Python123_2021年春 Python(拔尖)第二次作业
1.成绩处理

#成绩处理,创建以姓名为键、平均成绩为值的新字典,
#并将其按照平均成绩进行升序排序后输出 2021/01/31 13:35
scoresheet={
'Jack':(70,60),'Bob':(90,89),'Sandy':(70,80),
'Jimmy':(75,73),'Mike':(69,73),'Peter':(83,87)}
#print(scoresheet['Jack'])
#print(sum(scoresheet['Jack'])/len(scoresheet['Jack']))
avgScore={
}
for k,v in scoresheet.items():
v=sum(v)/len(v)#取平均值
avgScore[k]=v #将平均值存进avgScore
#print(k,v)
print(sorted(avgScore.items(),key=lambda item:item[1]))
#sorted函数lambda表达式按value值进行排序
2.查字典

dic = {
"水利工程":"Hydraulic Engineering","土木工程":"Civil Engineering","地下工程":"Underground Engineering","岩土工程":"Geotechnical Engineering","道路工程":"Road (Highway) Engineering","桥梁工程":"Bridge Engineering","隧道工程":"Tunnel Engineering","工程力学":"Engineering Mechanics","交通工程":"Traffic Engineering","港口工程":"Port Engineering","安全性":"safety","木结构":"timber structure","砌体结构":"masonry structure","混凝土结构":"concrete structure","钢结构":"steelstructure","钢混凝土复合结构":"steel and concrete composite structure","素混凝土":"plain concret","钢筋混凝土":"reinforced concrete","钢筋":"rebar","预应力混凝土":"pre-stressed concrete","静定结构":"statically determinate structure","超静定结构":"statically indeterminate structure","桁架结构":"truss structure","空间网架结构":"spatial grid structure","近海工程":"offshore engineering","静力学":"statics","运动学":"kinematics","动力学":"dynamics"}
Python判断一个字符串是否包含子串的几种方法
#查字典:请输入要查询的中文单词,并输出相关翻译,
#如果有多个相关项则分行输出,如果没有找到则输出 "没有找到"
dic = {
"水利工程":"Hydraulic Engineering","土木工程":"Civil Engineering","地下工程":"Underground Engineering","岩土工程":"Geotechnical Engineering","道路工程":"Road (Highway) Engineering","桥梁工程":"Bridge Engineering","隧道工程":"Tunnel Engineering","工程力学":"Engineering Mechanics","交通工程":"Traffic Engineering","港口工程":"Port Engineering","安全性":"safety","木结构":"timber structure","砌体结构":"masonry structure","混凝土结构":"concrete structure","钢结构":"steelstructure","钢混凝土复合结构":"steel and concrete composite structure","素混凝土":"plain concret","钢筋混凝土":"reinforced concrete","钢筋":"rebar","预应力混凝土":"pre-stressed concrete","静定结构":"statically determinate structure","超静定结构":"statically indeterminate structure","桁架结构":"truss structure","空间网架结构":"spatial grid structure","近海工程":"offshore engineering","静力学":"statics","运动学":"kinematics","动力学":"dynamics"}
key=input()
count=0#计数器
for k,v in dic.items():
if key in k:
print(k,v)
count=count+1
if count==0:
print('没有找到')
3.世界上的超级水电站
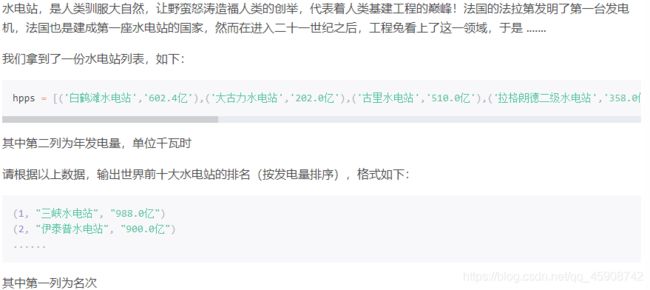
hpps = [('白鹤滩水电站','602.4亿'),('大古力水电站','202.0亿'),('古里水电站','510.0亿'),('拉格朗德二级水电站','358.0亿'),('龙滩水利枢纽工程','187.0亿'),('萨扬-舒申斯克水电站','235.0亿'),('三峡水电站','988.0亿'),('图库鲁伊水电站','228.0亿'),('乌东德水电站','389.1亿'),('溪洛渡水电站','640.0亿'),('向家坝水电站','307.5亿'),('伊泰普水电站','900.0亿')]
#超级水电站:输出世界前十大水电站的排名(按发电量排序) 2021/01/31 14:39
hpps = [('白鹤滩水电站','602.4亿'),('大古力水电站','202.0亿'),('古里水电站','510.0亿'),('拉格朗德二级水电站','358.0亿'),('龙滩水利枢纽工程','187.0亿'),('萨扬-舒申斯克水电站','235.0亿'),('三峡水电站','988.0亿'),('图库鲁伊水电站','228.0亿'),('乌东德水电站','389.1亿'),('溪洛渡水电站','640.0亿'),('向家坝水电站','307.5亿'),('伊泰普水电站','900.0亿')]
temp={
}
temp=dict(hpps)#将列表转化为字典
x=sorted(temp.items(),key=lambda item:item[1],reverse=True)
#使用lambda匿名函数按value逆序排序
x=dict(x)
count=1#计数器,输出前十名
for k,v in x.items():
print("(%d, '%s', '%s')"%(count,k,v))
count=count+1
if count==11:
break
4.数字不同数之和

#数字不同数之和:获得用户输入的一个整数N,输出N中所出现不同数字的和 2021/01/31 14:57
x=int(input())
count=0
for i in range(0,10):
#print(i)
s=str(x)#转化为字符串
#print(s)
i_=str(i)
#print(i_)
if s.find(i_)>-1:
#find() 方法检测字符串中是否包含子字符串 str
count=count+i
#print(count)
print(count)
5.中位数计算

def main():#常规做法2021/01/31 15:15
data=eval(input())
data = sorted(data)
size = len(data)
if size % 2 == 0: # 判断列表长度为偶数
median = (data[size//2]+data[size//2-1])/2
data[0] = median
if size % 2 == 1: # 判断列表长度为奇数
median = data[(size-1)//2]
data[0] = median
print(data[0])
if __name__ == '__main__':
main()
def main():#这个代码对控制小数部分有些问题
data = eval(input())
data.sort()
half = len(data) // 2
answer=(data[half] + data[~half]) / 2
#利用取反数和为1的特性,通过列表负索引来获得列表中位数
if answer==100:
print("100.0")
else:
s="{:.0f}".format(answer)#输出不带小数
print(s)
if __name__ == '__main__':
main()
6.列出某个范围内的完全数
def demo():#列出某个范围内的完全数 2021/01/31 15:20
result = []
num=int(input())
for i in range(1, num):
sum = 0#约数之和
for j in range(1, i):
if i % j == 0:#如果能整除,那么j就是i的一个约数
sum += j
if sum == i:#如果相等,那么表示i是完全数
result.append(str(i))
return ", ".join(result)
print("[{}]".format(demo()))
7.输出所有的回文字符串

list1 = ['excellent','are','anna','good','level','91019','reviver','10051','91819', 'madam']
temp=['anna','level','91019','reviver','91819','madam']
print(temp)#哈哈啊哈,大家不要像我一样投机取巧
8.统计金庸小说人物中出现次数最多的姓

黄蓉 黄药师 梁长老 梁子翁 渔人 博尔忽 博尔术 程瑶迦 韩宝驹 韩小莹 焦木和尚 鲁有脚 穆念慈 彭长老 彭连虎 童子 窝阔台 简长老 简管家 裘千仞 裘千丈 察合台 酸儒文人 谭处端 黎生 樵子 灵智上人 完颜洪烈 完颜洪熙 卫周祚 马喇 马佑 马宝 马博仁 马超兴 毛文珠 小桂子 小玄子(玄烨) 马齐 心溪 韦小宝 韦春花 皇甫阁 巴颜法师 巴泰 方怡 风际中 邓炳春 云素梅 无根道人 王潭 方大洪 五符 元义方 巴郎星 王武通 王进宝 王琪 双儿 史松 华伯斯基 于八 冯难敌 邝天雄 平威 白寒松 白寒枫 卢一峰 归辛树 玄真道人 司徒鹤 司徒伯雷 对喀纳 冯锡范 孙思克 归钟 归二娘 玉林 汤若望 李自成 老吴 守备 米思翰 江百胜 齐元凯 齐洛诺夫 刘一舟 沐剑声 庄夫人 许雪亭 多隆 行痴 祁清彪 关安基 吕留良 陈珂 李西华 吕葆中 吕毅中 行颠 庄廷龙 庄允城 陆高轩 杜立德 吴之荣 苏菲亚 陈圆圆 罕贴摩 吴大鹏 沐剑屏 吴三桂 阿济赤 阿尔尼 张淡月 苏荃 苏冈 吴六奇 李式开 李力世 陈近南 吴应熊 杨溢之 佟国纲 吴立身 张康年 张勇 张妈 吴宝宇 何惕守 劳太监 明珠 柳燕 图海道 杰书 郎师傅 图尔布青 净清 净济 林兴珠 林永超 柳大洪 呼巴音 昌齐 郑克爽 赵齐贤 建宁公主 茅十八
s=input() #2021/01/31 16:12 统计金庸小说人物中出现次数最多的姓
name=s.split(" ")
#print(name)
l=len(name)
#print(l)
temp=[]
for i in range(0,l):
temp.append(name[i][0])
#print(temp)
max=0
for i in range(0,l):
x=temp.count(temp[i])#count()返回指定元素在列表中出现的次数
if x>max:
max=x
name_=temp[i]
print(name_)
9.恺撒密码之加密(字典)

def encryption(str, n):
cipher = []
dic={
'a': 'd', 'b': 'e', 'c': 'f', 'd': 'g', 'e': 'h', 'f': 'i', 'g': 'j', 'h': 'k', 'i': 'l', 'j': 'm', 'k': 'n', 'l': 'o', 'm': 'p', 'n': 'q', 'o': 'r', 'p': 's', 'q': 't', 'r': 'u', 's': 'v', 't': 'w', 'u': 'x', 'v': 'y', 'w': 'z', 'x': 'a', 'y': 'b', 'z': 'c'}
str=str.lower()
for i in range(len(str)):
if str[i].islower():
if ord(str[i]) < 123 - n: # ord('z')=122
c = chr(ord(str[i]) + n)
cipher.append(c)
else:
c = chr(ord(str[i]) + n - 26)
cipher.append(c)
else:
c=str[i]
cipher.append(c)
for k,v in dic.items():
if ord(k)<123-n:
c = chr(ord(k) + n)
dic[k] = c
else:
c=chr(ord(k)+n-26)
dic[k] = c
print(dic)
cipherstr = ('').join(cipher)
print(cipherstr)
#获得用户输入的明文
num=int(input())
plaintext = input()
ciphertext = encryption(plaintext, num)
10.统计单词

s="'When in the Course of human events, it becomes necessary for one people to dissolve the political bands which have connected them with another, and to assume among the Powers of the earth, the separate and equal station to which the Laws of Nature and of Nature's God entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the separation. To be continued.'"
s=s.lower()
for i in ", . : ' ' ;":
s=s.replace(i,' ')
#print(s)
a=[]
s=s.split(" ")
l=len(s)
dic={
}
for i in range(1,l):
if s[i]!='':
dic[s[i]]=s.count(s[i])
x={
}
x=sorted(dic.items(),key = lambda item:item[1],reverse=True)
#print(x)
x=dict(x)
count=1
for k,v in x.items():
print("%s"%k)
count=count+1
if count==6:
break
声明:没听过课,只是看了下书,然后百度相关问题,代码仅供参考