深度集成 Flink: Apache Iceberg 0.11.0 最新功能解读
在 2021 年 1 月 27 日,Apache Iceberg 发布了 0.11.0 版本[1]。在这个版本中,实现了以下核心功能:
1、Apache Iceberg 在 Core API 层面支持了 partition 的变更;同时还在 Iceberg Format v2 之上新增了 SortOrder 规范,主要用于将那些散列度较高的 column 聚集在少数几个文件内,这样可以大量减少小文件的数量。同时提高读取的效率,因为数据通过 sort 写入后,文件级别和 Page 级别的 min-max 范围将更小,有助于高效的数据过滤。
2、在 Flink 和 Iceberg 的集成方面,社区实现了以下目标:
实现了 Flink Streaming Reader,意味着我们可以通过 Flink 流作业增量地去拉取 Apache Iceberg 中新增数据。对 Apache Iceberg 这样流批统一的存储层来说,Apache Flink 是真正意义上第一个实现了流批读写 Iceberg 的计算引擎,这也标志着 Apache Flink 和 Apache Iceberg 在共同打造流批统一的数据湖架构上开启了新的篇章。
实现了 Flink Streaming/Batch Reader 的 limit pushdown 和 filter pushdown。
实现了 CDC 和 Upsert 事件通过 flink 计算引擎写入 Apache Iceberg,并在中等数据规模上完成了正确性验证。
在 Flink Iceberg Sink 中支持 write.distribution-mode=hash 的方式写入数据,这可以从生产源头上大量减少小文件。
3、在 Spark3 和 Iceberg 的集成方面,社区支持了大量高阶 SQL:
MERGE INTO
DELETE FROM
ALTER TABLE ... ADD/DROP PARTITION
ALTER TABLE ... WRITE ORDERED BY
通过 Call
方式来执行更多的数据管理操作,例如合并小文件、清理过期文件等。
4、在周边生态集成方面,社区实现了以下目标:
引入 AWS module,完成和 AWS S3[2] 以及 Glue Catalog[3] 等云服务的集成;
集成流行的开源 catalog 服务 nessie[4]。
在接下来的内容里,我将说明 Apache Iceberg 0.11.0 在 Apache Flink 集成方面做的一些具体工作。
Apache Flink流式读取
在 Apache Iceberg 0.10.0 版本中,我们已经在 Flink SQL 层面支持了:
流作业写入 Apache Iceberg 表;
批作业写入 Apache Iceberg 表;
批作业读取 Apache Iceberg 表;
在最新的 Apache Iceberg 0.11.0 版本中,我们又成功集成了 Flink 流作业读取 Apache Iceberg 表。有了这个功能,可以很方便地实现不同 Iceberg 表之间的数据流转和 ETL。例如我们有一个原始表 A,需要把表 A 通过一些数据处理或者打宽,处理成一个表 B,那么这个场景是很适合用 Apache Iceberg 的 Streaming Reader 来实现的。

除此之外,Netflix 也提出他们在采用 Flink Streaming Reader 来实现历史数据的 backfill 和 boostrap。当然,这需要未来 iceberg 集成到 FLIP-27,目前 Netflix 提供了他们对这块工作的一些实践经验[5]和设计工作[6],大家感兴趣可以参考一下。
目前,对这个功能我们提供了 Flink SQL 和 DataStream API 两种使用方式(推荐采用 Flink SQL)。您可以通过阅读文档[7]来启动 Flink SQL 客户端,然后通过如下方式来启动流作业访问 Apache Iceberg 的增量数据:
-- Submit the flink job in streaming mode for current session.SET execution.type = streaming ;
-- Enable this switch because streaming read SQL will provide few job options in flink SQL hint options.SET table.dynamic-table-options.enabled=true;
-- Read all the records from the iceberg current snapshot, and then read incremental data starting from that snapshot.SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ ;
-- Read all incremental data starting from the snapshot-id '3821550127947089987' (records from this snapshot will be excluded).SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')*/ ;
Flink Source 的
Limit Pushdown 和 Filter Pushdown
在 Flink 的 Batch Source 和 Streaming Source 中,我们对接了 Limit 操作和 Filter 操作跟 Iceberg 表的下推实现。这意味着,在读取 Apache Iceberg 表时,碰到这样的 SQL:
SELECT * FROM sample LIMIT 10;
我们可以在存储层面就完成数据过滤,而不需要把数据从存储层面读取出来,再丢给计算引擎。从而大大提高数据的访问效率。
Filter 的下推也是类似,目前我们支持了如下 Filter 的下推,几乎包含了所有常见 filter 的下推操作:
SELECT * FROM sample WHERE data = 'a';SELECT * FROM sample WHERE data != 'a';SELECT * FROM sample WHERE data >= 'a';SELECT * FROM sample WHERE data <= 'a';SELECT * FROM sample WHERE data < 'a';SELECT * FROM sample WHERE data > 'a';SELECT * FROM sample WHERE data = 'a' AND id = 1;SELECT * FROM sample WHERE data = 'a' OR id = 1;SELECT * FROM sample WHERE data IS NULL;SELECT * FROM sample WHERE NOT (id = 1);SELECT * FROM sample WHERE data LIKE 'aaa%';
对 CDC(例如 MySQL Binlog)
和 Upsert 事件的支持
这个功能是 Apache Flink 社区用户呼声特别高的一个功能,主要来自两个核心场景的需求:
用户希望把来自关系型数据库的 binlog 导入到 Apache Iceberg 数据湖中,提供近实时的数据分析能力。
希望把 Flink 流作业 AGG 产生的 upsert stream 导入到 Apache Iceberg 数据湖中,从而借助 Apache Iceberg 的存储能力和 Apache Flink 的分析能力,提供近实时的数据报表。
通常来说,我们能选的开源方案各有不足:选择采用 Hive MR 则只能提供 T+1 的数据时效性;采用 Apache Kudu 则必须面临跟 HDFS 和云端对象存储脱节的尴尬;选择 HBase 则面临行存导致分析能力不足的问题;选择 Spark+delta 则无法充分利用 Apache Flink 在流计算领域的优势。那么,在 Apache Iceberg 的实现中,这些问题将有望解决。
我们把 flink+iceberg 对 CDC/Upsert 工作的集成大致分成了两个阶段:
第一阶段,是指 Flink 可以顺利地把 CDC 和 Upsert 的数据成功写入到 Apache Iceberg,并能读取到一个正确的结果;
第二阶段,是指 Flink+Iceberg 能顺利通过较大数据量的稳定性测试和性能测试,保证整条链路的稳定性和性能,从而达到可以上生产的水准。
那么,目前我们在 0.11.0 版本中,已经实现了第一阶段的目标,流作业已经能够成功地将 CDC/Upsert 数据写入到 Apache Iceberg 中,国内的小伙伴例如汽车之家和 B 站已经帮忙完成中等数据量的正确性验证。
在未来的 Apache Iceberg 0.12.0 版本中,我们规划了一系列的性能和稳定性相关事情,0.12.0 版本将会是 Iceberg CDC/Upsert 功能达到 Production Ready 的一个标志性版本。
支持 write.distribution-mode=hash
方式写入 Apache Iceberg
在 Flink 流作业写文件系统的数据文件时,非常容易碰到小文件的问题。这是因为如果 source 端的数据,不经过任何 shuffle 或者 cluster,就写入到 partition,很容易导致每个 Task 写了大量的 Partition 和 Bucket。这样对一个 Partition 来说,就存在多个 Task 写入,每个 Task 至少产生一个文件。而在 Apache Iceberg 这种数据湖架构中,Flink 的每一次 checkpoint,都将 Roll over file writer 以便提交 txn,那么随着分钟级别的 checkpoint 提交,一定会产生大量的小文件。
目前在 Apache Iceberg 中,将提供 3 中方式来解决小文件问题:
1、在 Iceberg 表中设置 write.distribution-mode=hash 属性,例如:
CREATE TABLE sample ( id BIGINT, data STRING) PARTITIONED BY (data) WITH ( 'write.distribution-mode'='hash');
这样可以保证每一条记录按照 partition key 做 shuffle 之后再写入,每一个 Partition 最多由一个 Task 来负责写入,大大地减少了小文件的产生。但是,这很容易产生另外一个问题,就是数据倾斜的问题。很多业务表都是按照时间字段来做分区的,而产生的新数据都是按照时间写入的,容易导致新数据都写入同一个 partition,造成写入数据热点。目前我们推荐的做法是,在 partition 下面采用 hash 的方式设置 bucket,那么每一个 partition 的数据将均匀地落到每个 bucket 内,每一个 bucket 最多只会由一个 task 来写,既解决了小文件问题,又解决了数据热点问题。
在 Flink 1.11 版本暂时不支持通过 SQL 的方式创建 bucket,但我们可以通过 Java API 的方式将上述按照 data 字段 partition 之后的表添加 bucket。调用方式如下:
table.updateSpec()
.addField(Expressions.bucket("id", 32))
.commit();
2、定期对 Apache Iceberg 表执行 Major Compaction 来合并 Apache iceberg 表中的小文件。这个作业目前是一个 Flink 的批作业,提供 Java API 的方式来提交作业,使用姿势可以参考文档[8]。
3、在每个 Flink Sink 流作业之后,外挂算子用来实现小文件的自动合并。这个功能目前暂未 merge 到社区版本,由于涉及到 format v2 的 compaction 的一些讨论,我们会在 0.12.0 版本中发布该功能。
总结
自 Apache Flink 接入 Apache Iceberg 以来,社区已经成功地发布了两个版本。在这两个版本中,我们已经成功地实现 Flink+Iceberg 的流批读写能力。
到目前为止,Flink+Iceberg 在国内外已经有不少成功的上线案例:
腾讯内部每天都有大量的日志数据通过 Flink 清洗处理后导入到 Iceberg,最大的表日新增几十 TB;
Netflix 则将公司内几乎所有的用户行为数据通过 Flink 流计算导入到 Iceberg,最终存储在 AWS S3 之上,相比 HDFS 的方式, Flink+Iceberg 帮助他们公司节省大量的存储成本;
同程艺龙也在 Flink+Iceberg 之上做了大量探索,之前几乎所有的分析数据都存储在 Hive 上,鉴于 Hive 在 ACID 和历史回溯等方面能力不足,他们调研了 Iceberg,发现 Iceberg 非常适合替换他们的 Hive 存储格式,又由于上层计算生态的良好对接,几乎所有的历史计算作业都不需要做改动,就能方便地切换 Hive 表到 Iceberg 之上。到目前为止同程艺龙已经完成了几十张 Hive 表到 Iceberg 表的迁移;
汽车之家也是成功在生产环境大量替换 Hive 表为 Iceberg 表的公司之一,同时他们也是最早采用社区版 Iceberg 做 CDC 和 Upsert 数据分析 PoC 的公司,也非常期待未来 0.12.0 对 CDC 和 Upsert 场景的更多优化。
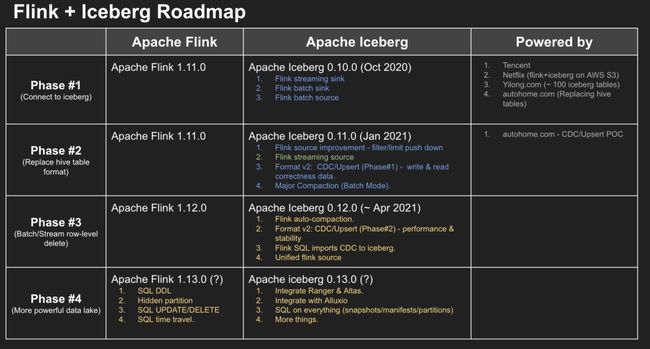
在未来的 Apache Iceberg 0.12.0 版本中,我们规划了上图的核心功能。本质上我们将实现 Flink+Iceberg 对 CDC 及 Upsert 场景的更好支持,将在稳定性、性能、易用性三个方面做更多的优化工作。
最后,我想聊一下 Apache Iceberg 在计算生态方面的现状。
随着 Apache Iceberg 0.11.0 新版的发布,Apache Iceberg 作为一个统一通用的数据湖 Table Format,在生态集成方面的优势愈发明显。由于在 Table Format 层面对计算引擎无偏袒,计算引擎的集成呈现出百花齐放的姿态,大数据生态内几乎所有主流计算引擎都跟 Iceberg 有着不同程度的对接:
Netflix、腾讯和 Apple 几家公司的贡献者主力推动 Spark+Iceberg 的集成,腾讯、Netflix 和 Apple 在 Apache Spark 社区有着多位 Spark PMC 和 Spark Committer,在 Spark 社区和 Iceberg 社区的影响力有目共睹。我个人乐观地判断,Apache Iceberg 和 Spark 的集成体验,未来有望比肩 Databricks delta 的商业版体验,大家可以期待下。
阿里巴巴 Flink 团队、Netflix 以及国内外庞大的 Flink 用户群在不断地推动 Flink+Iceberg 的集成,不再赘述;
AWS Presto 团队以及 Trino 团队则在不断推动着 Presto 和 Iceberg 的集成,AWS Presto 团队已经明确将 Iceberg 选型为他们的数据湖 table format。同时,也可以非常明显地看到,AWS 团队在 Iceberg 和 S3 以及 Glue 生态打通方面做的大量工作,Apache Iceberg 已经成为 AWS 数据湖生态中相当重要的一环。
Cloudera 已经明确地选型 Apache Iceberg 来构建他们的商业版数据湖。使用过 Hadoop 的同学一定不会对这家公司陌生,没错,这家公司就是 Hadoop 商业发行版做的最为出色的公司之一。未来,他们将基于 Apache Iceberg 推出公有云服务,将给用户带来完善的 Flink、Spark、Hive、Impala 数据湖集成体验。这里重点说一下 Apache Impala,Cloudera 在交互式分析场景下非常倚重自家开源的 Apache Impala(事实上,在大数据基准测试下 Impala 的性能表现的确要比 Presto 更好),Apache Iceberg 对存储层较为完美的抽象和对多样化计算引擎的包容,是成功打动 Cloudera 选型 Apache Iceberg 最核心的理由之一。
更多关于 Flink 数据湖的讨论,请扫描下方钉群二维码,加入数据湖技术交流钉钉群。我们会定期在群里发布 Apache Iceberg/Hudi 和 Flink 集成的最新进展,我们也非常欢迎大家积极讨论相关话题。
另外阿里云 Flink 团队也一直在寻求大数据计算和数据湖存储方向的人才,这里既有丰富的应用场景等你来挑战,又有相对灵活的空间参与开源社区提升个人影响力。感兴趣的同学可以直接联系:[email protected]。
参考链接:
[1]https://lists.apache.org/x/thread.html/rfa2be6bb85c0cae38ccedcf5c2d8fbfe192bdfccd58ee500e44e665e@%3Cdev.iceberg.apache.org%3E
[2]https://aws.amazon.com/cn/s3/
[3]https://aws.amazon.com/cn/glue/
[4]https://projectnessie.org/
[5]https://www.youtube.com/watch?v=rtz3p_iijP8&ab_channel=NetflixData
[6]https://docs.google.com/document/d/1q6xaBxUPFwYsW9aXWxYUh7die6O7rDeAPFQcTAMQ0GM/edit?ts=601316b0
[7]https://github.com/apache/iceberg/blob/master/site/docs/flink.md#preparation
[8]https://github.com/apache/iceberg/blob/master/site/docs/flink.md#rewrite-files-action
作者简介:
胡争(子毅),Apache Iceberg Committer,Apache HBase PMC 成员,阿里巴巴技术专家。目前主要负责 Flink 数据湖方案的设计和开发工作,Apache Iceberg 及 Apache Flink 项目的长期活跃贡献者,《HBase 原理与实践》作者。
▼ 关注「Flink 中文社区」,获取更多技术干货 ▼
