学习笔记——线性回归预测模型及其拓展(二)【从零开始学python数据分析与挖掘】
线性回归预测模型及其拓展
第一天 线性回归预测模型及其拓展
文章目录
- 线性回归预测模型及其拓展
- 前言
- 一、岭回归模型
-
- 1.求解
-
- 1.1参数求解
- 1.2系数求解的几何意义
- 2.岭回归的应用
-
- 2.1可视化方法确定λ值
- 2.2交叉验证法确定λ值
- 二、ASLLO回归模型
-
- 2模型介绍
- 2.1参数求解
- 3LASSO回归模型的应用
- 3.1可视化方法确定λ值
- 3.2交叉验证法确定λ值
- 3.数学概念
- 总结
前言
根据线性回归模型的参数估计公式β=(X’X) -1 X’y可知,得到β的前提是矩阵X’X可逆,但在实际应用中,可能会出现自变量个数多于样本量或者自变量间存在多重共线性的情况,此时将无法根据公式计算回归系数的估计值β。为解决这类问题,本章将基于线性回归模型介绍另外两种扩展的回归模型,它们分别是岭回归和LASSO回归。
一、岭回归模型
不管是自变量个数多于样本量的矩阵还是存在多重共线性的矩阵,最终算出来的行列式都等于0或者近似为0,类似于这样的矩阵都会导致线性回归模型的偏回归系数无解或者解是无意义的(因为矩阵X’X的行列式近似为0时,其逆矩阵将偏于无穷大,从而使得回归系数也被放大)。针对这个问题的解决,1970年Heer提出了岭回归模型
1.求解
1.1参数求解
- 参数求解
1.2系数求解的几何意义
- 系数求解的几何意义
2.岭回归的应用
-
自变量分别为患者的年龄、性别、体质指数、平均血压及六个血清测量值;因变量为糖尿病指数,其值越小,说明糖尿病的治疗效果越好。根据文献可知,对于胰岛素治疗糖尿病的效果表明,性别和年龄对治疗效果无显著影响,所以,在接下来的建模中将丢弃这两个变量。
-
由前文可知,岭回归模型的系数表达式为β=(X’X+λI) -1 X’y,故关键点是找到一个合理的λ值来平衡模型的方差和偏差,进而得到更加符合实际的岭回归系数。关于λ值的确定,通常可以使用两种方法,一种是可视化方法,另一种是交叉验证法。
2.1可视化方法确定λ值
- 可视化方法
2.2交叉验证法确定λ值
可视化方法只能确定λ值的大概范围,为了能够定量地找到最佳的λ值,需要使用k重交叉验证的方法。
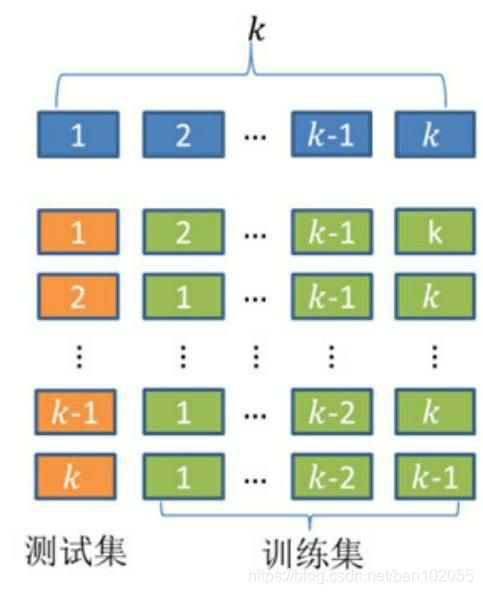
首先将数据集拆分成k个样本量大体相当的数据组
(如图中的第一行),并且每个数据组与其他组都没有重叠的观测;然
后从k组数据中挑选k-1组数据用于模型的训练,剩下的一组数据用于模
型的测试(如图中的第二行);以此类推,将会得到k种训练集和测试
集。在每一种训练集和测试集下,都会对应一个模型及模型得分(如均
方误差)。所以,在构造岭回归模型的k重交叉验证时,对于每一个给
定的λ值都会得到k个模型及对应的得分,最终以平均得分评估模型的优
良。
- 为了得到岭回归模型的最佳λ值,下面使用RidgeCV类对糖尿病数据集做10重交叉验证。然后从中挑选出最小的平均均方误差,并将对应的λ值挑选出来,作为最佳的惩罚项系数λ的值。对于该统计量,值越小,说明模型对数据的拟合效果越好。
二、ASLLO回归模型
2模型介绍
岭回归模型可以解决线性回归模型中矩阵X’X不可逆的问题,解决的办法是添加l2正则的惩罚项,最终导致偏回归系数的缩减。
与岭回归模型类似,LASSO回归同样属于缩减性估计,而且在回归系数的缩减过程中,可以将一些不重要的回归系数直接缩减为0,即达到变量筛选的功能。之所以LASSO回归可以实现该功能,是因为原本在岭回归模型中的惩罚项由平方和改成了绝对值,虽然只是稍做修改,但形成的结果却大相径庭。
LASSO回归模型的目标函数表示为下方的公式:

其中,λǁβǁ 1 为目标函数的惩罚项,并且λ为惩罚项系数,与岭回归模型中的惩罚系数一致,需要迭代估计出一个最佳值,ǁβǁ 1 为回归系数β的l1正则,表示所有回归系数绝对值的和。
2.1参数求解
- 参数求解
- 系数求解几何意义
3LASSO回归模型的应用
3.1可视化方法确定λ值
初始迭代的 λ值落在10 -5 至10 2 之间,然后根据不同的
λ值绘制出有关回归系数的折线图,图中的每条折线同样指代了不同的
变量。与岭回归模型绘制的折线图类似,出现了喇叭形折线,说明该变
量存在多重共线性。从图8-6可知,当λ值落在0.05附近时,绝大多数变
量的回归系数趋于稳定,所以,基本可以锁定合理的λ值范围,接下来
需要通过定量的交叉验证方法获得准确的λ值。
代码如下(示例):
# 导入第三方模块中的函数
from sklearn.linear_model import Lasso,LassoCV
# 构造空列表,用于存储模型的偏回归系数
lasso_cofficients = []
for Lambda in Lambdas:
lasso = Lasso(alpha = Lambda, normalize=True, max_iter=10000)
lasso.fit(X_train, y_train)
lasso_cofficients.append(lasso.coef_)
# 绘制Lambda与回归系数的关系
plt.plot(Lambdas, lasso_cofficients)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Lambda')
plt.ylabel('Cofficients')
# 显示图形
plt.show()
-
alpha:用于指定lambda值的参数,默认该参数为1。
-
normalize:bool类型参数,建模时是否需要对数据集做标准化处
理,默认为False。 -
max_iter:用于指定模型的最大迭代次数,默认为1000。
3.2交叉验证法确定λ值
如果需要实现LASSO回归模型的交叉验证,Python的sklearn模
块提供了现成的接口,只需调用子模块linear_model中的LassoCV类。有
关该“类”的语法和参数说明可见下方:
LassoCV(eps=0.001, n_alphas=100, alphas=None, fit_intercept=True, normalize=False,
precompute='auto', max_iter=1000, tol=0.0001, copy_X=True, cv=None, verbose=False,
n_jobs=1, positive=False, random_state=None, selection='cyclic')
alphas:指定具体的Lambda值列表用于模型的运算。
3.数学概念
-
- 多重共线性的矩阵行列式等于0的意义——如何导致偏回归系数无解或者解是无意义的
-
- 平衡模型的方差(回归系数的方差)和偏差(真实值与预测值之间的差异)意义何在。
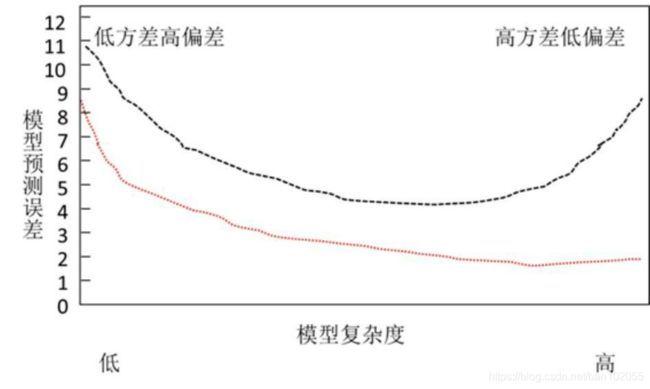
- 平衡模型的方差(回归系数的方差)和偏差(真实值与预测值之间的差异)意义何在。
-
- λ值
-
- 平均均方误差(MSE)
总结
当自变量间存在多重共线性或数据集中自变量个数多于观测数时,会导致矩阵X’X不可逆,进而无法通过最小二乘法得到多元线性回归模型的系数解,而本章介绍的岭回归与LASSO回归就是为了解决这类问题。相比于岭回归模型来说,LASSO回归可以非常方便地实现自变量的筛选,但付出的代价是增加了模型运算的复杂度。