Python地理数据处理 六:使用OGR过滤数据
目录
-
- 写在前面
- 1. 属性过滤条件
- 2. 空间过滤条件
- 3. 使用SQL创建临时图层
- 4. 利用过滤条件
写在前面
过滤条件可以将不想要的要素抛弃,通过过滤条件可以选出符合特定条件的要素,也可以通过空间范围限定要素,这样就可以简单地处理感兴趣的数据。
1. 属性过滤条件
过滤条件需要一个条件语句,类似于SQL语句中的Where子句。如:
‘Population < 50000’
‘Population = 50000’
‘Name = “Tokyo”’
注:比较字符串时,需要用引号将字符串包住,并且保证它们与包住整个查询字符串的引号不同。否则,将会导致语法错误。
测试某个对象不等于另一个值,可以使用!=或<>,也可以使用AND或者OR语句:
'(Population > 25000) AND (Population < 50000)'
'(Population > 50000) OR (Place_type = "County Seat")'
语句1:选出人口大于25000,但少于50000的要素;
语句2:选出人口超过50000,或者Place_type 为 County Seat 的要素(或同时满足)。
使用NOT来否定条件,NULL用于指示一个空值或属性表中没有数据值:
'(Population < 50000) OR NOT (Place_type = "County Seat")'
'County NOT NULL'
语句1:选出人口小于50000,或Place_type 不是 County Seat 的要素(或同时满足);
语句2:选出County 不为空的要素。
检查某个值是否在另外两个值之间,用 BETWEEN :
'Population BETWEEN 25000 AND 50000'
'(Population > 25000) AND (Population < 50000)'
语句1:选出人口在25000和50000之间的要素;
语句2:也是选出人口在25000和50000之间的要素。
检验某个值是否与其他多个不同值相同:
'Type_code IN (4, 3, 7)'
'(Type_code = 4) OR (Type_code = 3) OR (Type_code = 7)'
也适用于字符串:
'Place_type IN ("Populated Place", "County Seat")'
下划线匹配任何单个字符,百分号匹配任意数量的字符,使用LIKE进行字符串匹配(不区分大小写):
'Name LIKE "%Seattle%"'
使用LIKE操作符的匹配实例:
| 方式 | 匹配 | 不匹配 |
|---|---|---|
| _eattle | Seattle | Seattle WA |
| Seattle% | Seattle, Seattle WA | North Seattle |
| %Seattle% | Seattle, Seattle WA, North Seattle | Tacoma |
| Sea%le | Seattle | Seattle WA |
| Sea_le | Seatle (note misspelling) | Seattle |
使用Python交互式窗口测试,需要加载VectorPlotter类来交互式地绘制选择的结果:
>>> import os
>>> import sys
>>> from osgeo import ogr
>>> import ospybook as pb
>>> import matplotlib.pyplot as plt
>>> from ospybook.vectorplotter import VectorPlotter
>>> data_dir = r'E:\Google chrome\Download'
>>> vp = VectorPlotter(True)
>>> ds = ogr.Open(os.path.join(data_dir, 'global'))
>>> lyr = ds.GetLayer('ne_50m_admin_0_countries')# Get the countries shapefile layer
>>> vp.plot(lyr, fill=False) # fill=False表示只绘制出国家边界
>>> vp.plot(lyr, fill=False)
>>> pb.print_attributes(lyr, 4, ['name'], geom=False) # 查看图层属性
FID name
0 Aruba
1 Afghanistan
2 Angola
3 Anguilla
4 of 241 features
查看亚洲包含的要素:
SetAttributeFilter() 函数
import os
import sys
from osgeo import ogr
import ospybook as pb
from ospybook.vectorplotter import VectorPlotter
data_dir = r'E:\Google chrome\Download'
ds = ogr.Open(os.path.join(data_dir, 'global'))
lyr = ds.GetLayer('ne_50m_admin_0_countries')
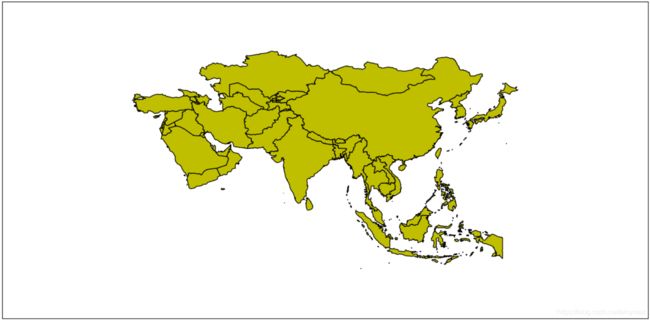
asia=lyr.SetAttributeFilter("continent = 'Asia'")
print(asia) # asia 为0时,表示查询语句被执行成功
count_asia=lyr.GetFeatureCount()
print(count_asia)# 亚洲总共有多少个记录
vp = VectorPlotter(True)
vp.plot(lyr, 'y')
vp.draw()
0
53
绘制结果:
查看属性过滤器效果:
>>> pb.print_attributes(lyr, 4, ['name'], geom=False)
FID name
1 Afghanistan
7 United Arab Emirates
9 Armenia
17 Azerbaijan
4 of 53 features
>>> lyr.GetFeature(2).GetField('name') # FID并没有改变
'Angola'
当设置另一个属性过滤条件,它不是创建当前过滤图层要素的子集,而是将过滤条件应用于整个图层:
lyr.SetAttributeFilter('continent = "South America"')
vp.plot(lyr, 'b')
5
241
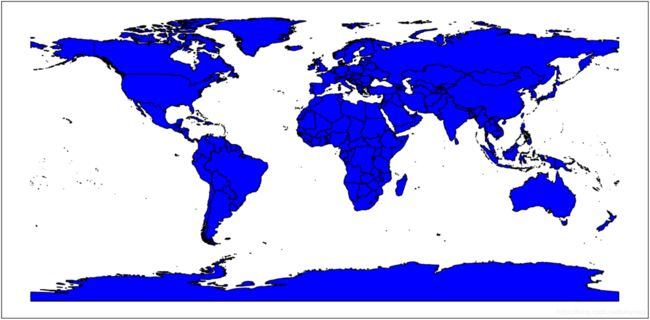
可以同时使用空间和属性过滤条件优化结果,后面会提到。
清除属性过滤条件来获取所有要素:
>>> lyr.SetAttributeFilter(None)
0
>>> lyr.GetFeatureCount()
241
2. 空间过滤条件
空间过滤条件可以使用空间范围,而不是属性值来筛选要素,可以用来选择位于另一个要素内或边界框内部的要素。
使用天然地球shapefile文件来选择出中国城市。首先,打开数据源文件,使用属性过滤条件筛选中国,并获得对应的要素记录和几何对象:
>>> from osgeo import ogr
>>> from ospybook.vectorplotter import VectorPlotter
>>> import ospybook as pb
>>> ds=ogr.Open(r"E:\Google chrome\Download\global")
>>> country_lyr = ds.GetLayer('ne_50m_admin_0_countries')
>>> vp = VectorPlotter(True)
>>> vp.plot(country_lyr, fill=False)
>>> country_lyr.SetAttributeFilter('name = "China"')
5
>>> feat = country_lyr.GetNextFeature()
>>> China = feat.geometry().Clone()
打开居住区图层,将所有城市数据表示为红点:
>>> city_lyr = ds.GetLayer('ne_50m_populated_places')
>>> city_lyr.GetFeatureCount()
1249
>>> vp.plot(city_lyr, 'r.')

# 选取中国城市
# 打开数据源文件夹获取国家边界图层,然后使用属性过滤条件筛选出中国,并获得对应的要素记录和几何对象
# 使用中国边界,根据空间过滤条件,筛选出居住区图层中的中国城市。
from osgeo import ogr
from ospybook.vectorplotter import VectorPlotter
import ospybook as pb
# 打开图层
ds=ogr.Open(r"E:\Google chrome\Download\global")
lyr=ds.GetLayer('ne_50m_admin_0_countries')
vp=VectorPlotter(True)
vp.plot(lyr,fill=False)
# 根据属性过滤条件筛选出中国
""" 属性过滤条件筛选后会返回一个要素,lyr.GetNextFeature()获得这个要素
Clone() 克隆这个要素,这样即使要素在内存中被删除后,仍然可以使用"""
country = lyr.SetAttributeFilter("name = 'China'")
feat = lyr.GetNextFeature()
China = feat.geometry().Clone()
# 加载城市图层,并绘制
city_lyr=ds.GetLayer('ne_50m_populated_places')
vp.plot(city_lyr,'r.')
# 根据空间过滤条件,筛选出中国的城市
country_filter=city_lyr.SetSpatialFilter(China)
country_count=city_lyr.GetFeatureCount()
print(country_count)
vp.plot(city_lyr,'bo')
vp.draw()
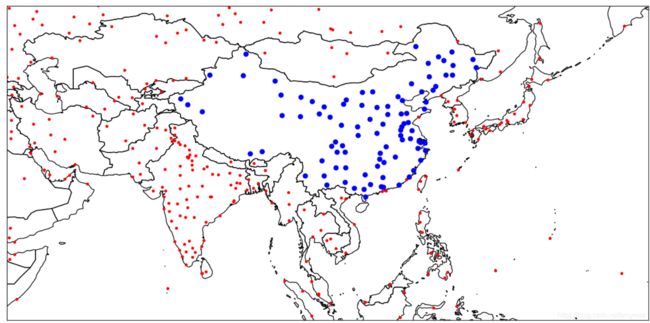
使用空间过滤条件和属性查询函数组合来优化选择,找出人口在100万以上的城市,并用正方形表示:
# 找出中国人口超过100万的城市
country_100 = city_lyr.SetAttributeFilter('pop_min > 1000000')
country_100_count = city_lyr.GetFeatureCount()
vp.plot(city_lyr, 'rs')
vp.draw()
一共有95个城市人口数超过100万人口:
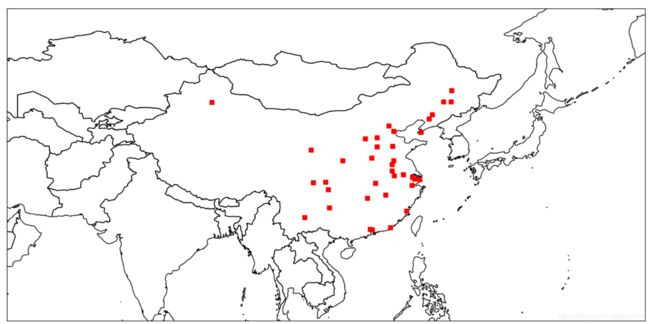
查看世界上有多少个城市人口数大于100万:
city_lyr.SetSpatialFilter(None)
city_lyr.GetFeatureCount()
vp.plot(city_lyr, 'm^', markersize=8)
vp.draw()
# 246
绘制结果:

SetSpatialFilterRect(minx, miny, maxx, maxy): 创建矩形进行空间过滤。
country_lyr.SetSpatialFilterRect(110, -50, 160, 0)
vp.plot(country_lyr, 'y')
vp.draw()
绘制结果:
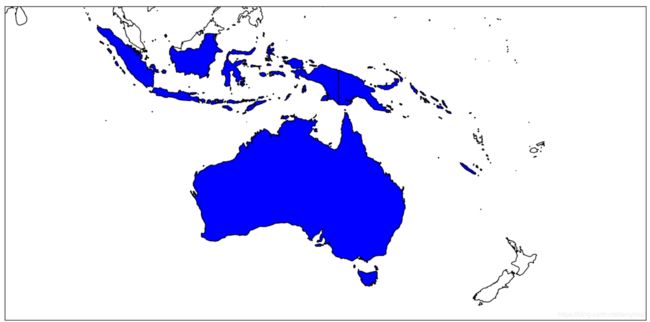
绘制澳大利亚的最大矩形可以作为全球国界图层的一个空间过滤条件。
3. 使用SQL创建临时图层
主要使用EcecuteSQL函数对数据源进行更复杂的查询,作用与数据源,而不是图层,可以操作多个图层。空间过滤条件可以作为可选项。
EcecuteSQL(statement,[spatialFilter],[dialect])
- statement:要使用的SQL语句
- spatialFilter:可选项,针对结果做空间过滤,默认没有过滤
- dialect用于说明SQL语句用什么标准的字符串,可用选项为:OGRSQL和SQLite。默认使用SQL标准。
1. 按照人口数降序排列返回结果:
ds = ogr.Open(os.path.join(data_dir, 'global'))
sql = '''SELECT ogr_geom_area as area, name, pop_est
FROM 'ne_50m_admin_0_countries' ORDER BY POP_EST DESC'''
lyr = ds.ExecuteSQL(sql)
pb.print_attributes(lyr, 3) # 此处输出报错
未能解决的问题:

init文件显示:
def print_attributes(lyr_or_fn, n=None, fields=None, geom=True, reset=True):
"""Print attribute values in a layer.
lyr_or_fn - OGR layer object or filename to datasource (will use 1st layer)
n - optional number of features to print; default is all
fields - optional list of case-sensitive field names to print; default
is all
geom - optional boolean flag denoting whether geometry type is printed;
default is True
reset - optional boolean flag denoting whether the layer should be reset
- to the first record before printing; default is True
"""
lyr, ds = _get_layer(lyr_or_fn)
if reset:
lyr.ResetReading()
n = n or lyr.GetFeatureCount()
geom = geom and lyr.GetGeomType() != ogr.wkbNone
fields = fields or [field.name for field in lyr.schema]
data = [['FID'] + fields]
if geom:
data[0].insert(1, 'Geometry')
feat = lyr.GetNextFeature()
while feat and len(data) <= n:
data.append(_get_atts(feat, fields, geom))
feat = lyr.GetNextFeature()
lens = map(lambda i: max(map(lambda j: len(str(j)), i)), zip(*data))
format_str = ''.join(map(lambda x: '{
{:<{}}}'.format(x + 4), lens))
for row in data:
try:
print(format_str.format(*row))
except UnicodeEncodeError:
e = sys.stdout.encoding
print(codecs.decode(format_str.format(*row).encode(e, 'replace'), e))
print('{0} of {1} features'.format(min(n, lyr.GetFeatureCount()), lyr.GetFeatureCount()))
if reset:
lyr.ResetReading()
shapefile文件没有任何内置的SQL引擎,若要查询的数据源自身具有SQL引擎支持,则会使用原生的SQL版本。
2. 使用SQLite版本的SQL标准从数据库中获取信息:
ds = ogr.Open(os.path.join(data_dir, 'global',
'natural_earth_50m.sqlite'))
sql = '''SELECT geometry, area(geometry) AS area, name, pop_est
FROM countries ORDER BY pop_est DESC LIMIT 3'''
lyr = ds.ExecuteSQL(sql)
pb.print_attributes(lyr)

3. 使用函数连接多个图层的属性:
# ne_50m_populated_places pp:图层重命名
# ON pp.adm0_a3 = c.adm0_a3 基于公共字段连接两表
ds = ogr.Open(os.path.join(data_dir, 'global'))
sql = '''SELECT pp.name AS city, pp.pop_min AS city_pop,
c.name AS country, c.pop_est AS country_pop
FROM ne_50m_populated_places pp
LEFT JOIN ne_50m_admin_0_countries c
ON pp.adm0_a3 = c.adm0_a3
WHERE pp.adm0cap = 1'''
lyr = ds.ExecuteSQL(sql)
pb.print_attributes(lyr, 3, geom=False)

4. 查看多个图层相关数据(城市人口和全国人口):
ds = ogr.Open(os.path.join(data_dir, 'global'))
sql = '''SELECT pp.name AS city, pp.pop_min AS city_pop,
c.name AS country, c.pop_est AS country_pop
FROM ne_50m_populated_places pp
LEFT JOIN ne_50m_admin_0_countries c
ON pp.adm0_a3 = c.adm0_a3
WHERE pp.adm0cap = 1 AND c.continent = "Asia"'''
lyr = ds.ExecuteSQL(sql)
pb.print_attributes(lyr, 3)

5. 使用SQLite标准查看shapefile数据源(SQLite标准也适用于其他数据源):
lyr = ds.ExecuteSQL(sql, dialect='SQLite')
6. 合并几何对象:
# Plot the counties in California.
ds = ogr.Open(os.path.join(data_dir, 'US'))
sql = 'SELECT * FROM countyp010 WHERE state = "CA"'
lyr = ds.ExecuteSQL(sql)
vp = VectorPlotter(True)
vp.plot(lyr, fill=False)
sql = 'SELECT st_union(geometry) FROM countyp010 WHERE state = "CA"'
lyr = ds.ExecuteSQL(sql, dialect='SQLite')
vp.plot(lyr, 'w')
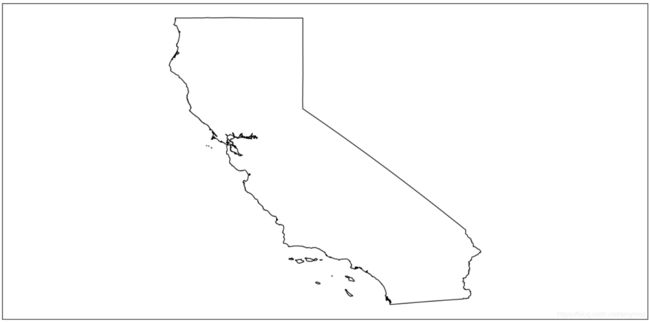
4. 利用过滤条件
1. 创建所需要的数据:
ds = ogr.Open(os.path.join(data_dir, 'global'), 1)
in_lyr = ds.GetLayer('ne_50m_populated_places')
in_lyr.SetAttributeFilter("FEATURECLA = 'Admin-0 capital'")
out_lyr = ds.CopyLayer(in_lyr, 'capital_cities2')
out_lyr.SyncToDisk()
2. 只选择需要的要素:
sql = """SELECT NAME, ADM0NAME FROM ne_50m_populated_places
WHERE FEATURECLA = 'Admin-0 capital'"""
in_lyr2 = ds.ExecuteSQL(sql)
out_lyr2 = ds.CopyLayer(in_lyr2, 'capital_cities3')
out_lyr2.SyncToDisk()