Java线上故障解决方案

一、前言:
我们在⽣产环境中,程序代码、硬件、⽹络、协作软件等任⼀因素,都会引发意想不到的问题,所以排查产线问题⽐较困难,所以问题的定位体现了⼀名⼯程师的基础能⼒,问题的解决则体现了⼯程师的技能素养。
二、线上常见问题

如出现 (CPU占⽤率过⾼、磁盘使⽤率100%、系统可⽤内存低、服务间调⽤时间过⻓、多线程并发异常、死锁等)
三、定位问题
方案 :
- 业务⽇志分析排查
通常情况下,⼤部分错误信息都会在⽇志上有所体现
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(100000);
System.out.println("开始执行");
for (int i = 0; i < 100000000; i++) {
executorService.execute(() -> {
String payload = IntStream.rangeClosed(1, 1000000)
.mapToObj(__ -> "a") .collect(Collectors.joining("")) + UUID.randomUUID().toString();
System.out.println("等待一小时开始");
try {
TimeUnit.HOURS.sleep(1);
}catch (Exception e){
log.info(payload);
}
});
}
executorService.shutdown();
executorService.awaitTermination(1,TimeUnit.HOURS);
}

通过日志可以发现出错误的位置是 第33行,报错java.lang.OutOfMemoryError 错误, 因为我们看下 newFixedThreadPool 方法的源码,发现,线程池的工作队列直接 new 了一个 LinkedBlockingQueue,他是一个无界队列。如果任务较多并且执行较慢但话,队列可能会快速积压,撑爆内存导致OOM
我们 ⼀定要在关键代码逻辑位置输出相关⽇志,尤其是在代码发⽣异常的时候,定要将⽇志输出到⽂件中,只有这样,才更利于我们的排查。
- APM分析排查
APM,全称Application Performance Management,应⽤性能管理,⽬的是通过各种探针采集数据, 收集关键指标,同时搭配数据呈现以实现对应⽤程序性能管理和故障管理的系统化解决⽅案。通过分布 式链路调⽤跟踪系统,通过在系统请求中透传 trace-id,将所有相关⽇志进⾏聚合,然后⽇志统⼀采集 和分析后,以图形化的形式展示给⼯程师们,⽽他们在排查问题的时候,可以简单粗暴且直观的调度出 问题最根本的原因。
通常在分布式架构中,仅通过分析单个服务的⽇志信息是不够的,此时则需要APM进⾏全链路分析,通过请求链路监控,实时的发现链路中相关服务的异常情况。

⽬前市场上使⽤较多的链路跟踪⼯具有如下⼏个:
-
大众点评 CAT :GitHub - dianping/cat: Central Application Tracking
-
Apache Skywalking:https://skywalking.apache.org/
-
Pinpoint:https://pinpoint.com/product/for-engineers
-
SpringCloud Zipkin:https://docs.spring.io/spring-cloud-sleuth/docs/current-SNAPSHOT/referencre/html/#sending-spans-to-zipkin
- 物理环境排查
CPU分析
- CPU使⽤率是衡量系统繁忙程度的重要指标。但是CPU使⽤率的安全阈值是相对的,取决于你的系统的IO密集型还是计算密集型。⼀般计算密集型应⽤CPU使⽤率偏⾼load偏低,IO密集型相反。
[root@ ~]# top
top命令是Linux下常⽤的 CPU 性能分析⼯具,能够实时显示系统中各个进程的资源占⽤状况,常⽤于服务端性能分析。
top 命令显示了各个进程 CPU 使⽤情况,⼀般 CPU 使⽤率从⾼到低排序展示输出。其中 LoadAverage 显示最近1分钟、5分钟和15分钟的系统平均负载,上图各值为3.4、3.31、3.46。
我们⼀般会关注 CPU 使⽤率最⾼的进程,正常情况下就是我们的应⽤主进程。第七⾏以下:各进
程的状态监控,参数说明:
- PID : 进程id
- USER : 进程所有者的⽤户名
- PR : 进程优先级
- NI : nice值。负值表示⾼优先级,正值表示低优先级
- VIRT : 进程使⽤的虚拟内存总量,单位kb
- SHR : 共享内存⼤⼩
- %CPU : 上次更新到现在的CPU时间占⽤百分⽐
- %MEM : 进程使⽤的物理内存百分⽐
- TIME+ : 进程使⽤的CPU时间总计,单位1/100秒
- COMMAND : 命令名称、命令⾏
内存
[root@ ~]# free -h
内存是排查线上问题的重要参考依据,free 是显示的当前内存的使⽤,-h 表示⼈类可读性。

参数说明:
- total :内存总数
- used:已经使⽤的内存数
- free:空闲的内存数
- shared:被共享使⽤的物理内存⼤⼩
- buffers/buffer:被 buffer 和 cache 使⽤的物理内存⼤⼩
- available: 还可以被应⽤程序使⽤的物理内存⼤⼩
磁盘
[root@ ~]# df -h
⽹络
[root@ ~]# dstat
默认情况下,dstat每秒都会刷新数据
三、Arthas诊断命令

Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱。
- 当你遇到以下类似问题而束手无策时,Arthas可以帮助你解决:
- 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
- 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
- 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
- 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
- 是否有一个全局视角来查看系统的运行状况?
- 有什么办法可以监控到JVM的实时运行状态?
- 怎么快速定位应用的热点,生成火焰图?
官方文档 :https://arthas.aliyun.com/doc/
安装
[root ~]# mkdir arthas
[root ~]# cd arthas/
[root ~]# wget https://maven.aliyun.com/repository/public/com/taobao/arthas/arthas-packaging/3.1.4/arthas-packaging-3.1.4-bin.zip
[root ~]# rm -rf /home/admin/.arthas/lib/*
[root ~]# cd arthas
[root ~]# ./install-local.sh
[root ~]# java -jar arthas-boot.jar

arthas 会列出已存在的Java进程,并提醒输⼊序号,键⼊回⻋,进⼊arthas 诊断界⾯。
arthas常⻅命令介绍
- jvm 查看当前 JVM 的信息
- thread 查看当前 JVM 的线程堆栈信息,-b选项可以⼀键检测死锁
- trace ⽅法内部调⽤路径,并输出⽅法路径上的每个节点上耗时,服务间调⽤时间过⻓时使⽤
- stack 输出当前⽅法被调⽤的调⽤路径
- Jad 反编译指定已加载类的源码,反编译便于理解业务
- logger 查看和修改logger,可以动态更新⽇志级别。
四、JVM问题定位命令
在 JDK 安装⽬录的 bin ⽬录下默认提供了很多有价值的命令⾏⼯具。每个⼩⼯具体积基本都⽐较⼩,因
为这些⼯具只是 jdk\lib\tools.jar 的简单封装。
其中,定位排查问题时最为常⽤命令包括:jps(进程)、jmap(内存)、jstack(线程)、jinfo(参
数)等。
- jps:查询当前机器所有Java进程信息
- jmap:输出某个 Java 进程内存情况
- jstack:打印某个 Java 线程的线程栈信息
- jinfo:⽤于查看 jvm
1. jps
jps ⽤于输出当前⽤户启动的所有进程 ID,当线上发现故障或者问题时,利⽤ jps 快速定位对应的 Java
进程 ID。
[root ~]# jps -m
参数解释:
- m:输出传⼊ main ⽅法的参数
- l:输出完全的包名,应⽤主类名,jar的完全路径名

当然,我们也可以使⽤ Linux 提供的查询进程状态命令也能快速获取 Tomcat 服务的进程 id。⽐如:
[root ~]# ps -ef|grep tomcat
2. jmap
jmap(Java Memory Map)可以输出所有内存中对象的⼯具,甚⾄可以将 VM 中的 heap,以⼆进制输
出成⽂本,使⽤⽅式如下: jmap -heap:
[root ~]# jmap -heap pid #输出当前进程JVM堆内存新⽣代、⽼年代、持久代、GC算法等信
注意:pid 通过jps命令得知

3. jstack
jstack⽤于打印某个 Java 线程的线程栈信息
举个栗⼦,某 Java 进程 CPU 占⽤率⾼,我们想要定位到其中 CPU 占⽤率最⾼的线程,如何定位?
3.1 利⽤ top 命令可以查出占 CPU 最⾼的线程 pid
[root ~]# top -Hp pid
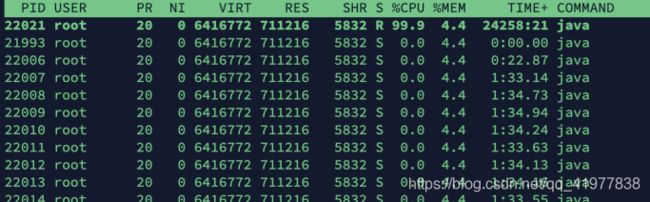
3.2 占⽤率最⾼的线程 ID 为 22021,将其转换为16进制形式(因为 java native 线程以16进制形式输
出)
[root ~]# printf '%x\n' 22021
3.3 利⽤ jstack 打印出 Java 线程调⽤栈信息
[root ~]# jstack 21993 | grep '0x5605' -A 50 --color
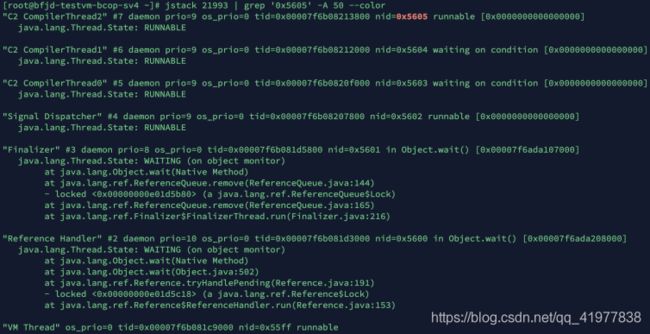
4. jinfo
jinfo可以⽤来查看正在运⾏的 java 应⽤程序的扩展参数,包括Java System属性和JVM命令⾏参数;也
可以动态的修改正在运⾏的 JVM ⼀些参数。
[root ~]# jinfo pid

5. jstat
jstat命令可以查看堆内存各部分的使⽤量,以及加载类的数量。
[root ~]# jstat -gc pid

五、GC分析
- Gc日志分析
Java 虚拟机GC⽇志是⽤于定位问题重要的⽇志信息,频繁的GC将导致应⽤吞吐量下降、响应时间增
加,甚⾄导致服务不可⽤。
JVM的GC日志的主要参数包括如下几个:
- -XX:+PrintGC 输出GC日志
- -XX:+PrintGCDetails 输出GC的详细日志
- -XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
- -XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
- -XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
- -Xloggc:…/logs/gc.log 日志文件的输出路径
IDEA 配置
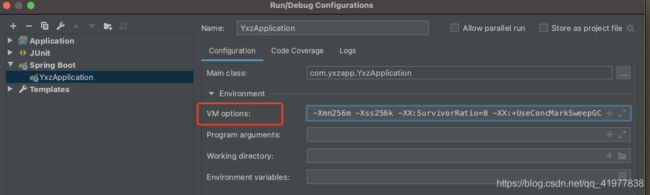
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/apps/logs/gc/gc.log -
XX:+UseConcMarkSweepGC
我们可以在 Java 应⽤的启动参数中增加-XX:+PrintGCDetails 可以输出 GC 的详细⽇志,例外还可以增
加其他的辅助参数,如 -Xloggc 制定 GC ⽇志⽂件地址。如果你的应⽤还没有开启该参数,下次重启时请
加⼊该参数。
以后打印出来的日志为:
0.756: [Full GC (System) 0.756: [CMS: 0K->1696K(204800K), 0.0347096 secs] 11488K->1696K(252608K),
[CMS Perm : 10328K->10320K(131072K)], 0.0347949 secs] [Times: user=0.06 sys=0.00, real=0.05 secs]
分析:
5.617(时间戳): [GC(Young GC) 5.617(时间戳): [ParNew(使用ParNew作为年轻代的垃圾回收期):
43296K(年轻代垃圾回收前的大小)->7006K(年轻代垃圾回收以后的大小)(47808K)(年轻代的总大小), 0.0136826 secs(回收时间)]
- CMS GC ⽇志分析
Concurrent Mark Sweep(CMS)是⽼年代垃圾收集器,从名字(Mark Sweep)可以看出,CMS 收集
器就是“标记-清除”算法实现的,分为六个步骤:
- 初始标记(STW initial mark)
- 并发标记(Concurrent marking)
- 并发预清理(Concurrent precleaning)
- 重新标记(STW remark)
- 并发清理(Concurrent sweeping)
- 并发重置(Concurrent reset)
其中初始标记(STW initial mark) 和 重新标记(STW remark)需要“Stop the World”。
老年代的GC日志(CMS)
//第一阶段 初始标记,CMS的第一个STW阶段,这个阶段会所有的GC Roots进行标记。
2020-10-20T17:04:45.424+0800: 10.756: [GC (CMS Initial Mark) [1 CMS-initial-mark: 68287K(68288K)] 69551K(99008K), 0.0019516 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
解析:CMS Initial Mark 说明该阶段为初始标记阶段,68287K(68288K)当前老年代空间的用量和总量,69551K(99008K)当前堆空间的用量和总量,0.0019516 secs初始化标记所耗费的时间。
//第二阶段并发标记
2020-10-20T17:04:45.426+0800: 10.758: [CMS-concurrent-mark-start]
2020-10-20T17:04:45.519+0800: 10.850: [CMS-concurrent-mark: 0.092/0.092 secs] [Times: user=0.56 sys=0.01, real=0.09 secs]
解析:CMS-concurrent-mark: 0.092/0.092 secs] 并发标记所所耗费的时间
//第三阶段 并发预清理阶段,并发执行的阶段。在本阶段,会查找前一阶段执行过程中,从新生代晋升或新分配或被更新的对象。通过并发地重新扫描这些对象,预清理阶段可以减少重新标记阶段的工作量。
2020-10-20T17:04:45.519+0800: 10.850: [CMS-concurrent-preclean-start]
2020-10-20T17:04:45.598+0800: 10.930: [CMS-concu解析rrent-preclean: 0.080/0.080 secs] [Times: user=0.46 sys=0.00, real=0.08 secs]
解析: [CMS-concurrent-preclean: 0.080/0.080 secs] 预清阶段所使用功能的时间。
//第四阶段 并发可中止的预清理阶段。这个阶段工作和上一个阶段差不多。增加这一阶段是为了让我们可以控制这个阶段的结束时机,比如扫描多长时间(默认5秒)或者Eden区使用占比达到期望比例(默认50%)就结束本阶段。
2020-10-20T17:04:45.599+0800: 10.930: [CMS-concurrent-abortable-preclean-start]
2020-10-20T17:04:45.599+0800: 10.930: [CMS-concurrent-abortable-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
//第五阶段 重新标记阶段,需要STW,从GC Root开始重新扫描整堆,标记存活的对象。需要注意的是,虽然CMS只回收老年代的垃圾对象,但是这个阶段依然需要扫描新生代,因为很多GC Root都在新生代。
2020-10-20T17:04:45.608+0800: 10.939: [GC (CMS Final Remark) [YG occupancy: 25310 K (30720 K)]2020-10-20T17:04:45.608+0800: 10.939: [Rescan (parallel) , 0.0117481 secs]2020-10-20T17:04:45.620+0800: 10.951: [weak refs processing, 0.0000354 secs]2020-10-20T17:04:45.620+0800: 10.951: [class unloading, 0.0268352 secs]2020-10-20T17:04:45.647+0800: 10.978: [scrub symbol table, 0.0053781 secs]2020-10-20T17:04:45.652+0800: 10.983: [scrub string table, 0.0006005 secs][1 CMS-remark: 68287K(68288K)] 93598K(99008K), 0.0447563 secs] [Times: user=0.18 sys=0.00, real=0.04 secs]
解析:
[YG occupancy: 25310 K (30720 K)] =》 新生代空间占用大小,新生代总大小。
[Rescan (parallel) , 0.0117481 secs] =》 暂停用户线程的情况下完成对所有存活对象的标记,此阶段所花费的时间。
[weak refs processing, 0.0000354 secs] =》第一步 标记处理弱引用;
[class unloading, 0.0033120 secs] =》 第二步,标记那些已卸载未使用的类;
[scrub symbol table, 0.0053781 secs][scrub string table, 0.0004780 secs =》 最后标记未被引用的常量池对象。
[1 CMS-remark: 68287K(68288K)] 93598K(99008K), 0.0447563 secs] =》 重新标记完成后 老年代使用量与总量,堆空间使用量与总量。
[Times: user=0.18 sys=0.00, real=0.04 secs] =》 各个维度的时间消耗。
//第六阶段 并发清理阶段, 对前面标记的所有可回收对象进行回收
2020-10-20T17:04:45.653+0800: 10.984: [CMS-concurrent-sweep-start]
2020-10-20T17:04:45.689+0800: 11.020: [CMS-concurrent-sweep: 0.036/0.036 secs] [Times: user=0.20 sys=0.01, real=0.04 secs]
2020-10-20T17:04:45.689+0800: 11.020: [CMS-concurrent-reset-start]
2020-10-20T17:04:45.689+0800: 11.021: [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
解析:
[CMS-concurrent-sweep: 0.036/0.036 secs] 开并发清理所耗费的时间。
[CMS-concurrent-reset: 0.000/0.000 secs] 重置数据和结构信息。
异常情况有:
伴随 prommotion failed,然后 Full GC:
[prommotion failed:存活区内存不⾜,对象进⼊⽼年代,⽽此时⽼年代也仍然没有内存容纳对象,将
导致⼀次Full GC]
伴随 concurrent mode failed,然后 Full GC:
[concurrent mode failed:CMS回收速度慢,CMS完成前,⽼年代已被占满,将导致⼀次Full GC]
频繁 CMS GC: [内存吃紧,⽼年代⻓时间处于较满的状态]
个人博客地址:http://blog.yanxiaolong.cn/