Spring cloud分布式链路跟踪:Sleuth Zipkin
背景
随着互联网的成长,需要支持大量的并发连接,并且需要将功能和服务有机结合,导致更加复杂的软件栈组合。更确切地说,多层架构( SOA或者微服务架构)变得更加普遍。
- 那么问题来了:出了问题怎么排查?

解决方案-分布式链路追踪系统
-
提供链路追踪,故障快速定位:可以通过调用链结合业务日志快速定位错误信息。
-
可视化: 各个阶段耗时,进行性能分析。
-
依赖优化:各个调用环节的可用性、梳理服务依赖关系以及优化。
三大组件
分布式链路追踪系统 三大组件
-
跟踪组件 – 负责收集性能数据
-
收集与存储组件 – 负责将跟踪组件的数据
-
展示组件 – 将跟踪数据展示出来
跟踪组件
-
要解决的问题
-
最初的调用方是谁?
-
请求在每个结点执行了多久,这个结点的调用方是谁?
-
怎么把这些统计信息联系起来?
理论
Google 的论文 : Dapper
-
分布式系统跟踪工具的设计空间已经被一些优秀文章探索过了,其中的Pinpoint[9]、Magpie[3]和X-Trace[12]和Dapper最为相近。这些系统在其发展过程的早期倾向于写入研究报告中,即便他们还没来得及清楚地评估系统当中一些设计的重要性。
-
虽然Dapper在许多高阶的设计思想上吸取了Pinpoint和Magpie的研究成果,但在分布式跟踪这个领域中,Dapper的实现包含了许多新的贡献

- Trace Tree : 一次跟踪
- 树节点是Span,包括:
- Span ID
- 开始时间和结束时间
- RPC时间数据
- 应用自定义标识数据annotations
- 树节点之间的边是Span 和它的父节点之间的关系
- 没有父节点的Span是根Span (root span)
- 所有树节点都有共同的一个Trace ID 标识这次跟踪
调用链实现步骤:
- 当一个线程处理一条跟踪的路径时Dapper把Trace context (Trace信息,包括Trace ID和- Span ID)放到ThreadLocal里面
- 如果计算要放到线程池里面进行,Dapper会注册一个callback,callback存储调用者的Trace context来达到继续跟踪的目的
- 对所有的RPC请求都加上Trace context
是不是有点复杂?
做个类比就一目了然了。 将这些东西和一棵树的元素对比下
TraceId-- RootId(根节点)
SpanId – NodeId (子节点)
Parent SpanId – parent NodeId (父节点描述信息)
其实本质就是为了生成一棵调用树。
追踪实现的方式有哪些?
-
硬编码? Long time = end-start ; ?
-
Spring aop ?
大致分为两种
interceptor
借助于组件自带的interceptor 功能。 就像 spring mvc 的 interceptor 一样
比如 httpclient ,mysql 驱动自带的拦截器功能。在开始之前记录时间,在执行完之后记录结束时间。
使用 agent 技术,比如Java agent
使用 java的 Instrumentation,开发者可以构建一个独立于应用程序的代理程序(Agent),用来监测和协助运行在 JVM 上的程序,甚至能够替换和修改某些类的定义。
有了这样的功能,开发者就可以实现更为灵活的运行时虚拟机监控和 Java 类操作了,这样的特性实际上提供了一种虚拟机级别支持的 AOP 实现方式,使得开发者无需对现有代码或者 JDK 做任何升级和改动,就可以实现某些 AOP 的功能了
在JDK5开始,在启动JVM时可增加-javaagent参数,在装载Class时对类进行动态的修改。

Java agent 在链路追踪上的应用
以httpClient为例:
java agent在jvm把相关类的字节流加载到内存之后,修改这些方法的具体实现(通常是在请求发送之前,开启一个spanEvent,记录发出请求的时间,在发送请求的时候,额外传入参数,向服务方发送transactionId 和 自己的spanId(通常是包含在http header 中)。 在请求结束的时候,记录结束的时间,算出耗时)
完整的链路追踪,需要调用端和服务端同时支持
以刚才讲的httpclient为例,服务端在接收到请求的时候,要检查是不是特殊的被追踪的请求(检查http header)。
如果是一个已经开始了的追踪请求,就以传入的traceId为准。否则就自己新起一个追踪。(类似于spring 事务传播机制中的required)
Sleuth简介
Sleuth是Spring Cloud的组件之一,它为Spring Cloud实现了一种分布式追踪解决方案,兼容Zipkin,HTrace和其他基于日志的追踪系统,例如 ELK(Elasticsearch 、Logstash、 Kibana)。
Sleuth相关术语
Sleuth引入了许多 Dapper中的术语:
-
Span 基本的工作单元。无论是发送一个RPC或是向RPC发送一个响应都是一个Span。每一个Span通过一个64位ID来进行唯一标识,并通过另一个64位ID对Span所在的Trace进行唯一标识。
Span能够启动和停止,他们不断地追踪自身的时间信息,当你创建了一个Span,你必须在未来的某个时刻停止它。
提示:启动一个Trace的初始化Span被叫作 Root Span ,它的 Span ID 和 Trace Id 相同。 -
Trace 由一系列Span 组成的一个树状结构。例如,如果你要执行一个分布式大数据的存储操作,这个Trace也许会由你的PUT请求来形成。
-
Annotation:用来及时记录一个事件的存在。通过引入 Brave 库,我们不用再去设置一系列的特别事件,从而让 Zipkin 能够知道客户端和服务器是谁、请求是从哪里开始的、又到哪里结束。出于学习的目的,还是把这些事件在这里列举一下:
-
cs (Client Sent) - 客户端发起一个请求,这个注释指示了一个Span的开始。
-
sr (Server Received) - 服务端接收请求并开始处理它,如果用 sr 时间戳减去 cs 时间戳便能看出有多少网络延迟。
-
ss(Server Sent)- 注释请求处理完成(响应已发送给客户端),如果用 ss 时间戳减去sr 时间戳便可得出服务端处理请求耗费的时间。
-
cr(Client Received)- 预示了一个 Span的结束,客户端成功地接收到了服务端的响应,如果用 cr 时间戳减去 cs 时间戳便可得出客户端从服务端获得响应所需耗费的整个时间。
下图展示了一个系统中的 Span 和 Trace 大概的样子:

使用Sleuth
为了确保你的应用名称能够在Zipkin中正确显示,你需要先在Springboot的核心配置文件中对spring.application.name 属性进行配置。
引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>
dependencies>
sleuth与zipkin通信默认为HTTP, 指定Zipkin服务地址
spring.zipkin.base-url=http://192.168.1.20:9411
如果你想使用RabbitMQ 或者Kafka 替代 HTTP ,需先引入 spring-rabbit 或者 spring-kafka 依赖。默认的目标名称是 zipkin 。如果你使用的是Kafka ,必须设置相应的 spring.zipkin.sender.type 属性:
spring.zipkin.sender.type: kafka
抽样率, 1为百分之百
spring.sleuth.sampler.pbrobability=1
安装Zipkin
zipkin提供数据存储,可视化页面等功能。
- 使用docker安装
docker run -d -p 9411:9411 openzipkin/zipkin
-
访问地址:http://host:9411

-
请求业务接口,并查看跟踪记录
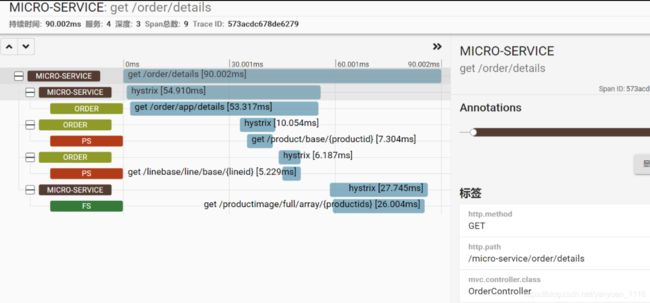
Sleuth源码参考
- TraceWebMvcConfigurer
class TraceWebMvcConfigurer implements WebMvcConfigurer {
@Autowired
ApplicationContext applicationContext;
TraceWebMvcConfigurer() {
}
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor((HandlerInterceptor)this.applicationContext.getBean(SpanCustomizingAsyncHandlerInterceptor.class));
}
}
- SpanCustomizingAsyncHandlerInterceptor
public final class SpanCustomizingAsyncHandlerInterceptor extends HandlerInterceptorAdapter {
@Autowired(required = false)
HandlerParser handlerParser = new HandlerParser();
SpanCustomizingAsyncHandlerInterceptor() {
// hide the ctor so we can change later if needed
}
@Override
//执行请求前处理跟踪数据
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object o) {
SpanCustomizer span = (SpanCustomizer) request.getAttribute(SpanCustomizer.class.getName());
if (span != null) handlerParser.preHandle(request, o, span);
return true;
}
// Set the route attribute on completion to avoid any thread visibility issues reading it
@Override
//完成请求后处理跟踪数据
public void afterCompletion(
HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
SpanCustomizer span = (SpanCustomizer) request.getAttribute(SpanCustomizer.class.getName());
if (span != null) setHttpRouteAttribute(request);
}
}