Blink/Flink作业 性能优化配置及原理
高性能作业指南
本文通过代码和一些配置信息来优化blink/flink作业的性能。
共分为几部分:
1.group aggregate优化:
开启minibatch,开启localglobal,开启partialfinal,count distinct改写为agg with filter(count distinct优化)
2.topN优化
使用UpdateFastRank算法:order by sum(正数) desc 时,要加上正数的过滤条件;topN输出不带rownum,输出时再排序一次;增大topN的cache大小;partitionby字段要有时间
3.高效内置函数
使用内置函数;使用单字符分隔符;multi_keyvalue代替keyvalue;用 LIKE 'xxx%'代替startwith,endwith等等;正则表达式慎用
4.网络传输的优化
使用 Dynamic-Rebalance 替代 Rebalance;使用 Rescale 替代 Rebalance
5.使用gemini
这部分内容是通过一篇ata文章和blink/flink官方文档的内容一起进行整理的,写的很好,整理一下就是上面的这个提纲,如果读过下面的原文,之后再进行查阅的时候看一下提纲就知道如何操作了。‘
一、group aggregate优化:
1.开启minibatch
开启minibatch,本质上就是为了减少吞吐,举例来说每次count操作都需要访问state,当数据量很大的时候,每个资源都要访问state,就会浪费很多资源,这时候使用minibatch,就可以攒好几个需要访问的操作一同访问state,这样就达到了减少资源浪费的情况。本质上就是缓存一定的数据后再触发处理。
用图片表示就是:
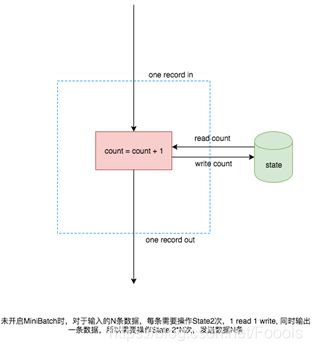

MiniBatch主要依靠在每个 task 上注册的 timer 线程来触发微批,会有一定的线程调度开销。微批处理是使用一定的延迟来换取大量吞吐的策略,如果用户有超低延迟的要求的话,不建议开启微批处理。微批处理一般对于聚合的场景都有显著的性能提升,所以建议开启。
开启MiniBatch之后要求State能支持Batch读写,目前默认的RocksDBStateBackend暂时不支持,Batch的读写实际是循环读写,而NiagaraStateBackend则支持真正的Batch读写。
开启方式
MicroBatch/MiniBatch 默认关闭,开启方式:
#3.2及以上版本开启window miniBatch(3.2及以上版本默认是不开启window miniBatch)
sql.exec.mini-batch.window.enabled=true
# 攒批的间隔时间,使用 microbatch 策略时需要加上该配置,且建议和 blink.miniBatch.allowLatencyMs 保持一致
blink.microBatch.allowLatencyMs=5000
# 使用 microbatch 时需要保留以下两个 minibatch 配置
blink.miniBatch.allowLatencyMs=5000
# 防止OOM,每个批次最多缓存多少条数据
blink.miniBatch.size=20000
2.开启localglobal(常规agg优化)
LocalGlobal优化即将原先的 Aggregate 分成Local+Global 两阶段聚合,也就是在 MapReduce 模型中熟知的 Combine+Reduce 处理模式。第一阶段在上游节点本地攒一批数据进行聚合(localAgg),并输出这次微批的增量值(Accumulator),第二阶段再将收到的 Accumulator merge起来,得到最终的结果(globalAgg)。
LocalGlobal本质上能够靠localAgg 聚合掉倾斜的数据,从而降低 globalAgg 的热点,从而提升性能。

适用场景
LocalGlobal 适用于提升如 SUM, COUNT, MAX, MIN, AVG 等普通 agg 上的性能,以及解决这些场景下的数据热点问题。
注:开启LocalGlobal需要 UDAF 实现 merge 方法。
开启方式
在 blink-2.x 版本开始,LocalGlobal 是默认开启的,参数是: blink.localAgg.enabled=true,但是需要 microbatch/minibatch 开启的前提下才能生效。
如何判断是否生效?
观察最终生成的拓扑图的节点名字中是否包含 “GlobalGroupAggregate” 或 “LocalGroupAggregate”
3.partialfinal(count distinct 热点优化)
上述的 LocalGlobal 优化能针对常见普通 agg 有较好的效果(如SUM, COUNT, MAX, MIN, AVG)。但是对于count distinct收效不明显,原因是 count distinct 在 local 聚合时,对于distinct key的去重率不高,导致在 global 节点仍然存在热点。
在旧版本用户为了解决 count distinct 的热点问题时,一般会手动改写成两层聚合(增加按distinct key 取模的打散层),自 2.2.0 版本开始,blink 提供了 count distinct 自动打散,我们称之为 PartialFinal 优化,用户无需自己改写成两层聚合。和 LocalGlobal 的原理对比请结合下图理解。

适用场景
- 适用于使用了 count distinct 且 aggregate 节点性能无法满足时。
- 不能包含 UDAF
- 因为partial-final优化会自动打散成两层聚合,会引入额外的网络 shuffle,在数据量不大的情况下,可能反而会浪费资源。
开启方式
默认不开启,使用参数显式开启:blink.partialAgg.enabled=true
如何判断是否生效?
观察最终生成的拓扑图的节点名中是否包含 “Expand” 节点,或者原来一层的 aggregate 变成了两层的 aggregate。
4.count distinct优化
自 blink-2.2.2 支持
有一些统计作业会计算各种维度的uv,比如全网uv、来自手淘的uv、来自pc的uv等等。很多用户都是用 CASE WHEN 来实现这种多维度统计的功能,但是建议使用更标准的 agg with filter 语法,因为 blink 目前的 SQL 优化器能分析出 filter 参数,从而同一个字段上计算不同条件下的 count distinct 能共享 state,减少对 state 的读写操作。性能测试中有一倍的性能提升。
适用场景
我们建议用户将 agg with CASE WHEN 的语法都替换成 agg with filter 的语法,尤其是对同一个字段上计算不同条件下的 count distinct 结果时有极大的性能提升。
使用方式
原始写法:
COUNT(distinct visitor_id) as uv1,
COUNT(distinct case when is_wireless='y' then visitor_id else null end) as uv2
优化写法:
COUNT(distinct visitor_id) as uv1,
COUNT(distinct visitor_id) filter (where is_wireless='y') as uv2
除此之外,还有另一种优化方法
本质上就是在key数量过大的情况下,牺牲一点点准确度,换取更高的性能。
背景
COUNT DISTINCT 的主要性能瓶颈是 AGG 节点的 state 需要保存所有 distinct key 的信息,当 distinct key 数目过大时,state 的读写开销太大。而在很多场景中,完全精确的统计不是那么重要,用户更希望牺牲部分精确度来换取性能上的提升,对于这类场景,用户可以选择使用我们新增的内置 AGG 函数 APPROX_COUNT_DISTINCT。
使用场景:
- 能接受非精确的结果,准确率在 99% 左右。
- 输入必须是 append 流, 目前不支持 retraction。
- distinct key 数目 (如 UV) 足够大;如果 distinct key 数目不大,APPROX_COUNT_DISTINCT 性能相对精确计算提升不大。
注意: APPROX_COUNT_DISTINCT 同样支持 MiniBatch/ Local-Global 等 Aggregate 上的优化。
使用方式
例如,SQL 中直接使用 APPROX_COUNT_DISTINCT(user) 代替 COUNT(DISTINCT user)。
APPROX_COUNT_DISTINCT(col [, accuracy])
两个参数含义如下:
col: 任意类型。
accuracy: 指定准确率, 可选参数, 取值范围为 (0.0, 1.0), 默认 0.99; 取值越高, 准确率越高,随之 state 开销越大, 性能越低。
二、优化topN
0.TopN的分类以及原理
这里先介绍一下topN,一般分为全局topN和分组topN,分组topN的operator进行了优化,使效率提高。
全局topN:
查询的结果只有一组排行榜。比如希望对全网商家按销售额排序,计算出销售额排名前十的商家。这就是全局 TopN,范例如下:
SELECT * FROM shop_sales ORDER BY sales DESC LIMIT 10
分组topN:
TopN 需要两层 query,子查询中使用ROW_NUMBER()开窗函数来为每条数据标上排名,排名的计算根据PARTITION BY和ORDER BY来指定分区列和排序列,也就是说每一条数据会计算其在所属分区中,根据排序列排序得到的排名。在外层查询中,对排名进行过滤,只取出排名小于 N 的,如 N=10,那么就是取 Top 10 的数据。如果没有指定PARTITION BY那么就是一个全局 TopN 的计算,所以 ROW_NUMBER 在使用上更为灵活。对全网商家根据行业按销售额排序,计算出每个行业销售额前十名的商家,SQL 范例如下。
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY category ORDER BY sales DESC) AS rownum
FROM shop_sales)
WHERE rownum <= 10
优化:
如下图所示,正常的逻辑下来,是按左侧的逻辑进行topN操作的,但是这回有一个弊端就是logicalCalc层在数据量很大的情况下会有效率很低的情况,所以我们将topN操作设计成了一个堆的形式,我们只维护N个数据,例如我们要找出最大的十个数据,那么新数据来了,我们拿新数据和堆内数据进行对比,比堆内数据大,进行取代;比堆内所有数据小,抛弃,这样大大提高了效率。

实现数据结构原理如下
topN 算子的实现上主要有两个数据结构,一个是 TreeMap,另一个是 MapState。TreeMap 的作用类似于上文的小根堆,有序地存放了排名前 N 的元素。但是 TreeMap 是个内存数据结构,在 failover 后会丢失,无法保证数据的一致性。因此我们还有一个 MapState 结构,MapState 是 Flink 提供的状态接口,用来存储 TopN 的数据(保证数据不丢)。当有 failover 发生后,MapState 能保证状态的恢复,而 TreeMap 会从 MapState 中重新构造出来。我们并有没有把顺序也存到状态中去,因为顺序是可以在恢复时重构的。因为每一次状态的读写操作都会涉及到序列化/反序列化,往往是性能的瓶颈,所以 TreeMap 的主要作用是降低了对 MapState 状态的读写操作。对大部分数据来说都是与 TreeMap 进行交互,不需要对 MapState 进行读写的,全是内存操作,所以 TopN 的性能是非常高的。

TopN 算子的主要处理流程是,每当有数据到达时,会与 TreeMap 的最小的元素比较,如果比它小,那么该数据就不可能是 TopN 的一员,直接丢弃即可。如果比它大,那么就会先更新 TreeMap,同时更新 MapState 中的存的数据。最后输出更新后的排行榜。为了减少冗余数据的输出,我们只会输出排名发生变化的数据。例如原先的第7名上升到了第六名,那么只需要输出新的第六名和第七名即可。
1. order by sum(正数) desc 时,要加上正数的过滤条件
UpdateFastRank 是最优算法,其有两个条件:1.输入流有PK信息。2.排序字段的更新是单调的,且单调方向与排序方向相反。如 order by count/count_distinct/sum(正数) desc
且已知 sum 的参数不可能有负数,那么需要加上过滤条件从而告诉优化器这个信息,才能优化出 UpdateFastRank 算法(blink-2.2.2+支持) 。如下所示(注意 sum(total_fee) filter … )
insert
into print_test
SELECT
cate_id,
seller_id,
stat_date,
pay_ord_amt -- 不输出rownum字段,能减小对结果表的输出量。
FROM (
SELECT
*,
ROW_NUMBER () OVER (
PARTITION BY cate_id,
stat_date -- 注意要有时间字段,否则state过期会导致数据错乱。
ORDER
BY pay_ord_amt DESC
) as rownum -- 根据上游sum结果排序)AS rownum
FROM (
SELECT
cate_id,
seller_id,
stat_date,
-- 重点。声明sum的参数都是正数,所以sum的结果是单调递增的,所以TopN能用优化算法。
sum (total_fee) filter (
where
total_fee >= 0
) as pay_ord_amt
FROM
random_test
WHERE
total_fee >= 0
GROUP
BY cate_name,
seller_id,
stat_date
) a
WHERE
rownum <= 100
);
2. 无排名优化
TopN的输出不要带上 rownum,最终前端显式时在做一次排序,这样能极大地减少往结果表输出的数据量。
3. 增加 TopN 的 cache 大小
TopN 为了提升性能有一个 state cache 层,cache 层能提升对 state 的访问效率。topn 的 cache 命中率的计算公式为:
cache_hit = cache_size*parallelism/top_n/partition_key_num
例如 Top100,配置缓存10000条,并发50,当用户的 patitionBy 的 key 维度较大时,如10万级别,那么 cache 命中率只有 10000*50/100/100000=5%,命中率会很低,导致大量的请求都会击中 state(磁盘),观察 state seek metric 可能会有很多毛刺。性能会大幅下降。
因此当partitionKey维度特别大时,可以适当加大 topn 的 cache size,相对应的也建议适当加大 topn 节点的 heap memory(通过手动资源配置调整)。
#默认10000条,调整 topn cahce 到20万,那么理论命中率能达 200000*50/100/100000 = 100%
blink.topn.cache.size=200000
4. partitionBy 的字段中要有时间类字段
比如每天的排名,要带上day字段。否则 TopN 的结果到最后会由于 state ttl 有错乱。
5.嵌套 TopN 解决热点问题
TopN 的计算与 GroupBy 的计算类似,如果数据存在倾斜,则会有计算热点的现象。比如全局 TopN,那么所有的数据只能汇集到一个节点进行 TopN 的计算,那么计算能力就会受限于单台机器,无法做到水平扩展。解决思路与 GroupBy 是类似的,就是使用嵌套 TopN,或者说两层 TopN。在原先的 TopN 前面,再加一层 TopN,用于分散热点。例如,计算全网排名前十的商铺,会导致单点的数据热点,那么可以先加一层分组 TopN,组的划分规则是根据店铺 ID 哈希取模后分成128组(并发的倍数)。第二层 TopN 与原先的写法一样,没有 PARTITION BY。第一层会计算出每一组的 TopN,而后在第二层中进行合并汇总,得到最终的全网前十。第二层虽然仍是单点,但是大量的计算量由第一层分担了,而第一层是可以水平扩展的。使用嵌套 TopN 的优化写法如下所示:
CREATE VIEW tmp_topn AS
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY HASH_CODE(shop_id)%128 ORDER BY sales DESC) AS rownum
FROM shop_sales)
WHERE rownum <= 10
SELECT *
FROM (
SELECT shop_id, shop_name, sales,
ROW_NUMBER() OVER (ORDER BY sales DESC) AS rownum
FROM tmp_topn)
WHERE rownum <= 10
三、高效的内置函数
1. 使用内置函数替换自定义函数
请尽量使用内置函数,在老版本时,由于内置函数不齐全,很多用户都用的三方包的自定义函数。在 blink-2.x 中,我们对内置函数做了很多的优化(主要是节省了序列化/反序列化、以及直接对 bytes 进行操作),但是自定义函数无法享受到这些优化。
2. KEYVALUE 函数使用单字符的分隔符
KEYVALUE 的签名是:KEYVALUE(content, keyValueSplit, keySplit, keyName),当keyValueSplit和KeySplit是单字符时,如’:’,’,'会使用优化的算法,会在二进制数据上直接寻找所需的 keyName 的值,而不会将整个 content 做切分。性能约有 30% 提升。
3. 多 KEYVALUE 场景使用 MULTI_KEYVALUE
自 blink-2.2.2 支持
如果在 query 中有对同一个 content 做大量 KEYVALUE 的操作,比如 content 中包含10个 key-value 对,希望把10个 value 的值都取出来作为字段。用户经常会写10个KEYVALUE函数,那么就会对 content 做10次解析。在这种场景建议使用 MULTI_KEYVALUE,这是一个表值函数。使用该函数可以只对 content 做一次 split 解析。性能约有 50%~100%的性能提升。
4. LIKE 操作注意事项
如果想做 startWith 的操作,用 LIKE ‘xxx%’
如果想做 endWith 的操作,用 LIKE ‘%xxx’
如果想做 contains 的操作,用 LIKE ‘%xxx%’
如果是做 equals 操作,用 LIKE ‘xxx’,其实和 str = ‘xxx’等价
如果想匹配 字符,请注意要做转义 LIKE ‘%seller/id%’ ESCAPE ‘/’。因为 _ 在 SQL 中是个单字符的通配符,能匹配上任何字符,如果声明成 LIKE %seller_id%’,那么 不单单会匹配 “seller_id” 还会匹配"seller#id", “sellerxid”, “seller1id” 等等,可能会导致结果不是预期的,而且在运行时会使用正则来匹配,效率就会特别慢。
5. 慎用正则函数(REGEXP)
正则表达式是非常耗时的操作,对比加减乘除通常有百倍的性能开销,而且正则表达式在某些极端情况下可能会进入无限循环,导致作业卡住。所以如果正则能改写 LIKE 的,就尽量用 LIKE。见上文第四点说明。正则函数包括:REGEXP, REGEXP_EXTRACT, REGEXP_REPLACE。
四、网络传输的优化
下游分配策略的方法优化,目前常见的Partitioner 策略包括:
- KeyGroup/Hash: 根据指定的 key 分配
- Rebalance: 轮询分配给各个channel
- Dynamic-Rebalance: 根据下游负载情况动态选择分配给负载较低的 channel。
- Forward: 未 chain 一起时,同Rebalance。chain一起时是一对一分配。
- Rescale: 上游与下游一对多或多对一。
1. 使用 Dynamic-Rebalance 替代 Rebalance
Dynamic Rebalance,它可以根据当前各subpartition中堆积的buffer的数量,选择负载较轻的subpartition进行写入,从而实现动态的负载均衡。相比于静态的rebalance策略,在下游各任务计算能力不均衡时,可以使各任务相对负载更加均衡,从而提高整个作业的性能。例如,在使用 rebalance 时,发现下游各个并发负载不均衡时,可以考虑使用 Dynamic-Rebalance。
参数:task.dynamic.rebalance.enabled=true, 默认关闭。
2. 使用 Rescale 替代 Rebalance
自 blink-2.2.2 支持
例如上游是5个并发,下游是10个并发。当使用 Rebalance 时,上游每个并发会轮询发给下游10个并发。当使用 Rescale 时,上游每个并发只需轮询发给下游2个并发。因为 channel 个数变少了,subpartition的 buffer 填充速度能变快,能提高网络效率。当上游的数据比较均匀时,且上下游的并发数成比例时,可以使用 Rescale 替换成 Rebalance。
参数:enable.rescale.shuffling=true,默认关闭。
五、高性能的内存式 StateBackend —— Gemini
自 blink-2.2.2 支持
Gemini是基于内存的state backend,相对于niagara/rocksdb减少了序列化以及JNI的开销,state读写速度更快,CPU消耗更低。Gemini主要适用于state较小并且state bound的场景,在追数据上具有明显优势(实测可以达到niagara的3-4倍)。另外Gemini提供了spill机制以确保不会发生gc问题或OOM。
适用条件
作业使用niagara state backend的峰值checkpoint size不超过(并发数 * 200)MB。
Gemini配置
Gemini详细使用方法见文档《GeminiStateBackend使用说明》 。
六、推荐的优化配置方案
综上所述,作业建议使用如下的推荐配置:
# excatly-once语义
blink.checkpoint.mode=EXACTLY_ONCE
# checkpoint间隔时间,单位毫秒
blink.checkpoint.interval.ms=180000
blink.checkpoint.timeout.ms=600000
# 使用niagara作为statebackend,以及设定state数据生命周期,单位毫秒
state.backend.type=niagara
state.backend.niagara.ttl.ms=129600000
# 开启5秒的microbatch
blink.microBatch.allowLatencyMs=5000
blink.miniBatch.allowLatencyMs=5000
blink.miniBatch.size=20000
# local 优化,默认已经开启
#blink.localAgg.enabled=true
# 开启partial优化,解决count distinct热点
blink.partialAgg.enabled=true
# 开启 join 节点优化
blink.miniBatch.join.enabled = true
# union all 优化
blink.forbid.unionall.as.breakpoint.in.subsection.optimization=true
# object reuse 优化,默认已开启
#blink.object.reuse=true
# GC 优化(SLS做源表不能设置该参数)
blink.job.option=-yD heartbeat.timeout=180000 -yD env.java.opts='-verbose:gc -XX:NewRatio=3 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:ParallelGCThreads=4'
blink.job.timeZone=Asia/Shanghai