MyCat专题(三)-MyCat基础入门
1.MyCat概述

Mycat 是数据库中间件
数据库中间件: 连接java应用程序和数据库
中间件: 是一类连接软件组件和应用的计算机软件, 以便于软件各部件之间的沟通。
2.MyCat的前世今生
2013年阿里的Cobar在某大型项目中使用过程中发现存在一些比较严重的问题,于是第一代改良版——Mycat诞生。Mycat开源以后,一些Cobar的用户参与了Mycat的开发,最终Mycat发展成为一个由众多软件公司的实力派架构师和资深开发人员维护的社区型开源软件。
2014年Mycat首次在上海的《中华架构师》大会上对外宣讲,引发围观,更多的人参与进来,随后越来越多的项目采用了Mycat
2015年6月为止,Mycat项目总共有17个Committer,其中核心参与者的年薪总额超过300万
2015年5月,由核心参与者们一起编写的第一本官方权威指南《Mycat权威指南》电子版发布,众筹预售超过200本,成为开源项目中的首创。
截至2015年4月,超过60个项目采用Mycat,涵盖电信、电子商务、物流、移动应用、O2O的众多领域和公司。
3.Mycat的官网
http://www.mycat.io/

4.Mycat的作用
4.1.MyCat读写分离
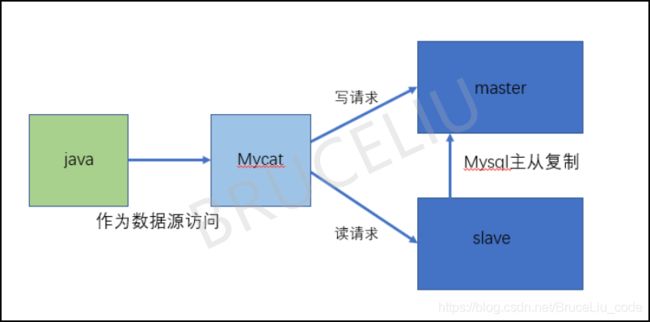
高可用性和MySQL读写分离:当一台服务器宕机时,由集群中的另外一台服务器自动接管它的工作,持续提供服务,由MyCat自动完成切换。MyCat可以轻松实现读写分离,实现主数据库的插入、更新、删除等写操作,从数据库的查询读操作。
4.2.数据分片

100亿大表水平分片,集群并行计算:将存放在同一个数据库中的数据通过某种规则进行切分,达到分散单台数据库设备负载的效果。(水平切分和垂直切分,如果表的数据量超过800万,可以考虑对数据进行拆分)
4.3.多数据源整合

整合多种数据源:当项目中使用到多种数据源时(如Mysql,Oracle等),可以使用MyCat逻辑库配置多种数据源,应用程序只需要配置逻辑库数据源即可。
5.Mycat的原理
Mycat 的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的 SQL 语句,首先对 SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库, 并将返回的结果做适当的处理,最终再返回给用户。

这种方式把数据库的分布式从代码中解耦出来,程序员察觉不出来后台使用 Mycat 还是MySQL
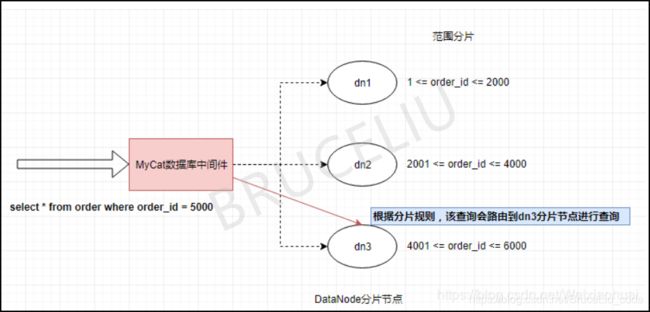
上图中,采用order_id作为分片字段进行范围分片,上面的SQL语句被发送到dn3这个分片节点进行执行,MyCat将查询结果进行处理后返回给用户。
6.MyCat核心概念
a. 逻辑库:schema,数据库中间件可以被当做一个或者多个数据库集群构成的逻辑库。
b. 逻辑表:table, 在MyCat中,对于应用来说,读写数据的表就是逻辑表。逻辑表可以进行分片,也可以不分。
1.分片表:order表按照规则将数据分到dn1和dn2两个节点 (`
`)
2.非分片表:order表只将数据分到dn1节点
3.ER表:基于E-R关系进行分片,子表的记录与其关联的父表的记录保存在同一个分片上,这样关联查询就不需要跨库进行查询
4.全局表:应用中可能存在一些数据变动很小的表,如字典表等,这些表的数据量不会很大,也很稳定。全局表存在于所有分片上,方便业务表与其进行关联查询,所有的分片都保存了一份全局表的数据。
c. 分片节点(dataNode):将一个大表拆分到多个分片数据库节点上,每个分片上面的数据库就是一个分片节点。
d. 节点主机(dataHost): 一个或者多个分片节点所在的主机就是节点主机,同一个节点主机上面可以有多个分片数据库。
e .分片规则 (rule)
就是拆分的算法, 如何来拆分呢? 就要用到分片规则, mycat有10中分片规则, 基本上我们的应用场景都包含在内了, 这方面mycat做的很赞!
7.MyCat配置详解
主要的配置文件设计有几个:
schema.xml: 主要配置逻辑库、分片表、分片节点和节点主机等信息;
server.xml: MyCat系统参数的配置文件;
sequence: 全局序列的配置文件;
log4j.xml:MyCat日志输出配置文件;
rule.xml: MyCat分片规则相关配置文件;
7.1.server.xml
user标签:主要配置MyCat的用户、密码以及权限等信息
<user name="root">
<property name="password">123456property>
<property name="schemas">test_db,test_db2,test_db3property>
<property name="readOnly">trueproperty>
<property name="benchmark">1000property>
<property name="usingDecrypt">1property>
user>
system标签:主要配置系统参数等,如下是一些常用的参数
<system>
<property name="charset">utf8property>
<property name="defaultSqlParser">druidparserproperty>
<property name="processors">1property>
<property name="sequenceHandlerType">0property>
<property name="useSqlStat">0property>
<property name="useGlobleTableCheck">0property>
<property name="serverPort">8066property>
<property name="managerPort">9066property>
<property name="bindIp">0.0.0.0property>
<property name="idleTimeout">300000property>
<property name="handleDistributedTransactions">0property>
<property name="useOffHeapForMerge">1property>
<property name="useZKSwitch">trueproperty>
system>
7.2.schema.xml
schema.xml : 配置MyCat逻辑库,逻辑表、分片节点、节点主机、分片规则及数据源信息等.
1)
<schema name="mycat_order" checkSQLschema="false" sqlMaxLimit="100">
<table name="t_order" dataNode="dn1,dn2" rule="mod-long">
<childTable name="t_order_detail" primaryKey="od_id" joinKey="order_id" parentKey="order_id">childTable>
table>
schema>
如上配置:
name : 逻辑库名字为mycat_order
checkSQLschema: false : 当设置为true时,比如发送一条sql:select * from mycat_order.t_order ,那么MyCat会自动去掉mycat_order逻辑库名字前缀,把sql变为:select * from t_order, 这样有效避免报表或视图不存在错误。
注意点: 如果使用select * from test.t_order ,sql语句中所带的逻辑库名字跟schema标签中的name不一致的话,MyCat不会自动去掉逻辑库名字前缀,如果逻辑库不存在,仍然会报错。
sqlMaxLimit:100 : 如果每次执行的sql语句后面没有跟上limit xx关键字的话,MyCat会自动在sql语句的后面拼上limit 100;例如: select * from t_order , 经过MyCat处理后sql变为: select * from t_order limit 100, 如果没有设置该值,MyCat默认会将全部结果集返回,这样查询速度就慢很多,建议加上,避免一次性查询过多数据。
另外,schema标签还有一个属性dataNode,用于指定没有分配分片节
点的那些表的默认数据节点。如:
<schema name="mycat_order" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="t_order" dataNode="dn1,dn2" rule="mod-long">
<childTable name="t_order_detail" primaryKey="od_id" joinKey="order_id" parentKey="order_id">childTable>
table>
schema>
如上配置,表t_order分布到dn1,dn2数据节点上,没有配置的表则会分布到默认的节点dn1(
2)
<table name="t_order" dataNode="dn1,dn2" rule="mod-long">table>
name属性: 逻辑表的名字,同一个逻辑库schema中的逻辑表的名称应该唯一,就像我们create table在同一个数据库中不能创建相同名字的两张表。
dataNode属性:配置逻辑表分布的数据节点,名字需要与dataNode标签的name对应上。
rule:配置逻辑表的分片规则,需要在rule.xml中声明的规则名字对应上。
ruleRequired: 指定分片规则是否必须,如果为true,但是没有指定rule,程序会报错。
primaryKey: 指定逻辑表对应真实表的主键,如果分片字段不是主键的话,那么使用主键查询的时候,会将查询语句发送到所有配置的分片节点上。如果分片字段是主键,MyCat会缓存主键与具体dataNode的对应关系,使用主键查询的时候只会将查询语句发送到该具体分片节点上,不会进行广播式发送。
type: 指定该逻辑表是全局表还是普通逻辑表。type="global"表示全局表
autoIncrement: 指定是否自增长主键。只有定义了自增长主键,使用last_insert_id()才能够正确返回值,否则返回0.(建议结合数据库模式的全局序列指定主键)
needAddLimit: 指定逻辑表是否在查询的时候自动添加limit去限制返回的结果集记录数,默认为true,如果语句中已经包含了limit关键字,则不会重复添加。
(3)
<table name="t_order" dataNode="dn1,dn2" rule="mod-long">
<childTable name="t_order_detail" primaryKey="od_id" joinKey="order_id" parentKey="order_id">childTable>
table>
name属性:子表的名称t_order_detail
primaryKey属性:子表的主键
joinKey属性:新增子表记录的时候,会根据该值查询父表在哪个分片节点上。(子表中字段的名称order_id)
parentKey属性:与父表建立关联关系的列,结合joinKey确定好子表记录存放的分片节点,插入子表记录时直接插入到该分片节点上。(父表中字段名称order_id)
needAddLimit属性: 指定逻辑表是否在查询的时候自动添加limit去限制返回的结果集记录数,默认为true,如果语句中已经包含了limit关键字,则不会重复添加。
(4)
<dataNode name="dn1" dataHost="host1" database="test_mycat" />
如上配置表示:使用名为host1的节点主机上的实际数据库(test_mycat)作为一个分片节点,名字为dn1.
name属性:指定分片节点的名称,与声明逻辑表table标签中的dataNode名字对应上
dataHost属性:指定分片节点所在的节点主机(数据库实例),与dataHost标签声明的name对应
database属性:指定真实数据库名称
(5)
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="host1" url="192.168.1.12:3306" user="root"
password="0905">
writeHost>
dataHost>
name属性: 指定分片主机的名称,供dataNode标签使用
maxCon属性: 指定读写实例的连接池的最大连接数量
minCon属性: 指定读写实例的连接池的最小连接数量,初始化连接池的大小
balance属性:指定负载均衡的类型
a. balance = “0” : 不开启读写分离,所有的读请求都发送到可用的writeHost写节点上(不会发readHost)。
b. balance = “1” : 全部的readHost与stand by writeHost参与select语句的负载均衡,
c. balance = “2” : 读操作会随机发往writeHost以及 readHost,理论上实现的是负载均衡
d. balance = “3” : 配置了readHost时读操作会随机发往readHost(不会发writeHost),而没有配置readHost时读操作会发往第一个writeHost。
writeType属性:
a. writeType="0": 所有写操作发送到配置的第一个writeHost,当第一个writeHost宕机时,切换到第二个writeHost,重新启动后以切换后的为准,切换记录在配置文件:dnindex.properties中
b. writeType="1": 所有写操作都随发送到配置的writeHost
dbType属性: 指定后端数据库类型,支持mysql、oracle等
dbDriver属性: 指定后端数据库连接驱动信息,支持native和jdbc。
switchType属性: 指定切换方式
switchType = -1:不自动切换
switchType = 1:自动切换(默认)
switchType = 2:基于MySql主从同步的状态来决定是否切换,心跳语句: show slave status
switchType = 3: 基于mysql galary cluster的切换机制,心跳语句: show status like 'wsrep%'
(6)标签:指定后端数据库进行心跳检查的语句,如下为mysql和oracle心跳检查的语句:
<heartbeat>select user()heartbeat> <heartbeat>select 1 from dualheartbeat>
(7)
<writeHost host="host2" url="192.168.1.11:3306" user="root" password="0905"> writeHost>
在一个dataHost中,可以配置多个writeHost和readHost,如果写节点出现宕机,那么写节点下面绑定的所有读节点也不能正常工作。
host属性:标识不同的实例,一般 writeHost 我们使用M1,readHost 我们用S1
url属性:数据库连接url
user属性:数据库连接用户名
password属性:数据库连接用户密码
8、总结

本文对MyCat中一些常见的配置,如逻辑表、逻辑库、分片规则以及常用的标签属性都进行了详细的说明,以此作为总结, 后面方便复习使用。