python 柱状图上显示字体_Python可视化各种统计图(附代码)

0 目录
1. 柱状图
2.堆积柱状图
(1)适用范围
(2)丑图和好图的对比(附代码)
3.饼图
(1) 适用范围
(2)演示和代码
(3)注意事项
4.直方图
(1) 适用范围
(2)演示和代码
(3)注意事项
5.折线图
(1)适用范围
(2)演示和代码
(3)注意事项
6.散点图
(1)适用范围
(2)演示和代码
(3)注意事项
7.箱线图
(1)适用范围
(2)演示和代码
(3)注意事项
8.茎叶图
(1)适用范围
(2)演示和代码
(3)注意事项
1.柱状图
见专栏另一篇文章
nameli:从Seaborn柱状图讨论绘制统计图注意事项zhuanlan.zhihu.com
2.堆积柱状图
(1)适用范围
堆积柱状图和柱状图的本质一样,都是针对离散型数据所做的统计图。不过,柱状图每根柱子只涉及一个离散型变量,而堆积柱状图涉及两个离散型变量。
(2)丑图和好图的对比
Ⅰ、背景说明:

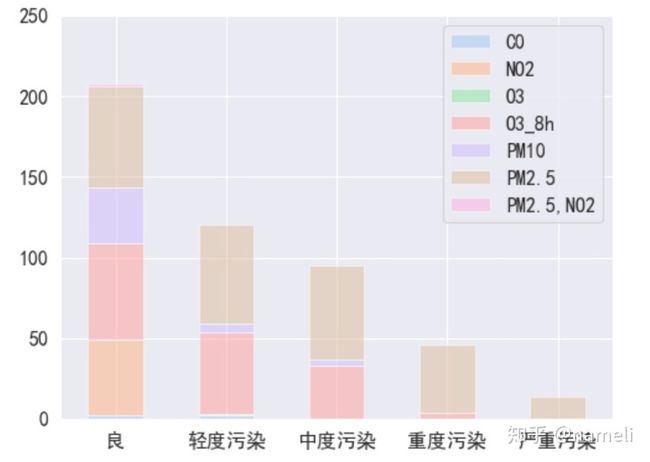
图1是北京市各主要空气污染物的分布,注意“NO2”表示
Ⅱ、丑图及代码
生成数据如下:
import pandas as pd
data = pd.DataFrame(data=data, columns=['C0','NO2',
'O3','O3_8h',
'PM10', 'PM2.5',
'PM2.5,NO2'],
index=['良','轻度污染','中度污染','重度污染','严重污染'])

绘图代码如下:
import numpy as np #载入必要的库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['figure.figsize'] = (8.0, 6.0) #调整图片大小
from matplotlib.font_manager import FontProperties #显示中文,并指定字体
myfont=FontProperties(fname=r'C:/Windows/Fonts/simhei.ttf',size=14)
sns.set(font=myfont.get_name())
plt.rcParams['axes.unicode_minus']=False #显示负号
sns.set_palette(sns.color_palette('pastel')) #设置调色板
data.plot.bar(stacked=True, alpha=0.5, )
plt.xticks(fontsize=16, rotation=0) #设置x和y轴刻度值的字体大小;rotation规定水平排列刻度文字。
plt.xticks(fontsize=16) #设置x轴刻度值的字体大小
plt.yticks(fontsize=16) #设置y轴刻度值的字体大小
plt.legend(fontsize=16) #设置legend刻度值的字体大小
plt.yticks(np.arange(0, 251, 50)) #设置y轴标签
plt.show()图2丑在两个方面:
(1)颜色区分性不强。比如"O3_8h"和"PM2.5 NO2"较难区分。
(2)同一根柱子上的颜色太多,对于数量较少的污染物,显示出来也很难查找。可以去掉频数最大值小于10的三种污染物。
Ⅲ、美图
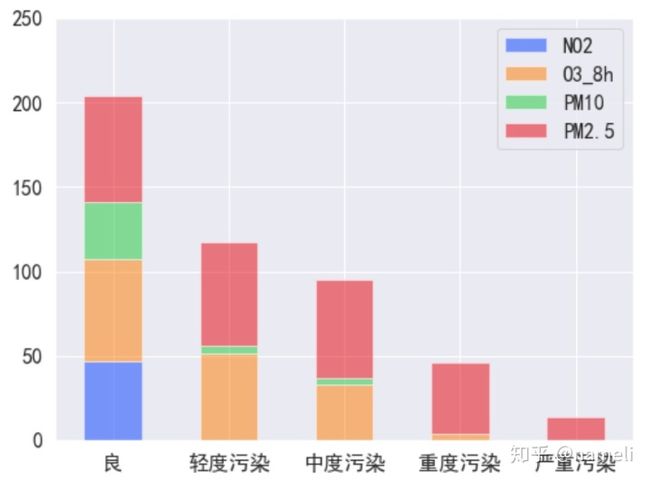
为去掉频数最大值小于10的三种污染物,用apply函数做数据处理如下:
s_1 = data.apply(np.max,axis=0)
s_2 = s_1[s_1.values>10]
data2 = data[s_2.index]
data2

绘图代码如下:
plt.rcParams['figure.figsize'] = (8.0, 6.0) #调整图片大小
import seaborn as sns
from matplotlib.font_manager import FontProperties #显示中文,并指定字体
myfont=FontProperties(fname=r'C:/Windows/Fonts/simhei.ttf',size=14)
sns.set(font=myfont.get_name())
plt.rcParams['axes.unicode_minus']=False #显示负号
sns.set_palette(sns.color_palette('bright')) #设置调色板
#pal_style = ['deep', 'muted', 'pastel', 'bright', 'dark','colorblind']
data2.plot.bar(stacked=True, alpha=0.5) #绘制堆积柱状图
plt.xticks(fontsize=16, rotation=0) #设置x和y轴刻度值的字体大小;rotation规定水平排列刻度文字。
plt.yticks(fontsize=16) #设置y轴刻度值的字体大小
plt.legend(fontsize=16) #设置legend刻度值的字体大小
plt.yticks(np.arange(0, 251, 50)) #设置y轴标签
plt.show()对比可知图3相比图2,更加简洁明了。
3 饼图
(1)适用范围
饼图和柱状图一样,也是针对离散型数据的统计图。但与柱状图多用于展示频数不同,饼图多用于展示频率(也就是比例)。
(2)饼图和代码

说明:
图3展示的是在游戏《炉石传说》中,最近一周职业使用热度,即某职业使用:次数占总 次数的比例。其中法师这个职业使用最多,占比19.7%;使用最少的死战士,占比不到5%。
代码:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data = pd.Series({"法师":0.197, '猎人':0.1557, '术士':0.1276,
'德鲁伊':'0.1126','牧师':0.1088, '盗贼':0.0938,
'圣骑士':0.0901, '萨满':0.0657, '战士':0.0488})
#print(data)
from matplotlib.font_manager import FontProperties #显示中文,并指定字体
myfont=FontProperties(fname=r'C:/Windows/Fonts/simhei.ttf',size=14)
sns.set(font=myfont.get_name())
plt.rcParams['figure.figsize'] = (8.0, 6.0) #调整图片大小
lbs= data.index
explodes=[0.1 if i=='法师' else 0 for i in lbs]
plt.pie(data, explode=explodes,labels=lbs, autopct="%1.1f%%",
colors=sns.color_palette("muted"),startangle = 90,pctdistance = 0.6,
textprops={'fontsize':14,'color':'black'})
plt.axis('equal') # 设置x,y轴刻度一致,以使饼图成为圆形。
plt.show()(3)注意事项
Ⅰ、饼的块数要不多不少,即饼图所展示的离散型变量数要适中。若块数太少,则可直接用一句话替代;块数太多,可采用将比例不到5%的归类为其他,或者是画条形图。
Ⅱ、饼的标签建议写在比例的附近,不宜整体单独列出。
Ⅲ、饼的配色宜赏心悦目。
Ⅳ、人眼更容易线性判别,而不易判断相对区域。所以,当进行相对区域的比较时,相比饼图,用条形图更好一些。
4 直方图
(1)适用范围
直方图是针对连续型变量做的统计图。它最大的用途是观察数据分布的形态,了解数据的取值范围。
(2)演示和代码

说明:
这里随机生成了1000个正态分布的随机数,画了两幅直方图。其中左图是频数图,即纵坐标是频数,表示落在相应区间的样本数;右图是频率图,即纵坐标是概率,表示落在某区间的概率。
直方图代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set() #设置seaborn默认格式
np.random.seed(0) #设置随机种子数
from matplotlib.font_manager import FontProperties #显示中文,并指定字体
myfont=FontProperties(fname=r'C:/Windows/Fonts/simhei.ttf',size=14)
sns.set(font=myfont.get_name())
plt.rcParams['axes.unicode_minus']=False #显示负号
x = np.random.randn(1000)
plt.rcParams['figure.figsize'] = (13, 5) #设定图片大小
f = plt.figure() #确定画布
f.add_subplot(1,2,1)
sns.distplot(x, kde=False) #绘制频数直方图
plt.ylabel("频数", fontsize=16)
plt.xticks(fontsize=16) #设置x轴刻度值的字体大小
plt.yticks(fontsize=16) #设置y轴刻度值的字体大小
plt.title("(a)", fontsize=20) #设置子图标题
f.add_subplot(1,2,2)
sns.distplot(x) #绘制密度直方图
plt.ylabel("密度", fontsize=16)
plt.xticks(fontsize=16) #设置x轴刻度值的字体大小
plt.yticks(fontsize=16) #设置y轴刻度值的字体大小
plt.title("(b)", fontsize=20) #设置子图标题
plt.subplots_adjust(wspace=0.3) #调整两幅子图的间距
plt.show()(3) 注意事项
Ⅰ、直方图的横轴表示区间,这些区间可以是等距的,也可以是不等距的;可以是左开右闭的,也可以是左闭右开的;
Ⅱ、直方图最大的用处是观察数据分布的形态,了解数据的取值范围。关于数据分布,直方图可以分为对称、左偏、右偏。而直方图左偏还是右偏,与其尾巴往哪偏是一致的。
Ⅲ、对于连续型变量,为确定其分布,我们往往先画出它的直方图。但若画出的直方图不美观,建议不要放在PPT中,此时可用更加美观、有说服力的图表或文字来展示。
Ⅳ、直方图不能有效传递信息时,也建议用统计表或文字来展示。
Ⅴ、柱状图的横轴,可以是类,也可以是表示类别或者范围的数字,但真正有意义的是柱状图的高度。直方图的横轴表示一个范围与区间,直方图真正有意义的是它的面积。理论上来讲,在直方图中是可以画出粗细不同的图形,而这些图形也有所含义。但是在柱状图中,图形的粗细非但没有含义,而且也会影响美观。
Ⅵ、分析报告或PPT中的直方图,尽量避免柱高使用密度衡量,因为不易解释。
5 折线图
(1)适用范围
折线图可以用于演示横截面数据、时间序列数据、面板数据。这里以时间序列数据来说明。时间序列数据指的是在一些时间点上,对某个对象采集的数据,它反映的是事物随时间的变化。比如以该县为样本,它在不同年份的GDP,这就是时间序列。
(2)演示和代码

说明:
使用的数据集是美国从1949年1月到1949年12月之间每月的失业率数据,通过绘制折线直观的了解失业率随时间的变化情况。由图可知,1949年1到10月,总体上失业率呈递增趋势,11月、12月失业率则开始下降。
代码如下:
import pandas as pd
import matplotlib.pyplot as plt
unrate = pd.read_csv(r"D:Documentspython_documentsUNRATE.csv")
unrate["DATE"] = pd.to_datetime(unrate['DATE']) #使用pandas的to_datetime函数将数据转换成标准日期格式
#print(unrate.head(12))
unrate.set_index(['DATE'],inplace=True)
unrate_1949 = unrate['1949']
#print(unrate_1949)
plt.rcParams["figure.figsize"] = (8, 6)
plt.plot(unrate_1949['VALUE'])
plt.xticks(rotation=45, fontsize=16) #旋转x轴刻度,并设置字体大小
plt.yticks(fontsize=16)
plt.xlabel("Month", fontsize=16)
plt.ylabel("Unemployment Rate", fontsize=16)
plt.title("Monthly Unemployment Trends, 1949", fontsize=20)
plt.show()(3)注意事项
Ⅰ、时间序列的典型特征是带有时间标签,因此折线图的横轴时间(顺序不能乱),纵轴是某一指标取值。
Ⅱ、观察折线图的3个要点:
1,看趋势,即看指标随着时间的变化,是呈现递增、递减、还是持平的趋势;
2,看周期,即看指标的取值是否呈现一定的周期规律;
3,看突发事件,即看指标的取值是否因为某个事件的发生,出现波峰或波谷。
6 散点图
(1)适用范围
用于展示两个连续型变量的一种常用统计图。
(2)演示和代码

说明:
这里使用numpy包的random函数随机生成1000组数据,然后通过scatter函数绘制了散点图。由图6可知,这些点不相关。
代码如下:
import numpy as np
import matplotlib.pyplot as plt
N = 1000
x = np.random.randn(N)
y = np.random.randn(N)
plt.scatter(x, y)
plt.show()(3)注意事项
Ⅰ、从散点图可以解读两个变量的相关关系,其中包括正线性相关、负线性相关、非线性相关、不相关;
Ⅱ、相关关系不等于因果关系。人们渴求因果关系,但常用的许多统计工具(回归分析等),探求的只是相关关系;
Ⅲ、除了已知的两个变量,当数据中还有其他变量信息时,可以通过改变“点”的颜色、形状和大小来表达;
Ⅳ、从散点图上。还能发现一些“异常”的信息,也就是“离群点”;
Ⅴ、当数据中有多个连续变量时,可以两两画散点图“矩阵”。但是连续型变量过多,画散点图会导致无法抓住重点,此时可以用相关系数矩阵图来表示。
7 箱线图
(1)适用范围
箱线图是一种针对连续型变量的统计图。它常用来配合定性变量画分组箱线图作比较。如果只有一个定量变量,很少用一个箱线图去展示其分布,此时更多选择直方图。
(2)演示和代码
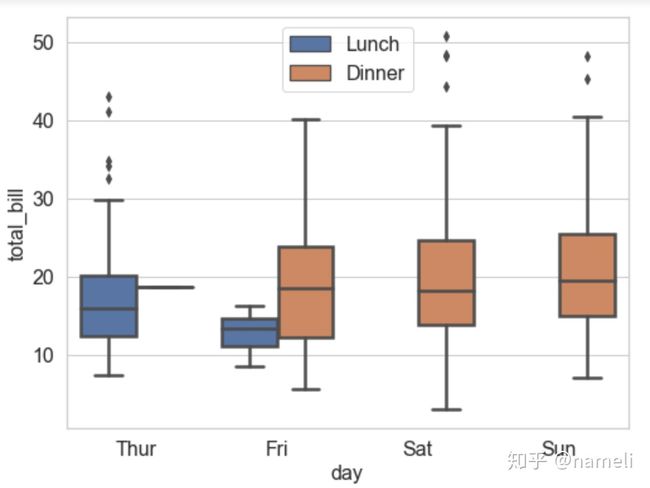
说明:
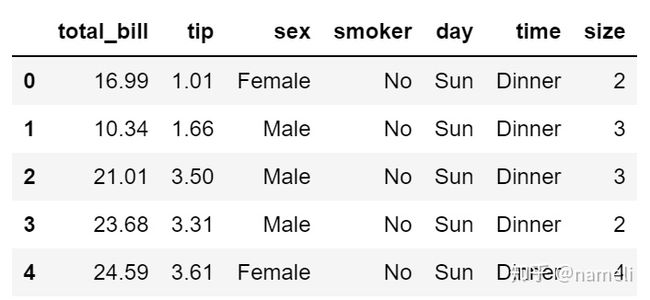
Ⅰ、数据集来自seaborn自带的tips数据集,它的变量及含义如下:total_bill表示该餐的消费总金额,tip表示小费,sex表示性别,smoker表示是否抽烟,day表示今天是周几,time表示该餐是午餐还是晚餐,size表示用餐人数。列出前5行如下:
Ⅱ、餐厅只有周四、周五有午餐消费,且周四中午的午餐消费总金额的平均水平(中位数)高于周五;
Ⅲ、餐厅有晚餐消费的周五、周六、周日,三天的消费平均水平(中位数)大致一致;
Ⅳ、不管是午餐、晚餐,消费的平均水平(中位数)都在10~20之间。
代码如下:
import matplotlib.pyplot as plt
import seaborn as sns
ax = sns.boxplot(x="day", y="total_bill", hue="time",
data=tips, linewidth=2.5)
plt.rcParams["figure.figsize"] = (8, 6)
plt.xticks(fontsize=16) #旋转x轴刻度
plt.yticks(fontsize=16)
plt.xlabel('day', fontsize=16)
plt.ylabel('total_bill',fontsize=16)
plt.legend(fontsize=16, loc='upper center')下面展示画多幅子图的情形:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set() #设置seaborn默认格式
from matplotlib.font_manager import FontProperties #显示中文,并指定字体
myfont=FontProperties(fname=r'C:/Windows/Fonts/simhei.ttf',size=14)
sns.set(font=myfont.get_name()) #seaborn解决中文乱码的问题
plt.rcParams['axes.unicode_minus']=False #显示负号
plt.rcParams['figure.figsize'] = (13, 10) #设定图片大小
f = plt.figure() #确定画布
f.add_subplot(3,2,1)
sns.boxplot(x="ST", y="ASSET",
data=data_1999, linewidth=2.5)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.xlabel('上市公司的ST状态', fontsize=16)
plt.ylabel('应收账款与总资产的比例',fontsize=16)
plt.title("(a)", fontsize=20) #设置子图标题
f.add_subplot(3,2,2)
sns.boxplot(x="ST", y="ATO",
data=data_1999, linewidth=2.5)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.xlabel('上市公司的ST状态', fontsize=16)
plt.ylabel('资产周转率',fontsize=16)
plt.title("(b)", fontsize=20) #设置子图标题
f.add_subplot(3,2,3)
sns.boxplot(x="ST", y="GROWTH",
data=data_1999, linewidth=2.5)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.xlabel('上市公司的ST状态', fontsize=16)
plt.ylabel('销售收入增长率',fontsize=16)
plt.title("(c)", fontsize=20) #设置子图标题
f.add_subplot(3,2,4)
sns.boxplot(x="ST", y="LEV",
data=data_1999, linewidth=2.5)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.xlabel('上市公司的ST状态', fontsize=16)
plt.ylabel('负债资产比率',fontsize=16)
plt.title("(d)", fontsize=20) #设置子图标题
f.add_subplot(3,2,5)
sns.boxplot(x="ST", y="ROA",
data=data_1999, linewidth=2.5)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.xlabel('上市公司的ST状态', fontsize=16)
plt.ylabel('资产收益率',fontsize=16)
plt.title("(e)", fontsize=20) #设置子图标题
f.add_subplot(3,2,6)
sns.boxplot(x="ST", y="SHARE",
data=data_1999, linewidth=2.5)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.xlabel('上市公司的ST状态', fontsize=16)
plt.ylabel('最大股东的持股比例',fontsize=16)
plt.title("(f)", fontsize=20) #设置子图标题
#plt.subplots_adjust(wspace=0.3) #调整两幅子图的间距
plt.tight_layout()
plt.savefig('0-1回归:6幅箱线图.png',dpi=600) #保存png格式图片
plt.show()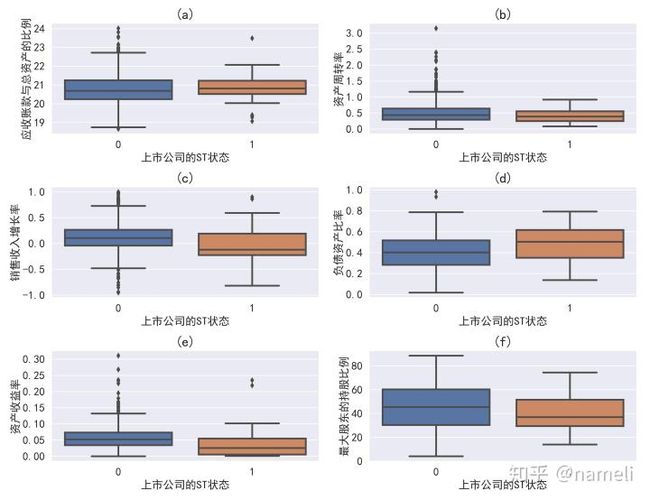
(3)注意事项
Ⅰ、箱线图的三要素:
其一、箱子的中间一条线是数据的中位数,代表了样本数据的平均水平;
其二、箱子的上下限,分别是数据的上四分位数和下四分位数,意味着箱子包含50%的数据。因此,箱子的高度在一定程度上反映了数据的波动程度;
其三、在箱子的上方和下方,各有一条线,分别代表上界和下界。对于冒出去的点,应理解为异常值。
Ⅱ、虽然箱线图也能看分布的形态,但人们更习惯从直方图去解读分布的形态。
8 茎叶图
(1)适用范围
用于同时展示原始数据和分布的形状。图形由“茎”和“叶”两部分组成,通常以数据的高位数字作为“茎“,低位数字作为“叶”
(2)演示和代码

说明:
图8展示的是一组百位数字的分布情况,“|”左边是分别是百位和十位,“|”右边数字均是个位数。以第四行为例,共有三个数字在[210,219]区间段内,分别是210, 215, 217。
代码如下:
from itertools import groupby
nums2=[225, 232,232,245,235,245,270,225,240,240,217,195,225,185,200,
220,200,210,271,240,220,230,215,252,225,220,206,185,227,236]
for k, g in groupby(sorted(nums2), key=lambda x: int(x) // 10):
#print('k', k)
#print('g', list(g))
lst = map(str, [int(y) % 10 for y in list(g)])
print (k, '|', ' '.join(lst))(3)注意事项
Ⅰ、样本数量应当小于大约 50。由于每个茎叶图表示一个数据值,因此当样本数量小于大约 50 时,茎叶图效果最佳。如果样本数量大于 50,则图上的数据点可能会延伸到太远的位置,这可能会使得分布很难评估。如果您的数据点多于 50 个,请考虑使用箱线图或直方图。
Ⅱ、样本数据应当是随机选择的。在统计学中,随机样本用于对总体做出归纳,即推断。如果数据不是随机收集的,则结果可能无法代表总体。