a.管理支持服务:包含数据库与消息代理服务
数据库作为基础/扩展服务产生的数据存放的地方
消息代理服务(也称消息中间件)为其他各种服务之间提供了统一的消息通信服务
b.基础管理服务包含Keystone、Glance、Nova、Neutron、Horizon五个服务
Keystone:认证管理服务、提供了其余所有组件的认证信息/令牌的管理、创建、修改等等、使用MySQL等数据库存储认证信息
Glance:镜像管理服务,提供了对虚拟机部署的时候所能提供镜像的管理、包含镜像的导入、格式以及制作相应的模板
Nova:计算管理服务,提供了对计算节点的Nova管理、使用Nova-API(入口节点)进行通信
Neutron:网络管理服务、提供了对网络节点的网络拓扑管理,同时提供Neutron在Horizon的管理界面
Horizon:控制台服务,提供了以Web形式对所有节点的所有服务的管理,通常把该服务成为Dashboard
c.扩展管理服务包含Cinder、Swift、Trove、Heat、Centimeter五个服务
Cinder:提供管理存储节点的Cinder相关、同时提供Cinder在Horizon中的管理面板
Swift:提供管理存储节点Swift相关、同时提供Swift在Horizon中的管理面板
Trove:提供管理数据库节点的Trove先关、同时提供Trove在Horizon中的管理面板
Heat:提供了基于模板来实现云环境中的资源的初始化,依赖关系处理,部署等基本操作,也可以解决自动收缩、负载均衡等高级特性
Centimeter:提供对物理资源以及虚拟资源的监控,并记录这些书库,读数据进行分析在一定条件下出发现货供应动作
控制节点通常来说只需要一个网络端口来用于通信和管理各个节点
1.5.1.1 解析
控制节点:(把控全局)统一管理,处理事务;并且进行分析后返回给客户,系统平台,运维人员
MySQL:Ceilometer计量服务统计数据的存储
RabbitMQ:消息代理。架构层:组件与组件之间的通讯,单个组件内部子功能模块之间的通讯
基础服务:集中化管理
网络接口:网卡
1.以网络层面,管理其它节点即以一种网卡类型去管理或者做一种类型的职能
2.以网卡职能划分网络类型,管理网络
管理网络:管理其它节点,
其它节点的管理网络:接受其它控制节点请求,且通过管理网络把数据返回
配置文件中,指定对接网卡的编号
每个网卡有不同的职能,有对应的网卡编号,
控制节点:分发任务,主要管理其它节点(管理者)
控制节点可以跑实例资源(处理具体任务)
1.5.2 计算节点
负责虚拟机运行
计算节点架构
计算节点包含Nova、Neutron、Telemter三个服务
1.基础服务
Nova:提供虚拟机的创建、运行、迁移、快照等围绕虚拟机的服务、并提供API与控制节点对接、由控制节点下发任务
Neutron:提供计算节点与网络节点之间的通信
2.扩展服务
Telmeter:提供计算节点监控代理、将虚拟机的情况反馈的控制节点,是Centimeter的代理服务
计算节点包含最少两个网络端口
端口1:与控制节点进行通信,受控制节点统一调配
端口2:与网络节点,存储节点进行通信
1.5.2.1 解析
计算节点:
(负责一些具体的实例的创建,资源管理,各种精细化具体操作)
基础服务:
Nova:
1.实例生命周期的管理
2.负责调用底层VMM的资源供给虚拟机使用
网络插件代理:
通过插件和代理来实现网络二层,三层的具体功能
扩展服务:
Ceilometer Agent
计量 代理
定向管理,监控,并且统计资源,把资源给控制节点中的Ceilometer,计算出资源使用量,按量收集
管理网络:接受控制节点的调度管理
数据网络:与数据库进行对接,把资源存储在数据库中
1.5.3 网络节点
负责对外网络与内网之间的通信
网络节点架构
网络节点仅包含Neutron服务
Neutron:负责管理私有网络与公有网络的通信,以及管理虚拟机网络之间通信/拓扑、管理虚拟机之上的防火墙等等
网络节点包含三个网络端口
端口1:用于与控制节点进行通信。
端口2:用于除了控制节点之外的计算/存储节点之间的通信
端口3:用于外部的虚拟机与相应的网络之间通信
1.5.3.1 解析
网络节点:
(提供了openstack架构内各个组件,节点之间通讯)
与计算机中数据网络相互关联
基础服务Neutron:网络资源的具体实现
管理网络:eth1 接受控制节点的任务调度,通过不同的接口类型(网卡)去实现整个openstack中,架构的互相调用和控制
数据网络:eth2 数据库服务,数据信息的交互,提供数据资源
外部网络:eth3 只负责与外部第三方组件进行对比,关联,集成
1.5.4 存储节点
负责对虚拟机的额外存储管理等等
存储节点架构
存储节点包含Cinder,Swift等服务
Cinder:块存储服务,提供相应的块才能出,简单来说,就是虚拟出一块存盘,可以挂载到相应的虚拟机之上,不收文件系统的影响,对虚拟机来说,这个操作像是加了一块硬盘,可以完成对磁盘的任何操作,包括挂载、卸载、格式化,转换文件系统等等操作,大多应用于虚拟机空间不足的情况下的空间扩容等
Swift:对象存储服务,提供相应的独享存储、简单来说,就是虚拟出一块磁盘空间,可以在这个空间当中存放文件,也仅仅只能存放文件,不能进行格式化,转换文件系统,大多应用于云磁盘/文件
存储节点包含最少两个网络端口
端口1:与控制节点进行通信,接受控制节点任务,受控制节点统一调配
端口2:与计算/网络节点进行通信,完成控制节点下发的各类任务
1.5.4.1 解析
存储节点:提供存储服务
基础服务:Cinder Swift (存储服务)
openstack原生架构中的数据服务
数据管理:通过数据网络将资源供给计算节点中的实例使用
二 OpenStrack模块介绍
2.1 控制台Horizon(图形化界面)
管理,控制OpenStack服务的Web控制面板
openstack是一个架构,由多个节点服务器组成,这些服务器为实现同一个任务,而做虚拟化,将资源整合成一个整体,对外进行分配,使用
2.1.1 Horizon特点
实例管理
访问与安全管理
偏好设定
镜像管理
用户管理
卷管理
对象存储处理
2.2 身份认证模块Keystone
负责管理身份验证,服务规则和服务令牌功能的模块
2.2.1 Keystone涉及概念
User(用户)
Tenant/tone(租户/项目)互相独立
Role(角色)不同用户,不同权限。权限分类
Service(服务)
Token(令牌)
Endpoint(端点)
2.2.2 身份认证模块Keystone
Keystone涉及概念
Keystone工作流程图

2.3 镜像模块Glance
提供发现,注册和下载的镜像服务,虚拟机镜像的集中式仓库
通过虚拟机镜像创建虚拟机
2.3.1 Glance主要组件
glance-api
glance-registry
database
storage repository for image files
2.3.2 镜像的格式
RAW VDI
QCOW2 ISO
VHD AKI,ARI,AMI
VMDK
2.4 网络模块Neutron
实现实例与实例之间以及实例与外部网络之间的通信
提供二层(L2)vSwitch交换和三层(L3)Router路由抽象功能
内网 外网
示例:openstack中根据镜像创建的虚拟机
2.4.1 实现功能
Router:为用户提供路由,NAT等服务
Network:对应于一个真实物理网络中的二层局域网(VLAN)
Subnet:指定一段IPV4或IPV6地址并描述其相关的配置信息
2.5 虚拟网络
对二层物理网络Network的抽象与管理(局域网之间通信,vm之间)
虚拟交换机/网桥
虚拟路由器
Namespace
DHCP
浮动IP地址
2.5.1 组网模型
Local
Flat
VLAN
Overlay之VXLAN(内部为二层物理。通过隧道进行传输数据信息)
2.6 块存储Cinder
提供对Volume从创建到删除整个生命周期的分类
2.6.1 Cinder功能
提供REST API
调度Volume创建请求,合理优化存储资源的分配
支持多种back-end(后端)存储方式
2.6.2 Cinder组件
Cinder-Api Cinder-Backup:
Cinder-Volume Message Queue
Cinder-Scheduler Database
2.7 对象存储swift
使用普通硬件来构建冗余的,可扩展的分布式对象存储集群。存储容量可达PB级
Swift属于对象存储,用于永久类型的静态数据的长期存储(如虚拟机镜像,图片存储,邮件存储和存档备份)
2.7.1 Swift特点
极高的数据持久性, 为单点故障
完全对称的系统架构 简单,可依赖
无限的可扩展性
2.7.2 Swift组件
代理服务(ProxyServer)
认证服务(AuthenticationServer)
缓存服务(CacheServer)
账户服务(AccountServer)
容器服务(ContainerServer)
对象服务(ObjectServer)
复制服务(Replicator)
更新服务(Updater)
审计服务(Auditor)
账户清理服务(AccountReaper)
2.7.3 Swift存储结构
Objects
Accounts
Containers
Tmp
async_pending
quarantined
三 OpenStack 环境部署
多个用户同时提交创建虚拟机,只有一个节点压力大
有多个节点,控制节点接收请求,并将请求发送给计算节点,进行调度,如存在多个计算节点,用户可以并行操作。
3.1 部署准备
虚拟机资源信息
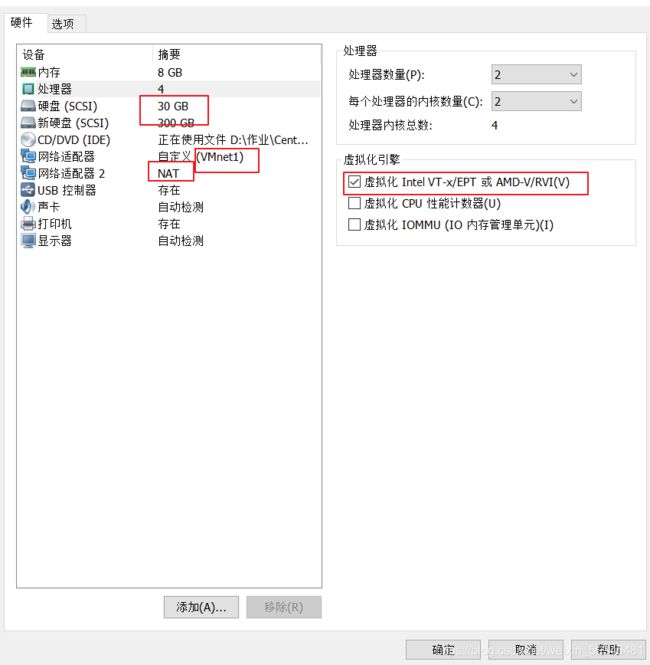
1、控制节点ct(controller)
CPU:双核双线程-CPU虚拟化开启
内存:8G 硬盘:30G+300G(CEPH块存储)
双网卡:VM1-(局域网)192.168.100.11 NAT-20.0.0.11
操作系统:Centos 7.6(1810)-最小化安装
2、计算节点c1(compute01)
CPU:双核双线程-CPU虚拟化开启
内存:8G 硬盘:30G+300G(CEPH块存储)
双网卡:VM1(局域网)-192.168.100.12 NAT-20.0.0.12
操作系统:Centos 7.6(1810)-最小化安装
3、计算节点c2(compute02)
CPU:双核双线程-CPU虚拟化开启
内存:8G 硬盘:30G+300G(CEPH块存储)
双网卡:VM1(局域网)-192.168.100.13 NAT-20.0.0.13
操作系统:Centos 7.6(1810)-最小化安装
PS:最小内存6G
3.2 部署思路:
1,配置操作系统+OpenStack运行环境
2,配置OpenStack平台基础服务(rabbitmq,mariadb,memcache,Apache)
rabbitmq:各个组件之间传递信息,消息队列
mariadb:数据库
memcache:身份验证存储令牌,数据库
RabbitMQ解析:
各个组件之间的交互是通过“消息队列”来实现的,就是使用RabbitMQ
其中,有这样几个角色:producer, consumer, exchange, queue
producer是消息发送者,consumer是消息接受者,中间要通过exchange和queue。producer将消息发送给exchange,exchange决定消息的路由,即决定要将消息发送给哪个queue,然后consumer从queue中取出消息,进行处理
消息发出,资源正被占用,这时,需要等待到资源占用释放,才可以进行任务
如一直等待,直到资源被释放,才执行任务,叫同步调用
如将任务排列在这等待,自己继续进行其他任务,叫异步调用
网卡设置
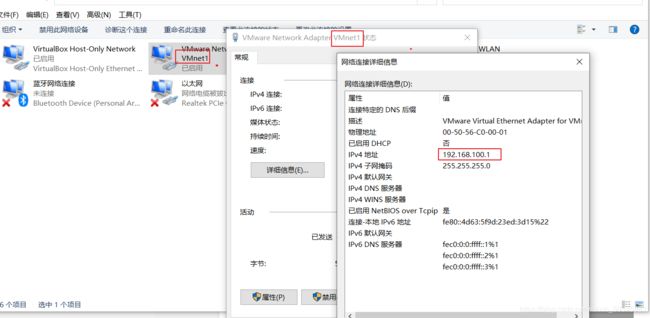

安装CentOS7.6
先开启VMnet1,后添加NAT网卡,开启虚拟化
在安装过程中设置
选择Install CentOS 7
按tab键,输入命令net.ifnames=0 biosdevname=0
创建时修改网卡为eth0

最小化安装

设置安装目标位置
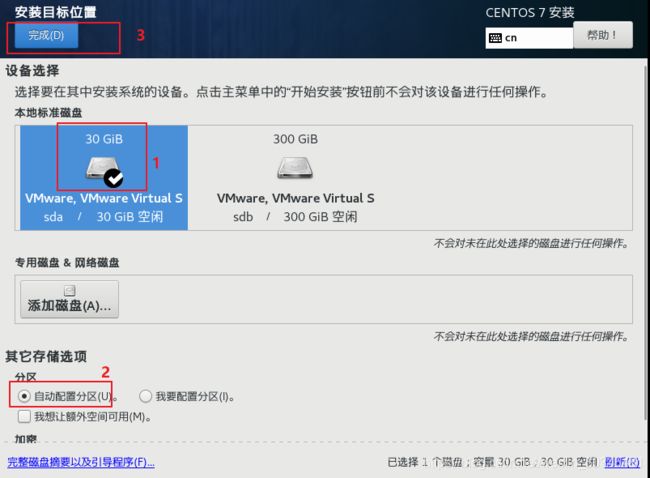
查看网卡设置
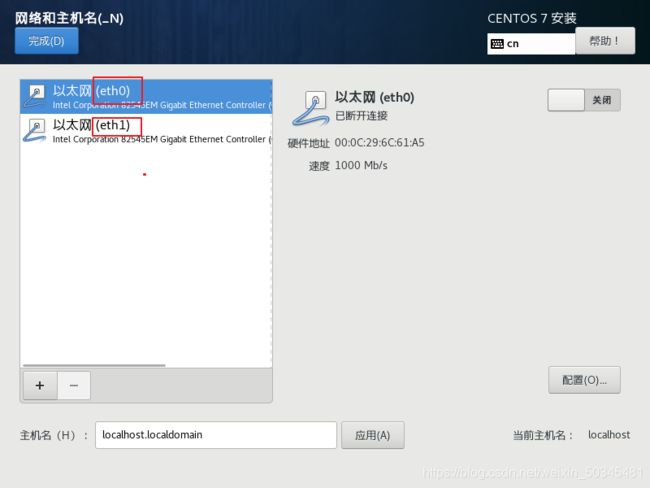
安装完成设置网卡

设置eth0
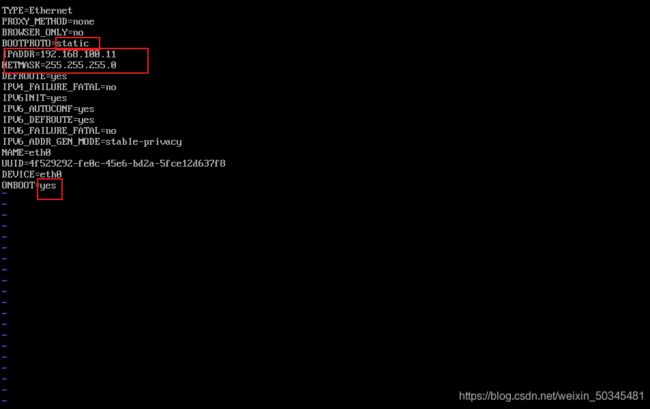
设置eth1

查看网卡情况
网络联通性
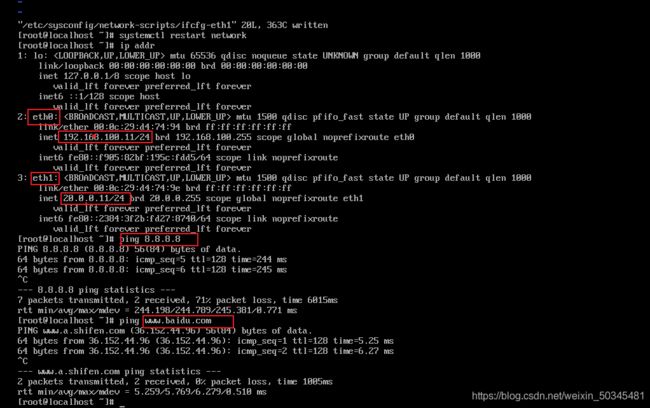
其它两台节点设置


重命名
[root@localhost ~]# hostnamectl set-hostname controller
[root@localhost ~]# su
[root@localhost ~]# hostnamectl set-hostname compute01
[root@localhost ~]# su
[root@localhost ~]# hostnamectl set-hostname compute02
[root@localhost ~]# su
3.3 部署流程
初始化设置
3.3.1 关闭防火墙
面向所有设备
[root@controller ~]# systemctl stop firewalld
[root@controller ~]# setenforce 0 核心防护关闭
[root@controller ~]# systemctl disable firewalld
[root@controller ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
[root@controller ~]# grep -v "#" /etc/selinux/config

3.3.2 免交互
设置映射(内部网址)
[root@controller ~]# vi /etc/hosts
添加
192.168.100.11 controller
192.168.100.12 compute01
192.168.100.13 compute02

[root@controller ~]# ssh-keygen -t rsa 生成密钥
[root@controller ~]# ssh-copy-id controller 公钥传递
[root@controller ~]# ssh-copy-id compute01
[root@controller ~]# ssh-copy-id compute02



进行身份验证
在控制节点上
[root@controller ~]# ssh root@compute01
[root@compute01 ~]# exit
[root@controller ~]# ssh root@compute02
[root@compute02 ~]# exit

在计算节点01上
[root@compute01 ~]# ssh root@controller
[root@controller ~]# exit
[root@compute01 ~]# ssh root@compute02
[root@compute02 ~]# exit

在计算节点02上
[root@compute02 ~]# ssh root@controller
[root@controller ~]# exit
[root@compute02 ~]# ssh root@compute01
[root@compute01 ~]# exit

3.3.3 安装基础环境依赖包
面向所有节点
[root@controller ~]# yum -y install net-tools bash-completion vim gcc gcc-c++ make pcre pcre-devel expat-devel cmake bzip2
net-tools 可以使用ifconfig命令
bash-completion 自动补全
pcre 正则 devel库
expat-devel:Apache依赖包,C语言开发,解析XML文档的开发库
[root@controller ~]# yum -y install centos-release-openstack-train python-openstackclient openstack-selinux openstack-utils
centos-release-openstack-train 保证安装更新openstack版本为最新版本t版
python-openstackclient openstack的python客户端
因为openstack中的API大多数是python编写的,并且连接数据库,也需要python
openstack-selinux openstack核心安全防护
openstack-utils openstack其它util工具
以上安装操作多进行几次,避免对后期的rabbitmq部署配置引发问题
3.3.4 设置时间同步
安装同步软件
[root@controller ~]# yum -y install chrony
在控制节点上设置为同步源
[root@controller ~]# vi /etc/chrony.conf
默认指向centos时间同步服务器
添加修改
server ntp.aliyun.com iburst 设置为时间同步源
allow 192.168.100.0/24 为192.168.100网段提供时间同步
[root@controller ~]# systemctl restart chronyd 重启服务
[root@controller ~]# systemctl enable chronyd 自启动
[root@controller ~]# chronyc sources 更新
iburst可以直接同步一个大的时间跨度
例如:
刚创建一个虚拟机
时间设置为 2020年8月可以使用iburst直接立刻同步到现在时间2021年1月
不使用iburst
会以缓慢方式向标准时间进行靠拢
在生产环境里面,要看需求情况使用这个参数
(闰年,多一天,少一天,直接同步会产生影响)
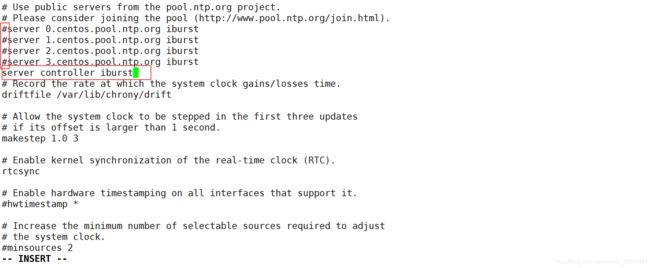

在计算节点1.2上
[root@compute01 ~]# vi /etc/chrony.conf
添加
server controller iburst 设置时间同步源为控制节点
[root@compute01 ~]# systemctl restart chronyd
[root@compute01 ~]# systemctl enable chronyd
[root@compute01 ~]# chronyc sources
控制时间同步后台进程去搜索关联同步的时间服务器信息

3.3.5 设置任务计划
面向所有节点
[root@controller ~]# crontab -e
[root@controller ~]# date 查看当前时间
*/30 * * * * /usr/bin/chronyc sources >> /var/log/chronyc.log
分钟小时日期月星期 追加 日志文件
时间间隔设置不要太小,尽量拉长,因为频次太快,导致日志量越来越大,存储空间受影响

配置系统环境
配置服务(控制节点上)
3.3.6 安装,配置MariaDB
[root@controller ~]# yum -y install mariadb mariadb-server python2-PyMySQL
mariadb-server :mariadb服务器
此包用于openstack的控制端连接mysql所需要的模块,如果不安装,则无法连接数据库;此包只安装在控制端
[root@controller ~]# yum -y install libibverbs 底层库文件
设置mysql配置文件
[root@controller ~]# vi /etc/my.cnf.d/openstack.cnf
添加
[mysqld]
bind-address=192.168.100.11 控制节点局域网地址(绑定内网地址)本地数据库节点ip
default-storage-engine=innodb 默认存储引擎
innodb_file_per_table=on 每张表独立表空间文件(文件存储空间)
max_connections=4096 最大连接数
collation-server=utf8_general_ci 默认字符集(不区分大小写)
character-set-server=utf8 字符集utf8_bin区分大小写

mysql 5.6(大版本)和mysql 5.7(小版本)
大版本更新内容更为复杂
小版本更多是修复bug,打补丁
mysql 5.7把mysql 5.6 收购
在读写分离操作时 5.6 5.7
对应的默认库文件 test mysql
客户端无法远程连接到数据库
5.7把 5.6 收购,在5.7中进行调整:
底层库文件 test mysql 库文件
表空间(类似名称空间)
名称文件:是一种相互独立的隔离环境
docker 容器
k8s 都会涉及到名称空间隔离(6种隔离的环境,作为空间隔离的判读依据)
[root@controller ~]# systemctl enable mariadb 自启动数据库
[root@controller ~]# systemctl start mariadb 开启数据库服务
[root@controller ~]# mysql_secure_installation 数据库初始化设置
[root@controller ~]# mysql -uroot -pabc123 测试登录数据库



3.3.7 安装RabbitMQ(消息队列)
所有创建虚拟机的指令,控制端都会发送到rabbitmq,node节点监听rabbitmq
安装软件
[root@controller ~]# yum -y install rabbitmq-server
[root@controller ~]# systemctl enable rabbitmq-server 自启动
[root@controller ~]# systemctl start rabbitmq-server 开启服务
报错解决方案
1.检查之前安装的软件环境是否安装成功
2.重新安装完成软件环境,要先杀死rabbitmq的所有进程

创建消息队列用户,用于controler和node节点连接rabbitmq的认证
[root@controller ~]# rabbitmqctl add_user openstack RABBIT_PASS
用户名 密码
Creating user "openstack"
因为rabbitmq跑在openstack平台里,作为数据交互和传递的载体时,因为需要被keystone认证,有用户身份来进行管理,便于认证
配置openstack用户的操作权限(正则,配置读写权限)
[root@controller ~]# rabbitmqctl set_permissions openstack ".*" ".*" ".*" 配置文件 写
读
Setting permissions for user "openstack" in vhost "/"
Nova与Keystone进行通讯
1.rabbidb,把nova请求读取写入到本地内部
2.Nova把请求相关写入到Rabbitmq的内部
3.把消息传递过程中,也会进行读写操作
授予独立的用户身份,读写权限
[root@controller ~]# netstat -anptu | grep 5672
可查看25672和5672 两个端口(5672是Rabbitmq默认端口,25672是Rabbit的测试工具CLI的端口)

Nova与Keystone进行通讯
1.rabbidb,把nova请求读取写入到本地内部
2.Nova把请求相关写入到Rabbitmq的内部
3.把消息传递过程中,也会进行读写操作
授予独立的用户身份,读写权限

查看rabbitmq插件列表
[root@controller ~]# rabbitmq-plugins list
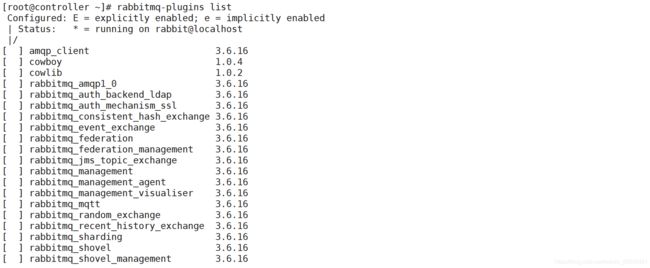
开启rabbitmq的web管理界面的插件,端口为15672(可以通过网页访问,图形化页面)
[root@controller ~]# rabbitmq-plugins enable rabbitmq_management
[root@controller ~]# netstat -anptu | grep 5672

在浏览器上
http://192.168.100.11:15672访问
默认账号密码都为guest


3.3.8 安装memcached
作用:
安装memcached是用来存储session(会话)信息;服务身份验证机制(keystone)使用memched来缓存令牌,在登录openstack的dashboard时,会产生一些session信息,这些session信息会存放到memcached中
介绍:
Memcached是一个自由开源的, 高性能,分布式内存对象缓存系统。
Memcached是以LiveJourmal旗下Danga Interactive公司的Brad Fitzpatric为首开发的一款软件。现在已成为mixi、hatena、 Facebook. Vox、 LiveJournal等众多服务中提高Web应用扩展性的重要因素
Memcached是一种基于内存的key-value存储,用来存储小块的任意数据(字符串、对象)。这些数据可以是数据库调用、API调用或者是页面渲染的结果
Memcached简洁而强大。它的简洁设计便于快速开发,减轻开发难度,解决了大数据量缓存的很多问题。它的API兼容大部分流行的开发语言。
本质上,它是一个简洁的key-value存储系统。
一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩展性。
并且在BAT里,redis已经逐渐取代了memcached,成为分布式场景广泛使用的缓存方案
差别总结:

[root@controller ~]# yum -y install memcached python-memcached
python模块在OpenStack中起到了连接数据库的作用
修改memcached配置文件
[root@controller ~]# vi /etc/sysconfig/memcached
PORT="11211" 默认端口号
USER="memcached" 默认账户名
MAXCONN="1024" 最大连接数
CACHESIZE="64" 缓存大小
OPTIONS="-l 127.0.0.1,::1,controller"
选项 添加主机名,控制节点所在

[root@controller ~]# systemctl enable memcached 自启动
[root@controller ~]# systemctl start memcached 开启服务
[root@controller ~]# netstat -anptu | grep 11211 查看端口状态
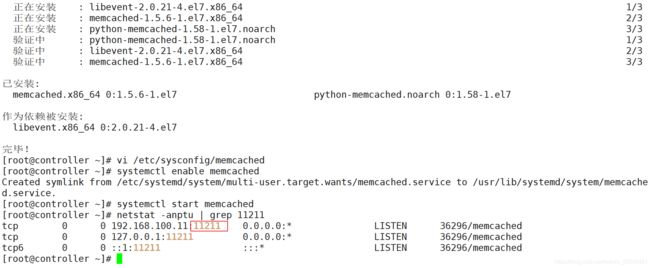
3.3.9 安装etcd
etcd特点:
简单: 基于HTTP+JSON的API让你可以用CURL命令就可以轻松使用。
安全: 可以选择SSL客户认证机制。
快速: 每个实例每秒支持一千次写操作。
可信: 使用Ralf算法充分实现了分布式。
应用场景
场景一: 服务发现
服务发现(Service Discovery)要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务如何才能找到对方并建立连接。
微服务协同工作架构中,服务动态添加(自愈性)
PaaS平台中应用多实例与实例故障重启透明化
场景二: 消息发布和订阅
在分布式系统中,最为适用的组件间通信的方式是消息发布和订阅机制。
具体而言,即配置一个配置共享中心,书籍提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦有关主题有消息发布,就会实时通知订阅者。通过这种方式可以实现发布式系统配种的集中式管理和实时动态更新。
应用中的一些配置新存放在etcd上进行集中管理
分布式日志收集系统
这个系统的核心工作是收集分布在不同机器上的日志。
系统中心需要动态自动获取与人工干预修改信息请求内容
通常的解决方案是对外保留接口,例如JMX接口,来获取一些运行时的信息或提交修改的请求。
而引入etcd后,只需要将这些信息存放在指定的etcd目录中,即可通过http接口直接被外部访问。
场景三: 负载均衡
场景四: 分布式通知与协调
与消息发布和订阅有点相似。两者都使用了etcd的Watcher机制,通过注册与异步通知机制,实现分布式环境下的不同系统之间的通知与协调,从而对数据变更进行实时处理。
实现方式通常为:
不同系统都在etcd上对同一个目录进行注册,同时设置Watcher监控该目录的变化(如果对子目录的变化也有需求,可以设置成递归模式),当某个系统更新了etcd的目录,那么设置了Watcher的系统就会受到通知,并做出相应的通知,并作出相应处理。
通过etcd进行低耦合的心跳检测
检测系统和被检测系统通过etcd上某个目录管理而非直接关联起来,这样可以大大减少系统的耦合性。
通过etcd完成系统调度
某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台做的一些操作,实际上只需要修改etcd上某些目录节点的状态,而etcd就会自动把这些变化通知给注册了Watcher的推送系统客户端,推送系统再作出相应的推送任务。
通过etcd完成工作汇报
大部分类似的任务分发系统,子任务启动后,到etcd来注册一个临时工作目录,并且定时将自己的进度汇报(将进度写入到这个临时目录),这样任务管理者就能够实时知道任务进度。
场景五: 分布式锁
因为etcd使用Raft算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。
锁服务有两种使用方式,一是保持独占,二是控制时序。
保持独占
即所有试图获取锁的用户最终只有一个可以得到。
控制时序
即所有试图获取锁的用户都会进入等待队列,获得锁的顺序是全局唯一的,同时决定了队列执行顺序。
场景六: 分布式队列
分布式队列的常规用法与场景五中所描述的分布式锁的控制时序用法类似,即创建一个先进先出的队列,保证顺序。
场景七: 集群监控与Leader竞选
通过etcd来进行监控实现起来非常简单并且实时性强,用到了以下两点特性:
前面几个场景已经提到了Watcher机制,当某个节点消失或由变动时,Watcher会第一时间发现并告知用户。
节点可以设置TTL key,比如每隔30s向etcd发送一次心跳使代表该节点依然存活,否则说明节点消失。
场景八: 为什么使用etcd而不用Zookeeper?
相比较之下,Zookeeper有如下缺点:
复杂。 Zookeeper的部署维护复杂,管理员必须掌握一系列的知识和技能;而Paxos强一致性算法也是素来以复杂难懂而闻名于世;另外,Zookeeper的使用也比较复杂,需要安装客户端,官方只提供Java和C的两种语言的接口。
Java编写。这里不是对Java有偏见,而是Java本身就偏向重型应用,它会引入大量的依赖。而运维人员则普遍希望机器集群能尽可能的简单,维护起来也不容易出错
发展缓慢。 Apache基金会项目特有的“Apache Way”在开源界也饱受争议,其中一大原因就是由于基金会庞大的结构和松散的管理导致项目发展缓慢。
etcd作为一个后起之秀,其优点也很明显:
简单。 使用Go编写部署简单;使用HTTP作为接口使用简单;使用Raft算法保证强一致性让用户易于理解。
数据持久化。 etcd默认数据一更新就进行持久化。
安全。 etcd支持SSL客户端安全认证。
安装etcd
[root@controller ~]# yum -y install etcd
修改配置文件
[root@controller ~]# cd /etc/etcd/
[root@controller etcd]# ls -lh
[root@controller etcd]# vi etcd.conf
修改
ETCD_DATA_DIR="/var/lib/etcd/default.etcd" 数据目录位置
ETCD_LISTEN_PEER_URLS="http://192.168.100.11:2380"
监听其他etcd member的url(2380端口,集群之间通讯,域名为无效值)
ETCD_LISTEN_CLIENT_URLS="http://192.168.100.11:2379"
对外提供服务的地址(2379端口,集群内部的通讯端口)
ETCD_NAME="controller"
集群中节点标识(名称)
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.100.11:2380"
该节点成员的URL地址,2380端口:用于集群之间通讯。
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.100.11:2379"
ETCD_INITIAL_CLUSTER="controller=http://192.168.100.11:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster-01" 集群唯一标识,群集名称
ETCD_INITIAL_CLUSTER_STATE="new"
初始集群状态,new为静态,表示单个节点
若为existing,则表示此ETCD服务将尝试加入已有的集群,初始化完成后,会根据自己的集群名称自动寻找其它相同集群名称的ETCD
若为DNS,则表示此集群将作为被加入的对象,等待加入状态


[root@controller etcd]# systemctl enable etcd 自启动
[root@controller etcd]# systemctl start etcd 开启服务
[root@controller etcd]# systemctl status etcd 服务状态
[root@controller etcd]# netstat -anptu | grep 2379 查看端口
[root@controller etcd]# netstat -anptu | grep 2380


总结
通过以上搭建openstack基础环境架构进一步的熟悉了解openstack服务部署流程,部署按控制节点与计算节点向结合的方式配置。
openstack
基础环境
1.防火墙,核心防护,DNS,网卡,映射,免交互,时间同步
2.openstack 依赖环境(openstack-T版的软件源/包,python在openstack中的client环境,openstack-util工具和openstack-selinux核心防护)
3.数据库,mysql memcached etcd
4.rabbitmq
5.第三方工具