python一些常用语句和语法记录
备忘查询
目录
一些操作
*和**传递参数
时间日期处理
添加包的搜索路径sys.path
保留固定位数的小数
格式化字符串标准输出格式
argparse 解析命令
快捷方式查询
实时监控GPU
ffmpeg直接录制视频
youtube-dl下载youtube视频
python可执行bash
中文编码问题
python脚本执行命令行
conda降级指定安装包
Class相关属性
迭代器的调用
super继承
文件操作
文件读写注意
文件遍历注意
debug
numpy
axis的理解
shape ( ,)与( ,1)的区别
列表/数组的索引
灵活的冒号和逗号索引
cv相关
PIL库
图片闪退
一些操作
进度条打印
其实挺简单,就是\r回到开头就行。参见:https://blog.csdn.net/s740556472/article/details/79767080
*和**传递参数
可以用在函数和类中传递参数,灵活多变。大致分为四类
- 单星号——调用
可以看出,就是将输入数据类型进行unpack后传入,unpack后数据长度必须和函数/类的形参个数一致否则报错。
def print_input(a,b,c):
print(a,b,c)
a=[1,2,3]
b=(4,5,6)
c=dict(q=7,w=8,e=9)
print_input(*a)
print_input(*b)
print_input(*c) #只有key没有value
1 2 3
4 5 6
q w e- 单星号——定义
这个比较常见,函数或类参数传递经常用的到。与上面相反,是pack功能,将输入函数/类的参数打包成元组传递
def print_input(*args):
print(args)
a=1
b=[1,2,3]
c=dict(q=4,w=5,e=6)
print_input(b)
print_input(a,b,c)
([1, 2, 3],)
(1, [1, 2, 3], {'q': 4, 'w': 5, 'e': 6})- 双星号——调用
最常见的就是这个了。传入**对象须为字典,**作用是unpack,将字典解压成key=value的等式形式传入函数中,其中key必须与形参严格一一对应不能有不匹配的项。虽然字典元素具有无序性,但是通过key的形参一致性进行实参对应的绑定,然后传入函数就不用担心unpack后的顺序问题。当然,长度也得一致。
def print_input(a,b,c):
print(a,b,c)
a=dict(a=1,b=2)
m=(1,2,3)
print_input(**a,c=m)
1 2 (1, 2, 3)
#print_input(**a,c=m)等价于: print_input(a=1,b=2,c=m),不仅指定了实参,还用key指定了形参,必须匹配,否则报错
# 错误如 a=dict(a=1,b=2) m=(1,2,3) print_input(**a,m) 没有固定形参c的传输对象
# a=dict(a=1,q=2) m=(1,2,3) print_input(**a,m) 没有形参q- 双星号——定义
这个也很常见,就比较简单了,将输入的等式压缩打包成字典形式,输入长度不限,形式不限
import torch
def print_input(**kwargs):
print(kwargs)
print_input(a=1,name='Bob',content=[1,2,3],tensor=torch.randn(3,3))
{'a': 1, 'name': 'Bob', 'content': [1, 2, 3],
'tensor': tensor([[ 0.2964, -0.2142, -0.9612],
[ 0.5923, -2.4604, 0.0199],
[ 1.4155, 0.8309, 0.7050]])}时间日期处理
http://www.wklken.me/posts/2015/03/03/python-base-datetime.html#1-datetime
添加包的搜索路径sys.path
sys.path变量在import sys后可以使用,返回的是包搜索路径的列表,可以通过:
sys.path.append(ROOT_DIR)添加某特定目录为搜索路径,从而可以很方便地import需要的包了 (写demo测试很好用)
保留固定位数的小数
用于文件写入之类的,很方便,常用
from decimal import Decimal
a = 1 / 3
print(a)
a = Decimal(a).quantize(Decimal('0.00'))
print(a)
a = Decimal(a).quantize(Decimal('0.0000'))
print(a)
0.3333333333333333
0.33
0.3300格式化字符串标准输出格式
包含各种格式输出:
http://www.runoob.com/python/python-strings.html
打印的时候最好还是用format格式化好看:
print("网站名:{name}, 地址 {url}".format(name="ming71", url="https://github.com/ming71"))
网站名:ming71, 地址 https://github.com/ming71
argparse 解析命令
三步:
- 创建 ArgumentParser() 对象
- 调用 add_argument() 方法添加参数
- 使用 parse_args() 解析添加的参数
参数分为两种:定位参数和可选参数
- 定位参数:必选,在输入时必须输入该参数,以及赋值(可用默认值)
- 可选参数:可以选择输入时是否键入,特点是有“--”
import argparse
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('integers', metavar='N', type=int, nargs='+',
help='an integer for the accumulator')
parser.add_argument('--sum', dest='accumulate', action='store_const',
const=sum, default=max,
help='sum the integers (default: find the max)')
args = parser.parse_args()
print args.accumulate(args.integers)
$ python argparse_usage.py
usage: argparse_usage.py [-h] [--sum] N [N ...]
argparse_usage.py: error: too few arguments
$ python argparse_usage.py 1 2 3 4
4
$ python argparse_usage.py 1 2 3 4 --sum
10十分强大,更多功能:
http://wiki.jikexueyuan.com/project/explore-python/Standard-Modules/argparse.html
https://zhuanlan.zhihu.com/p/34395749

快捷方式查询
实时监控GPU
监控gpu使用
watch -n 0.5 nvidia-smi监控温度
watch -n 0.5 nvidia-smi -q -i 0,1 -d TEMPERATURE(每0.5秒刷新一次)
ffmpeg直接录制视频
ffmpeg -video_size 1024x768 -framerate 25 -f x11grab -i :0.0+100,200 output.mp4
youtube-dl下载youtube视频
安装一些相关的包,可百度youtube-dl安装,然后下载命令:
1.youtube-dl --list-extractors #查看支持网站列表
2.youtube-dl -U #程序升级
3.youtube-dl --get-format URL #获取网站能下的视频格式
4.youtube-dl -F URL #获取所有格式(目前仅支持YouTube),例如:
5.youtube-dl -F https://www.youtube.com/watch?v=nCfrfCzaB2A
6.--max-quality #下载的是上面的(best) 1280*720
#如果你想下真正的最高画质需要分别下上面的138和140,然后用视频软件合成。
#下载普通的视频只需要youtube-dl https://www.youtube.com/watch?v=nCfrfCzaB2A 默认下载下来的格式为webm
7.youtube-dl -f format URL #下载指定格式的视频,这里以下载1080p原画质量的视频格式为例:
8.youtube-dl -f 137 http://www.youtube.com/watch?v=n-BXNXvTvV4
9.下不下来时试试强制IPV4下载:youtube-dl --force-ipv4 url
简单点:
youtube-dl https://www.youtube.com/watch?v=N1ZgIkJ0bvY
消除因为跑GPU带来的CPU加速警告
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'写入待编译py文件中即可
python可执行bash
#!/home/xiaoming/anaconda3/envs/keras/bin/python3写入待编译py文件首,该路径是python解释器路径,我选择的时anaconda-python的。
然后该py文件就可以./执行了
注意:得放在第一行!!
中文编码问题
# -*- coding: utf-8 -*-文档中有中文注释,最好使用utf-8编码,否则换环境可能乱码。
python脚本执行命令行
无敌好用!使用os模块:
os.system(cmd)import os
status=os.system('cd ~/ev/yolo-master/keras-yolo3 && python yolo.py')
#status=0时执行正常注意:囿于os.system()的机制问题,只能cd后在一句语句中完成所有命令,并且父进程不会真的cd到指定目录!!(也可以用surprocess模块)
conda降级指定安装包
conda install -c conda keras==2.1.2Class相关属性
迭代器的调用
可以用next()方法获取generator的值
https://blog.csdn.net/brucewong0516/article/details/79121179
关于内建函数的理解:
其实就是对基本操作的高级修改!比如__len__方法,如果你实例化了一个类a=A(),不自己定义len(),那么返回的为默认的len()方法,如果你定义一下:def __len__(): return 'hello'.那么调用len(a)它就给你返回‘hello’。
对于迭代器也是一样的,如def __iter__(self):和def __next__(self):,前者是创建迭代器(可以理解为初始化),后面的是每次迭代执行的操作,比如:
# 迭代器理解
class Test():
def __init__(self,files):
self.files=files
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
if self.count == 3:
raise StopIteration
img_path = files[self.count]
return img_path,2
def __len__(self):
return 1
img_name=Test(files)
#上面的类实例化创建迭代器后,一旦参与迭代,首先运行__iter__(self)初始化,然后不断__next__(self)迭代,直到抛出异常,可以看出,return两个值
for i, (img_paths, img) in enumerate(img_name):
print(i,img_paths,img)
0 D:\application\visual studio\GaussianFilter\mean_filter\x64\Debug\BlueCup.jpg 2
1 D:\application\visual studio\GaussianFilter\mean_filter\x64\Debug\cameraman.tif 2
2 D:\application\visual studio\GaussianFilter\mean_filter\x64\Debug\dl.JPG 2super继承
- 低级理解
首先:http://www.runoob.com/python/python-func-super.html讲的不错,大意就是一句话:
super() 将当前类的对象self转化为父类的对象,如继承自nn.Module,一般都要调用super()继承父类的很多属性和方法。
意思就是,你想在子类实现自己的一些方法,但是子类方法和父类重名会覆盖父类的方法,于是可以调用super实现对父类方法的继承,按照一定顺序先后执行子类父类的方法。
实际用的时候大多都是一个场景:继承父类的构造函数。很好理解,因为继承父类的很多方法,需要和父类相同的构造函数初始化才能调用。如:继承自nn.Module的类,继承其构造函数时都是super(Upsample, self).__init__(),不传递参数,原因是,pytorch的源码中nn.Module构造函数就没有传递任何参数,保持一致性。
- 高级理解
进一步的,关于单继承和多继承的super这个链接说的很明白:https://mozillazg.com/2016/12/python-super-is-not-as-simple-as-you-thought.html
归纳一下就是:
1. 首先有个 类方法__mro__很好用,直接调用类名加该方法如:MaskRCNN.__mro__(注意:是类名,不实例化的对象名),可以查看类搜索的顺序
2.对于单继承问题很简单,按照MRO列表向前搜索,然后反过来由内而外依次执行,比如下面的例子,搜索B->A,而执行的时候是从内层的A函数到B,直到这一点就足够读懂很多深度继承的网络模型定义了,它们都是逐层继承构造函数,直到最终的基类nn.Module,执行时会从内层向外执行所有的构造函数,参见mmdetection的MaskRCNN定义。
class A(object):
def __init__(self):
self.n = 2000
def add(self, m):
# 第二步:
# 得到对象的n=3,执行add运算,m=0
# n=3+0=3
self.n += m
print('running A n=%d'%self.n)
class B(A):
def __init__(self):
self.n = 3
def add(self, m):
# 第一步:
# 将B的self对象转换为父类A的,并继承A的add函数
super(B,self).add(m)
# 第三步:
# 回到B继续执行B的后续语句,执行加法
# n=3+3=6(这里不涉及回传A中计算得到的n=3,而是第二步的计算本身就是在B中执行的,因为超类继承对象转换)
self.n += 3
print('running B n=%d'%self.n)
b = B()
b.add(0)
print(b.n)
B.__mro__
running A n=3
running B n=6
6
(__main__.B, __main__.A, object)3.多继承
这个就比较秀了,m2det中用到了多继承,还是mark一下。
解决的问题:如对西瓜,猫基类进行分类,分类可以为雌性/雄性,也可以为动物/植物,如果传统二叉树分类会随类别而指数级爆炸,因此采用多类继承的方法。
和单继承的区别:就是搜索顺序,广度优先,使用class_name.__mro__或者class_name.mro()可以查看
class A(object):
def __init__(self):
self.n = 2
def add(self, m):
self.n += m
print('running A +m n=%d'%self.n)
class B(A):
def __init__(self):
self.n = 3
def add(self, m):
super(B,self).add(m)
self.n += 3
print('running B +3 n=%d'%self.n)
class C(A):
def __init__(self):
self.n = 4
def add(self, m):
super(C,self).add(m)
self.n += 4
print('running C +4 n=%d'%self.n)
class D(B, C):
def __init__(self):
self.n = 5
def add(self, m):
super(D,self).add(m)
self.n += 5
print('running D +5 n=%d'%self.n)
d = D()
d.add(0)
print(d.n)
D.__mro__
running A +m n=5
running C +4 n=9
running B +3 n=12
running D +5 n=17
17
(__main__.D, __main__.B, __main__.C, __main__.A, object)文件操作
语句:http://blog.51cto.com/liuzhengwei521/1892211
文件读写注意
注意!python没有删除行方法,只能读取后重写!而且,重写不能覆盖源文件,最好重新建一个文件!!否则无效
(去掉空行弄了好久才发现是这个问题)
(可以解决,但是这种方法比较简单)

文件遍历注意
python的for遍历文件,顺序是按照字符从小到大,不是int整型!!!!!
如文件名为1-100,他的遍历顺序为:1,10,100,2,。。。。

切记!!
解决方法很简单:(1)补零对齐 (2)提取编号转成数组再排序
debug
一个trick : 加一句a=input() 就OK,相当于C++的system("pause");
自从有了ipdb,debug再也不用input()了,十分方便
numpy
axis的理解
这篇博客讲的挺好:https://blog.csdn.net/fangjian1204/article/details/53055219
整理一下:二维数组中,axis=0是沿着纵轴操作,对象是索引,axis=0是沿着横轴操作。对于多维数组而言,实际上axis=i,是对下标为i的维度轴进行操作。可以想象,对于k维数组a,其维度编号0,1....k-1,依次是从外往内的,最后的索引如a[0:0:...:1],其中最后一维对应的数字才是真正贴近数值data的,其他的可以看做维度的扩张和选择过程,前面的很多0是在缩小选择范围最后的1才决定性取到了值,也就是最内层的维度,这样就可以理解了。
import numpy as np
a1=np.random.rand(3,3)
a2=np.random.rand(3,3,3)
b1=np.min(a1,axis=0)
b2=np.min(a2,axis=0)
print('a1:',a1)
print('a2:',a2)
print('b1:',b1)
print('b2:',b2)
a1: [[ 0.7574266 0.83122986 0.9602632 ]
[ 0.74055483 0.66450883 0.56583587]
[ 0.33758674 0.72998259 0.10543056]]
a2: [[[ 0.50169571 0.81683584 0.73059628]
[ 0.21065074 0.48884878 0.61444667]
[ 0.37762202 0.79229691 0.76464615]]
[[ 0.42680422 0.30909557 0.66330327]
[ 0.12870257 0.13053744 0.67944607]
[ 0.33531862 0.70035291 0.53043544]]
[[ 0.82509347 0.10511158 0.34749444]
[ 0.31722198 0.32350327 0.16058674]
[ 0.57899711 0.84316478 0.32287292]]]
b1: [ 0.33758674 0.66450883 0.10543056]
b2: [[ 0.42680422 0.10511158 0.34749444]
[ 0.12870257 0.13053744 0.16058674]
[ 0.33531862 0.70035291 0.32287292]] #这个三维数组按axis=0索引最小值,就是找最外面维度为单位的数组的最小值,因此是比较每个3*3数组元素选出一个3*3最小值。
shape ( ,)与( ,1)的区别
np.array()里面的参数从左往右先有几个" [ ",就是几维数组。如([1,2,3])的shape是(3,),表示是一维数组,三个元素;array([[1,2,3],[2,3,4]])代表二维数组了,两行三列;那么np.array([ [1],[2],[3] ]),其shape是(3,1)表示二维数组,三行每行一个元素。
sklearn和matplotlib很多函数传入需要是二维数组时,reshape一维(a,)成(a,1)就行了(随时记得检查数组维度,进行计算时不能有缺省,reshape)
reshape()参数中出现-1
代表略过此维度,根据其他维度自行计算填充。如3*3矩阵reshape(-1,1),就展成了列向量。
列表/数组的索引
列表的索引方式太强了!!!除了整数索引切片,还能花式索引,布尔索引!!十分好用。
如直接a[a>5]索引筛选,还有bool索引如下:

bool量作为索引,直接取出True对应的维度,False舍弃,做个多维的实验:
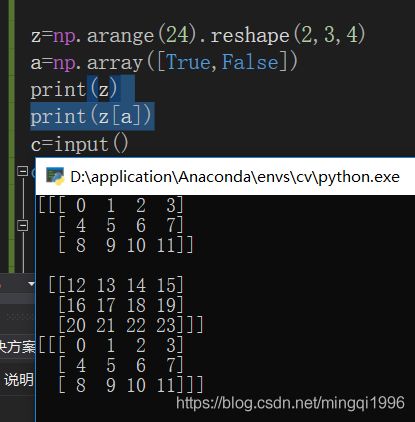
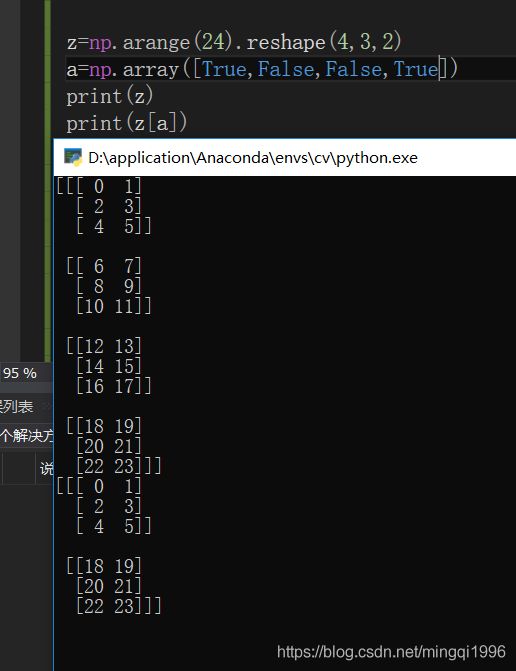
就可以解释了,bool索引只选择第一个维度,输入的bool矩阵必须和被索引矩阵的第一维度匹配,然后根据True的位置进行选择对应子模块。
灵活的冒号和逗号索引
用于opencv的bgr到rgb的转换
https://blog.csdn.net/pnnngchg/article/details/79420357
https://blog.csdn.net/qq1483661204/article/details/78149262(可百度:双冒号用法)
cv相关
PIL库
PIL的Image库的image对象使用open方法打开图片和opencv的imread返回参数不同,前者是w,h,后者opencv是(h,w,c).
import cv2
from PIL import Image
path=r'D:\application\visual studio\picture\person.jpg'
cv_img=cv2.imread(path)
pil_img=Image.open(path)
print(cv_img.shape)
print(pil_img.size)
(182, 277, 3)
(277, 182)图片闪退
加上cv2.waitKey(0)即可。