yolov3-pytorch(ultralytics)训练数据
笔记教程,方便自己回忆,纯小白,目前啥也不懂,只知道步骤
建议直接看下面的官方教程,比较明确
系统:Ubuntu 18.04
1、准备工作
1.1、克隆项目
- 为了防止文件夹混乱,自己在主目录下
cd ~创建一个文件夹mkdir YOLOv3,专门用于存放关于YOLOv3的一些工作。 - 进入YOLOv3
cd YOLOv3 - 克隆
git clone [email protected]:ultralytics/yolov3.git
1.2、安装模块
- 创建虚拟环境
conda create -n yolov3-pytorch-ultralytics python=3.8,python版本最好3.8或者以上 - 激活虚拟环境并进入
conda activate yolov3-pytorch-ultralytics - 通过项目下面的 requirements.txt 安装项目需要的模块
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt,如果设置过了pip源,就直接使用pip3 install -r requirements.txt -i,否则下载速度会很慢。
1.3、数据准备
-
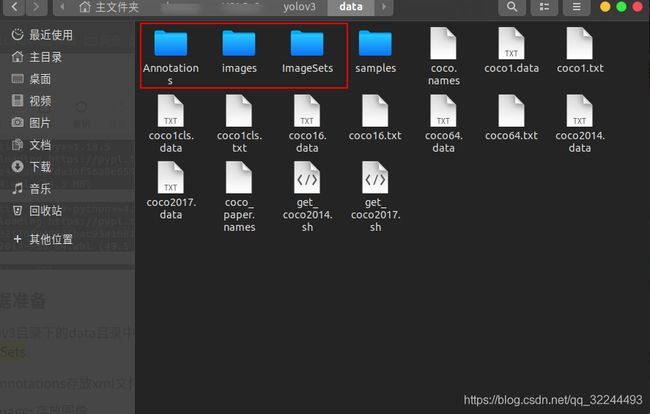
在yolov3目录下的data目录中创建四个文件夹,分别是Annotations、images与ImageSets。
- Annotations存放xml文件
- images存放图像
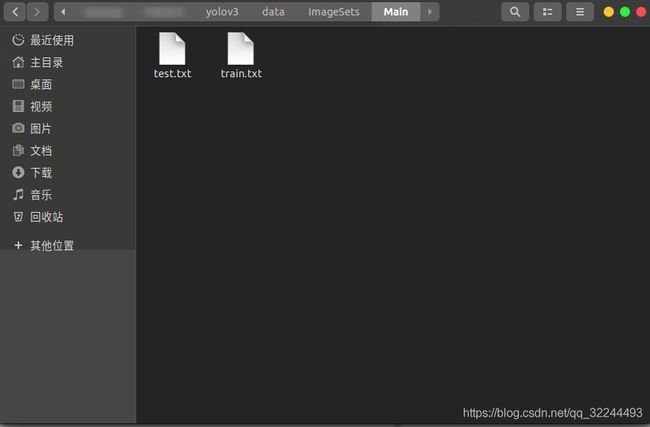
- ImageSets新建Main文件存放train与test文件(脚本生成)
-
在data目录下面新建一个py文件ImageSets.py,用于生成ImageSets目录下Main目录中的train.txt和test.txt文件。使用
python3 ImageSets.py执行。
import os
import random
trainval_percent = 0.2 #可自行进行调节
train_percent = 1
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
#ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
#fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
#ftrainval.write(name)
if i in train:
ftest.write(name)
#else:
#fval.write(name)
else:
ftrain.write(name)
#ftrainval.close()
ftrain.close()
#fval.close()
ftest.close()
- 在yolov3目录下建立voc_labels.py文件生成labels标签文件。使用
python3 voc_labels.py执行。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test']
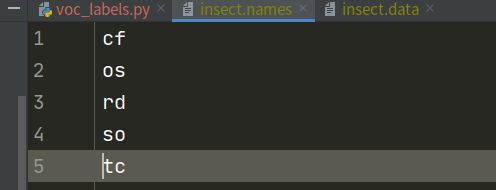
classes = ['cf','os','rd','so','tc'] #自己训练的类别
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()

- 在data目录下新建insect.data
gedit insect.data,配置训练的数据,insect.name为预测的类别名字。同时也要新建一个insect.names,里面的内容是每行一个类别,类别名和voc_labels.py中的classes一样。
classes=5
train=data/train.txt
valid=data/test.txt
names=data/insect.names
1.4、cfg文件
-
备份cfg文件夹下的yolov3.cfg
cp yolov3.cfg yolov3.cfg.bak,然后修改cfg文件gedit yolov.cfg。# 打开yolov3.cfg文件后,搜索yolo,共有三处yolo,下面以一处的修改作为示例。 [convolutional] # 紧挨着[yolo]上面的[convolutional] size=1 stride=1 pad=1 filters=30 # filters=3*(你的class种类数+5) activation=linear [yolo] mask = 6,7,8 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=5 # 修改classes num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1 # 显存大的写1 反之0下面是cfg文件到参数解释
[net] # Testing # batch=1 # subdivisions=1 # Training batch=64 subdivisions=16 # 一批训练样本的样本数量,每batch个样本更新一次参数 # batch/subdivisions作为一次性送入训练器的样本数量 # 如果内存不够大,将batch分割为subdivisions个子batch # 上面这两个参数如果电脑内存小,则把batch改小一点,batch越大,训练效果越好 # subdivisions越大,可以减轻显卡压力 width=608 height=608 channels=3 # 以上三个参数为输入图像的参数信息 width和height影响网络对输入图像的分辨率, # 从而影响precision,只可以设置成32的倍数 # 动量 DeepLearning1中最优化方法中的动量参数,这个值影响着梯度下降到最优值得速度 momentum=0.9 # 权重衰减正则项,防止过拟合 decay=0.0005 # 通过旋转角度来生成更多训练样本 angle=0 # 通过调整饱和度来生成更多训练样本 saturation = 1.5 # 通过调整曝光量来生成更多训练样本 exposure = 1.5 # 通过调整色调来生成更多训练样本 hue=.1 # 学习率决定着权值更新的速度,设置得太大会使结果超过最优值,太小会使下降速度过慢。 # 如果仅靠人为干预调整参数,需要不断修改学习率。刚开始训练时可以将学习率设置的高一点, # 而一定轮数之后,将其减小在训练过程中,一般根据训练轮数设置动态变化的学习率。 # 刚开始训练时:学习率以 0.01 ~ 0.001 为宜。一定轮数过后:逐渐减缓。 # 接近训练结束:学习速率的衰减应该在100倍以上。 # 学习率的调整参考https://blog.csdn.net/qq_33485434/article/details/80452941 learning_rate=0.001 # 在迭代次数小于burn_in时,其学习率的更新有一种方式,大于burn_in时,才采用policy的更新方式 burn_in=1000 # 训练达到max_batches后停止学习 max_batches = 500200 # 这个是学习率调整的策略,有policy:constant, steps, exp, poly, step, sig, RANDOM,constant等方式 # 参考https://nanfei.ink/2018/01/23/YOLOv2%E8%B0%83%E5%8F%82%E6%80%BB%E7%BB%93/#more policy=steps # 下面这两个参数steps和scale是设置学习率的变化,比如迭代到40000次时,学习率衰减十倍。 # 45000次迭代时,学习率又会在前一个学习率的基础上衰减十倍 steps=400000,450000 # 学习率变化的比例,累计相乘 scales=.1,.1 [convolutional] batch_normalize=1 filters=32 size=3 stride=1 pad=1 activation=leaky # Downsample [convolutional] batch_normalize=1 filters=64 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=32 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear # Downsample [convolutional] batch_normalize=1 filters=128 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear # Downsample [convolutional] batch_normalize=1 filters=256 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear # Downsample [convolutional] batch_normalize=1 filters=512 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear # Downsample [convolutional] batch_normalize=1 filters=1024 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=1024 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=1024 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=1024 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=1024 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear ###################### [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=255 activation=linear [yolo] mask = 6,7,8 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=80 num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1 [route] layers = -4 [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [upsample] stride=2 [route] layers = -1, 61 [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=512 activation=leaky [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=512 activation=leaky [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=512 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=255 activation=linear [yolo] mask = 3,4,5 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=80 num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1 [route] layers = -4 [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [upsample] stride=2 [route] layers = -1, 36 [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=256 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=256 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=256 activation=leaky [convolutional] size=1 stride=1 pad=1 # 每一个[region/yolo]层前的最后一个卷积层中的 filters=num(yolo层个数)*(classes+5) # 5的意义是5个坐标,论文中的tx,ty,tw,th,to filters=255 activation=linear # 在yoloV2中yolo层叫region层 [yolo] mask = 0,1,2 # anchors是可以事先通过cmd指令计算出来的,是和图片数量,width,height以及cluster(应该就是下面的num的值, # 即想要使用的anchors的数量)相关的预选框,可以手工挑选,也可以通过k means 从训练样本中学出 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=80 # 每个grid cell预测几个box,和anchors的数量一致。当想要使用更多anchors时需要调大num, # 且如果调大num后训练时Obj趋近0的话可以尝试调大object_scale num=9 # 利用数据抖动产生更多数据,YOLOv2中使用的是crop,filp,以及net层的angle,flip是随机的, # jitter就是crop的参数,tiny-yolo-voc.cfg中jitter=.3,就是在0~0.3中进行crop jitter=.3 # 参与计算的IOU阈值大小.当预测的检测框与ground true的IOU大于ignore_thresh的时候,参与loss的计算,否则,检测框的不参与损失计算。 # 参数目的和理解:目的是控制参与loss计算的检测框的规模,当ignore_thresh过于大,接近于1的时候,那么参与检测框回归loss的个数就会 # 比较少,同时也容易造成过拟合;而如果ignore_thresh设置的过于小,那么参与计算的会数量规模就会很大。同时也容易在进行检测框回归的时候造成欠拟合。 # 参数设置:一般选取0.5-0.7之间的一个值,之前的计算基础都是小尺度(13*13)用的是0.7,(26*26)用的是0.5。这次先将0.5更改为0.7。 # 参考:https://www.e-learn.cn/content/qita/804953 ignore_thresh = .7 truth_thresh = 1 # 为1打开随机多尺度训练,为0则关闭 random=1 -
可以通过上面的方法自己修改,也可以通过sh文件自动生成。在cfg下面新建create_custom_model.sh文件,然后执行命令
bash create_custom_model.sh,< num-classes> 类别数目参数,根据你的需要修改。比如我的就是bash create_custom_model.sh 5,然后根据生成的cfg文件适当的更改其它参数。
create_custom_model.sh
#!/bin/bash
NUM_CLASSES=$1
echo "
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=16
subdivisions=1
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
# Downsample
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=256
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=512
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
######################
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=$(expr 3 \* $(expr $NUM_CLASSES \+ 5))
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=$NUM_CLASSES
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 61
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=$(expr 3 \* $(expr $NUM_CLASSES \+ 5))
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=$NUM_CLASSES
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 36
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=$(expr 3 \* $(expr $NUM_CLASSES \+ 5))
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=$NUM_CLASSES
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
" >> yolov3-custom.cfg
1.5、权重文件下载
- yolov3目录下的weights文件下原本只有download_yolov3_weights.sh,我们需要在网站去下载权重文件到weights目录下。
- 下载后记得解压
unzip xxx.zip
2、训练
-
在train.py目录下,使用命令
python3 train.py --data data/insect.data --weights weights/yolov3.weights --cfg cfg/yolov3-custom.cfg --epochs 10 --batch-size 4开始训练。python3 train.py表示执行train.py.--data data/insect.data表示训练该数据--weights weights/yolov3.weights表示使用该训练权重--epochs 10表示十个训练时期,可更改--cfg cfg/yolov3-custom.cfg表示使用yolov3-custom.cfg--batch-size 4表示batch-size大小为4,提示显存不够就往小了调
这是训练完成的样子
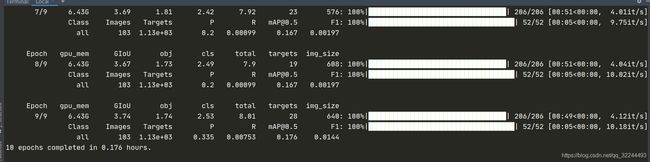
-
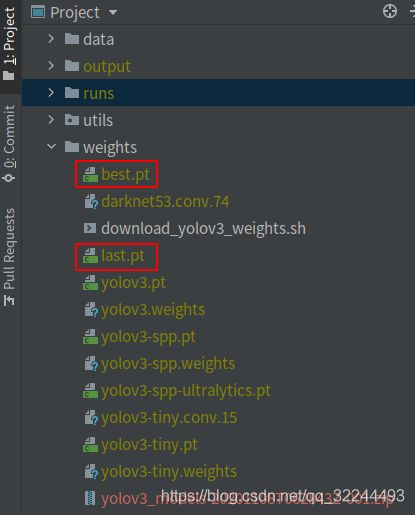
训练完成后获得到如下两个文件。其中best.pt是100次训练中得到的最好的一个权重,last.pt是最后一次训练所得的权重。
3、评估模型
python test.py --data data/insect.data --cfg cfg/yolov3-custom.cfg --weights weights/last.pt

4、检测
-
将待检测的图片放入data\sample文件夹下,基于训练获得的weights文件夹下的best.pt模型文件,运行detect.py即可完成检测
python detect.py --names data/insect.names --weights weights/best.pt --source data/samples/Cf-1.jpg检测效果如下

5、遇到的问题
-
Unresolved reference ‘apex’
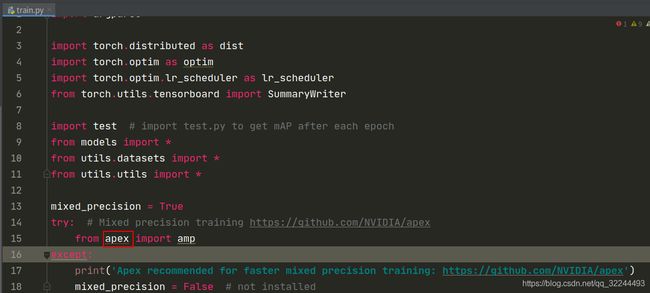
apex是一款基于 PyTorch 的混合精度训练加速神器,单纯的inference实际上不需要apex模块,如果还要训练自己的数据集,就需要安装这个模块,安装方法如下:
在github上把apex项目下载或者git到本地,链接为:https://github.com/NVIDIA/apex。
在terminal中激活pytorch的环境,并且进入到apex的文件夹下,在terminal中执行:python setup.py install
6、官方教程——训练自己的数据
这个教程将帮助你如何通过YOLOv3训练自己的数据
6.1、开始之前
克隆该仓库,下载教程数据集,安装 requirements.txt 中的依赖,包括 Python >= 3.8 和 PyTorch >= 1.7 。
$ git clone https://github.com/ultralytics/yolov3 # clone repo
$ cd yolov3
$ pip install -r requirements.txt # install dependencies
6.2、训练自己的数据
6.2.1、创建 dataset.yaml
COCO128 是一个由COCO2017训练集前128张图片组成的小型教程数据集。同样的128张图像用于训练和验证,以验证我们的训练管道是否能够过拟合。data/coco128.yaml 如下所示,是一个数据集配置文件,定义了如下内容:
- 可选的下载命令/URL,用于自动下载
- 训练图像的目录路径(或是训练图像列表的txt文件路径)
- 同样的验证图像路径
- 种类的数量
- 种类列表名
# download command/URL (optional)
download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../coco128/images/train2017/
val: ../coco128/images/train2017/
# number of classes
nc: 80
# class names
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
6.2.2、创建标签
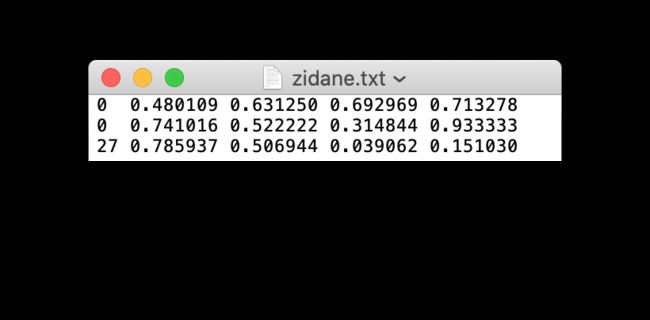
在使用了一些例如 CVAT、makesense.ai 或者 Labelbox 的工具去标注你的图片,你需要导出你的标注文件为YOLO格式,一张图片对应一个txt文件(如果没有目标在图片中,那么改图片的txt文件就不需要)。txt文件的格式为:
- 每个对象一行
- 每行的格式为:类别 中心坐标x 中心坐标y 宽 高
- 框坐标必须是规范化的xywh格式(从0到1)。如果你的方框是像素,那么x中心和宽度除以图像的宽度,y中心和高度除以图像的高度。
- 类别数从0开始计数
与上图相对应的标签文件包含2个人(0类)和一条领带(27类):
6.2.3、组织目录
根据以下的列子来组织你的训练和验证图片以及标签。在此示例中,我们假定/ coco128在/ yolov3目录旁边。YOLOv3通过用/ labels /替换images目录中的/ images /的最后一个实例,自动为每个图像定位标签。例如:
coco/images/train2017/000000109622.jpg # image
coco/labels/train2017/000000109622.txt # label
6.2.4、选择一个模型
选择一个预先训练过的模型开始训练。在这里我们选择YOLOv3,最小和最快的型号。
| Model | A P v a l AP^{val} APval | A P t e s t AP^{test} APtest | A P 50 AP_{50} AP50 | S p e e d G P U Speed^{GPU} SpeedGPU | params | FLOPS |
|---|---|---|---|---|---|---|
| YOLOv3 | 43.3 | 43.3 | 63.0 | 4.8ms | 208 | 61.9M |
| YOLOv3-SPP | 44.3 | 44.3 | 64.6 | 4.9ms | 204 | 63.0M |
| YOLOv3-tiny | 17.6 | 34.9 | 34.9 | 1.7ms | 588 | 8.9M |
6.2.5、训练
通过指定数据集,batch-size,图片大小,预训练权重--weights yolov3.pt(推荐yolov3.pt),或是随机初始化--weights '' --cfg yolov3.yaml(不推荐)在COCO128上训练YOLOv3模型。预训练权重会在最新的发布版本中自动下载下来。
# Train YOLOv3 on COCO128 for 5 epochs
$ python train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov3.pt
所有训练结果都以递增的运行目录保存到 run/train/中,即runs/train/exp2,runs/train/exp3等等。欲了解更多细节,请参阅谷歌合作笔记的培训部分。
6.3、可视化
6.3.1、权重和偏差记录
Weights & bias (W&B)现在与YOLOv3集成,用于实时可视化和云记录训练运行。这允许更好的运行比较和内省,以及改进的可视性和团队成员之间的协作。要启用W&B日志记录,先安装wandb,然后进行正常的培训(第一次使用时将指导安装)。
$ pip install wandb
在训练期间,您将在https://www.wandb.com/上看到实时更新,并且您可以使用“ W&B报告”工具创建结果的详细报告。
6.3.2、本地记录
默认情况下,所有结果都会记录在runs/train,每次为新的训练创建一个新的实验目录runs/train/exp2,runs/train/exp3等,来查看训练和测试jpgs,看mosaics,标签,预测和增强效果。请注意,Mosaic Dataloader用于训练(如下所示),这是由Ultralytics开发并在YOLOv4中首次使用的新概念。
train_batch0.jpg显示训练批次0的mosaics 和标签
test_batch0_labels.jpg显示测试批次0的标签
test_batch0_pred.jpg显示测试批次0的预测:
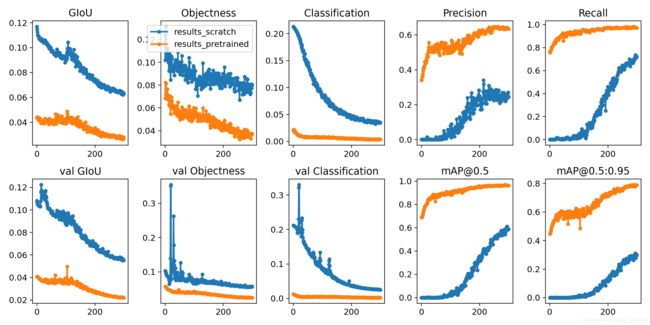
训练损失和性能指标也被记录到Tensorboard和一个定制的result.txt日志文件中,该日志文件在培训完成后被绘制成result .png(下图)。这里我们展示了YOLOv3在COCO128到300个时代的训练,从零开始(蓝色),从预先训练的--weights yolov3.pt(橙色)。
from utils.utils import plot_results
plot_results(save_dir='runs/train/exp') # plot results.txt as results.png
参考
- YOLO(v3)PyTorch版 训练自己的数据集
- Pytorch 版YOLOV3训练自己的数据集
- YOLOv5 实现目标检测(训练自己的数据集实现猫猫识别)