Flink/Blink 原理漫谈(三)state 有状态计算机制 详解
系列文章目录
Flink/Blink 原理漫谈(零)运行时的组件
Flink/Blink 原理漫谈(一)时间,watermark详解
Flink/Blink 原理漫谈(二)流表对偶性和distinct详解
Flink/Blink 原理漫谈(三)state 有状态计算机制 详解
Flink/Blink 原理漫谈(四)window机制详解
Flink/Blink 原理漫谈(五)流式计算的持续查询实现 详解
Flink/Blink 原理漫谈(六)容错机制(fault tolerance)详解
文章目录
- 系列文章目录
- State
-
- State存储实现
- State的分类
-
- 状态一致性
- 端到端的一致性
- 总结
State
首先,blink是有状态计算的,State是流计算特有的,流计算在 大多数场景 下是增量计算,数据逐条处理(大多数场景),每次计算是在上一次计算结果之上进行处理的,这样的机制势必要将上一次的计算结果进行存储(生产模式要持久化),另外由于 机器,网络,脏数据等原因导致的程序错误,在重启job时候需要从成功的检查点(checkpoint,后面篇章会专门介绍)进行state的恢复。增量计算,Failover这些机制都需要state的支撑。
除此外,状态也可以理解为是一个本地变量,可以被业务逻辑所访问。
State存储实现
Blink内部有四种state的存储实现,具体如下:
• 基于内存的HeapStateBackend - 在debug模式使用,不 建议在生产模式下应用;
• 基于HDFS的FsStateBackend - 分布式文件持久化,每次读写都产生网络IO,整体性能不佳;checkpoint存在远程的持久化文件系统上,本地状态存在taskmanager的JVM堆上。
• 基于RocksDB的RocksDBStateBackend - 本地文件+异步HDFS持久化,blink-1.x版本生产应用;将所有状态序列化,存入RocksDB中
• 还有一个是基于Niagara(blink2.x)NiagaraStateBackend - 分布式持久化,blink-2.x版本生产应用;
Blink-1.x版本选择用RocksDB+HDFS的方式进行State的存储,State存储分两个阶段,首先本地存储到RocksDB,然后异步的同步到远程的HDFS。 这样的而设计既消除了HeapStateBackend的局限(内存大小,机器坏掉丢失等),也减少了纯分布式存储的网络IO开销。
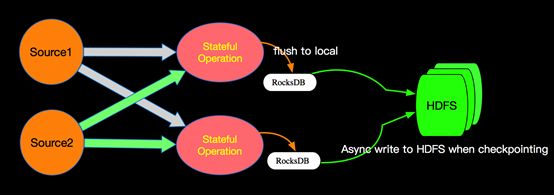
State的分类
OperatorState - Blink内部的Source Connector的实现中就会用OperatorState来记录source数据读取的offset。
作用范围:算子任务本身,并行子任务不可访问。
KeyedState - 这里面的key是我们在SQL语句中对应的GroupBy/PartitioneBy里面的字段,key的值就是groupby/PartitionBy字段组成的Row的字节数组,每一个key都有一个属于自己的State,访问限定为当前数据的key,key与key之间的State是不可见的;任务会维护处理这个key所对应的状态。

状态一致性
在流处理中,一致性可以分为 3个级别:
at-most-once: 最多一次。这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可能丢失。
at-least-once: 最少一次。这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算。
exactly-once: 时间无丢失,就一次。这指的是系统保证在发生故障后得到的计数结果与正确值一致。
Flink既保证了 exactly-once,也具有低延迟和高吞吐的处理能力。
端到端的一致性
为了实现端到端一致,每一个组件都需要保证自己的一致性:
内部保证:checkpoint
Source端:可重设数据的读取位置
Sink端:数据不会重复写入外部系统
内部保证的checkpoint单开一节介绍;source端很好理解;
sink端的实现有两种:

幂等写入,事务写入
幂等写入:一个操作可能重复很多次,但是只导致一次结果更改。但是会存在一个问题:已经输出显示的数据无法回滚,用在实时大屏时会出问题。
事务写入:需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。实现方式有两种:预写日志,两阶段提交。
预写日志:把结果数据当做state来保存,checkpoint完成时,一次性写入sink系统。
实现容易。
问题:有延迟,输出可能不完整。
两阶段提交:每个checkpoint,sink会启动一个事务。两阶段分别为预提交和正式提交,预提交指将数据写入外部sink,不提交;正式提交指收到checkpoint完成通知,提交。缺点在于需要一个外部sink系统。
举例来说,如果使用kafka作为source和sink,需要使用kafka consumer和kafka producer来实现端到端的一致性。
总结
。有状态的计算则会基于多个事件输出结果。以下是一些
例子。
⚫ 所有类型的窗口。例如,计算过去一小时的平均温度,就是有状态的计算。
⚫ 所有用于复杂事件处理的状态机。例如,若在一分钟内收到两个相差 20 度
以上的温度读数,则发出警告,这是有状态的计算。
⚫ 流与流之间的所有关联操作,以及流与静态表或动态表之间的关联操作,
都是有状态的计算。
有状态计算这个概念很重要,后面很多机制的实现都是基于state的。