ceph集群部署
一、ceph特点高性能
1. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,
并行度高。
2.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架
感知等。
3. 能够支持上千个存储节点的规模,支持TB到PB级的数据。
高可用性:
1. 副本数可以灵活控制。
2. 支持故障域分隔,数据强一致性。
3. 多种故障场景自动进行修复自愈。
4. 没有单点故障,自动管理。
高可扩展性:
1. 去中心化。
2. 扩展灵活。
3. 随着节点增加而线性增长。
特性丰富:
1. 支持三种存储接口:块存储、文件存储、对象存储。
2. 支持自定义接口,支持多种语言驱动。
二、ceph提供的存储方式
对象存储(RADOSGW):提供RESTful接口,也提供多种编程语言绑定,兼容S3、Swift;
块存储(RDB):由RBD提供,可以直接作为磁盘挂载,内置了容灾机制;
文件系统(CephFS):提供POSIX兼容的网络文件系统CephFS,专注于高性能、大容量存储;
1、Monitors:监视器,维护集群状态的多种映射,同时提供认证和日志记录服务,包括有关monitor 节点端到端的信息,其中包括 Ceph 集群ID,监控主机名和IP以及端口。并且存储当前版本信息以及最新更改信息,通过 "ceph mon dump"查看 monitor map。
2、MDS(Metadata Server):Ceph 元数据,主要保存的是Ceph文件系统的元数据。注意:ceph的块存储和ceph对象存储都不需要MDS。
3、OSD:即对象存储守护程序,但是它并非针对对象存储。是物理磁盘驱动器,将数据以对象的形式存储到集群中的每个节点的物理磁盘上。OSD负责存储数据、处理数据复制、恢复、回(Backfilling)、再平衡。完成存储数据的工作绝大多数是由 OSD daemon 进程实现。在构建 Ceph OSD的时候,建议采用SSD 磁盘以及xfs文件系统来格式化分区。此外OSD还对其它OSD进行心跳检测,检测结果汇报给Monitor
4、RADOS:Reliable Autonomic Distributed Object Store。RADOS是ceph存储集群的基础。在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致。
5、librados:librados库,为应用程度提供访问接口。同时也为块存储、对象存储、文件系统提供原生的接口。
6、RADOSGW:网关接口,提供对象存储服务。它使用librgw和librados来实现允许应用程序与Ceph对象存储建立连接。并且提供S3 和 Swift 兼容的RESTful API接口。
7、RBD:块设备,它能够自动精简配置并可调整大小,而且将数据分散存储在多个OSD上。
8、CephFS:Ceph文件系统,与POSIX兼容的文件系统,基于librados封装原生接口
1、正常IO流程图
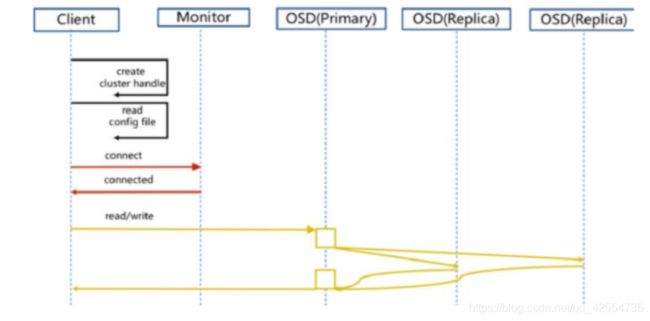
步骤:
1. client 创建cluster handler。
2. client 读取配置文件。
3. client 连接上monitor,获取集群map信息。
4. client 读写io 根据crshmap 算法请求对应的主osd数据节点。
5. 主osd数据节点同时写入另外两个副本节点数据。
6. 等待主节点以及另外两个副本节点写完数据状态。
7. 主节点及副本节点写入状态都成功后,返回给client,io写入完成
2、新主IO流程图
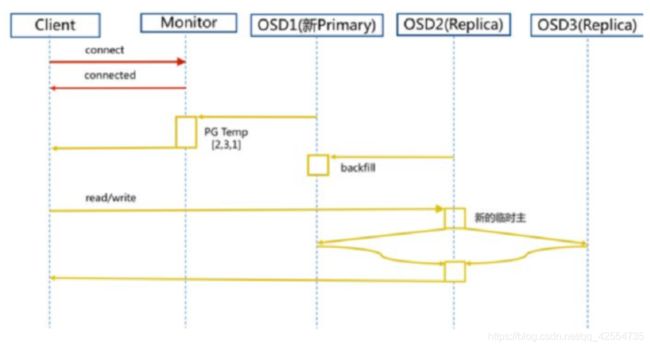
说明:如果新加入的OSD1取代了原有的 OSD4成为 Primary OSD, 由于 OSD1 上未创建 PG , 不存在数据,那么 PG 上的 I/O 无法进行,怎样工作的呢?
新主IO流程步骤:
1. client连接monitor获取集群map信息。
2. 同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。
3. 临时主osd2会把数据全量同步给新主osd1。
4. client IO读写直接连接临时主osd2进行读写。
5. osd2收到读写io,同时写入另外两副本节点。
6. 等待osd2以及另外两副本写入成功。
7. osd2三份数据都写入成功返回给client, 此时client io读写完毕。
8. 如果osd1数据同步完毕,临时主osd2会交出主角色。
9. osd1成为主节点,osd2变成副本。
五、Ceph 数据存储过程
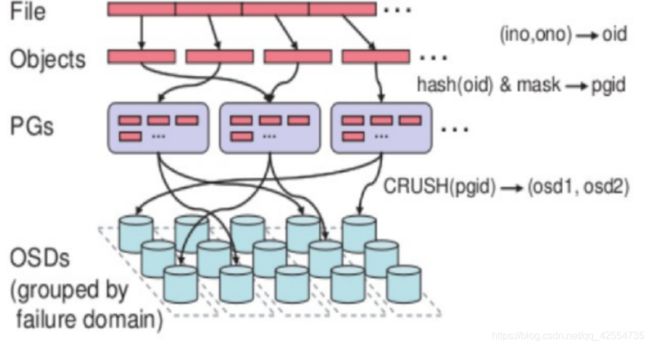
无论使用哪种存储方式(对象、块、文件系统),存储的数据都会被切分成Objects。Objects size大小可以由管理员调整,通常为2M或4M。每个对象都会有一个唯一的OID,由ino与ono生成,虽然这些名词看上去很复杂,其实相当简单。
ino:即是文件的File ID,用于在全局唯一标识每一个文件
ono:则是分片的编号
比如:一个文件FileID为A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的oid则为A0与A1。
File —— 此处的file就是用户需要存储或者访问的文件。对于一个基于Ceph开发的对象存储应用而言,这个file也就对应于应用中的“对象”,也就是用户直接操作的“对象”。
Ojbect —— 此处的object是RADOS所看到的“对象”。Object与上面提到的file的区别是,object的最大size由RADOS限定(通常为2MB或4MB),以便实现底层存储的组织管理。因此,当上层应用向RADOS存入size很大的file时,需要将file切分成统一大小的一系列object(最后一个的大小可以不同)进行存储。为避免混淆,在本文中将尽量避免使用中文的“对象”这一名词,而直接使用file或object进行说明。
PG(Placement Group)—— 顾名思义,PG的用途是对object的存储进行组织和位置映射。具体而言,一个PG负责组织若干个object(可以为数千个甚至更多),但一个object只能被映射到一个PG中,即,PG和object之间是“一对多”映射关系。同时,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,即,PG和OSD之间是“多对多”映射关系。在实践当中,n至少为2,如果用于生产环境,则至少为3。一个OSD上的PG则可达到数百个。事实上,PG数量的设置牵扯到数据分布的均匀性问题。关于这一点,下文还将有所展开。
OSD —— 即object storage device,前文已经详细介绍,此处不再展开。唯一需要说明的是,OSD的数量事实上也关系到系统的数据分布均匀性,因此其数量不应太少。在实践当中,至少也应该是数十上百个的量级才有助于Ceph系统的设计发挥其应有的优势。
基于上述定义,便可以对寻址流程进行解释了。具体而言, Ceph中的寻址至少要经历以下三次映射:
(1)File -> object映射
(2)Object -> PG映射,hash(oid) & mask -> pgid
(3)PG -> OSD映射,CRUSH算法
CRUSH,Controlled Replication Under Scalable Hashing,它表示数据存储的分布式选择算法, ceph 的高性能/高可用就是采用这种算法实现。CRUSH 算法取代了在元数据表中为每个客户端请求进行查找,它通过计算系统中数据应该被写入或读出的位置。CRUSH能够感知基础架构,能够理解基础设施各个部件之间的关系。并CRUSH保存数据的多个副本,这样即使一个故障域的几个组件都出现故障,数据依然可用。CRUSH 算是使得 ceph 实现了自我管理和自我修复。
RADOS 分布式存储相较于传统分布式存储的优势在于:
1. 将文件映射到object后,利用Cluster Map 通过CRUSH 计算而不是查找表方式定位文件数据存储到存储设备的具体位置。优化了传统文件到块的映射和Block MAp的管理。
2. RADOS充分利用OSD的智能特点,将部分任务授权给OSD,最大程度地实现可扩展
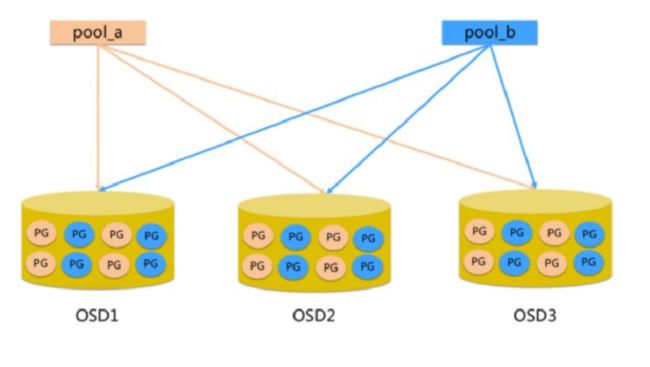
七、Ceph Pool和PG分布情况
pool:是ceph存储数据时的逻辑分区,它起到namespace的作用。每个pool包含一定数量(可配置) 的PG。PG里的对象被映射到不同的Object上。pool是分布到整个集群的。 pool可以做故障隔离域,根据不同的用户场景不统一进行隔离
管理节点:ceph-admin
ceph节点:ceph-node1, ceph-node2, ceph-node3
所有节点:ceph-admin, ceph-node1, ceph-node2, ceph-node3
1. 修改主机名(各个节点)
hostnamectl set-hostname ceph-admin
hostnamectl set-hostname ceph-node1
hostnamectl set-hostname ceph-node2
hostnamectl set-hostname ceph-node3
2. 修改hosts文件(各个节点)
# vi /etc/hosts
192.168.10.102 ceph-admin
192.168.10.103 ceph-node1
192.168.10.104 ceph-node2
192.168.10.105 ceph-node3
二、ceph节点安装(所有节点)
建议在所有 Ceph 节点上安装 NTP 服务(特别是 Ceph Monitor 节点),以免因时钟漂移导致故障
# sudo yum install ntp ntpdate ntp-doc
NTP服务端配置
1.检查系统是否安装了NTP包,没有安装我们直接使用yum命令安装
2.NTP服务端配置文件编辑: vim /etc/ntp.conf
# @3新增-权限配置
restrict *IP* mask 255.255.255.0 nomodify notrap
# @3改动-注释掉上级时间服务器地址
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
# 新增上级时间服务器
server *IP*
3.启动NTP时间服务器:systemctl start ntpd
4.查看NTP是否正常运行:netstat -tlunp | grep ntp
三、 创建部署 CEPH 的用户(所有节点)
ceph-deploy 工具必须以普通用户登录 Ceph 节点,且此用户拥有无密码使用 sudo 的权限,因为它需要在安装软件及配置文件的过程中,不必输入密码。
建议在集群内的所有 Ceph 节点上给 ceph-deploy 创建一个特定的用户,但不要用 “ceph” 这个名字。
1、在各 Ceph 节点创建新用户
#sudo useradd cephu
#sudo passwd cephu
2、确保各 Ceph 节点上新创建的用户都有 sudo 权限
# visudo
最后一行添加:
cephu ALL=(root) NOPASSWD:ALL
四、允许无密码SSH登录(管理节点)
因为 ceph-deploy 不支持输入密码,你必须在**管理节点**上生成 SSH 密钥并把其公钥分发到各 Ceph 节点。 ceph-deploy 会尝试给初始 monitors 生成 SSH 密钥对。
1. 生成 SSH 密钥对
不要用 sudo 或 root 用户。
# su cephu
$ ssh-keygen #一路回车
2. 把公钥拷贝到各 Ceph 节点
$ ssh-copy-id ceph-node1
$ ssh-copy-id ceph-node2
$ ssh-copy-id ceph-node3
3. 修改 ~/.ssh/config 文件(没有则新增),这样 ceph-deploy 就能用你所建的用户名登录 Ceph 节点了
$ sudo vi ~/.ssh/config
Host ceph-admin
Hostname ceph-admin
User cephu
Host ceph-node1
Hostname ceph-node1
User cephu
Host ceph-node2
Hostname ceph-node2
User cephu
Host ceph-node3
Hostname ceph-node3
User cephu
4. 测试ssh能否成功
$ ssh ceph-node1
exit
$ ssh ceph-node2
exit
$ ssh ceph-node3
exit
$ sudo chmod 644 ~/.ssh/config
五、 配置EPEL源(所有节点)
$ sudo yum install -y yum-utils && sudo yum-config-manager --add-repo https://dl.fedoraproject.org/pub/epel/7/x86_64/ && sudo yum install --nogpgcheck -y epel-release && sudo rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 && sudo rm /etc/yum.repos.d/dl.fedoraproject.org*
1. 把软件包源加入软件库(管理节点)
$ sudo vi /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/$basearch/
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/noarch/
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/SRPMS/
enabled=1
gpgcheck=0
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
2.新软件库并安装ceph-deploy(管理节点)
$sudo yum update && sudo yum install ceph-deploy
$ sudo yum install yum-plugin-priorities
六、搭建集群
1. 安装准备,创建文件夹(管理节点)
1.在管理节点上创建一个目录,用于保存 ceph-deploy 生成的配置文件和密钥对。
$ cd ~
$ mkdir my-cluster
$ cd my-cluster
注:若安装ceph后遇到麻烦可以使用以下命令进行清除包和配置:
// 删除安装包
$ ceph-deploy purge ceph-admin ceph-node1 ceph-node2 ceph-node3
// 清除配置
$ ceph-deploy purgedata ceph-admin ceph-node1 ceph-node2 ceph-node3
$ ceph-deploy forgetkeys
2. 创建集群和监控节点 (管理节点)
创建集群并初始化监控节点:
这里ceph-node1是monitor节点,所以执行:
$ ceph-deploy new ceph-node1
完成后,my-clster 下多了3个文件:ceph.conf、ceph-deploy-ceph.log 和 ceph.mon.keyring。
3. 修改配置文件
$ cat ceph.conf
[global]
fsid = be35ff7c-8ca8-4900-87f1-73fd1561f1b0
mon_initial_members = ceph-node1
mon_host = 192.168.10.103
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
把 Ceph 配置文件里的默认副本数从 3 改成 2 ,这样只有两个 OSD 也可以达到 active + clean 状态。
把 osd pool default size = 2 加入
$ sed -i '$a\osd pool default size = 2' ceph.conf
如果有多个网卡,
可以把 public network 写入 Ceph 配置文件的 [global] 段:
public network = {
ip-address}/{
netmask}
4. 安装ceph (在所有节点操作 如果在管理节点操作可能会超时)
sudo yum -y remove pciutils-libs
sudo yum -y install ceph ceph-radosgw yum-plugin-priorities
5. 配置初始 monitor(s)、并收集所有密钥(管理节点)
$ ceph-deploy mon create-initial
{
cluster-name}.client.admin.keyring
{
cluster-name}.bootstrap-osd.keyring
{
cluster-name}.bootstrap-mds.keyring
{
cluster-name}.bootstrap-rgw.keyring
6. 添加2个OSD
登录到 Ceph 节点、并给 OSD 守护进程创建一个目录,并添加权限。
$ ssh ceph-node2
$ sudo mkdir -p /data/local/osd0
$ sudo chmod 777 /data/local/osd0/
$ exit
$ ssh ceph-node3
$ sudo mkdir -p /data/local/osd1
$ sudo chmod 777 /data/local/osd1/
$ exit
然后,从管理节点执行 ceph-deploy 来准备 OSD 。
$ ceph-deploy osd prepare ceph-node2:/data/local/osd0 ceph-node3:/data/local/osd1
最后,激活 OSD 。
$ ceph-deploy osd activate ceph-node2:/data/local/osd0 ceph-node3:/data/local/osd1
7.把配置文件和 admin 密钥拷贝到管理节点和 Ceph 节点
$ ceph-deploy admin ceph-admin ceph-node1 ceph-node2 ceph-node3
8.所有节点操作
$sudo chmod +r /etc/ceph/ceph.client.admin.keyring
部署MGR
1 [manager@deploy my-cluster]$ ceph-deploy mgr create node1 node2 node3
开启dashboard
sudo ceph mgr module enable dashboard #开启dashboard模块
sudo ceph config-key set mgr /dashboard/node1/server_addr
9. 检查集群的健康状况和OSD节点状况
ssh ceph-node1 sudo ceph health
ssh ceph-node1 sudo ceph -s
ssh ceph-node2 sudo ceph health
ssh ceph-node2 sudo ceph -s
ssh ceph-node3 sudo ceph health
ssh ceph-node3 sudo ceph -s
[cephu@ceph-admin my-cluster]$ ceph health
HEALTH_OK
[cephu@ceph-admin my-cluster]$ ceph -s
cluster be35ff7c-8ca8-4900-87f1-73fd1561f1b0
health HEALTH_OK
monmap e1: 1 mons at {
ceph-node1=192.168.10.103:6789/0}
election epoch 3, quorum 0 ceph-node1
osdmap e10: 2 osds: 2 up, 2 in
flags sortbitwise,require_jewel_osds
pgmap v26: 64 pgs, 1 pools, 0 bytes data, 0 objects
13883 MB used, 88466 MB / 102350 MB avail
64 active+clean
[cephu@ceph-admin my-cluster]$ ceph osd df
ID WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR PGS
0 0.04880 1.00000 51175M 6791M 44383M 13.27 0.98 64
1 0.04880 1.00000 51175M 7091M 44083M 13.86 1.02 64
TOTAL 102350M 13883M 88466M 13.56
MIN/MAX VAR: 0.98/1.02 STDDEV: 0.29
ceph默认的CRUSH故障域是host级别。
查看当前CRUSH
[cephu@ceph-admin my-cluster]$ ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.01959 root default
-3 0.00980 host ceph-node2
0 hdd 0.00980 osd.0 up 1.00000 1.00000
-5 0.00980 host ceph-node3
1 hdd 0.00980 osd.1 up 1.00000 1.00000
获取当前Crush Map
[root@ceph-osd1 ~]# ceph osd getcrushmap -o /tmp/cephcrushmap
反编译Crush Map
因为/tmp/cephcrushmap是一个二进制文件,需要通过crushtool反编译为文本文件。
[root@ceph-osd1 ~]# crushtool -d /tmp/cephcrushmap > /tmp/cephcrushmap.txt
编译Crush Map文本文件为二进制文件
[root@ceph-osd1 ~]# crushtool -c /tmp/cephcrushmap.txt -o /tmp/cephcrushmap.new
把新的Crush Map应用于集群并生效
[root@ceph-osd1 ~]# ceph osd setcrushmap -i /tmp/cephcrushmap.new
四、创建Pool
执行以下命令创建一个pool,名字叫pool1
$ sudo ceph osd pool create pool1 128
执行以下命令将pool的size(副本数)设置为2,否则执行命令rbd ls pool1时会卡住
$ sudo ceph osd pool set pool1 size 2
执行命令sudo ceph -s查看pg的状态,应该是active+clean
$ sudo ceph -s
...
data:
pools: 1 pools, 128 pgs
objects: 0 objects, 0B
usage: 1.00GiB used, 19.0GiB / 20.0GiB avail
pgs: 128 active+clean
执行以下命令,可以看到ceph集群中的pool
$ sudo ceph osd pool ls
pool1
如果想删除pool1,则执行以下的命令
$ sudo ceph osd pool delete pool1 pool1 --yes-i-really-really-mean-it
重启ceph-mon服务,命令如下:
$ systemctl restart ceph-mon.target
扩展 -------网上复制下来的 没操作
四、扩展集群(扩容)
1. 添加OSD
在 ceph-node1 上添加一个 osd.2。
- 创建目录
$ ssh ceph-node1
$ sudo mkdir /var/local/osd2
$ sudo chmod 777 /var/local/osd2/
$ exit
- 准备OSD
$ ceph-deploy osd prepare ceph-node1:/var/local/osd2
- 激活OSD
$ ceph-deploy osd activate ceph-node1:/var/local/osd2
- 检查集群状况和OSD节点:
[zeng@ceph-admin my-cluster]$ ceph -s
cluster a3dd419e-5c99-4387-b251-58d4eb582995
health HEALTH_OK
monmap e1: 1 mons at {
ceph-node1=192.168.0.131:6789/0}
election epoch 3, quorum 0 ceph-node1
osdmap e15: 3 osds: 3 up, 3 in
flags sortbitwise,require_jewel_osds
pgmap v37: 64 pgs, 1 pools, 0 bytes data, 0 objects
19450 MB used, 32731 MB / 52182 MB avail
64 active+clean
[zeng@ceph-admin my-cluster]$ ceph osd df
ID WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR PGS
0 0.01659 1.00000 17394M 6478M 10915M 37.24 1.00 41
1 0.01659 1.00000 17394M 6478M 10915M 37.24 1.00 43
2 0.01659 1.00000 17394M 6494M 10899M 37.34 1.00 44
TOTAL 52182M 19450M 32731M 37.28
MIN/MAX VAR: 1.00/1.00 STDDEV: 0.04
2. 添加MONITORS
在 ndoe2 和 ceph-node3 添加监控节点。
- 修改
mon_initial_members、mon_host和public network配置:
[global]
fsid = a3dd419e-5c99-4387-b251-58d4eb582995
mon_initial_members = ceph-node1,ceph-node2,ceph-node3
mon_host = 192.168.0.131,192.168.0.132,192.168.0.133
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size = 2
public network = 192.168.0.120/24
- 推送至其他节点:
$ ceph-deploy --overwrite-conf config push ceph-node1 ceph-node2 ceph-node3
- 添加监控节点:
$ ceph-deploy mon add ceph-node2 ceph-node3
- 查看集群状态和监控节点:
[zeng@ceph-admin my-cluster]$ ceph -s
cluster a3dd419e-5c99-4387-b251-58d4eb582995
health HEALTH_OK
monmap e3: 3 mons at {
ceph-node1=192.168.0.131:6789/0,ceph-node2=192.168.0.132:6789/0,ceph-node3=192.168.0.133:6789/0}
election epoch 8, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3
osdmap e25: 3 osds: 3 up, 3 in
flags sortbitwise,require_jewel_osds
pgmap v3919: 64 pgs, 1 pools, 0 bytes data, 0 objects
19494 MB used, 32687 MB / 52182 MB avail
64 active+clean
[zeng@ceph-admin my-cluster]$ ceph mon stat
e3: 3 mons at {
ceph-node1=192.168.0.131:6789/0,ceph-node2=192.168.0.132:6789/0,ceph-node3=192.168.0.133:6789/0}, election epoch 8, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3