Python爬虫实例——爬取美团美食数据
1.分析美团美食网页的url参数构成
1)搜索要点
美团美食,地址:北京,搜索关键词:火锅
2)爬取的url
https://bj.meituan.com/s/%E7%81%AB%E9%94%85/
3)说明
url会有自动编码中文功能。所以火锅二字指的就是这一串我们不认识的代码%E7%81%AB%E9%94%85。
通过关键词城市的url构造,解析当前url中的bj=北京,/s/后面跟搜索关键词。
这样我们就可以了解到当前url的构造。
![]()
2.分析页面数据来源(F12开发者工具)
开启F12开发者工具,并且刷新当前页面:可以看到切换到第二页时候,我们的url没有变化,网站也没有自动进行刷新跳转操作。(web中ajax技术就是在保证页面不刷新,url不变化情况下进行数据加载的技术)

此时我们需要在开发者工具中,找到xhr里面对应当前数据的响应文件。
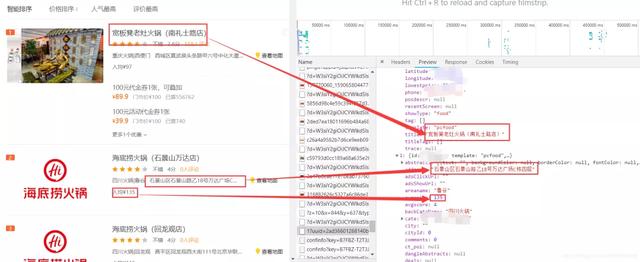
分析到这里可以得知:我们的数据是以json格式交互。分析第二页的json文件请求地址与第三页json文件的请求地址。
第二页:https://apimobile.meituan.com/group/v4/poi/pcsearch/1?uuid=xxx&userid=-1&limit=32&offset=32&cateId=-1&q=%E7%81%AB%E9%94%85
第三页:https://apimobile.meituan.com/group/v4/poi/pcsearch/1?uuid=xxx&userid=-1&limit=32&offset=64&cateId=-1&q=%E7%81%AB%E9%94%85
对比发现:offse参数每次翻页增加32,并且limit参数是一次请求的数据量,offse是数据请求的开始元素,q是搜索关键词poi/pcsearch/1?其中的1是北京城市的id编号。
3.构造请求抓取美团美食数据
接下来直接构造请求,循环访问每一页的数据,最终代码如下。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
|
运行结果如下:
本地文件:

4.总结
根据搜索词变化,城市变化,可以改变url中指定的参数来实现。同时也要记得变更headers中的指定参数,方法简单,多加练习即可熟悉ajax类型的数据抓取。
以上就是Python爬虫实例——爬取美团美食数据的详细内容,更多关于Python爬虫爬取美食数据的资料请关注脚本之家其它相关文章!