垃圾邮件分类的各种尝试(机器学习篇)
文章目录
-
- 数据集格式
- 清洗数据集
-
- - 去掉停用词
- - 去掉URL
- - 去掉HTML标签
- - 去掉表情符号
- - 去掉特殊符号
- 使用机器学习的方法
-
- 朴素贝叶斯、SVM
-
- 1.1 读取数据
- 1.2 构造词频矩阵
- 1.3 训练并预测
- 1.4 利用其它特征(TF-IDF)
- 逻辑回归(LR)
- 随机森林(RF)
- XGBoost
- LightGBM
- 总结
垃圾邮件分类,作为初学者实践文本分类是一个不错的开始。文章将通过传统机器学习和深度学习的方法来解决分类问题。
机器学习方法:朴素贝叶斯、SVM、逻辑回归、RF、XGBoost、LightGBM
深度学习方法:垃圾邮件分类的各种尝试(深度学习篇)
开源代码地址(欢迎star~):https://github.com/ljx02/Spam_Email_Classificaton
数据集下载链接:由于数据较小,暂时也放到了Git项目中
解决这个问题通用的思路是:
- 读取文本数据,包括训练集、测试集、验证集,如果数据质量不高考虑先清洗一下数据
- 创建词典,这一步有点抽象,可以看作是对语料中的词进行统计,方便后续提取特征
- 特征提取,通过对特征进行编码(向量化)
- 选择模型,开始训练分类器
- 验证模型,预测结果
数据集格式
总的数据集一共有4458条数据,将按照8:2进行划分训练集和验证集。通过分析发现,其中pam的数量有3866条,占数据集的大多数,可以考虑不平衡样本采样进行训练。
数据集的格式如图所示,有三列分别是ID,Label(pam、spam),Email

清洗数据集
在实际中清洗数据也是非常必要的,套用一句俗话“数据决定了模型的上限”。常用的清洗数据的方法有:去掉停用词、去掉URL、去掉HTML标签、去掉特殊符号、去掉表情符号、去掉长重复字、将缩写补全、去掉单字、提取词干等等。当然,清洗数据也可能使模型变差,需要三思。提供部分处理的参考代码如下:
- 去掉停用词
from nltk.corpus import stopwords
stop = set(stopwords.words('english'))
text = "their are so many picture. how are you do this time very much!"
clean_text = []
for word in word_tokenize(text):
if word not in stop:
clean_text.append(word)
print(clean_text)
- 去掉URL
# 删除URL
example = "New competition launched :https://www.kaggle.com/c/nlp-getting-started"
def remove_URL(text):
url = re.compile(r'https?://\S+|www\.\S+')
return url.sub(r'', text)
print(remove_URL(example))
- 去掉HTML标签
# 删除HTML标签
example = """"""
def remove_html(text):
html = re.compile(r'<.*?>')
return html.sub(r'', text)
- 去掉表情符号
# 删除表情符号
def remove_emoji(text):
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U00002702-\U000027B0"
u"\U000024C2-\U0001F251"
"]+", flags=re.UNICODE)
return emoji_pattern.sub(r'', text)
- 去掉特殊符号
import string
def remove_punct(text):
# 对punctuation中的词进行删除
table = str.maketrans('', '', string.punctuation)
return text.translate(table)
使用机器学习的方法
朴素贝叶斯、SVM
1.1 读取数据
import pandas as pd
# 读邮件数据CSV
train_email = pd.read_csv("data/train.csv", usecols=[2], encoding='utf-8')
train_label = pd.read_csv("data/train.csv", usecols=[1], encoding='utf-8')
1.2 构造词频矩阵
第二步同时也构造了词典,因为词频矩阵的行是所有文章中出现的词,纵轴代表文章。统计每一篇文章中出现相应词的次数。举个例子如下:
['Hello','How are you','Are you OK']
| hello | how | are | you | … | |
|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | … |
| 1 | 0 | 1 | 1 | 1 | … |
| 2 | 0 | 0 | 1 | 1 | … |
代码实现,使用sklearn中的工具,进行计算得出词频矩阵。这里需要注意的是,在处理训练集时,使用fit_transform而在测试得时候使用transform,因为测试的时候是不需要再训练。
from sklearn.feature_extraction.text import CountVectorizer
# 将内容转为list类型
train_email = np.array(train_email).reshape((1, len(train_email)))[0].tolist()
train_label = np.array(train_label).reshape((1, len(train_email)))[0].tolist()
# 使用词袋模型
vectorizer = CountVectorizer()
# CountVectorizer类会把文本全部转换为小写,然后将文本词块化。主要是分词,分标点
data_train_cnt = vectorizer.fit_transform(data_train)
data_test_cnt = vectorizer.transform(data_dev)
1.3 训练并预测
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import LinearSVC
from sklearn.metrics import confusion_matrix
# 利用贝叶斯的方法
clf = MultinomialNB()
clf.fit(data_train_cnt, label_train)
score = clf.score(data_test_cnt, label_dev)
print(score)
# 利用SVM的方法
svm = LinearSVC()
svm.fit(data_train_cnt, label_train)
score = svm.score(data_test_cnt, label_dev)
print(score)
result_svm = svm.predict(data_test_cnt)
print(confusion_matrix(label_dev, result_svm))
运行结果如下:分数都不错,总的感觉贝叶斯效果稍好一点(当然数据有限~~)
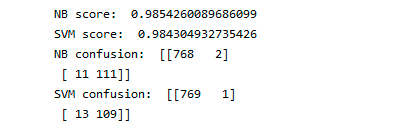
1.4 利用其它特征(TF-IDF)
使用不同的特征进行训练,比较有名的是TF-IDF(词频-逆文档频率),逆文档频率含义是如果某个词或短语具有良好的类别区分能力,并且在其它文档中很少出现,则认为这个词或者短语有很好的类别区分能力,比较适合分类。通俗地讲,如果一个词在其中一个文档中出现过,在其它文章中没有出现过,则将这个词的权重增大。反之如果这个词大量出现在所有文档中,则表示这个词对于分类来说不是很重要,出现再多也无实际意义,所以降低其权重。计算逆文档频率一般采用下图公式:
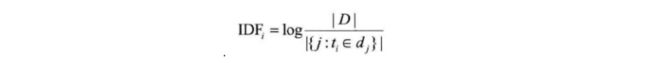
TF-IDF就是词频和逆文档频率的乘积。
具体代码如下(有两种写法):
第一种:直接利用TfidfTransformer对词频矩阵进行计算,得出TF-IDF矩阵
from sklearn.feature_extraction.text import TfidfTransformer
vectorizer = CountVectorizer()
# CountVectorizer类会把文本全部转换为小写,然后将文本词块化。主要是分词,分标点
data_train_cnt = vectorizer.fit_transform(data_train)
transformer = TfidfTransformer()
data_train_tfidf = transformer.fit_transform(data_train_cnt)
data_test_cnt = vectorizer.transform(data_dev)
data_test_tfidf = transformer.transform(data_test_cnt)
第二种:利用TfidfVectorizer对data_train直接操作,得出TF-IDF矩阵(最终结果是一样的)
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer_tfidf = TfidfVectorizer(sublinear_tf=True)
data_train_tfidf = vectorizer_tfidf.fit_transform(data_train)
data_test_tfidf = vectorizer_tfidf.transform(data_dev)
从结果分析,引入TF-IDF特征后效果有一点点波动,算做一种尝试。
逻辑回归(LR)
逻辑回归是用途最广的分类算法,适用性很强。但是想充分利用好逻辑回归,就得不断的调整参数,直到合理为止。具体代码和上边的极其相似,需要引入下面这句话:
from sklearn.linear_model import LogisticRegression
随机森林(RF)
随机森林是一种以决策树为基础的一种更高级的算法。随机森林即可以用于回归也可以用于分类。随机森林从本质上看属于集成学习的一种,通过建立几个模型组合起来解决一个问题。往往随机森林的表现要优于单一的决策树。实现随机森林的代码与上边的类似,已经有库提供这个方法了,只需要引入下边代码:
from sklearn.ensemble import RandomForestClassifier
XGBoost
XGBoost也属于集成学习,高效地实现了GBDT算法并进行了算法和工程上的许多改进。属于boosting的一种。XGBoost算法的核心思想如下:
- 不断地添加树,每次添加都是要学习一个新的f(x),目的是拟合上次的残差
- 每个叶子节点对应一个分数,最终只需要将对应的分数相加起来就得到样本的预测值。
XGBoost的一大优势就是,能够自动学习出缺失值的处理策略。同时使用了一阶导数和二阶导数,有利于梯度下降的更快更准。
当然XGBoost也有缺点:
- 每轮迭代时,都需要遍历整个训练数据多次。耗时且占用较大内存。
- 预排序方法的时间和空间的消耗都较大。
同样,代码只需要引入库如下:
import xgboost as xgb
LightGBM
LightGBM是一个梯度Boosting框架,使用基于决策树的学习方法。具有以下优势:
- 更快的训练效率
- 低内存的使用
- 更高的准确率
- 支持并行化学习
- 可以处理大规模数据
利用LightGBM进行训练,直接引库就好:
import lightgbm as lgb
总结
尝试了不同的方法,总体不难,代码好多都有了方便的库函数辅助。但是每一种方法如果想发挥出它的最大效果,就得不断尝试修改参数。为了快捷调参,可以使用网格调参,具体使用方法已经写入代码中,可以查看GridSearchCV的使用方法。修改参数的第一步就是认识方法中的所有参数,下边我分享一些参数介绍的文章链接:
LightGBM介绍及参数调优
XGBoost介绍及参数调优
LogisticRegression介绍及参数调优
由于训练数据较少,最终发现NB的效果最理想。其它方法估计在大的数据集上会表现好一点,需要后续试验验证。后续可以改进的方法有:
- 调整参数
- 模型融合
- 引入额外信息和特征