算法小课堂——最小生成树Kruskal
算法小课堂——最小生成树Kruskal
- 前言
- 算法原理
- 代码实现
- 算法实操
-
- UVA1395——苗条的生成树
-
- 题目
- 分析
- 代码实现
- 样例测试
- UVa1151——买还是建
-
- 题目
- 分析
- 代码实现
- 样例测试
- 结语
前言
hello,大家好吖,上周我们讲解了 Floyd算法,不知大家还有没有印象嘞~,今天我们来讲解一下最小生成树,简单又实用的策略优化算法
算法原理
最小生成树(Kruskal 算法)适用于求解连通所有节点所需花费最小的问题。最形象的例子就是: 有n个村子,每个村子与其他村子修筑连通的道路需要花费一定金额,怎么样在保证所有村子连通的情况下使花费最少呢?
最小生成树本质是贪心,从耗费最少的边开始,不断加入集合,直到所有节点都连通。
首先,我们将所有的边按照权重(消耗值)进行从小到大排序,这里我们需要一个集合来存储最后选出的满足条件的边。然后遍历排序后的边,如果起点终点不在一个集合,则将终点加入起点的集合中,如果已经在一个集合里,说明前面用更少的消耗(之前从小到大排列的作用)达到了相同的效果,则不采用这条边。
可以发现,这个算法过程主要是连通分量的查询和合并。需要知道任意两个节点是不是在同一个连通分量中,根据需要还要合并两个连通分量。这里说的连通分量可以认为是边的集合,不唯一。

存储连通分量我们可以想到链表或者邻接矩阵,查询连通我们可以使用DFS或者BFS,但是是对于图结构而言,而且这种思路会比较复杂点,查询上效率不高。 坦白说就是费劲
这里一般教科书推荐是并查集(Union-Find Set),可以把每个连通分量看成一个集合,该集合包含了在这个连通分量的所有节点。而我们不需要去考虑连通的方式,比如顺序或者连通的形式,只需要考虑它是不是我的崽。查询的过程简单了,合并的过程利用集合的基本操作就可以完成,整个过程就可以比较简洁。
下面我们用例子来演示一下:
比如我们通过查询边已经得到三个不同的连通分量如下:
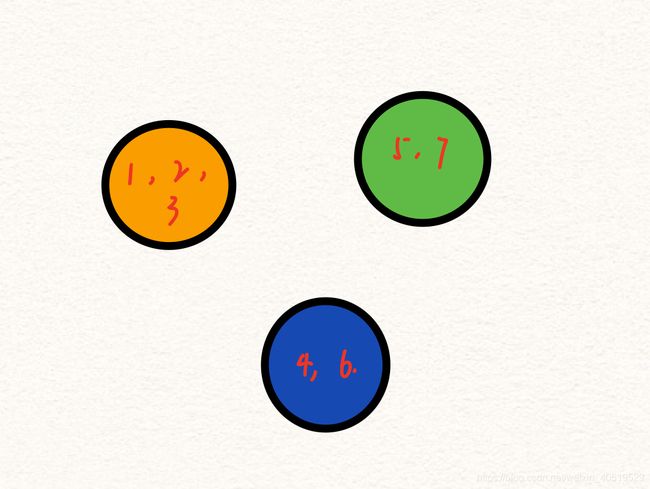
然后如果橙子集合中的任意一个节点有连接蓝色集合里的任意一个节点的边(查询是不是同一个连通分量),且为当前下一步的最优,则接下来的连通分量会进行合并:

算法的终止条件可以是遍历完所有的边,也可以是当连通分量有n-1个时(n个节点的图其无环连通边的个数为n-1)。既然要耗费最少,那自然是没有多余的边。
代码实现
首先我们需要实现并查集的类及相应的方法。
class Union_find_set:
"""
the implementation of union_find_set
"""
def __init__(self, identity, subset):
# identity: 标号,即所属连通分量的标签
# subset: 当前集合的数据
self.identity = identity
self.set = set()
if isinstance(subset, set):
self.set = subset
elif isinstance(subset, list) or isinstance(subset, tuple):
for item in subset:
self.set.add(item)
else:
raise ValueError("Subset should be list or set or tuple type")
# 获取当前连通分量的标签
def get_id(self):
return self.identity
# 设置当前连通分量的标签
def set_id(self, value):
self.identity = value
return
# 获取当前连通分量的节点数据
def get_set(self):
return (i for i in self.set)
# 设置当前连通分量的节点数据
def set_set(self, s):
self.set = s
return
# 返回当前连通分量与其他连通分量的并集
def union(self, other):
return self.set.union(other.set)
然后我们来看看Kruskal算法的实现(以开头作为解释的问题为例:有n个村子m条待修的路,每条路连通两个村子,且耗费一定金额。求使所有村子互通的最少金额)
def Mini_spanning_tree():
"""
implement Mini_spanning_tree using Union-Find set
"""
# 数据读入
n, k = list(map(int, input().split()))
data = []
for i in range(k):
data.append(list(map(int, input().split())))
data = sorted(data, key=lambda x: x[2])
# 总耗费
tot = 0
# 选出的边集合
path = []
s = dict()
# 初始化: 节点各自为营
for i in range(n+1):
s[i] = Union_find_set(i, [i])
# 遍历
for d in data:
u, v, w = d
# 编号不同且路径小于n-1,连通情况下路径数量等于节点数-1
if s[u].get_id() != s[v].get_id() and len(path) < n - 1:
# 修改节点v所在连通分量里所有节点的标签号
for i in s[v].get_set():
s[i].set_id(s[u].get_id())
# 获取节点u和节点v各自所在的连通分量的并集
temp = s[u].union(s[v])
# 将并集里的所有节点的连通分量设置成该并集,即每个节点的并查集类都存储有其所属连通分量的所有数据信息
for t in temp:
s[t].set_set(temp)
tot += w
path.append(d)
print("Total comsuption: {}".format(tot))
# print("The path is belowing:")
# print(*path)
return
测试一下例子:
>>> Mini_spanning_tree()
6 9
1 2 4
1 3 -1
2 3 3
2 4 5
4 5 10
2 6 10
3 6 10
4 6 1
5 6 1
Total comsuption: 9
The path is belowing:
[1, 3, -1] [4, 6, 1] [5, 6, 1] [2, 3, 3] [2, 4, 5]
算法实操
UVA1395——苗条的生成树
题目
给出一个n(n≤100)节点的图,求苗条度(最大边减最小边的值)尽量小的生成树。
分析
根据 《算法竞赛入门》 第2版的内容,这个题目是想要得出一个最值,那程序自然是循环判断。消耗最少的最小生成树不一定是最苗条的,我们还是先按边权值从小到大排序。
对于一个边的区间 [L,R](L+n-1 ≤ R ≤ k),如果这些边使得所有节点全部连通,那么一定存在苗条度不大于 w[R] - w[L] 的生成树。如果从L起连续n-1条边就可以使节点全部连通,那么其苗条度最小。如果不行,增大R,把新加入的边与之前生成的连通集合一起做 Kruskal,直到所有节点连通。更新L,继续枚举R。
代码实现
def UVA_1395():
# 数据读入,单次测试
n, k = list(map(int, input().split()))
data = []
for i in range(k):
data.append(list(map(int, input().split())))
data = sorted(data, key=lambda x: x[2])
# 最小耗费,初始化为最大消耗的边
min_tot = data[-1][2]
# 最小生成树函数,给定数据范围和并查集,返回连通的路径节点list
def Kruskal(sub_data, s, path):
# sub_data: 用来更新的数据
# s: 并查集
# path: 连通的路径节点list
nonlocal n
for d in sub_data:
u, v, w = d
# 编号不同且路径小于n-1,连通情况下路径数量等于节点数-1
if s[u].get_id() != s[v].get_id() and len(path) < n - 1:
# 修改节点v所在连通分量里所有节点的标签号
for i in s[v].get_set():
s[i].set_id(s[u].get_id())
# 获取节点u和节点v各自所在的连通分量的并集
temp = s[u].union(s[v])
# 将并集里的所有节点的连通分量设置成该并集,即每个节点都存储有其所属连通分量的所有数据信息
for t in temp:
s[t].set_set(temp)
path.append(d)
return path
# 特殊测试例子:只有一条路,两个节点
if n == 2 and k == 1:
print(0)
return
# 不满足连通条件要求的边数量
elif k < n-1:
print(-1)
return
# 有最小生成树方案标志
flag = False
# 根据连通的边数量限制,起点遍历范围为[0, k-(n-1)-1]
for s in range(k - (n - 1)):
# 每次枚举L要重新生成并查集
uf_set.clear()
for i in range(k):
uf_set[i] = Union_find_set(i, [i])
# 如果从L到L+n-1的边可以连通,那就是该情况的“最苗条”解
path = Kruskal(data[s:s + n], uf_set, [])
# print(path)
if len(path) == n - 1:
min_tot = min(min_tot, path[-1][2] - path[0][2])
flag = True
continue
# 如果不可以连通,则枚举R
else:
for v in range(s + n, k):
# 记得把第一次Kruskal生成的path传入
path = Kruskal(data[s:v + 1], uf_set, path)
# print(s, v, path)
if len(path) == n - 1:
min_tot = min(min_tot, path[-1][2] - path[0][2])
flag = True
break
else:
continue
if flag:
print(min_tot)
else:
print(-1)
return
样例测试
>>> UVA_1395()
5 8
1 2 1
2 3 100
3 4 100
4 5 100
1 5 50
2 5 50
3 5 50
4 1 150
[output]
50
>>> UVA_1395()
5 10
1 2 110
1 3 120
1 4 130
1 5 120
2 3 110
2 4 120
2 5 130
3 4 120
3 5 110
4 5 120
[output]
0
>>> UVA_1395()
5 10
1 2 9384
1 3 887
1 4 2778
1 5 6916
2 3 7794
2 4 8336
2 5 5387
3 4 493
3 5 6650
4 5 1422
[output]
1686

UVa1151——买还是建
题目
平面上有n个点,为了让n个点连通,你可以新建一些边,建造边的费用等于两个端点坐标距离的平方。另外还提供q个套餐可供购买,购买了第i个套餐,则该套餐中所有的节点变得相互连通。求出能够使所有节点连通且花费最少的方案,给出其花费。
分析
根据 《算法竞赛入门》 第2版的内容,由于买了套餐相当于添加了一些权重为0的边,我们可以去枚举购买套餐的方案,然后去分别进行Kruskal,得出最优解。但是这样做的复杂度规模太大了,枚举需要 2 q 2^q 2q, 排序需要 O ( n 2 l o g n ) O(n^2 logn) O(n2logn),排序之后Kruskal算法的时间复杂度为 n 2 n^2 n2, 因此总的时间复杂度为 O ( 2 q ( n 2 + n 2 l o g n ) ) O(2^q (n^2+n^2logn)) O(2q(n2+n2logn))。
这里我们需要先求一次原始图的最小生成树,再结合套餐的枚举去求新的最小生成树。结合Kruskal,即最小生成树的特性,排序较后或者两端已经是在同一个连通分量里的边不会去考虑。而题目里的套餐其实是增加了权重为0的边,即在原本的边排序的最前面插入一些边。那么在考虑到原始图构成的最小生成树的情况下,我们只是加入了一些权重为0的边,肯定也可以使所有节点连通,因为本来就可以连通了嘛,我们都求了一次Kruskal了。
所以,原来被原始图的Kruskal所抛弃的边,再后续结合套餐的Kruskal中依旧会被抛弃,就会大大减少需要check的边数量,复杂度就会降下来。
代码实现
def UVa1151():
# 读入数据
n, k = list(map(int, input().split()))
sub_net = []
for i in range(k):
sub_net.append(list(map(int, input().split())))
# 注意题目给的序号是从1开始的,一个小坑
for j in range(sub_net[i][0]):
sub_net[i][2 + j] -= 1
# 存储坐标
city = []
for i in range(n):
city.append(list(map(int, input().split())))
# 原题的意思应该是距离的平方!
Get_dis = lambda x, y: (
(city[x][0] - city[y][0]) ** 2 + (city[x][1] - city[y][1]) ** 2)
# 存储边
edges = []
for i in range(n):
for j in range(i + 1, n):
edges.append([i, j, Get_dis(i, j)])
# 排序
edges = sorted(edges, key=lambda x: x[2])
# Kruskal算法
def Kruskal(sub_data, s, path):
# sub_data: 用来更新的数据
# s: 并查集
# path: 连通的路径节点list
nonlocal n
for d in sub_data:
u, v, w = d
# 编号不同且路径小于n-1,连通情况下路径数量等于节点数-1
if s[u].get_id() != s[v].get_id() and len(path) < n - 1:
# 修改节点v所在连通分量里所有节点的标签号
for i in s[v].get_set():
s[i].set_id(s[u].get_id())
# 获取节点u和节点v各自所在的连通分量的并集
temp = s[u].union(s[v])
# 将并集里的所有节点的连通分量设置成该并集,即每个节点都存储有其所属连通分量的所有数据信息
for t in temp:
s[t].set_set(temp)
path.append(d)
return path
# 初始化并查集
s = dict()
for i in range(len(edges)):
s[i] = Union_find_set(i, [i])
# 得到原始图的最小生成树
path = Kruskal(edges, s, [])
# 输出
ans_tot = sum([p[2] for p in path]) # 总耗费
ans_path = [] # 边
ans_plan = 0 # 方案枚举的二进制数
# 二进制枚举购买方案的种类
for i in range(1, 2**k, 1):
tot = 0
path_copy = path.copy()
for j in range(k):
# 二进制的每一位代表该方案是否购买
if (i >> j) & 1:
tot += sub_net[j][1]
for m in range(sub_net[j][0]-1):
path_copy.append([sub_net[j][m+2], sub_net[j][m+3], 0])
# 排序
path_copy = sorted(path_copy, key=lambda x: x[2])
# 初始化并查集
s.clear()
for idx in range(len(path_copy)):
s[idx] = Union_find_set(idx, [idx])
new_path = Kruskal(path_copy, s, [])
# 计算消耗
tot = sum([p[2] for p in new_path]) + tot
# 更新
if tot < ans_tot:
ans_tot = tot
ans_path = new_path
ans_plan = i
# 打印最佳方案
print("The Optimal Plan: ")
for i in range(k):
if (ans_plan >> i) & 1:
print("Buy sub_net {}".format(i+1))
for p in ans_path:
if p[2] != 0:
print("Build edge from node {} to node {}".format(p[0], p[1]))
print("Total money: {}".format(ans_tot))
return
样例测试
>>> UVa1151()
7 3
2 4 1 2
3 3 3 6 7
3 9 2 4 5
0 2
4 0
2 0
4 2
1 3
0 5
4 4
[output]
The Optimal Plan:
Buy sub_net 1
Buy sub_net 2
Build edge from node 0 to node 4
Build edge from node 1 to node 2
Build edge from node 1 to node 3
Total money: 17
结语
最小生成树是策略优化型算法,在算法题目中也比较常见,掌握起来也并不困难。
题目的代码实现都是小刀自己手敲,可能会出现bug,如有错误,还望指正。如果觉得这篇blog解答了你的疑惑或者让你有所收获,那就点个赞吧~

