QQ音乐JS逆向爬虫,获取调皮的sign参数,我用python全都爬!
前言:
一周的时间又过去了,上一周分析了网易云的JS逆向爬虫,主要还是AES对称加密和RES非对称加密算法搞的鬼,导致很多人看了文章表示很难懂,debug也有的找不到,这我实在没办法了, 评论我是有问必答,更多的还是需要你们多阅读,仔细阅读,才行。
看了一下上周的数据,有点夸张啊,我一下子自己都懵了,
嘿嘿,当然我自己还是很开心的,文章收到了浏览,也是对自己的最大支持。
其实很久没有这么多人看我文章了, 平均每次都是三四百的访问量, 我都见怪不怪了,我现在大三了吧, 其实事情也很多,我有想做的事情,也有自己的想法,面对考研还是工作,我和你们都是一个样,纠结中,但是我最后可能还是会选择去考研,因为工作太累了吧, 我现在学的东西太多了,乱七八糟的的,这篇博客,是网易云的对应篇, 好兄弟就要一起整整齐齐被我们爬,如果还有没接触过网易云的爬虫的朋友们,可以点击阅读阅读,一定有收获的! 点击网易云爬虫阅读
对于QQ音乐, 其实也是参数加密的,只不过这个参数更加难搞, 他很调皮, sign参数, 我花了很多时间,用了很多方式,二三天的时间内,最后搞定, 我本人最开始只是学了python, 对于前端后端的了解,还只是小白阶段, 暑假内集训了前端的知识,最近二个星期内一直在看Django框架, 说这些不是说我怎么怎么样, 只是阐述一个很简单的道理,单单只会一个脚本语言是没有用的,程序员都是T型发展,哪里都需要涉足,尤其是爬虫来说, 啥都要会点, 但如果你只是入门了解了解, 当我没说过,简单入门,一周速成!
20岁的我,到底会怎么样,我自己也不知道,博客快3k粉丝了
, 再接再厉!!
>
这篇文章有点长,因为有点难懂, 我只是想讲清楚一点,给她看,或者 给一些基础不是很好的人看一下, 大佬可以亲喷点,代码用到了很多库,但是我再后面也会一个个提到,不影响各位阅读, 只要耐心的看,你就一定有收获。
文章三天之后设置为粉丝可见。
歌曲版权最终归QQ音乐所有!
我是沙漏,如果你喜欢我的文章,你可以点一个赞,收藏一次,关注下我,多谢。
有问题可以在评论区留言,我下课有时间就会回答你们,大三了有点小忙,
读后有收获,点赞,关注,加收藏,共勉!
点我,点我,点我呀!博主其他文章


爬虫高级必然JS逆向,QQ音乐爬虫就是一个很好的练手,读完学会了直接在你女朋友面前装一手,读完你将收获到,QQ音乐JS逆向,sign参数获取,songmid参数获取,vkey参数获取,selenium自动化解析,用python解析执行js代码。
效果图:
页面分析:
- 当我们打开QQ音乐的时候,你想要播放歌曲,页面会强制你登入账号,才能调用网页的播放器, 这是一个重要点, 所以后面的参数中,我们要加入账号信息, 这个爬虫是不能爬取vip视频的,凡是标题带爬vip视频的,一定要仔细看看, 腾讯这么大公司还会让你写个小爬虫就随便拿掉数据的,这不是瞎搞啊,所以我将的只是获取非会员歌曲的方式。
- 那下面就一步一步的开始吧!
1. 初步分析
首先我们随意的播放一些歌曲,如下:
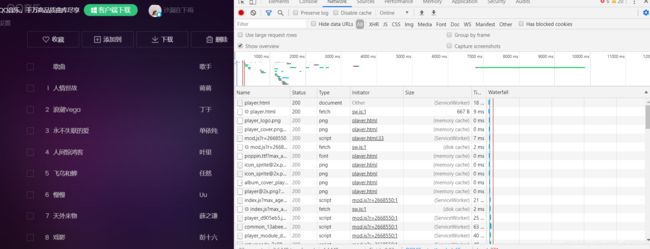
在调试中,我们可以找到这样的js文件,(具体怎么找,刷新一直点看呗,或者你眼尖可以看链接参数,没啥经验,就一个个点看看, 后面记得参数就可以直接用过滤器或者搜索 ),找到如下:
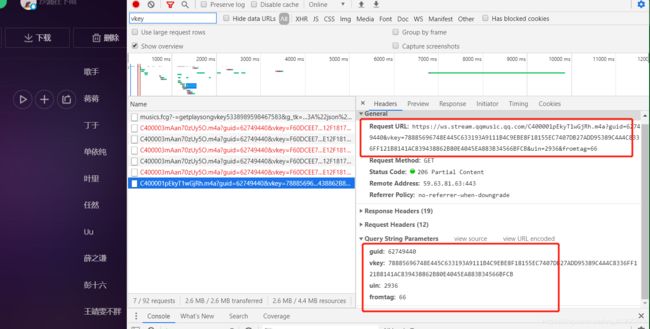
上面的框是这首歌对应的链接,复制打开在浏览器,就可以直接播放,下面的框是请求携带的参数,区别二首歌如下:
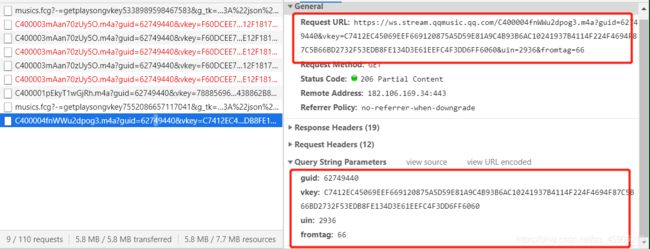
ps: 对于这个连接注意一点, 参数没有带r, 所以你找到的参数带r的,没有用,错了,对着我图仔细看看。
发现了吧,也就是vkey参数发现了变化。所以这个vkey参数是一个关键点。
那下面我们寻找vkey。
2. 寻找vkey
这个时候,我们就可以直接用过滤器了,因为知道是参数vkey, 如下:
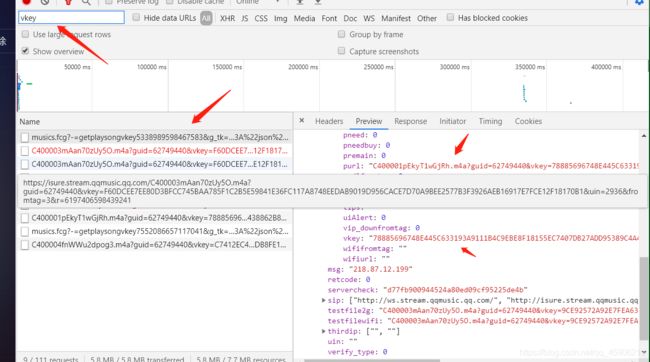
在 preview 中,我找到了vkey参数,但是细心的你会发现,这里直接就有一个网址参数, purl 对比之前的歌曲链接, 你会发现,前面少了一些而已, 少了 https://u.y.qq.com/cgi-bin/musics.fcg? 到时候直接加上去就得了, 所以不碍事,现在我们看一下这个链接的参数构成,如下:

对比分析发现, 有用的参数 sign, -, longinUin, data , 其他参数可有可无, 其中动态变化的参数是 sign 和 songmid, 那现在我们只需要找到这二个参数在哪里就行了。
3. 寻找songmid:
关于这个songmid,真是要了我的命, 我一直在播放界面中去找, 一直捣腾,结果屁都没有,无意中,我在列表区打开了调试, 然后我就发现了这个songmid庐山真面目了,如下:

右边箭头中 a标签里面最后一段就是songmid,感谢它直接拼接到浏览器中,那就好办了,直接爬它,然后和对应的歌手啊,歌曲名啊,放在一个字典或者元组里面,方便后面操作, 对于这个页面的爬取,不能直接用request去爬的,动态js渲染,得用selenium去爬,后面会讲到, 在这里,我们把href 进行处理就可以拿到songmid了。
4. 寻找sign:
sign参数应该是QQ音乐最变态的一个参数了,极度难找,但是最后还是被我找到了,没有用,兵来将挡水来土掩,还是我行。
在之前的vkey的图片里面,我们点击他对应的js文件,如下:

然后可视化打开,搜索sign参数,最后找到像这样。
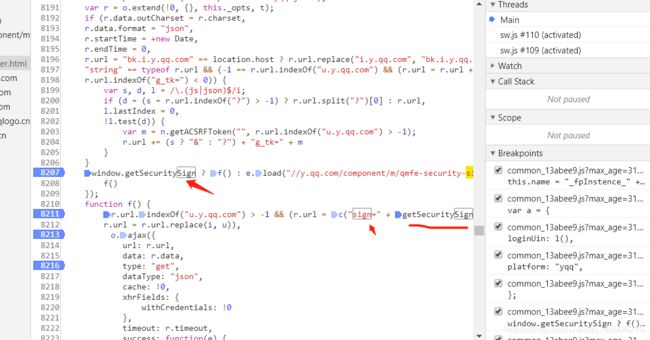
在这些参数上都打上断点, 开始调试, 我们发现 sign参数,是由一个函数 getSecuritySign() 返回的, 对的,一开始我也是这样认为的,调试中,我们可以进入到这个函数,打开发现是一段js文件,如下:

直接把这个复制文件到自己电脑里面, python第三方库 execjs 可以运行js文件或者js代码, 安装 pip install PyExecJS 想了解的可以百度,或者直接阅读源码。
我们直接把这个文件调用运行,是不可以的,会发现n, window, sign 都没有定义, 所以我们需要进行处理,处理之后,然后模拟加密之后,结果居然错了,sign一直对不上,这就很奇怪,差不多我是从昨天下午一直到现在纠结这个sign参数, 期间我debug了很久很久,最后我放弃了, 开始百度寻找答案, 感谢大佬,参考大佬文章, 在他的一篇文章中, 我知道了sign的获取不仅仅是直接调用这个函数, 还需要其他的操作,如下:

补充之前没有定义的参数, 然后调用 __sign_hash_20200305加密函数,最后发送这个sign参数, 最后我也是拿到了这个参数,这里面的参数data就是之前我们图片中的携带参数data, 可以参考前面的图片,到这里我们就获取到了sign参数。
爬虫高级必然JS逆向,QQ音乐爬虫就是一个很好的练手,读完学会了直接在你女朋友面前装一手,读完你将收获到,QQ音乐JS逆向,sign参数获取,songmid参数获取,vkey参数获取,selenium自动化解析,用python解析执行js代码。
爬虫思路:
既然这些参数我们都知道怎么获取的了,那么编写这个代码也就简单多了, 这次就不发送邮箱给女朋友了,直接输出在控制台得了, 有需要的自行扩展, 甚至你还可以用scrapy扩展到爬取全站的音乐资源, 但是最好别这样,文明爬虫,别搞事情。
- songmid 的获取我们需要导入selenium ,然后搭配headless, useagent
- sign 我们需要使用execjs执行js文件获取
- vkey(purl) 我们需要使用构造好的表单参数请求网址
- down_url 我们只需要请求网址,然后下载到本地就行了。
编写爬虫。
Js文件放不进来,太大了, 可以自己在浏览器中获取,实在不行找我吧。。
代码:
init:
import requests
from urllib.parse import urlencode
from get_useragent import GetUserAgentCS
import os
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from lxml import etree
import time
import execjs # 执行js
class Getparams(object):
"""
参数需要逆推,在第一个get_mp3_ur中,参数 vkey 是会变化的,
所以我们需要拿到vkey参数 和 C4000....... m4a 参数
继续分析其他页面, 看看怎么拿到这些参数
"""
def __init__(self):
self.ua = GetUserAgentCS().get_user()
# setting the selenium headless
self.chrome_options = Options()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
self.browser = None
# 添加随机请求头 并完成设置
self.SeleniumUserAgent()
self.SeleniumSettingEnd()
# 测试代码
# ----------------------
self.get_mp3_url = 'https://isure.stream.qqmusic.qq.com/C4000000CZcC0Yu576.m4a?'
self.params = {
"guid": "62749440", "vkey": "CD3C2A1C153884C4A10594EBA5A1070036CDB6107A2DEB9FE139C3C9"
"D4F73CF44AD0711941B2B4D33B1A76D52DFAE72231F3BAF1FFB05FC5",
"uin": "2936", "fromtag": "66",
}
# ---------------------
self.path = os.path.join(os.path.dirname(__file__), 'QQ音乐下载/')
self.headers = {
"user-agent": self.ua}
self.down_mp3_url = 'https://u.y.qq.com/cgi-bin/musics.fcg?'
# 暂时先用一页 有需要扩展可以全站爬取
self.homepage = 'https://y.qq.com/n/yqq/playlist/7278178798.html'
# down url request
self.down_url = 'https://ws.stream.qqmusic.qq.com/'
self.name_singer_mid = []
self.isExist(path=self.path)
分不清网址是哪个的, 回头看, 自己记下来那些网址的前缀。
获取songmid:
def using_selenium_to_get_songmid(self):
"""using the selenium to spider the page now
TODO: The function maybe using add the page cookies
return fill the self.list
"""
self.browser.get(self.homepage)
time.sleep(1) # 等待js渲染完成
html = etree.HTML(self.browser.page_source)
song_name = html.xpath('//ul[@class="songlist__list"]/li/div/div[3]/span/a/@title')
song_tags_a = html.xpath('//ul[@class="songlist__list"]/li/div/div[3]/span/a/@href')
# https://y.qq.com/n/yqq/song/002d6Cow334MPL.html 类似这样的
song_mid = ["".join(i.strip(".html").split("/")[-1]) for i in song_tags_a]
song_singer = html.xpath('//ul[@class="songlist__list"]/li/div/div[4]/a/text()')
self.name_singer_mid = list(zip(song_name, song_singer, song_mid)).copy()
# print(list(zip(song_name, song_singer, song_mid)))
获取sign:
def get_sign(self, datas):
with open('D:\pyth\网络爬虫设计\QQMp3spider\getsign.js', 'r') as fr:
course = fr.read()
js = execjs.compile(course)
sign = js.call('getSecuritySign', datas)
# a = Sim_hash(data=datas)
# sign += a.jiami(a.get_sign())
# ss = 'CJBPACrRuNy7' + json.dumps(datas)
# ss = 'CJBPACrRuNy7' + JSON.stringify(data);
return sign
构造参数获取vkey(purl):
def get_down_mp3_url(self, song_mid=None):
"""
params : song_mid
just enter the params
"""
try:
if not song_mid or not isinstance(song_mid, str):
raise Exception("The song_mid is error, you enter a None or list, "
"you song_mid is ", song_mid, "the type is ", type(song_mid))
except Exception as e:
print("You can run the function again !", e)
params = {
"-": "getplaysongvkey3441060389750814",
"g_tk": "829763618",
'sign': '',
"loginUin": "884427640",
"data": {
'req': {
"module": "CDN.SrfCdnDispatchServer", "method": "GetCdnDispatch",
"param": {
"guid": "62749440", "calltype": 0, "userip": ""}},
"req_0": {
"module": "vkey.GetVkeyServer", "method": "CgiGetVkey",
"param": {
"guid": "62749440", "songmid": [str(song_mid)], "songtype": [0],
"uin": "884427640", "loginflag": 1, "platform": "20"}},
"comm": {
"uin": 884427640, "format": "json", "ct": 24, "cv": 0}}
}
sign = self.get_sign(params['data'])
print(sign)
params['sign'] = sign
# 对网址进行一部分微处理
url = self.down_mp3_url + urlencode(params, encoding='UTF-8')
url = url.replace("+", "")
url = url.replace("%27", "%22")
# encode the url using utf8
print(url)
r = requests.get(url, headers=self.headers)
time.sleep(0.7)
if r.status_code == 200:
# 分析出接口网址
try:
purl = r.json().get("req_0")['data']['midurlinfo'][0]["purl"]
return self.down_url + purl
except Exception as e:
print("出现了一点错误,我们正在重试! ", e)
time.sleep(1)
self.get_down_mp3_url(song_mid=song_mid)
else:
raise Exception("down request error ", r.status_code)
这里要注意我们构造的url是有问题的, 存在编码不匹配, 替换一下就行了。
打印下载:
def print_list(self):
"""
print the name_singer_mid the list
you can choose a music download or choose all music
"""
print('正在加载歌曲列表,请等待........')
self.using_selenium_to_get_songmid()
print("- " * 10, "QQMusic DownLoad", "- " * 10)
print(f'序号\t\t歌曲\t\t歌手')
for index, content in enumerate(self.name_singer_mid):
print(f'{index + 1}\t\t{content[0]}\t\t{content[1]}')
msg = """
PS: 输入可以单个或者多个输出,若全部下载,第一个值请输入字母 'a'
单个输入,输入结束后回车
多个输入,输入以空格隔开序号,后回车
请输入你的选项:
"""
flag = input(msg).split()
if len(flag) == 1 and flag[0] == "a":
self.down_mp3(self.name_singer_mid, islist=True)
elif len(flag) >= 2:
# TODO: 生成一个零时数组,遍历返回
k = [self.name_singer_mid[int(i) - 1] for i in flag]
self.down_mp3(k, islist=True)
elif len(flag) == 1:
self.down_mp3(self.name_singer_mid[int(flag[0]) - 1], islist=False)
def down_mp3(self, url_list, islist=False):
"""
params: url_list , using the url to down load the music.mp3
islist bool False/ True
"""
print("正在下载中, 请稍等.......")
if not islist:
self.down(mid_path=url_list[1], song_mid=url_list[2], song_name=url_list[0])
elif islist:
for i in url_list:
self.down(mid_path=i[1], song_mid=i[2], song_name=i[0])
def down(self, mid_path, song_mid, song_name):
"""down function """
self.isExist(path=(self.path + str(mid_path) + "/"))
url = self.get_down_mp3_url(song_mid=song_mid)
r = requests.get(url, headers=self.headers)
if r.status_code == 200:
filename = str(song_name).strip() + ".mp3"
with open(filename, 'ab') as fw:
fw.write(r.content)
print(f'下载ok, 保存ok ,', filename)
爬虫高级必然JS逆向,QQ音乐爬虫就是一个很好的练手,读完学会了直接在你女朋友面前装一手,读完你将收获到,QQ音乐JS逆向,sign参数获取,songmid参数获取,vkey参数获取,selenium自动化解析,用python解析执行js代码。
全部代码:
# -*- coding : utf-8 -*-
# @Time : 2020/9/24 21:52
# @author : 沙漏在下雨
# @Software : PyCharm
# @CSDN : https://me.csdn.net/qq_45906219
import requests
from urllib.parse import urlencode
from get_useragent import GetUserAgentCS
import os
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from lxml import etree
import time
import execjs # 执行js
class Getparams(object):
"""
参数需要逆推,在第一个get_mp3_ur中,参数 vkey 是会变化的,
所以我们需要拿到vkey参数 和 C4000....... m4a 参数
继续分析其他页面, 看看怎么拿到这些参数
"""
def __init__(self):
self.ua = GetUserAgentCS().get_user()
# setting the selenium headless
self.chrome_options = Options()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
self.browser = None
# 添加随机请求头 并完成设置
self.SeleniumUserAgent()
self.SeleniumSettingEnd()
# 测试代码
# ----------------------
self.get_mp3_url = 'https://isure.stream.qqmusic.qq.com/C4000000CZcC0Yu576.m4a?'
self.params = {
"guid": "62749440", "vkey": "CD3C2A1C153884C4A10594EBA5A1070036CDB6107A2DEB9FE139C3C9"
"D4F73CF44AD0711941B2B4D33B1A76D52DFAE72231F3BAF1FFB05FC5",
"uin": "2936", "fromtag": "66",
}
# ---------------------
self.path = os.path.join(os.path.dirname(__file__), 'QQ音乐下载/')
self.headers = {
"user-agent": self.ua}
self.down_mp3_url = 'https://u.y.qq.com/cgi-bin/musics.fcg?'
# 暂时先用一页 有需要扩展可以全站爬取
self.homepage = 'https://y.qq.com/n/yqq/playlist/7278178798.html'
# down url request
self.down_url = 'https://ws.stream.qqmusic.qq.com/'
self.name_singer_mid = []
self.isExist(path=self.path)
def SeleniumUserAgent(self):
"""Setting the selenium the user-agent"""
self.chrome_options.add_argument("lang=zh_CN.UTF-8") # setting the language (chinese)
self.chrome_options.add_argument(f"user-agent={self.ua}")
def SeleniumSettingEnd(self):
"""Setting the selenium if end"""
# As: selenium Chrome Setting
self.browser = webdriver.Chrome(options=self.chrome_options)
def isExist(self, path=None):
"""
mkdir
"""
print('create and into ', path)
path = path.strip()
if not os.path.exists(path):
os.mkdir(path)
os.chdir(path)
else:
os.chdir(path)
def using_selenium_to_get_songmid(self):
"""using the selenium to spider the page now
TODO: The function maybe using add the page cookies
return fill the self.list
"""
self.browser.get(self.homepage)
time.sleep(1) # 等待js渲染完成
html = etree.HTML(self.browser.page_source)
song_name = html.xpath('//ul[@class="songlist__list"]/li/div/div[3]/span/a/@title')
song_tags_a = html.xpath('//ul[@class="songlist__list"]/li/div/div[3]/span/a/@href')
# https://y.qq.com/n/yqq/song/002d6Cow334MPL.html 类似这样的
song_mid = ["".join(i.strip(".html").split("/")[-1]) for i in song_tags_a]
song_singer = html.xpath('//ul[@class="songlist__list"]/li/div/div[4]/a/text()')
self.name_singer_mid = list(zip(song_name, song_singer, song_mid)).copy()
# print(list(zip(song_name, song_singer, song_mid)))
def get_sign(self, datas):
with open('D:\pyth\网络爬虫设计\QQMp3spider\getsign.js', 'r') as fr:
course = fr.read()
js = execjs.compile(course)
sign = js.call('getSecuritySign', datas)
# a = Sim_hash(data=datas)
# sign += a.jiami(a.get_sign())
# ss = 'CJBPACrRuNy7' + json.dumps(datas)
# ss = 'CJBPACrRuNy7' + JSON.stringify(data);
return sign
def get_down_mp3_url(self, song_mid=None):
"""
params : song_mid
just enter the params
"""
try:
if not song_mid or not isinstance(song_mid, str):
raise Exception("The song_mid is error, you enter a None or list, "
"you song_mid is ", song_mid, "the type is ", type(song_mid))
except Exception as e:
print("You can run the function again !", e)
params = {
"-": "getplaysongvkey3441060389750814",
"g_tk": "829763618",
'sign': '',
"loginUin": "884427640",
"data": {
'req': {
"module": "CDN.SrfCdnDispatchServer", "method": "GetCdnDispatch",
"param": {
"guid": "62749440", "calltype": 0, "userip": ""}},
"req_0": {
"module": "vkey.GetVkeyServer", "method": "CgiGetVkey",
"param": {
"guid": "62749440", "songmid": [str(song_mid)], "songtype": [0],
"uin": "884427640", "loginflag": 1, "platform": "20"}},
"comm": {
"uin": 884427640, "format": "json", "ct": 24, "cv": 0}}
}
sign = self.get_sign(params['data'])
print(sign)
params['sign'] = sign
# 对网址进行一部分微处理
url = self.down_mp3_url + urlencode(params, encoding='UTF-8')
url = url.replace("+", "")
url = url.replace("%27", "%22")
# encode the url using utf8
print(url)
r = requests.get(url, headers=self.headers)
time.sleep(0.7)
if r.status_code == 200:
# 分析出接口网址
try:
purl = r.json().get("req_0")['data']['midurlinfo'][0]["purl"]
return self.down_url + purl
except Exception as e:
print("出现了一点错误,我们正在重试! ", e)
time.sleep(1)
self.get_down_mp3_url(song_mid=song_mid)
else:
raise Exception("down request error ", r.status_code)
def print_list(self):
"""
print the name_singer_mid the list
you can choose a music download or choose all music
"""
print('正在加载歌曲列表,请等待........')
self.using_selenium_to_get_songmid()
print("- " * 10, "QQMusic DownLoad", "- " * 10)
print(f'序号\t\t歌曲\t\t歌手')
for index, content in enumerate(self.name_singer_mid):
print(f'{index + 1}\t\t{content[0]}\t\t{content[1]}')
msg = """
PS: 输入可以单个或者多个输出,若全部下载,第一个值请输入字母 'a'
单个输入,输入结束后回车
多个输入,输入以空格隔开序号,后回车
请输入你的选项:
"""
flag = input(msg).split()
if len(flag) == 1 and flag[0] == "a":
self.down_mp3(self.name_singer_mid, islist=True)
elif len(flag) >= 2:
# TODO: 生成一个零时数组,遍历返回
k = [self.name_singer_mid[int(i) - 1] for i in flag]
self.down_mp3(k, islist=True)
elif len(flag) == 1:
self.down_mp3(self.name_singer_mid[int(flag[0]) - 1], islist=False)
def down_mp3(self, url_list, islist=False):
"""
params: url_list , using the url to down load the music.mp3
islist bool False/ True
"""
print("正在下载中, 请稍等.......")
if not islist:
self.down(mid_path=url_list[1], song_mid=url_list[2], song_name=url_list[0])
elif islist:
for i in url_list:
self.down(mid_path=i[1], song_mid=i[2], song_name=i[0])
def down(self, mid_path, song_mid, song_name):
"""down function """
self.isExist(path=(self.path + str(mid_path) + "/"))
url = self.get_down_mp3_url(song_mid=song_mid)
r = requests.get(url, headers=self.headers)
if r.status_code == 200:
filename = str(song_name).strip() + ".mp3"
with open(filename, 'ab') as fw:
fw.write(r.content)
print(f'下载ok, 保存ok ,', filename)
def start(self):
"""
start yourself demo
"""
url = self.get_mp3_url + urlencode(self.params)
r = requests.get(url, headers=self.headers)
if r.status_code == 200:
with open("勿忘.mp3", 'wb') as fw:
fw.write(r.content)
print("down load successful !")
a = Getparams()
a.print_list()
读后有收获,点赞,关注,加收藏,共勉!
点我,点我,点我呀!博主其他文章