计算机二级python编程题笔记(基础题)(自用)
1.以123 为随机种子,随机生成10个介于1(含)到999(含)之间的随机数,每个随机数后跟随一个逗号进行分隔,屏幕输出这10个随机数。
涉及知识:random随机生成
import random
___1.___
for i in range(__2.____):
print(___3.___, end=",")
1.random.seed(123)
2.10
3.random.randint(1,999)
random()函数常见应用:
1.random.randint(1,10) 产生一个1-10整数型随机数(包含1,10)
2.random.random()产生一个0-1之间的随机浮点数
3.random.uniform(1.1,5.4)产生一个1.1-5.4的随机浮点数
4.random.choice()从序列中随机选取一个元素
5.random.randrange(1,100,2)生成从1-100的数,间隔为2的随机整数
6.random.shuffle(a)将序列a中的元素顺序打乱
2.随机选择手机品牌列表brandlist = [‘华为’,‘苹果’,‘诺基亚’,‘OPPO’,‘小米’]中的一个手机品牌,屏幕输出。
import ___1___
brandlist = ['华为','苹果','诺基亚','OPPO','小米']
random.seed(0)
..2....
print(name)
1.random
2.name=random.choice(brandlist)
3.获得用户输入的一个字符串,将字符串逆序输出,同时紧接着输出该字符串所包含字符的个数,请完善代码。
将字符串逆序输出,我好几次下意识都是要写list.reverse(),这个是错的,因为reverse()是列表的方法,用于反向列表中的元素
s = input()
print(_______(1)_________)
print(_______(2)_________)
1.s[::-1],end=""
2.len(s)
注意紧接着输出,所以要有end=""
**4.使用turtle 库的turtle.fd()函数和turtle.left()函数绘制一个边长为200像素的正方形及一个紧挨四个顶点的圆形,写入代码替换模板中的横线,不得修改其他代码,效果如图
**
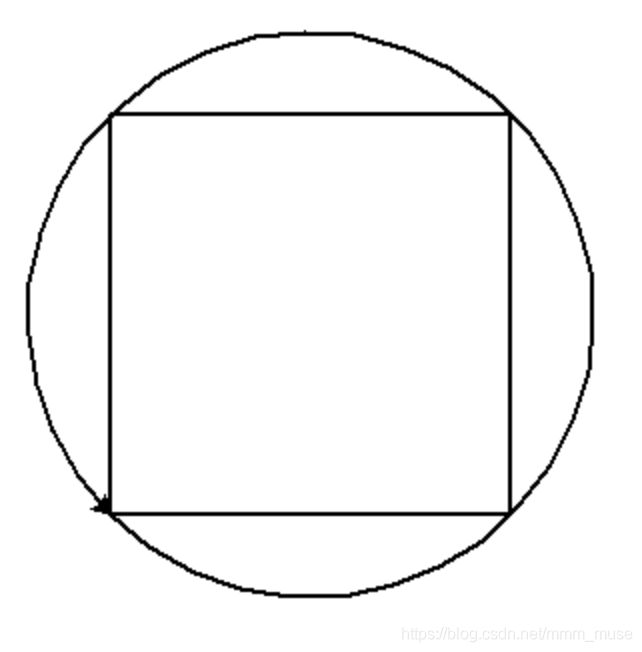
import turtle
turtle.pensize(2)
for i in range(_______(1)_________):
turtle.fd(200)
turtle.left(90)
turtle.left(_______(2)_________)
turtle.circle(_______(3)_________*pow(2,0.5))
1.4#循环四次,正方形四条边
2.-45#这个顺时针逆时针,一开始我脑子也转不过来,理解为如果顺时针45度,圆就不能把正方形包起来了。对吧?
3.100#圆的半径
关于turtle库常见用法:(小海龟嘛可爱的名字)
1.画笔:
turtle.pensize()画笔宽度
turtle.pencolor()画笔颜色
2.控制画笔:
turtle.right(45)顺时针移动45度
turtle.left(45)逆时针移动45度
turtle.fd(200)前进移动200个像素长度
5.使用字典和列表型变量完成村长选举。某村有40名有选举权和被选举权的村民,名单在附件name.txt中,从这40名村民中选出一人当村长,40人的投票信息由附件vote.txt中给出,每行是一张选票的信息,有效票中得票最多的村民当选。
问题:请从vote.txt 中筛选出无效票写入文件vote1.txt 。有效票的含义是:选票中只有一个名字且该名字在name.txt文件列表中,不是有效票的票称之为无效票。
f=open("name.txt")
names=f.readlines()
f.close()
f=open("vote.txt")
votes=f.readlines()
f.close()
D={
}
NUM=0
for vote in _______(1)________:
num = len(vote.split())
if num==1 and vote in _______(2)________:
D[vote[:-1]]=_______(3)________+1
NUM+=1
else:
with open("vote1.txt","a+",encoding="utf-8") as fi:
fi.write("{}".format(__))
1.votes
2.names
3.D.get(vote[:-1],0)#这个是字典的使用:在d字典中找vote[:-1],没有的话给这个键的值赋0,有的话+1,完成按key计数操作。
4.vote
6.使用字典和列表型变量完成村长选举。某村有40名有选举权和被选举权的村民,名单在附件name.txt中,从这40名村民中选出一人当村长,40人的投票信息由附件vote.txt中给出,每行是一张选票的信息,有效票中得票最多的村民当选。
问题:给出当选村长的名字及其得票数。
f=open("name.txt")
names=f.readlines()
f.close()
f=open("vote.txt")
votes=f.readlines()
f.close()
D={
}
NUM=0
for vote in _______(1)________:
num = len(vote.split())
if num==1 and vote in _______(2)________:
D[vote[:-1]]=_______(3)________+1
NUM+=1
*l=list(D.items())
l.sort(key=lambda s:s[1],_______(5)________)
name=____(6)____
score=____(7)____
print("有效票数为:{} 当选村民为:{},票数为:{}".format(NUM, name, score))*
从斜体部分与上题不同
5.reverse=True
6. l[0][0]
7. l[0][1]
以上答案涉及的的方法:
list.sort(key=lambda s:s[1],reverse=True)比较key来排序,reverse是排序规则,reverse=True降序,reverse = False 升序(默认)
*7.《命运》是著名科幻作家倪匡的作品。这里给出《命运》的一个网络本文件,文件名为“命运.txt”
三个题目的附件是一样的文件,同一个《命运.txt》
目的附件是一样的文件,同一个《命运.txt》
------------------------------------------
本题解答 问题一
问题一 、(5分)在右侧修改代码,对“命运.txt”文件进行字符频次统计,输出频次最高的中文字符(*不包括标点符号)及其频次,字符与频次之间采用英文冒号“:”分隔,示例格式如下:
理:224
**
...
d = {
}
...
print("{}:{}".format(______))
碎碎念:好省略的代码。。。给了和没给差不多~菜鸟哭泣。

txt = open("命运.txt", "r", encoding="utf-8").read()
for ch in ",。?:":
txt = txt.replace(ch, "")
d = {
}
for ch in txt:
d[ch] = d.get(ch, 0) + 1
ls = list(d.items())
ls.sort(key=lambda x: x[1], reverse=True)
print("{}:{}".format(ls[0][0], ls[0][1]))
思路步骤:
先读进来文件,
读文件,我一直都很容易混乱,这里给大家简单输出,看个大概。

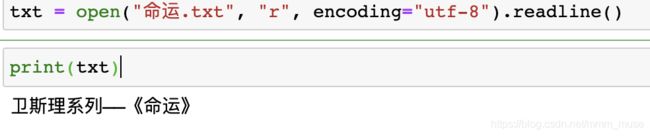
read()输出的更像是原文件形式
readlines()输出是将文件内容全读进来,变成列表,每一行是列表中的一个元素‘’
readline()是只读一行。
OK回来!
之后他要求不包括标点符号,我们用replace去替换。
建立字典,方便后续计数。
逐个字去循环,如果有这个字(key)就加一,如果没有就给这个key赋值0
结束计数,我们需要把字典变成列表形式,因为sort方法是对于列表而言的。
OK,打印输出
我觉得这个题还是很重要,很常见的,基本上就分为三大步:
1.读文件,处理文件内容形式
2.创建字典,循环计数
3.创建列表,排序打印输出
8.对“命运.txt”文件进行字符频次统计,按照频次由高到低,在屏幕输出前10个频次最高的字符,不包含回车符,字符之间无间隔,连续输出,示例格式如下;
理斯卫…(后略,共10个字符)
file=open("命运.txt","r",encoding="utf-8").read()
file=file.replace("\n","")
d = {
}
for i in file:
d[i]=d.get(i,0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 此行可以按照词频由高到低排序
for i in range(10):
print(ls[i][0],end="")
还有第三题,俺没啥时间,放弃了。
键盘输入正整数n,按要求把n输出到屏幕,格式要求:宽度为15个字符,数字右边对齐,不足部分用*填充。
n = eval(input("请输入正整数:"))
print("{______}".format(n))
:*>15
这个format格式化输出,也必须好好看一下。
1."{1} {0} {1}".format(“hello”, “world”) # 设置指定位置
‘world hello world’

2.键盘输入一句话,用jieba 分词后,将切分的词组按照在原话中的逆序输出到屏幕上,词组中间没有空格。示例如下:
请输入一段中文文本:
输入:我爱妈妈
输出:妈妈爱我
import jieba
txt = input("请输入一段中文文本:")
___1___
for i in ls[::-1]:
___2___
1.ls=jieba.lcut(txt)
2.print(I ,end="")
3.a和b是两个列表变量,列表a为[3,6,9] 已给定,键盘输入列表b ,计算a中元素与b中对应元素乘积的累加和。
例如:键盘输入列表b为[1,2,3],累加和为13+26+3*9=42,因此,屏幕输出计算结果为42
a = [3,6,9]
b = eval(input()) #例如:[1,2,3]
___1___
for i in ___2___:
s += a[i]*b[i]
print(s)
1.s=0
2.range(3)
4.使用turtle库的 turtle.fd()函数和 turtle.seth()函数绘制一个边长为100的正五边形,在模板中删除横线替换代码,不得修改其他代码。
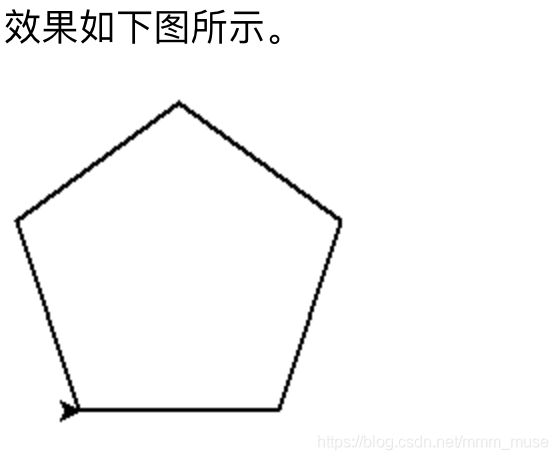
import turtle
turtle.pensize(2)
d = 0
for i in range(1, ______(1)________):
______(2)________
d += ______(3)________
turtle.seth(d)
1.6
2.100
3.72
这里出现了新的方法,turtle.seth(d)
此方法是只改变小海龟的行进方向,角度按照逆时针,不前进
所以这里的turtle.seth(72)就是逆时针走72度。顺便提一下小学知识:多边形内角和=180度*(n-2)
5.键盘输入一组我国高校所对应的学校类型,以空格为分隔,共一行,示例格式如下:
综合 理工 综合 综合 综合 师范 理工
统计各类型的数量,从数量多道少的顺序屏幕输出类型及对应数量,以英文冒号分隔,以英文冒号分隔,每个类型一行,输出参考格式如下:
综合:4
理工:2
师范:1
txt = input("请输入类型序列:")
..1.
d = {
}
..2.
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 按照数量排序
for k in ls:
print("{}:{}".format(k[0], k[1]))
1.txt1=txt.split(" ")
2.for I in txt1:
d[I]=d.get(I,0)+1
下面所示为一套由公司职员随身佩戴的位置传感器采集的数据,文件名称为“sensor.txt”,其内容示例如下:
2016/5/31 0:05, vawe1on1,1,1
2016/5/31 0:20, earpa001,1,1
2016/5/31 2:26, earpa001,1,6
…(略)
第一列是传感器获取数据的时间,第二列是传感器的编号,第三列是传感器所在的楼层,第四列是传感器所在的位置区域编号。
问题一 (10分):在右侧模板中修改代码,读入sensor.txt文件中的数据,提取出传感器编号为earpa001的所有数据,将结果输出保存到“earpa001.txt”文件。输出文件格式要求:原数据文件中的每行纪录写入新文件中,行尾无空格,无空行。参考格式如下:
2016/5/31 7:11, earpa001,2,4
2016/5/31 8:02, earpa001,3,4
2016/5/31 9:22, earpa001,3,4
…(略)
...
for line in ______:
...
fo.write('{},{},{},{}\n'.format(______))
...
又是给了个寂寞
fi=open("sensor.txt","rb")
fo=open("earpa001.txt","wt")
for line in fi:
ls=str(line,encoding="utf-8").strip(' \r\n').split(',')
if ls[1].count("earpa001")>0:
fo.write('{},{},{},{}\n'.format(ls[0],ls[1],ls[2],ls[3]))
fi.close()
fo.close()
1.接收用户输入的一个小于 20的正整数,在屏幕上逐行递增显示从 01 到该正整数,数字显示的宽度为 2,不足位置补 0,后面追加一个空格,然后显示‘>’号,‘>’号的个数等于行首数字。
输入输出示例
输入
3
输出
01 >
02 >>
03 >>>
n = input('请输入一个正整数:') #请输入一个正整数:
for i in range(______1______):
print('______2______'.format(i+1, ______3______))
1.int(n)
2.{:0>2} {}
3.">"*(I+1)
2.让用户输入一串数字和字母混合的数据,然后统计其中的数字和字母的个数,显示在屏幕上。示例
输入:
Fda243fdw3
输出:
数字个数:4,字母个数:6
ns = input("请输入一串数据:")
dnum,dchr = _____1_______
for i in ns:
if i.isnumeric():
dnum += _____2_______
elif i.isalpha():
dchr += _______3_____
else:
pass
print('数字个数:{},字母个数:{}'.format(_____4_______))
1.0,0
2.1
3.1
24.dnum,dchr
**3.将程序里定义好的 std 列表里的姓名和成绩与已经定义好的模板拼成一段话,显示在屏幕上。
输出:
亲爱的张三,你的考试成绩是:英语90, 数学87, python语言95, 总成绩272.特此通知.
**
std = [['张三',90,87,95],['李四',83,80,87],['王五',73,57,55]]
modl = "亲爱的{}, 你的考试成绩是: 英语{}, 数学{}, Python语言{}, 总成绩{}.特此通知."
for st in std:
cnt = _______1_____
for i in range(_______2_____):
cnt += _____3_______
print(modl.format(st[0],st[1],st[2],st[3],cnt))
1.0
2.3
3.int(st[i+1])
4.利用 random 库和 turtle 库,在屏幕上绘制5个圆圈,圆圈的半径和圆心的坐标有 randint()函数产生,圆心的 X 和 Y 坐标范围在 [-100,100]字间;半径的大小范围在[20,50]之意,圆圈的颜色随机在 color 列表里选择。效果如下图所示。
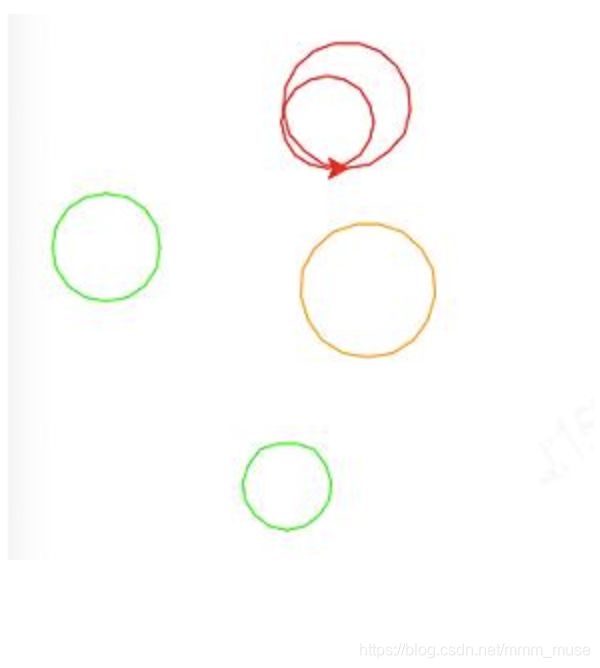
______1______
import random as r
color = ['red','orange','blue','green','purple']
r.seed(1)
for i in range(5):
rad = r.____2________
x0 = r._____3_______
y0 = r.randint(-100,100)
t.color(r.choice(color))
t.penup()#提起画笔嘛
t._____4_______#提起画笔后,移动到圆心坐标点
t.pendown()#放下画笔,开画
t._____5_______(rad)#画圆
t.done()
1.import turtle as t
2.randint(20,50)
3.randint(-100,100)
4.goto(x0,y0)
5.cricle
5.
6.
7.
1.程序接收用户输入的五个数,以逗号分隔。将这些数按照输入顺序输出,每个数占 10 个字符宽度,右对齐,所有数字显示在同一行。
输入:
23,42,543,56,71
输出:
23 42 543 56 71
num = input()._____1_______
for i in num:
print(_____2_______)
1.split(",")
2."{: >10}".format(i),end=""
2.社会平均工作时间是每天 8 小时。如果这位科学家的当下成就值是 1,假设每工作 1 小时成就值增加 0.01%,计算并输出两个结果:这位科学家 5 年后的成就值。 以及达到成就值 100 所需要的年数。其中,成就值和年数都以整数表示,每年以 365 天计算。
scale = 0.0001 # 成就值增量
def calv(base, day):
val = base * pow(___1_________)
return val
print('5年后的成就值是{}'.format(int(calv(1, 5*365))))
year = 1
while calv(1, ____2________) < 100:
year += 1
print('{}年后成就值是100'.format(year))
1.(1+scale),8day
2.year365
**3.程序接收用户输入的一个数字并判断是否为正整数,如果不是正整数,则显示“请输入正整数”并等待用户重新输入,直至输入正整数为止,并显示输出该正整数。
**
while True:
try:
a = eval(input('请输入一个正整数: '))
if a > 0 and ______1______:
print(a)
_____2_______
else:
print("请输入正整数")
except:
print("请输入正整数")
1.a==int(a)
2.break
4.根据列表保存的数据采用 Turtle 库画图直方图,显示输出在屏幕上,效果如下图所示。
Ls=[69,292,33,131,61,254]
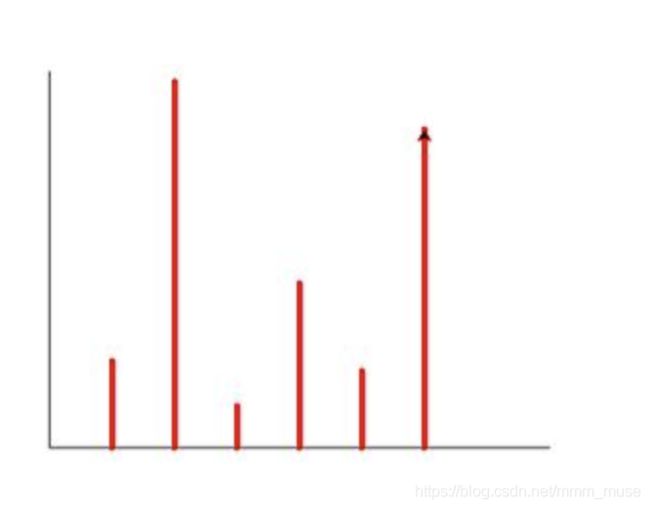
______1______
ls = [69, 292, 33, 131, 61, 254]
X_len = 400
Y_len = 300
x0 = -200
y0 = -100
t.penup()
t.goto(x0, y0)
t.pendown()
t.fd(X_len)
t.fd(-X_len)
t.seth(______2______)
t.fd(Y_len)
t.pencolor('red')
t.pensize(5)
for i in range(len(ls)):
t._______3_____
t.goto(x0 + (i+1)*50, ____4________)
t.seth(90)
t.pendown()
t.fd(______5______)
t.done()
1.import turtle as t
2.90
3.penup()#提起画笔,但是不画
4.y0#移到坐标处后,pendown()再画
5.ls[i]
5.在已定义好的字典 Pdict 里有一些人名及其电话号码。请用户输入一个人的姓名,在字典中查找该用户的信息,如果找到,生成一个范围在1000到9999之间的四位数字的验证码,并将名字、电话号码和验证码输出在屏幕上,如示例所示。如果查找不到该用户信息,则显示“对不起,您输入的用户信息不存在。”示例如下:
输入:Bob
输出:
Bob 234567891 1926
对不起,您输入的用户信息不存在。
import random
random.seed(2)
pdict= {
'Alice':['123456789'],
'Bob':['234567891'],
'Lily':['345678912'],
'Jane':['456789123']}
name = input('请输入一个人名:')
......
答案:
if name in pdict.keys():
print("{} {} {}".format(name,pdict.get(name)[0],random.randint(1000,9999)))
else:
print('对不起,您输入的用户信息不存在。')
pdict.get(name)返回key=name的值
6.该题目共二个问题,分成两道题分别作答。2 个文本文件分别摘自2019年和2018年的政府工作报告。请在右侧代码框中个源文件 ,实现以下功能
本题解答问题1
问题1 :数据统计。要求: 统计出两个文件中出现次数最多的10 个词语,作为主题词,要求词语不少于2个字符,打印输出在屏幕上,输出示例如下:(示例仅作为示意)
2019:改革:10,企业:9,…(略),深化:2
2018:改革:11,效益,7,…(略),深化:1
注意:输出格式采用英文冒号和英文逗号,标点符号前后无空格,各词语间用逗号分隔,最后一个词语后无逗号。
import jieba
f1=open("政府工作报告2018.txt",'r')
f2=open("政府工作报告2019.txt",'r')
d = {
}
d2={
}
for i2 in f2.readlines():
for words2 in i2.split(' '):
word2=jieba.lcut(words2)
for ii2 in word2:
if len(ii2)>=2:
d2[ii2]=d2.get(ii2,0)+1
lt2 = list(d2.items())
lt2.sort(key = lambda x:x[1],reverse = True)
print('2019:',end='')
for iii2 in range(10):
if iii2<9:
print("{}:{}".format(lt2[iii2][0],lt2[iii2][1]),end=',')
else:
print("{}:{}".format(lt2[iii2][0],lt2[iii2][1]))
for i in f1.readlines():
for words in i.split(' '):
word=jieba.lcut(words)
for ii in word:
if len(ii)>=2:
d[ii]=d.get(ii,0)+1
lt = list(d.items())
lt.sort(key = lambda x:x[1],reverse = True)
print('2018:',end='')
s1=[]
for iii in range(10):
if iii<9:
print("{}:{}".format(lt[iii][0],lt[iii][1]),end=',')
else:
print("{}:{}".format(lt[iii][0],lt[iii][1]))
f1.close()
f2.close()
1.a和b是两个列表变量,列表a为[3,6,9]已给定,键盘输入列表b,将a列表的三个元素依次插入到b列表中对应的三个元素的后面,并显示输出在屏幕上。
例如:键盘输入列表b为[1,2,3],因此,屏幕输出计算结果为[1,3,2,6,3,9]
a = [3,6,9]
b = eval(input()) #例如:[1,2,3]
j=1
for i in range(len(__(1)____)):
b._____(2)_____
j+= __(3)______
print(b)
1.a
2.insert(j,a[i])
3.2
**2.键盘输入整数n,按要求把n输出到屏幕,格式要求:宽度为25个字符,等号字符(=)填充,右对齐,带千位分隔符。如果输入正整数超过25位,则按照真实长度输出。
例如:键盘输入正整数n为1234,屏幕输出 ====================1,234**
s = input()
print("{_______(1)_________}".format(_______(2)_________))
1.:=>25,
2.eval(s)
3.获得用户输入的以逗号分隔的三个正整数,记为a、b、c,以 a为起始数值,b为步长,c为数字的个数,产生一个递增的等差数列,将这个数列以列表格式输出,请完善模板中的代码。
a, b, c = _______(1)_________
ls = []
for i in range(c):
ls._______(2)_________
print(ls)
1.eval(input())
2.append(a+b*I)
4.使用turtle 库的turtle.fd()函数和turtle.seth()函数绘制一个边长为40像素的正12边型,在模板中横线处替换代码,不得修改其他代码,效果如下图所示。
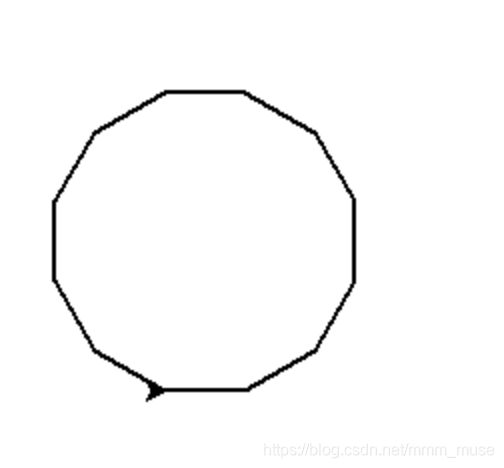
import turtle
turtle.pensize(2)
d=0
for i in range(1, _______(1)_________):
_______(2)_________
d += _______(3)_________
turtle.seth(d)
1.13
2.turtle.fd(40)
3.30
by the way记住turtle.seth()是逆时针啊,这样就好理解了,而且Seth的角度是绝对角度。
**5.计算两个列表 1s 和 1t 对应元素乘积的和(即向量和),补充模板中的代码,删除下划线,可以任意修改代码。完成程序。
1s = [111, 222, 333, 444, 555, 666, 777, 888, 999]
1t = [999, 777, 555, 333, 111, 888, 666, 444, 222]
**
ls = [111, 222, 333, 444, 555, 666, 777, 888, 999]
lt = [999, 777, 555, 333, 111, 888, 666, 444, 222]
s = 0
________1________
print(s)
1.for I in range(len(ls)):
s=s+ls[I]+lt[i]
**键盘输入一个9800到9811之间的正整数n,作为Unicode编码,把n-1、n和n+1三个Unicode 编码对应字符按照如下格式要求输出到屏幕:宽度为11个字符,加号字符+填充,居中。
例如:
键盘输入:9802
屏幕输出:++++???++++ **
n = eval(input("请输入一个数字:"))
print("{__1____}".format(___2___))
1.:+^11
2.chr(n-1)+chr(n)+chr(n+1)
**
1.使用字典和列表型变量完成最有人气的明星的投票数据分析。投票信息由附件里的文件 vote.txt 给出,一行只有一个明星姓名的投票才是有效票。有效票中得票最多的明星当选最有人气的明星。
问题一:请统计有效票张数。在编程模板中补充代码完成程序。**

f = open("vote.txt",encoding="utf-8")
names = f.readlines()
f.close()
n = 0
for name in _______(1)_________:
num = _______(2)_________
if _______(3)________:
n+=__(4)____
print("有效票{}张".format(n))
1.names
2.name.split(" ")
3.len(num)==1
4.1
获得用户输入的以逗号分隔的三个数字,记为a、b、c,以a为起始数值,b为前后相邻数的比值,c为数列长度,产生一个等比数列,将这个数列以逗号分隔的形式输出,最后一个元素输出后无逗号,请完善模板中的代码。
a, b, c = _______(1)_________
ls = []
for i in range(c):
_______(2)_________
print(",".join(ls))
1.eval(input())
2.ls.append(str(a*(b**i)))
根据斐波那契数列的定义,F(0)=0,F(1)=1,F(n)=F(n-1)+F(n-2)(n>=2),输出不大于100的序列元素。
例如:屏幕输出实例为:
0,1,1,2,3,…(略)
a, b = 0, 1
while __1____:
print(a, end=',')
a, b = ___2___
1.a<=100
2.b,a+b
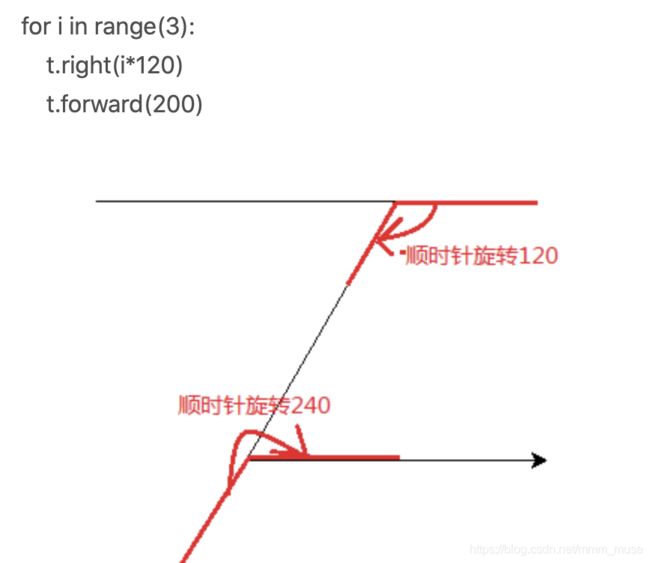
使用Turtle 库的turtle.right()函数和turtle.fd()绘制一个菱形,边长为200像素,4个内角度数为2个60度和2个120度效果如下图所示
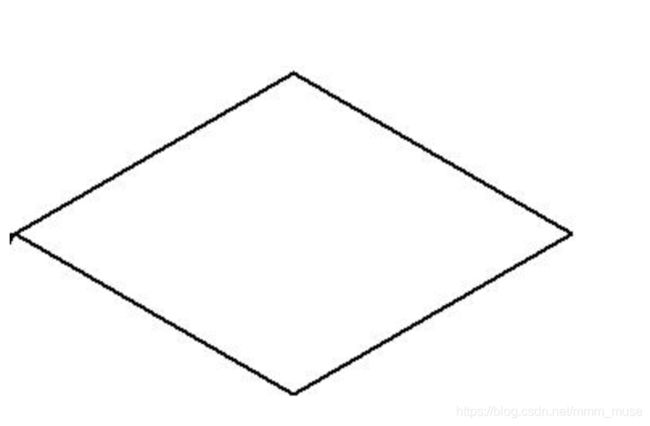
import turtle
turtle.right(-30)
___(1)___
turtle.right(60)
turtle.fd(200)
___(2)___
turtle.fd(200)
turtle.right(60)
turtle.fd(200)
turtle.right(120)
1.turtle.fd(200)
2.turtle.right(120)
turtle.right(degree):顺时针移动degree°
turtle.left(degree):逆时针移动degree°
** 键盘输入某个班级各个同学就业的行业名称,行业名称之间用空格间隔(回车结束输入)。完善python代码,统计各行各业就业的学生数量,按数量从高到低方式输出。例如输入:
交通 金融 计算机 交通 计算机 计算机
输出参考格式如下,其中冒号为英文冒号:
计算机:3
交通:2
金融:1 **
names=input("请输入各个同学行业名称,行业名称之间用空格间隔(回车结束输入):")
...
d = {
}
.1..
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 按照数量排序
for k in ls:
print("{}:{}".format(__2____))
1.for I in names.split():
d[I]=d.get(I,0)+1
2.for k in range(len(ls)):
print("{}:{}".format(ls[k][0],ls[k][1]))
我是这样写的,大家随意
by the way:一开始我写成了names.split(" “) ,split(” ")和split() 是不同的,前者只分一个空格,后者可分多个。
获得用户输入的一个数字,对该数字以30字符宽度,十六进制,居中输出,字母小写,多余字符采用双引号(")填充,请完善模板中代码。注(英文引号)
s = input()
print("{_______(1)_________}".format(_______(2)_________))
1.:"^30x
2.eval(s)
获得用户输入的一个数字,其中数字字符(0到9)用对应的中文字符“O一二三四五六七八九十”替换,输出替换后的结果,请完善模板中的代码。
n = input()
s = "〇一二三四五六七八九"
for c in "0123456789":
_______(1)_________
print(n)
1.n=n.replace(c,s[int©])
本题的提示已经在编程模板中给出,其中的代码可以修改,请删除横线 ,补全代码。实现以下功能:
键盘输入一组人员姓名、年龄、性别等信息,信息间采用空格分隔,每人一行,空行回车结束录入,示例格式如下:
张三 23 男
李四 21 女
王五 18 男
计算并输出这组人员的平均年龄(保留2位小数)和其中男性人数,格式如下:平均年龄是20.67 男性人数是2
data = input() # 姓名 年龄 性别
.1..
while data:
.2..
data = input()
..3.
print("平均年龄是{:.2f} 男性人数是{}".format(___4___))
I=0
sum_age=0
nan_num=0
i+=1
name,age,sex=data.split()
sum_age=sum_age+int(age)
if sex==“男”:
nan_num+=1
4.
sum_age/i,nan_num
获得用户的非数字输入,如果输入中存在数字,则要求用户重新输入,直至满足条件为止,并输出用户输入字符的个数,完善模板中的代码,可以删除全部提示代码,删除横线完成编程。
while True:
s = input("请输入不带数字的文本:")
..1.
print(len(s))
I=0
for p in s:
if “0”<=p<=“9”:
I=I+1
if I==0:
break
print(len(s))
《三国演义》是中国古典四大名著之一,曹操是其中主要人物,考生文件夹下文件data.txt 给出《三国演义》简介。
---------------------------------------
本题解答问题1
问题1:(10分)请编写程序,用Python语言中文分词第三方库jieba对文件 data.txt进行分词,并将结果写入文件out.txt,每行一个词,例如:
内容简介
编辑
整个
故事
在
东汉
…
在右侧的程序框架文件中 补充代码完成程序。
import jieba
f = open('data.txt','r')
lines = f.readlines()
f.close()
f = open('out.txt','w')
for line in lines:
line = ______(1)______ #删除每行首尾可能出现的空格
wordList = ______(2)______ #用结巴分词,对每行内容进行分词
f.writelines('\n'.______(3)______) #将分词结果存到文件out.txt中
f.close()
import jieba
f = open('data.txt','r')
lines = f.readlines()
f.close()
f = open('out.txt','w')
for line in lines:
line=line.strip()
wordList = jieba.lcut(line)
for ii in wordList:
f.writelines("{}\n".format(ii)) #将分词结果存到文件out.txt中
f.close()
以上是我自己写的,并非标准答案
问题2:(10分)对文件out.txt 进行分析,打印输出曹操出现的次数
import jieba
f = open('out.txt','r') #以读的方式打开文件
words = f.readlines()
f.close()
D={
}
for w in _______(1)_________: #词频统计
D[w[:-1]]=_______(2)_________ + 1
print("曹操出现次数为:{} ".format(_______(3)_________))
import jieba
f = open('out.txt','r') #以读的方式打开文件
words = f.readlines()
f.close()
D={
}
for w in words: #词频统计
D[w[:-1]]= D.get(w[:-1],0)+ 1
print("曹操出现次数为:{} ".format(D.get("曹操")))
**模板中给出的代码是本题目的提示框架,其中代码可以任意修改。请在该文件中删除横线,编写代码,以实现一下功能:
键盘输入小明学习的课程名称及考分等信息,信息间采用空格分隔,每个课程一行,空行回车结束录入,示例格式如下:
数学 90
语文 95
英语 86
物理 84
生物 87
屏幕输出得分最高的课程以及成绩,得分最低的课程及成绩,以及平均分(保留2位小数)。
注意,其中逗号为英文逗号,格式如下;
最高分课程是语文95, 最低分课程是物理84, 平均分是88.40
**
data = input() # 课程名 考分
...
while data:
...
data = input()
...
print("最高分课程是{}{}, 最低分课程是{}{}, 平均分是{:.2f}".format(______))
data = input() # 课程名 考分
sumsub=0
i=0
d={
}
while data:
i+=1
sub,num=data.split()
d[sub]=int(num) #记得赋值时要转成int类型
sumsub=sumsub+int(num)
data = input()
ls=list(d.items())
ls.sort(key=lambda x:x[1],reverse=True)
pingjun=sumsub/i
print("最高分课程是{}{}, 最低分课程是{}{}, 平均分是{:.2f}".format(ls[0][0],ls[0][1],ls[-1][0],ls[-1][1],pingjun))
在附件中有一个 data.txt文件是一个来源于网上的技术信息资料。
---------------------------------------
本题回答问题1
问题1 (10分)在右侧的编程框内,补充修改代码完成程序。用Python语言中文分词第三方库jieba对文件data.txt进行分词,并选择长度大于等于3个字符的关键词,写入文件out1.txt,每行一个关键词,各行的关键词不重复,输出顺序不做要求,例如:
人工智能
科幻小说
…
import jieba
txt=open('data.txt','r').read()
ls=[]
f = open('out1.txt','w',encoding="utf-8")
txt1=jieba.lcut(txt)
for i in txt1:
if len(i)<3:
continue
else:
if i not in ls:
ls.append(i)
f.writelines('\n'.join(ls))
f.close()
第二题:计数长度超过3的词频输出到out2.txt
import jieba
txt=open('data.txt','r').read()
txt1=jieba.lcut(txt)
d = {
}
for i in txt1:
if len(i)<3:
continue
else:
d[i]=d.get(i,0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 此行可以按照词频由高到低排序
file=open('out2.txt','w') # 此处可多行
for i in range(len(ls)):
file.writelines('{}:{}\n'.format(ls[i][0],ls[i][1]))
好啦,到这里就差不多分享结束啦,希望小可爱们好好复习,考试顺利~~~回见~(o^^o)