python爬虫学习笔记Requests模块
写在前面:笔记所有内容均来自哔哩哔哩(B站相关视频链接(侵删))
一、requests模块
(一)理论相关
requests模块:python中原生的一款基于网络请求的模块,功能非常强大,简单便捷效率极高。
作用:模拟浏览器发请求。
如何使用:(requests模块的编码流程)
1、指定url
2、发起请求
3、获取响应数据
4、持久化存储
(二)实战编码
一个简单的小栗子1:爬取搜狗首页的页面数据(搜狗首页)
python代码实现:
#!/usr/bin/env python
# -*- cording:utf-8 -*-
# 爬取搜狗首页的数据
import requests
if __name__ == "__main__":
# 第一步 :指定url
url = 'https://www.sogou.com/'
# 第二步 :发起请求
# get方法会返回一个响应对象
response = requests.get(url=url)
# 第三步 :获取响应数据
page_text = response.text
print(page_text)
# 第四步 :持久化存储
with open('./sogou.html', 'w', encoding='utf-8') as fp: # ./是指生成的文件创建在当前目录下
fp.write(page_text)
print("爬取数据结束!!")
结果截图:
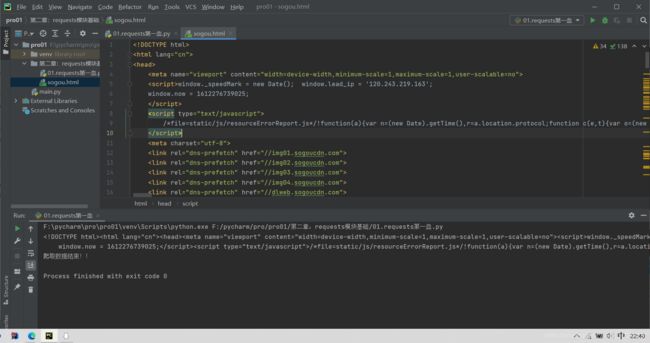
------------------------第一天就到这吧 2021.2.2 22:46 持续更新中…-----------------
一个简单的小栗子2:requests实战之百度网页的采集器(百度搜索)
python代码实现:
#!/usr/bin/env python
# -*- cording:utf-8 -*-
import requests
if __name__ == "__main__":
# UA伪装:将对应的User—Agent封装到一个字典中
# UA伪装的目的是去对抗UA检测
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56'
}
url = 'https://www.baidu.com/s' # 其中s是搜索模块的意思
# 将需要的关键词参数放入到字典中:
kw = input('给我一个关键词')
param = {
'wd': kw # 这里的wd是word的缩写,也就是关键词的意思
}
response = requests.get(url=url, params=param, headers=headers)
page_text = response.text
fileName = kw + '.html'
with open("./" + fileName, 'w', encoding='utf-8') as fp: # 这里不加"./"也可以,好像是默认就保存在当前目录之下
fp.write(page_text)
print(fileName + "保存成功")
需要解释的一些地方:
0. 查看浏览器User-Agent的方法:打开你的浏览器在地址栏输入:about:version,然后其中的用户代理就是(这个方法原文在这:点我跳转)
1. 百度搜索的地址url当中,s表示的是搜索(search);wd表示的是关键词(word),问号在代码的编写中可以省略。如图

(其实后面还有一大串,被我删掉了,不过不影响搜索,俺也不知道为啥,大家可以试试)
结果截图:

和打开该.html的截图,Ctrl+Alt+L是正规化爬取下来的.html文件的格式,(置顶的居然是广告,属实受不了)
一个简单的小栗子3:requests实战之破解百度翻译(百度翻译链接)
python代码实现:
#!/usr/bin/env python
# -*- cording:utf-8 -*-
import requests
import json
if __name__ == "__main__":
# 第一步:指定url
post_url = 'https://fanyi.baidu.com/sug'
# 第二步:进行UA伪装:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.56'
}
# 第三步:post的请求参数处理
word = input("请输入要翻译的单词")
data = {
'kw': word
}
# 第四步:发送请求
response = requests.post(url=post_url, data=data, headers=headers)
# 5第五步:获取响应的数据,返回的是json类型的数据,故可以使用json()
dic_obj = response.json()
# 持久化存储
fileName = word + '.json'
# fp=open(fileName,'w', encoding='utf-8')
with open("./" + fileName, 'w', encoding='utf-8') as fp: # 这里不加"./"也可以,好像是默认就保存在当前目录之下
json.dump(dic_obj, fp=fp, ensure_ascii=False)
print('over!!!!')
需要解释的一些地方:
0. 百度翻译的翻译栏输入单词后页面就会局部刷新,使用的是Ajax技术,所以要定位到Ajax的请求,方法是:网页右击,点击检查(谷歌浏览器会显示英文,不过问题不大)
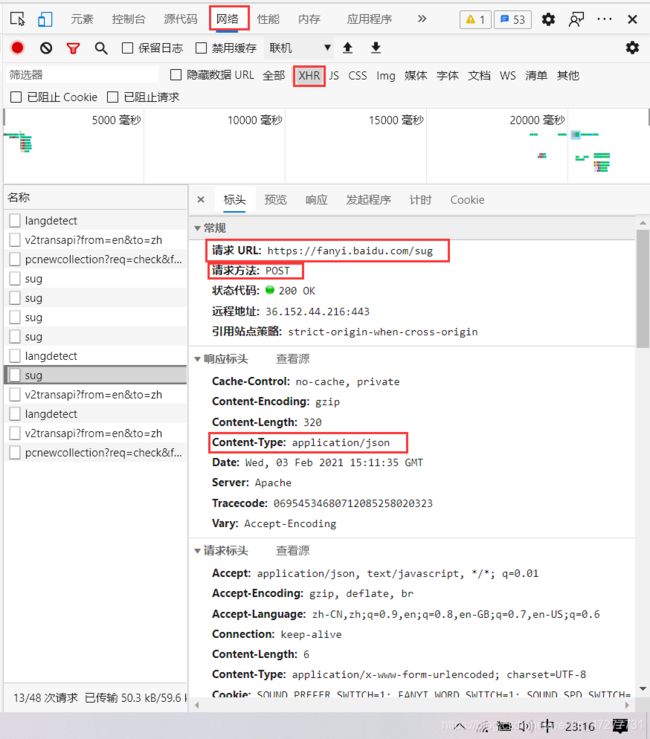
而具体为什么是这些个“sug”中的这个sug,原因是这个sug的最下面包含了完整的单词信息

最后也发现改请求是post请求,故代码中要使用post请求,而且还可以发现返回的数据是json格式
结果截图:

------------------------第二天就到这吧 2021.2.3 23:19 持续更新中…-----------------