hive中groupby优化_Hive的10种常用优化总结,再也不怕MapReduce分配不均了
Hive作为大数据领域常用的数据仓库组件,在平时设计和查询时要特别注意效率。影响Hive效率的几乎从不是数据量过大,而是数据倾斜、数据冗余、job或I/O过多、MapReduce分配不合理等等。对Hive的调优既包含对HiveSQL语句本身的优化,也包含Hive配置项和MR方面的调整。
列裁剪和分区裁剪
最基本的操作。所谓列裁剪就是在查询时只读取需要的列,分区裁剪就是只读取需要的分区。以我们的日历记录表为例:
select uid,event_type,record_datafrom calendar_record_logwhere pt_date >= 20190201 and pt_date <= 20190224and status = 0;当列很多或者数据量很大时,如果select *或者不指定分区,全列扫描和全表扫描效率都很低。
Hive中与列裁剪优化相关的配置项是hive.optimize.cp,与分区裁剪优化相关的则是hive.optimize.pruner,默认都是true。在HiveSQL解析阶段对应的则是ColumnPruner逻辑优化器。
谓词下推
在关系型数据库如MySQL中,也有谓词下推(Predicate Pushdown,PPD)的概念。它就是将SQL语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量。
例如以下HiveSQL语句:
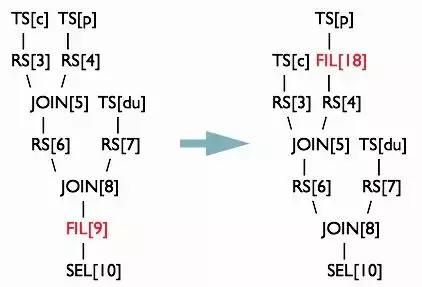
select a.uid,a.event_type,b.topic_id,b.titlefrom calendar_record_log aleft outer join (select uid,topic_id,title from forum_topicwhere pt_date = 20190224 and length(content) >= 100) b on a.uid = b.uidwhere a.pt_date = 20190224 and status = 0;对forum_topic做过滤的where语句写在子查询内部,而不是外部。Hive中有谓词下推优化的配置项hive.optimize.ppd,默认值true,与它对应的逻辑优化器是PredicatePushDown。该优化器就是将OperatorTree中的FilterOperator向上提,见下图。
sort by代替order by
HiveSQL中的order by与其他SQL方言中的功能一样,就是将结果按某字段全局排序,这会导致所有map端数据都进入一个reducer中,在数据量大时可能会长时间计算不完。
如果使用sort by,那么还是会视情况启动多个reducer进行排序,并且保证每个reducer内局部有序。为了控制map端数据分配到reducer的key,往往还要配合distribute by一同使用。如果不加distribute by的话,map端数据就会随机分配到reducer。
group by代替distinct
当要统计某一列的去重数时,如果数据量很大,count(distinct)就会非常慢,原因与order by类似,count(distinct)逻辑只会有很少的reducer来处理。这时可以用group by来改写:
select count(1) from (select uid from calendar_record_logwhere pt_date >= 20190101group by uid) t;但是这样写会启动两个MR job(单纯distinct只会启动一个),所以要确保数据量大到启动job的overhead远小于计算耗时,才考虑这种方法。当数据集很小或者key的倾斜比较明显时,group by还可能会比distinct慢。
那么如何用group by方式同时统计多个列?下面是解决方法:
select t.a,sum(t.b),count(t.c),count(t.d) from (select a,b,null c,null d from some_tableunion allselect a,0 b,c,null d from some_table group by a,cunion allselect a,0 b,null c,d from some_table group by a,d) t;group by配置调整
map端预聚合
group by时,如果先起一个combiner在map端做部分预聚合,可以有效减少shuffle数据量。预聚合的配置项是hive.map.aggr,默认值true,对应的优化器为GroupByOptimizer,简单方便。
通过hive.groupby.mapaggr.checkinterval参数也可以设置map端预聚合的行数阈值,超过该值就会分拆job,默认值100000。
倾斜均衡配置项
group by时如果某些key对应的数据量过大,就会发生数据倾斜。Hive自带了一个均衡数据倾斜的配置项hive.groupby.skewindata,默认值false。
其实现方法是在group by时启动两个MR job。第一个job会将map端数据随机输入reducer,每个reducer做部分聚合,相同的key就会分布在不同的reducer中。第二个job再将前面预处理过的数据按key聚合并输出结果,这样就起到了均衡的效果。
但是,配置项毕竟是死的,单纯靠它有时不能根本上解决问题,因此还是建议自行了解数据倾斜的细节,并优化查询语句。
join基础优化
join优化是一个复杂的话题,下面先说5点最基本的注意事项。
build table(小表)前置
在最常见的hash join方法中,一般总有一张相对小的表和一张相对大的表,小表叫build table,大表叫probe table。如下图所示。
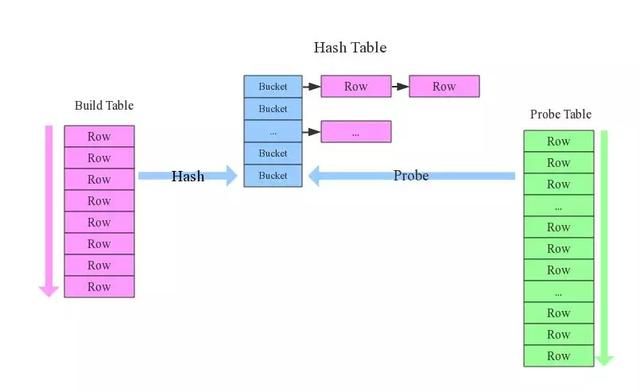
Hive在解析带join的SQL语句时,会默认将最后一个表作为probe table,将前面的表作为build table并试图将它们读进内存。如果表顺序写反,probe table在前面,引发OOM的风险就高了。
在维度建模数据仓库中,事实表就是probe table,维度表就是build table。假设现在要将日历记录事实表和记录项编码维度表来join:
select a.event_type,a.event_code,a.event_desc,b.upload_timefrom calendar_event_code ainner join (select event_type,upload_time from calendar_record_logwhere pt_date = 20190225) b on a.event_type = b.event_type;多表join时key相同
这种情况会将多个join合并为一个MR job来处理,例如:
select a.event_type,a.event_code,a.event_desc,b.upload_timefrom calendar_event_code ainner join (select event_type,upload_time from calendar_record_logwhere pt_date = 20190225) b on a.event_type = b.event_typeinner join (select event_type,upload_time from calendar_record_log_2where pt_date = 20190225) c on a.event_type = c.event_type;如果上面两个join的条件不相同,比如改成a.event_code = c.event_code,就会拆成两个MR job计算。
负责这个的是相关性优化器CorrelationOptimizer.
利用map join特性
map join特别适合大小表join的情况。Hive会将build table和probe table在map端直接完成join过程,消灭了reduce,效率很高。
select a.event_type,b.upload_timefrom calendar_event_code ainner join (select event_type,upload_time from calendar_record_logwhere pt_date = 20190225) b on a.event_type < b.event_type;上面的语句中加了一条map join hint,以显式启用map join特性。早在Hive 0.8版本之后,就不需要写这条hint了。map join还支持不等值连接,应用更加灵活。
map join的配置项是hive.auto.convert.join,默认值true,对应逻辑优化器是MapJoinProcessor。
还有一些参数用来控制map join的行为,比如hive.mapjoin.smalltable.filesize,当build table大小小于该值就会启用map join,默认值25000000(25MB)。还有hive.mapjoin.cache.numrows,表示缓存build table的多少行数据到内存,默认值25000。
分桶表map join
map join对分桶表还有特别的优化。由于分桶表是基于一列进行hash存储的,因此非常适合抽样(按桶或按块抽样)。
它对应的配置项是hive.optimize.bucketmapjoin,优化器是BucketMapJoinOptimizer。但我们的业务中用分桶表较少,所以就不班门弄斧了,只是提一句。
倾斜均衡配置项
这个配置与上面group by的倾斜均衡配置项异曲同工,通过hive.optimize.skewjoin来配置,默认false。
如果开启了,在join过程中Hive会将计数超过阈值hive.skewjoin.key(默认100000)的倾斜key对应的行临时写进文件中,然后再启动另一个job做map join生成结果。通过hive.skewjoin.mapjoin.map.tasks参数还可以控制第二个job的mapper数量,默认10000。
再重复一遍,通过自带的配置项经常不能解决数据倾斜问题。join是数据倾斜的重灾区,后面还要介绍在SQL层面处理倾斜的各种方法。
优化SQL处理join数据倾斜
空值或无意义值
这种情况很常见,比如当事实表是日志类数据时,往往会有一些项没有记录到,我们视情况会将它置为null,或者空字符串、-1等。如果缺失的项很多,在做join时这些空值就会非常集中,拖累进度。
因此,若不需要空值数据,就提前写where语句过滤掉。需要保留的话,将空值key用随机方式打散,例如将用户ID为null的记录随机改为负值:
select a.uid,a.event_type,b.nickname,b.agefrom (select (case when uid is null then cast(rand()*-10240 as int) else uid end) as uid, event_type from calendar_record_logwhere pt_date >= 20190201) a left outer join (select uid,nickname,age from user_info where status = 4) b on a.uid = b.uid;单独处理倾斜key
这其实是上面处理空值方法的拓展,不过倾斜的key变成了有意义的。一般来讲倾斜的key都很少,我们可以将它们抽样出来,对应的行单独存入临时表中,然后打上一个较小的随机数前缀(比如0~9),最后再进行聚合。SQL语句与上面的相仿,不再赘述。
不同数据类型
这种情况不太常见,主要出现在相同业务含义的列发生过逻辑上的变化时。
举个例子,假如我们有一旧一新两张日历记录表,旧表的记录类型字段是(event_type int),新表的是(event_type string)。为了兼容旧版记录,新表的event_type也会以字符串形式存储旧版的值,比如'17'。当这两张表join时,经常要耗费很长时间。其原因就是如果不转换类型,计算key的hash值时默认是以int型做的,这就导致所有“真正的”string型key都分配到一个reducer上。所以要注意类型转换:
select a.uid,a.event_type,b.record_datafrom calendar_record_log aleft outer join (select uid,event_type from calendar_record_log_2where pt_date = 20190228) b on a.uid = b.uid and b.event_type = cast(a.event_type as string)where a.pt_date = 20190228;build table过大
有时,build table会大到无法直接使用map join的地步,比如全量用户维度表,而使用普通join又有数据分布不均的问题。这时就要充分利用probe table的限制条件,削减build table的数据量,再使用map join解决。代价就是需要进行两次join。举个例子:
select /*+mapjoin(b)*/ a.uid,a.event_type,b.status,b.extra_infofrom calendar_record_log aleft outer join (select /*+mapjoin(s)*/ t.uid,t.status,t.extra_infofrom (select distinct uid from calendar_record_log where pt_date = 20190228) sinner join user_info t on s.uid = t.uid) b on a.uid = b.uidwhere a.pt_date = 20190228;MapReduce优化
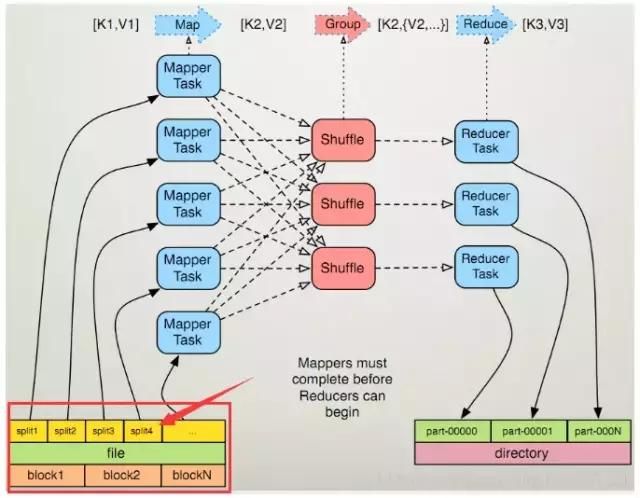
调整mapper数
mapper数量与输入文件的split数息息相关,在Hadoop源码org.apache.hadoop.mapreduce.lib.input.FileInputFormat类中可以看到split划分的具体逻辑。这里不贴代码,直接叙述mapper数是如何确定的。
- 可以直接通过参数mapred.map.tasks(默认值2)来设定mapper数的期望值,但它不一定会生效,下面会提到。
- 设输入文件的总大小为total_input_size。HDFS中,一个块的大小由参数dfs.block.size指定,默认值64MB或128MB。在默认情况下,mapper数就是:
default_mapper_num = total_input_size / dfs.block.size。 - 参数mapred.min.split.size(默认值1B)和mapred.max.split.size(默认值64MB)分别用来指定split的最小和最大大小。split大小和split数计算规则是:
split_size = MAX(mapred.min.split.size, MIN(mapred.max.split.size, dfs.block.size));
split_num = total_input_size / split_size。 - 得出mapper数:
mapper_num = MIN(split_num, MAX(default_num, mapred.map.tasks))。
可见,如果想减少mapper数,就适当调高mapred.min.split.size,split数就减少了。如果想增大mapper数,除了降低mapred.min.split.size之外,也可以调高mapred.map.tasks。
一般来讲,如果输入文件是少量大文件,就减少mapper数;如果输入文件是大量非小文件,就增大mapper数;至于大量小文件的情况,得参考下面“合并小文件”一节的方法处理。
调整reducer数
reducer数量的确定方法比mapper简单得多。使用参数mapred.reduce.tasks可以直接设定reducer数量,不像mapper一样是期望值。但如果不设这个参数的话,Hive就会自行推测,逻辑如下:
- 参数hive.exec.reducers.bytes.per.reducer用来设定每个reducer能够处理的最大数据量,默认值1G(1.2版本之前)或256M(1.2版本之后)。
- 参数hive.exec.reducers.max用来设定每个job的最大reducer数量,默认值999(1.2版本之前)或1009(1.2版本之后)。
- 得出reducer数:
reducer_num = MIN(total_input_size / reducers.bytes.per.reducer, reducers.max)。
reducer数量与输出文件的数量相关。如果reducer数太多,会产生大量小文件,对HDFS造成压力。如果reducer数太少,每个reducer要处理很多数据,容易拖慢运行时间或者造成OOM。
JVM重用
在MR job中,默认是每执行一个task就启动一个JVM。如果task非常小而碎,那么JVM启动和关闭的耗时就会很长。可以通过调节参数mapred.job.reuse.jvm.num.tasks来重用。例如将这个参数设成5,那么就代表同一个MR job中顺序执行的5个task可以重复使用一个JVM,减少启动和关闭的开销。但它对不同MR job中的task无效。
并行执行与本地模式
- 并行执行
Hive中互相没有依赖关系的job间是可以并行执行的,最典型的就是多个子查询union all。在集群资源相对充足的情况下,可以开启并行执行,即将参数hive.exec.parallel设为true。另外hive.exec.parallel.thread.number可以设定并行执行的线程数,默认为8,一般都够用。 - 本地模式
Hive也可以不将任务提交到集群进行运算,而是直接在一台节点上处理。因为消除了提交到集群的overhead,所以比较适合数据量很小,且逻辑不复杂的任务。
设置hive.exec.mode.local.auto为true可以开启本地模式。但任务的输入数据总量必须小于hive.exec.mode.local.auto.inputbytes.max(默认值128MB),且mapper数必须小于hive.exec.mode.local.auto.tasks.max(默认值4),reducer数必须为0或1,才会真正用本地模式执行。
严格模式
所谓严格模式,就是强制不允许用户执行3种有风险的HiveSQL语句,一旦执行会直接失败。这3种语句是:
- 查询分区表时不限定分区列的语句;
- 两表join产生了笛卡尔积的语句;
- 用order by来排序但没有指定limit的语句。
要开启严格模式,需要将参数hive.mapred.mode设为strict。
结束
写了这么多,肯定有遗漏或错误之处,欢迎各位大佬批评指正。